NoSQL
우선 RDBMS들이 있음에도 불구하고 NoSQL의 등장한 원인부터 알아보려고 해요.
마틴 파울러의 "NoSQL - 빅 데이터 세상으로 떠나는 간결한 안내서" 라는 책제목만 보아도 대략적인 느낌이 와요. 방대한 데이터, 대용량 웹 서비스, 대용량 트래픽 등 IT 발전으로 인해 이제 인터넷을 사용하지 않는 사람은 드물어요.
🤔 뿐만 아니라, 유연성에 대한 고민도 해봐야 해요. RDBMS에서 스키마를 만들어서 그에 맞는 데이터를 넣는다는 규약으로 혼동을 줄일 수는 있지만, 규약이라는 것을 다른 의미로 보면 변경을 허용하지 않으려는 성질이 있어요.
빠른 변화에 적응 가능한 것을 찾아야 해요. 즉, 변경에 유연하게 대처해야 할 수 있어야 해요. NoSQL은 스키마 없이도 사용 가능하고, 데이터 타입도 미리 정하지 않는다는 특징이 있어요.
❗️무엇보다도 NoSQL의 가장 큰 장점은 RDBMS보다 읽기와 쓰기 성능이 뛰어나다는 것이에요.
RDBMS들은 대부분 인덱스 처리 방식을 B-Tree 방식을 채택하였는데, 이 때문에 쓰기 부분에서 성능 저하가 일어나요.
구글, 페이스북, 아마존과 같이 IT 서비스 업체들은 더이상 RDBMS만으로는 서비스 트래픽을 감당하기 어렵다고 판단했어요. 특히 구글의 빅테이블, 아마존의 다이나모와 같은 논문 및 자료는 데이터를 실시간으로 분산처리하는 개념을 세상에 알려주는 계기가 되었어요.
Redis
NoSQL은 다양한 모델이 있지만, Redis는키 하나로 데이터 하나를 저장하고 조회할 수 있는 단일 키-값 구조를 가져요. RDBMS와 비교하면 주 키 하나와 일반 필드 하나를 가진 테이블을 들 수 있는 거에요.
키-값 모델 NoSQL은 단순한 저장구조로 인하여 복잡한 조회 연산을 지원하지 않아요. 그래서 고속 읽기와 쓰기에 최적화된 경우가 많지요.
정리해보면, Redis는 다양한 자료구조를 저장하고 조회할 수 있으며 다양한 종류의 조회 방법을 지원하는 인메모리 NoSQL이에요.
종류
Redis는 Jedis와 Lettuce 두 종류가 있어요. 이 부분에 대한 내용은
이동욱님의 Jedis 보다 Lettuce 를 쓰자에 잘 정리되어 있어요. 차후에 저도 실험 테스트를 해보려고 해요.
Cache
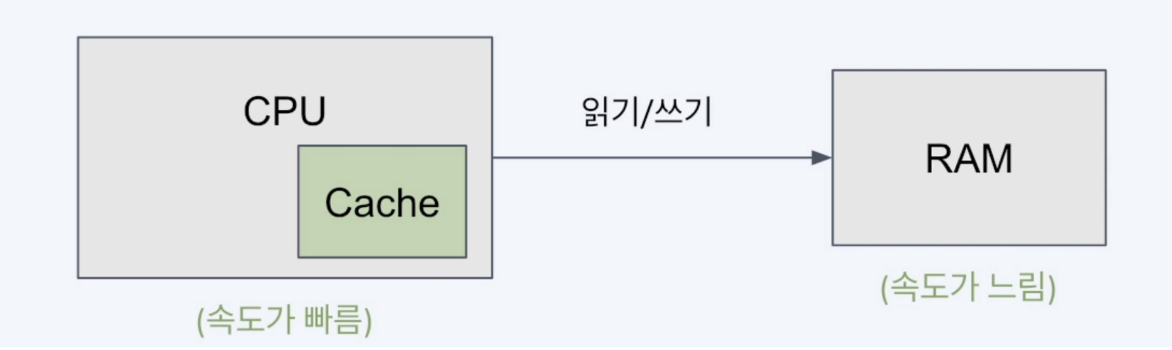
속도를 위해 용량을 절충하는 캐시는 일반적으로 데이터의 하위 집합을 일시적으로 저장합해요. 보통 완전하고 영구적인 데이터가 있는 데이터베이스와는 대조적이지요. 즉, Cache의 데이터는 언제든지 사라질 수 있는 거에요.
캐싱 과정
캐싱 과정을 보면 왜 성능상 이점이 있는지 알 수 있어요.
