7-1. 딥러닝으로 손글씨 인식하기
이전에는 컴퓨터에게 이미지를 인식시키는 것은 매우 어려운일이었지만, 딥러닝 기술의 등장으로 이미지를 인식하고 처리하는 것이 더욱 쉬워지고 정확도 또한 매우 높아졌다.
7-2. 데이터 세트 'MNIST'
MNIST는 인공지능 프로그래밍 계의 Hello World라고 불릴 정도로 잘 알려진 데이터 세트. 이는 손글씨 숫자와 정답 레이블을 표시한 데이터이다.
컴퓨터에는 이미지를 처리할 때, 아주 작은 점들의 모임으로 취급하는데, 이 점들의 최소 단위를 1픽셀(Pixel)이라고 한다. Mnist 데이터는 가로 28픽셀, 세로 28픽셀로 총 28*28=784의 픽셀의 이미지로 만들어졌다. 이때, 하나의 픽셀은 0에서 255까지, 총 256가지의 정수값을 가진다. 이때, 픽셀의 정수값이 0이면 검은색, 255면 흰색, 그 사이의 값이면 회색으로 간주한다.
이미지 한 장, 한 장에는 정답 레이블(label)이 붙어 있다. 이는 손글씨로 쓰인 숫자가 어떤 수를 나타내는지 정답을 써 둔 것. 정답 레이블은 지도 학습(supervised learning)알고리즘에 꼭 필요하다.
인공지능 알고리즘은 크게 지도 학습(supervised learning)알고리즘, 비지도 학습(unsupervised learning)알고리즘, 강화 학습(reinforcement learning)알고리즘으로 분류된다. 지도 학습에서는 정답 레이블이 붙은 데이터 세트를 사용하여 모델을 만든다. 비지도 학습은 정답 레이블이 없는 데이터 세트를 사용하는데, 이때 주성분 분석 등이 이에 해당한다. 강화학습은 사람이 컴퓨터에게 행동할 수 있는 선택지와 보상을 줄 조건을 설정하면, 이후는 컴퓨터가 알아서 스스로의 행동 알고리즘을 만들어낼 수 있는 새로운 인공지능 모델이다.
7-3. 신경망이란?
신경망은 데이터를 읽는 입력층과 최종 결과를 내는 출력층, 그리고 그 사이에 하나 이상 존재하는 은닉층(hidden layer)로 구성된다. 각 계층은 노드(node)라고 불리는 인공 뉴런으로 만들어지는데, 신경망 중에서도 은닉층이 두 개 이상인 경우를 **심층 신경망(DNN, Deep neural network)라고 부른다.
신경망은 사람의 뇌에 있는 신경세포인 뉴런과 그런 세포들의 연결 관계를 흉내내서 만든 수학적 모델이다. 이는 인접한 신경세포와 연결되어 있으면서 전기 신호를 전달하여 정보를 처리한다고 알려져 있다.
결론적으로 인공 뉴런 역할을 하는 노드는 신경세포처럼 입력을 받고, 그 결과로 일정한 값을 출력한다. 노드는 입력값 x에 대하여 가중치 w를 곱하고, 여기에 또 다시 바이어스 b를 더한다. 최종적으로 이 값에 활성화 함수 σ를 적용해 변환된 값을 출력한다. 이때, 입력값 x는 여러 개가 있을 수 있고, 이에 따라 가중치 w도 여러 개가 나올 수 있다.

결국, 이런 노드 여러 개가 결합하면서 신경망이 만들어진다. MNIST 데이터는 784 픽셀이므로 784개의 노드로 구성된 입력층이 만들어지고, 손글씨 이미지에 따라 그에 맞는 입력값이 들어간다. 입력층으로 들어간 이미지 정보는 은닉층을 통과하면서 최종적으로 10(0~9이므로)개의 노드로 구성된 출력층에 도달한다.
7-4. 신경망이란?
신경망에서 사용하는 활성화 함수 중에는 시그모이드 함수와 ReLU 함수가 있다. 시그모이드 함수는 다음과 같다.
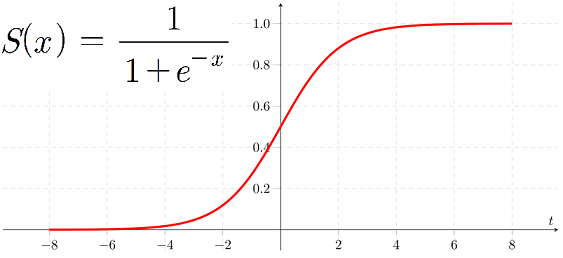
이를 사용하는 분류 모델로는 로지스틱 회귀가 있다.
