선형회귀 모델은 직선이나 평면상에서 수치 예측 모델을 의미하는데, 통계학에서는 '단순회귀분석'이나 '다중회귀분석'이라고 말하기도 한다.
5-1. 회귀 모델로 주택 가격 추정하기
주택을 구입하려하는데, 그 주택의 가격이 적절한지 어떻게 판단할 수 있을까? 역세권인지, 방의 크기나 개수는 적당한지, 건물이 지은 지 얼마나 되었는지, 등 주택 가격을 결정하는 요소는 너무나 다양하고, 그 가격이 거품이 낀 것인지, 저평가된 것인지를 판단해야 한다.
이에 인공지능 알고리즘을 활용하여 주택 가격의 추정 모델을 구축하고자 한다. 주택 가격을 추정할 때는 주소, 입지 조건, 건축 연수, 층수, 방의 배치 형태나 넓이와 같은 정보를 활용해야 한다.
이때 우리가 추정하고 싶은 주택 가격을 목적변수(objective variable) 또는 종속변수(dependent variable)라고 하며, 추정하는데 필요한 정보를 설명변수(explanatory variable) 또는 독립변수(independent variable)이라고 한다.
우리는 주택 가격을 추정하는 수치 예측을 하려고 하므로, 직선상의(선형) 수치 예측(회귀) 모델인 선형회귀(linear regression)모델을 사용해야 하고자 한다.
이러한 인공지능 모델을 만들 때는 주의할 점이 있다. 모델을 만들 때는 여러 가지 다양한 매물의 정보를 수집하고 이러한 정보를 분석하여 만들어진다. 그렇게 대량의 데이터로부터 만드어진 관계식과 주어진 데이터를 사용하여 추정 가격을 산출하게 되는데, 어느 한쪽으로 치우친 데이터를 사용한다면 제대로 된 관계식을 얻을 수 없다. 예를 들어, 수집한 주택 정보의 상당수가 비교적 지은 지 얼마 안 된 건물들이라면, 건축 연수가 오래될수록 얼마나 가격이 떨어지는지에 대해서는 제대로 평가를 할 수 없다. 즉, 이렇게 편향(bias)이 적은 데이터를 수집하는 것이 정확한 결과를 위해서는 필수적이다.
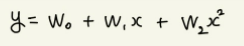
이때 이러한 식은 그래프로 표현하면 직선이 아니라 곡선이지만, 선형회귀 문제로 정의한다. 이유는 이 모델식으로 풀고자 하는 것이 차수가 2인 x가 아니라 w0나, w1, w2와 같은 차수가 1인 가중치이기 때문이다. 즉, w를 기준으로 본다면 1차식이기에 선형식을 갖는 것이다.
5-2. 데이터 세트 'Boston Housing Dataset'
인공지능에는 모델을 만들 때 학습 데이터와 테스트 데이터가 필요하며, 이를 데이터 세트라고 부른다. 이때, 사이킷런에서 제공하는 'Boston Housing Dataset' 데이터 셋의 정보는 다음과 같다.

즉, column의 14개이며, 행의 개수는 506행인 데이터셋이다.
이때, 변수들에는 종류와 특징이 존재한다.
질적데이터
- 명목척도(nominal scale): 분류나 구별을 하기 위한 척도. 더미변수 (예: 남성:1 여성:0)
- 서열척도(ordinal scale): 대소 관계만 의미가 있는 척도. (예: 나쁨:0 보통:1 좋음:2)
양적데이터
-
등간척도(interval scale): 간격에 의미가 있는 변수. 덧셈, 뺄셈만 의미 가짐. (예: 서기)
예를 들어 서기 2018년은 1009년의 2배이지만 사실 큰 의미가 없음. -
비율척도(ratio scale): 비례에도 의미가 있는 변수. 덧셈, 뺄셈, 곱셈, 나눗셈 전체에 의미 가짐. (예: 속도, 키)
5-3. 선형회귀 모델
회귀 모델이란 하나의 목적변수(종속변수)를 하나 이상의 설명변수(독립변수)로 기술한 관계식을 말한다. 이때 w를 계수(가중치)라 하며, x를 설명변수라고 할 때 목적변수 y의 선형회귀 모델은 다음과 같다.