- 클라이언트가 데이터 요청
- RAM 및 인 메모리 엔진에서 데이터 조회
- 2번에서 확인되면 응답
- 2번에서 확인되지 않는다면 DB에서 조회한 결과를 Cache에 저장 후 응답
DB로 가기 전에 작은 데이터 공간을 먼저 확인해서 가져오기에 성능상 이점이 있는 거에요. 다만, 작은 데이터 공간에 메모리는 DB 메모리보다 확연히 작을 거에요.
캐싱 적용
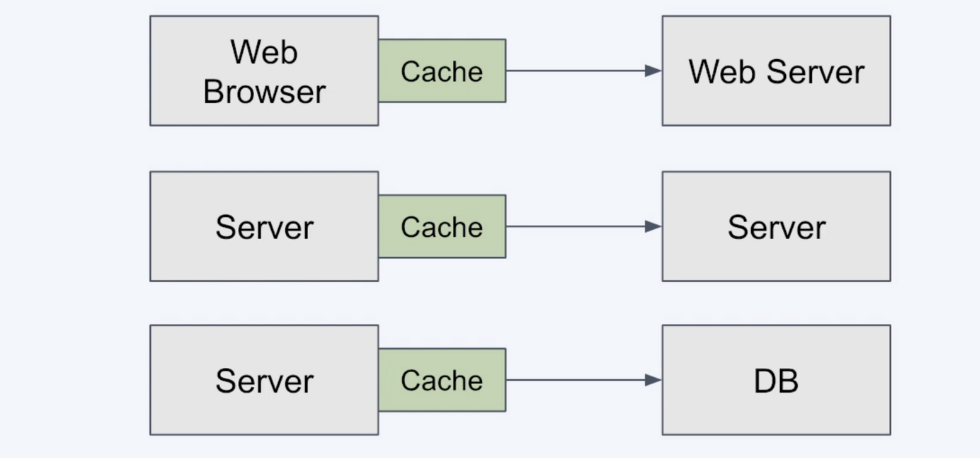
위 그림을 통해 캐싱 적용의 장점 세가지를 확인할 수 있어요
- Web Browser Cache를 통한 네트워크 지연 감소
- Server Cache를 통한 서버 리소스 사용 감소
- Server Cache를 통한 병목현상 감소
캐싱 용어
- 캐시 적중(Cache hit) : 캐시에 접근해 데이터를 발견함
- 캐시 미스(Cache miss) : 캐시에 접근했는데 데이터를 발견하지 못함
- 캐시 히트율(Cache hit rate) : 캐시 히트 / (캐시 히트 + 캐시 미스)
- 캐시 삭제 정책(Eviction Policy) : 캐시의 데이터 공간 확보를 위한 저장된 데이터 삭제
- 캐시 전략 : 환경에 따라 적합한 캐시 운영 방식을 선택할 수 있음(Cache-Aside, Write Through)
캐시 전략 (읽기)
Cache-Aside (Lazy-loading)
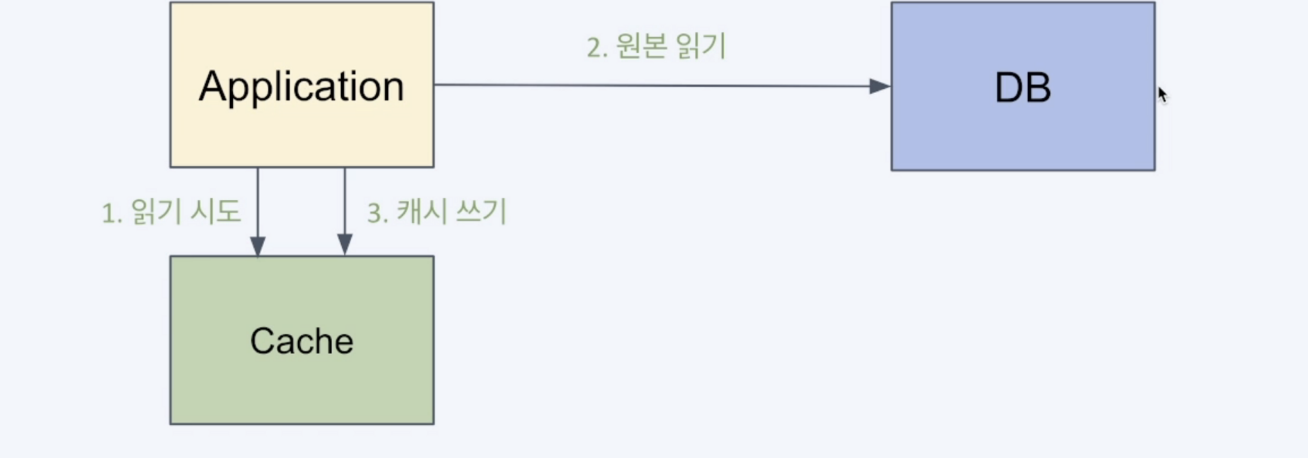
Cache-Aside는 항상 캐시를 먼저 확인하는 방식 이에요. 캐시에 없다면 원본(DB)에서 읽어온 후에 캐시에 저장하는 것이지요.