ReLU함수는 다음과 같으며, 최근 시그모이드 함수를 대체하는 용도로 많이 사용되고 있다.
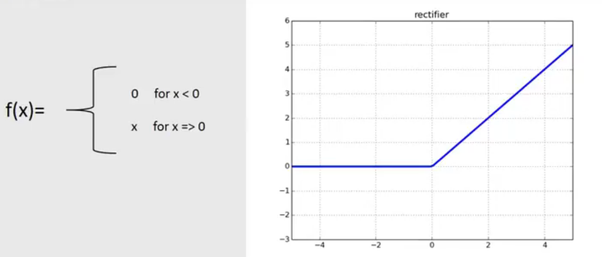
수식에서 알 수 있듯이, 이는 함수의 입력값이 0보다 작거나 같으면 0을 출력하고, 입력값이 0보다 크면 입력한 값이 그대로 출력값으로 나오는 함수이다.
이 두 가지 활성화 함수는 모두 비선형 함수이다. 비선형이라는 말은 하나의 직선으로 표현할 수 없다는 뜻이며, 이를 사용하면 하나의 직선으로는 구분하지 못하는 영역을 구분할 수 있다.
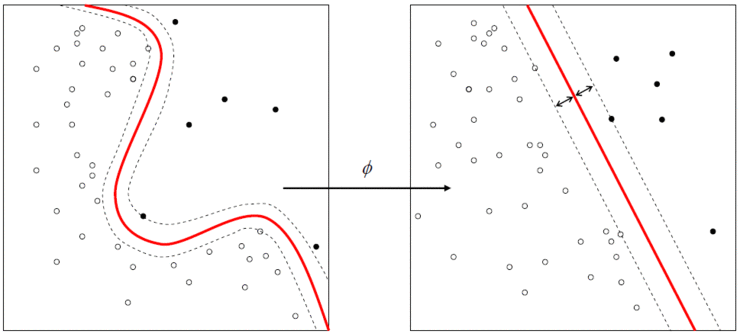
신경망에서는 이런 비선형적인 영역을 구분하기 위해 여러 계층의 네트워크가 필요하다. 이때 활성화 함수가 비선형적이어야 하는 이유는 신경망의 표현력이 더 향상되기 때문이다.
7-5. 심층 신경망이란?
신경망의 은닉층을 여러 개로 만들어 쓰는 알고리즘이 존재하는데, 이러한 알고리즘을 심층 신경망이라고 한다.
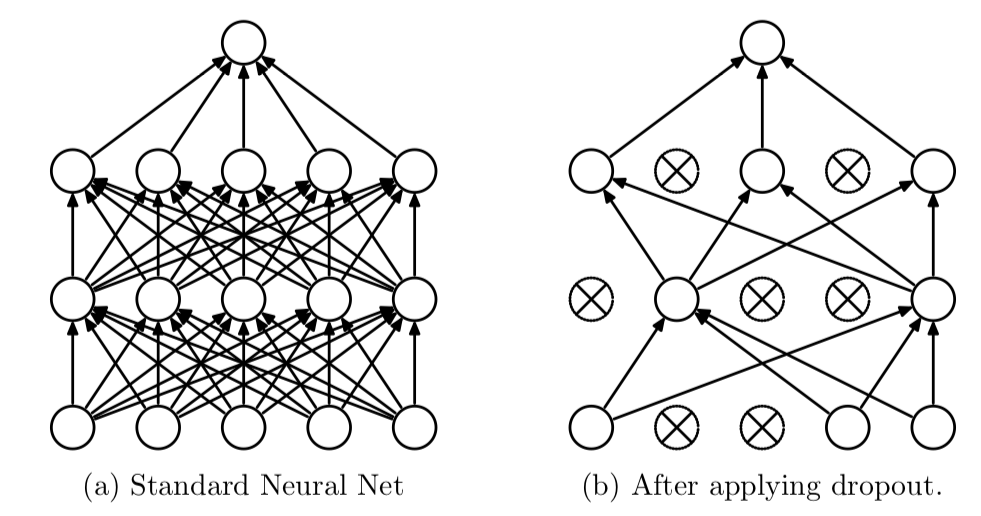
신경망의 계층을 여러 개로 만들고 데이터의 특징을 여러 차례 추출하다 보면, 더 정밀하고 정확한 판단이 가능할 것이라고 기대하는 접근 방법이다. 이전의 머신러닝 환경에서는 계층이 늘어날 때 기울기 소실(Gradient vanishing)이 발생하거나, 학습할 데이터양의 부족, 컴퓨터의 성능 부족으로 충분한 학습을 할 수 없었으나, 최근의 머신러닝에는 드랍아웃(drop out)이나 ReLU함수와 같은 기법으로 이러한 문제들을 대부분 해결할 수 있었다.