이때, 알고리즘이 하는 일은 모델식에서 적절한 가중치 w를 찾아서 결정하는 것.
이를 위해서는 모델식의 x와 y에 값을 넣음ㄴ서 w를 찾아야 하는데, 수많은 정보를 대입해야 하기에 이 과정에는 행렬을 이용하는 것이 일반적이다.

이번에 사용할 데이터 세트에 대한 n=506(행의 개수), l=13(열의 개수)이다. 즉, 목적변수를 n차원의 열벡터 Y로, 설명변수와 w0의 계수 1을 n행(l+1)열의 행렬 X로, 가중치를 l+1차원의 열벡터 W로 두면 앞의 정의를 다음과 같이 표현할 수 있다.

이때, 인공지능이 하는 일은 선형회귀 모델식에 가장 잘 맞는 열벡터 W를 찾는 것이다.
5-4. 최소제곱법으로 파라미터 도출하기
모델에 가장 잘 들어맞는 가중치를 찾는 근사법으로 최소제곱법(least square method)를 사용할 수 있다.
이는 데이터 세트와 같은 수치 데이터들을 1차함수와 같은 특정 함수를 사용하여 근사적으로 표현할 수 있다고 가정한다. 이러한 함수가 수치 데이터들을 잘 표현하기 위해서는 수치 데이터값과 함수의 결괏값 사이에 오차가 최소가 되어야 하는데, 이 과정에서 오차를 제곱하여 모두 더한 값이 최소가 되는 가중치를 찾게 된다. 이렇게 최종적으로 오차가 가장 작게 나오는 가중치를 찾으면 이를 모델식의 계수로 사용한다.
목적변수를 Y, 설명변수를 X1, X2, ..., Xl 모델식을 f(X1, X2, ..., Xl)라고 한다면, 최소제곱법을 적용하는 과정은 오차의 제곱합 D를 최소화하는 f(X1, X2, ..., Xl)을 구하는 것. n개의 데이터 세트에서 k번째의 데이터를 (xk1, xk2, ..., xkl, yk)라고 한다면, 오차의 제곱합과 모델식은 다음과 같다.

이를 달리 표현하면 변수 w의 값을 변화하면서 함수 D의 값을 구하되, 그 값이 최소가 되는 w들의 조합을 찾는 것. 이 과정에서 다음과 같이 편미분을 사용한다.
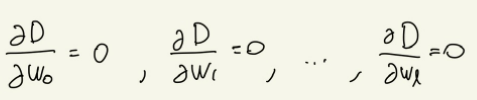
이렇게 해서 구한 l+1개의 연립 1차방정식으로 w의 값을 구한다.
인공지능이란 '인공적으로 만들어진 인간과 같은 지능, 또는 그런 지능을 만드는 기술'
5-5. 정규화로 과학습 줄이기
단순히 데이터의 양이 많다고 해서 반드시 좋은 관계식이 나오는 것은 아니다.

가운데의 그래프처럼 약간의 노이즈는 허용하나 전체적인 데이터의 특성을 잘 반영하는 식을 일반화 능력(generalization ability)가 있다고 하며, 오른쪽의 그래프처럼 주어진 데이터에 너무 정확히 들어맞아 지나치게 복잡하게 표현된 상태를 과학습(overfitting)이라고 한다.
선형회귀에서 과학습을 피하기 위한 방법으로 정규화(Regularization)이 있다. 이는 모델이 복잡해질수록 패널티를 적용하는 방법으로 과학습을 억제한다. 모델이 지나치게 복잡해지지 않도록 모델식 자체에 모델의 계수(가중치)가 작아지게 만드는 항을 추가하는 방법을 사용한다.
정규화를 할 때는 보통 L1정규화와 L2정규화를 사용한다. 이는 파라미터(가중치 함수)의 L1노름과 L2노름을 의미한다.
먼저 선형회귀 모델을 다음과 같이 정의하자.

정규화를 위해 추가할 항을 다음과 같이 정의하고, L1정규화에서는 파라미터의 L1 노름에 계수를 곱한 다음과 같은 항을 사용한다.