필요한 데이터만 캐시에 저장되고 Cache miss가 있어도 치명적이지 않는다는 장점이 있으나, 최초 접근은 느리고 업데이트의 주기가 일정하지 않기 때문에 캐시가 최신 데이터가 아닐 수 있다는 단점이 있어요.
스프링이 채택한 캐시 전략
스프링에서 레디스는 이 방식을 채택하였어요. (다음 편에 이와 관련된 내용을 적용해 볼 거에요.)
캐시 전략 (쓰기)
Write Through
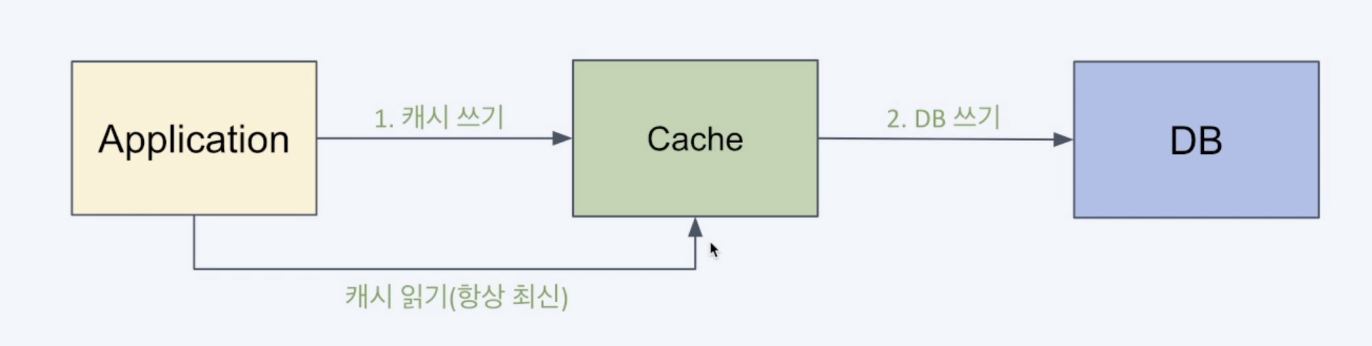
Write Through는 데이터를 쓸 때, 항상 데이터를 업데이트 하여 최신 상태를 유지하는 방식이에요
캐시가 항상 동기화 되어 있어 데이터가 최신이라는 장점이 있으나, 자주 사용하지 않는 데이터도 캐시되고, 쓰기 지연시간이 증가한다는 단점이 있어요.
Write Back

Write Back은 데이터를 캐시에만 쓰고, 캐시의 데이터를 일정 주기로 DB에 업데이트하는 방식이에요.
쓰기가 많은 경우 DB에 부하를 줄일 수 있다는 장점이 있으나, 캐시가 DB에 쓰기 전에 장애가 생기면 데이터 유실 가능하다는 단점이 있어요.
캐싱 데이터 제거 전략
'캐시에서 어떤 데이터를 언제 제거할 것인가?' 는 캐싱에서 제일 중요하게 생각할 부분이기도 해요. 제한된 자원을 효율적으로 사용하거나, 비용 효율적인 방식을 채택해야 하기 때문이에요.
- Expiration : 각 데이터에 TTL(Time-To-Live)을 설정해 서버 시간 기준으로 삭제
- Eviction 알고리즘 : 공간을 확보해야 할 경우 어떤 데이터를 삭제해야 할지 결정하는 방식
- LRU : 가장 오랫동안 사용되지 않은 데이터 삭제
- LFU : (최근에 사용했을지라도) 가장 적게 사용한 데이터 삭제
- FIFO : 선입선출
참고자료
레디스 공식 홈페이지
lettuce.io
Cache개념과 Spring에서의 Cache
Jedis 보다 Lettuce 를 쓰자
캐싱이란 무엇이고 어떻게 작동합니까