7-6. 순전파
입력층에서 출력층까지 정보가 전파되는 과정을 수식으로 표현해보고자 한다. 이러한 과정을 순전파(forward propagation)이라고 한다. 이때 MNIST 데이터는 784개의 입력값을 사용한다.

우리는 입력층의 노드가 3개, 은닉층의 노드가 2개, 출력층의 노드가 3개인 신경망을 수식으로 표현하고자 한다. 이때, 은닉층의 활성화 함수는 시그모이드를 사용하고, 출력층의 활성화 함수는 softmax를 사용한다
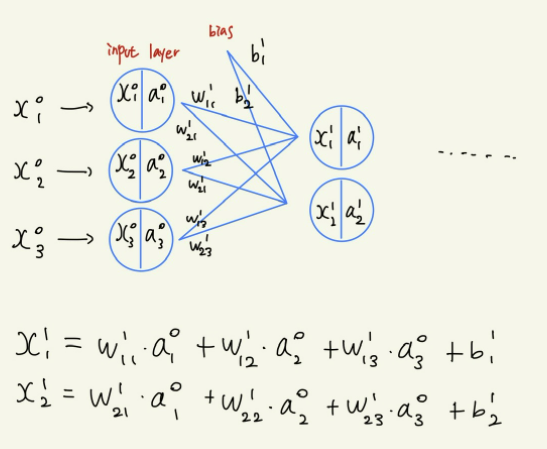
이를 행렬을 이용해 표현하면 다음과 같이 표현할 수 있다.
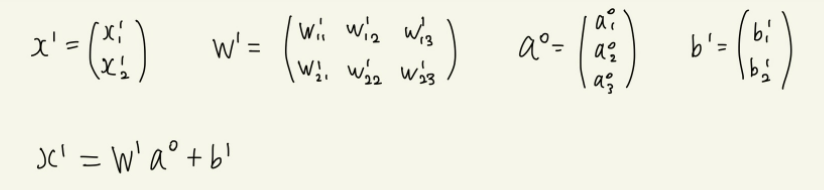
은닉층의 출력값은 다음과 같이 계산할 수 있다.
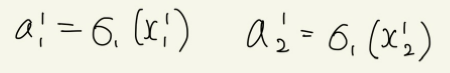
이후, 은닉층에서 출력층으로 정보가 전달되는 과정은 다음과 같다.
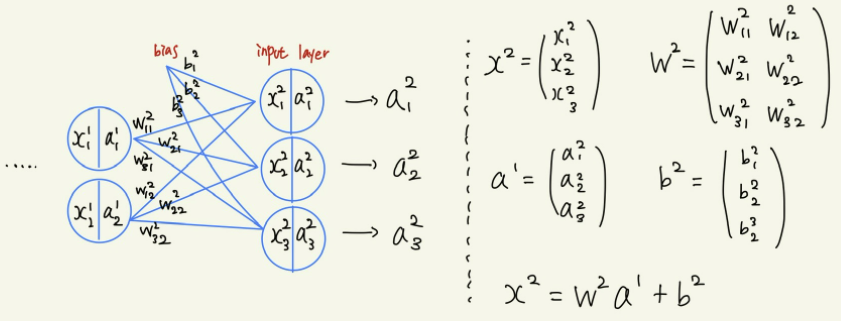
결과적으로 출력값은 비선형으로 변환된 값이 나오게 된다. 최종 출력층에서는 softmax 함수를 사용한다.
softmax 함수
n차원의 실수 벡터 x가 있다고 가정할 때, 다음 식에서 n차원의 실수 벡터 y를 결과값으로 내는 함수를 softmax 함수라고 부른다.