L2 정규화에서는 파라미터의 L2노름에 계수를 곱한 다음과 같은 항을 사용한다
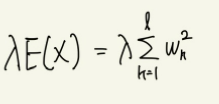
이 항을 최소제곱오차를 구하는 식 D에 추가한다.

L1 정규화의 경우 이렇게 정규화 항이 추가된 함수 D를 최소화할 수 있는 가중치 W(선형회귀 모델에서 바이어스인 w0의 계수이자 가중치인 w1, w2, ..., wl을 담고 있는 행렬)을 찾다 보면 W의 노름이 너무 커지지 않도록 억제가 되며, 이렇게 정규화된 선형회귀를 Lasso 회귀라고 한다.
L2 정규화에서는 L1정규화와 달리 절댓값을 사용하지 않기에 상대적으로 미분이 쉽다. 이렇게 정규하된 선형회귀를 Ridge 회귀라고 한다.
이렇게 구해진 L1 정규화와 L2 정규화는 기존의 모델식에 조합해서 쓸 수 있고, 심지어 이 둘을 조합할 수도 있는데 그렇게 만들어진 회귀 모델을 Elastic Net이라고 한다.
이때 정규화에 사용되는 λ는 상수인데, λ값을 크게 잡으면 전체를 최소화하기 위해 가징추 함수의 노름이 작아져 정규화를 더 강화시키는 효과가 있다. 즉, λ를 조절함으로써 정규화의 강약을 조절할 수 있다.
5-6. 완성된 모델 평가하기
머신러닝에서는 보통 하나의 데이터 세트를 학습용 데이터와 테스트용 데이터로 나눈 다음, 학습 데이터로 학습된 모델을 테스트 데이터로 검증하면서 모델이 더 나은 성능을 발휘하도록 조정한다. 이렇게 조정하는 과정을 튜닝(tuning)이라고 한다.
모델을 검증하기 위한 데이터 세트를 만드는 방법으로는 다음이 있다.
-
홀드아웃 교차 검증법(holdout cross validation)
하나의 데이터 세트를 학습용 데이터와 테스트용 데이터 두 가지로 나누는 방법 -
k-분할 교차 검증법(k-fold cross validation)
데이터 세트를 k개로 분할한 다음 k번에 걸쳐 학습 데이터와 테스트 데이터의 조합을 바꿔쓰는 방법
모델의 성능은 잔차(residual)을 통한 시각화를 통해 눈으로도 확인할 수 있다. 이때 잔차란 추정된 회귀식과 실제 데이터 사이의 차이를 말한다. 이때 잔차는 다음과 같이 표현할 수 있다.

잔차를 그래프로 표현했을 때 큰 문제가 없다고 판단했다면, 다음은 모델의 성능을 평가할 수 있는 평균제곱오차(mean square error)나 결정계수같은 지표를 통해 살펴보아야 한다.

MSE는 잔차의 제곱을 모두 더한 다음 평균을 구한 것으로, 작으면 작을수록 모델이 잘 들어맞는다는 것을 의미한다. 결정계수의 분모는 y의 분산을 의미한다. 이는 0이상 1이하의 값을 가지는데, 1에 가까우면 가까울수록 잘 들어맞는 모델이라고 생각할 수 있다.
통계와 머신러닝은 둘 다 데이터를 다루는 학문이고, 분석하는 방법도 비슷하다. 다만, 그 학문이 지향하는 목적 면에서 큰 차이를 보이는데, 통계는 기존 데이터에 대한 '설명'에 무게 중심이 있고, 머신러닝은 기존 데이터를 통한 '예측'에 무게 중심이 쏠려 있다. 이에 통계에서는 '검증'에 더 충실해야 하고, 수집된 데이터를 바탕으로 발생한 현상에 대해 더욱 정확하게 설명하는 것을 목표로 한다. 반면 머신러닝에서는 '예측'이 더 중요하므로 수집된 데이터를 분할한 뒤, 일부로는 모델을 만들고 일부로는 검증을 하면서 더욱 정밀한 예측을 가능하게 하는 것 목표로 한다.