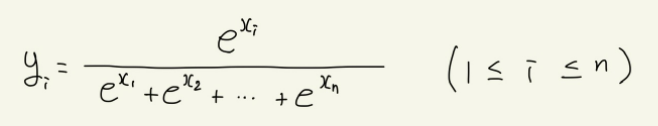
이를 사용하면 결과값을 확률적인 표현으로 만들 수 있다.
지금까지 입력층 1개에 노드는 3개, 은닉층 1개에 노드는 2개, 출력층 1개에 노드는 3개를 사용한 신경망을 예로 사용하였는데, MNIST 데이터는 입력층 1개에 노드 784개, 은닉층 2개 이상에 노드는 제 각각으로 k개, 출력층에는 노드 10개의 비교적 큰 네트워크를 사용한다.
이때 은닉층의 개수나 각 계층의 노드 수 k개는 엔지니어가 결정하는 부분. 보통 출력층으로 갈수록 노드 개수를 줄여나가는 것이 일반적이다.
은닉층에서 활성화 함수로 ReLU를 보통 사용하는 것은 Gradient vanishing 현상을 해결하기 위한 것
7-7. 손실함수
가중치와 바이어스를 조정할 때는 손실 함수의 값이 최소가 되도록 만들어 주어야 한다. 우리의 목표는 손실 함수가 최소가 되는 신경망을 만드는 것이 목표이다. 손실 함수에는 여러 가지가 있지만, 여기서는 평균제곱오차(MSE, mean squared error)를 사용한다. 그러나 보통 분류가 필요한 상황의 손실 함수로는 크로스 엔트로피를 사용한다.

만약, 3계층 신경망에서 2계층의 출력 y^2=(0.1w, 0.5w, 1-0.6*w)이고 정답 t=(0, 1, 0)일 때, 평균제곱오차는 다음과 같다.
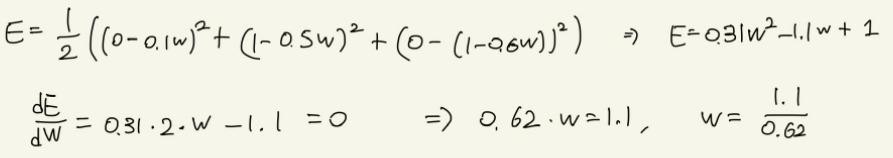
이번 MNIST 데이터를 활용한 실습에서 신경망의 출력값은 0에서 9까지의 숫자 중에서 어느 숫자에 더 가까운지에 대한 확률값이 나온다. 반면 정답 레이블은 정답 숫자만 1이고 나머지 숫자는 0으로 표현되는 one-hot으로 나오게 된다.
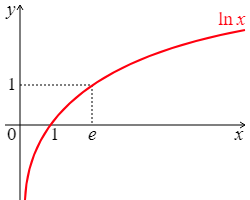
크로스 엔트로피는 다음과 같은 수식으로 표현된다.

이때, 크로스 엔트로피의 수식에 음수가 붙는 이유는 그래프와 같이 y가 1일 때 E=0이 나오고, y가 0에 가까워질수록 E의 값은 0보다 작아진다. 즉, y가 0에 가까워지면 음수가 나오는데, 이를 양수로 만들어주기 위해 마이너스를 붙이는 것이다.
이렇게 만들어진 손실함수 E를 최소화하는 가중치와 바이어스를 구하면 된다. 이때 출력층의 활성화 함수에는 Softmax를 사용해야 하는데, 이래야 출력값은 0≤y≤1 같은 확률 표현으로 나오고, 그 결과는 1이 넘지 안기에 log(y)>0 이 되는 상황이 발생하지 않는다.
7-8. 경사하강법 사용하기
이는 손실 함수가 최소가 되는 경우를 구하기 위한 것. 최솟값을 구하기 위해서는 미분했을 때 접선의 기울기가 0이 되는 방정식을 풀면 된다. 이때, 기존 MSE를 미분해서 풀게 된다면 수많은 변수가 나온다. 이러한 변수들을 모두 다루기는 어렵기에 경사하강법(Gradient Descent)를 사용해야 한다.
경사하강법은 함수의 그래프를 따라 움직이면서 기울기를 조사하고, 이때 구한 기울기의 값이 작아지는 방향으로 조금씩 내려가는 방법이다. 이는 함수의 최솟값을 근사적으로 알아내기 위한 방법이다.
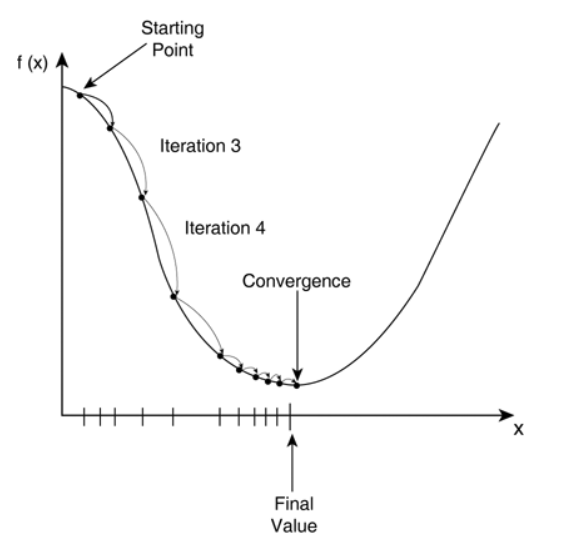
이러한 경사하강법을 수식으로 표현하면 다음과 같다.
먼저 도함수의 정의식을 다시 쓴 후,
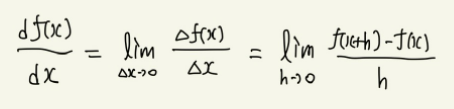
h=Δx 라고 가정한 후 식을 다시 쓰면 다음과 같이 적을 수 있다.
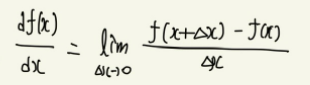
이때 Δx가 충분히 작은 값이라고 한다면, lim를 떼어버리고 다음과 같은 근사 표현을 쓸 수 있다.
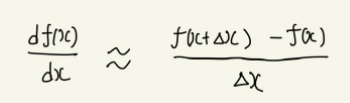
이후 양변에 Δx를 곱하면 다음과 같은 식이 만들어지는데, 이를 근사공식이라고 한다.
한편, 함수 f(x)에 대해 x에 Δx만큼의 변화를 주었을 때 f(x)의 변화량을 Δf(x)라고 한다면 다음가 같은 식이 성립하며
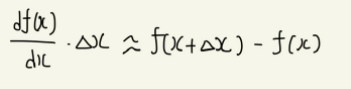
이를 위의 식에 대입하면 다음과 같은 식이 만들어진다.
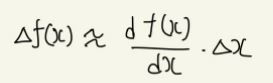
우리는 이 식에서 Δf(x)가 음이 되는 방향으로 Δx를 조금씩 이동하면서 최솟값을 찾고자 한다.
이를 위해서는 0보다 크고 1보다 작은 어떤 상수 η를 가정했을 때, 다음과 같은 수식이 성립하면 함수의 최솟값을 찾기 위해 그래프를 타고 내려갈 수 있다. 즉, Δx와 df(x)/dx의 부호가 서로 반대여야 한다.
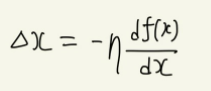
이때 η는 학습률(learning rate)로 크기를 얼마나 많이 움직이는가를 표현하는 상수이다. 너무 크면 이동하는 폭이 넓어 최솟값으로 수렴하지 못하고 건너뛰어 발산해버릴 수 있고, 너무 작으면 이동하는 폭이 좁아 경사를 하강하는 데 너무 오래 걸릴 수 있다.
그래프에서 이동하기 전의 위치를 xi라 한다면 다음과 같은 식을 만들 수 있다.
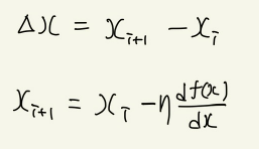
이제 이 식을 여러 개의 변수를 사용하는 다변수 함수(multivariate function)으로 생각을 하면 다음과 같은 방법으로 표현할 수 있고, 손실 함수의 최솟값을 찾기 위해 그래프를 따라 내려갈 수 있다.
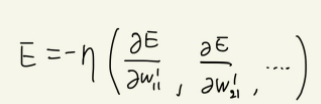
이때,
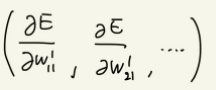
가 손실 함수 E의 기울기가 된다.
딥러닝에서 모델을 만들 때 경사하강법의 일종인 확률적 경사하강법(Stochastic gradient descent)를 사용하기도 한다. 경사하강법에서 제대로 값이 나오기 위해서는 모든 학습 데이터의 오차를 계산해야 하는데, 모든 데이터를 다루기에는 학습 시간이 너무 오래걸리거나 부작용이 발생할 수 있다. 이에 학습 데이터 중 N개의 데이터만 골라 학습시킨 후, 그 결과로 나온 손실 함수에 경사하강법을 적용하여 가중치를 구하는 방법이 있다. 이를 반복하면 N개 데이터마다 가중치를 갱신할 수 있게 되는데, 이때 처리하는 N개의 데이터 개수를 배치 사이즈(Batch size)라고 한다.
학습을 시킬 때는 학습 데이터를 몇 차례 다시 사용하면서 정확도를 높일 수 있는데, 이 반복하는 횟수를 에포크(epoch)라고 한다.
7-9. 오차역전파법
신경망의 입력치에 가중치를 곱하고, 그 값을 다음 계층으로 전달하는 과정을 반복하는 것을 순전파라고 했다. 이번에는 이 과정을 거꾸로 돌려 출력값과 정답 사이의 오차를 먼저 구한 다음에, 앞 단계의 계층으로 거슬러 올라가며 가중치를 조정할 것인데, 이를 역전파 방식(Back propagation)이라고 한다. 즉, '출력값의 오차를 기반으로 출력층에서 입력층 방향으로 가중치와 바이어스를 거꾸로 갱신해 나가는 방법'을 오차역전파법이라고 한다.
우리가 구하고 싶은 것은 함수의 기울기인 다음 식을 구하는 것으로,
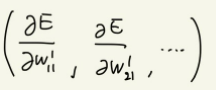
좀 더 일반화 해서
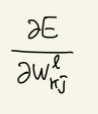
를 구하고자 한다. 이때 미분의 연쇄법칙을 사용한다.

이때 우리는 δ를 구해야 하는데, 이는 어떤 계층에 있냐에 따라 구하는 방법이 달라진다.
-
마지막 계층일 때의δ
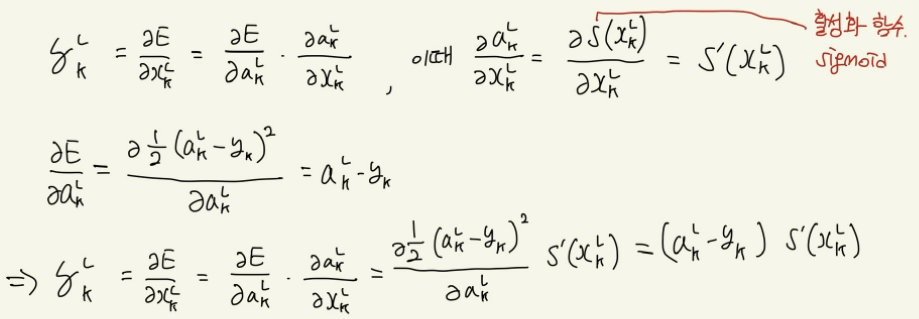
-
마지막 계층이 아닐 때의δ

즉, 정리하면 δ는 다음과 같다.
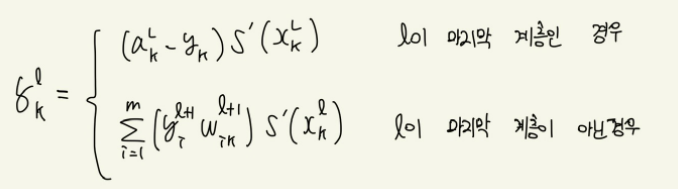
바이어스는 다음과 같다.
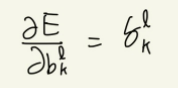

즉 정리하면 오차역전파법을 정리하면
- 1. 손실 함수를 구한 후, 그 값을 최소화 하기 위한 w와 b를 구한다.
이 과정에서 최소화하고 싶은 변수 w와 b의 개수가 너무 많아, 미분할 때 0이 되는 연립방정식을 푸는 것이 사실 어렵다.- 2. 경사하강법을 사용하여 손실 함수의 값이 작아지는 방향을 확인한다.
값을 움직일 양을 구하기 위해 미분하여 구할 값이 너무 많아 사실상 계산하는 것이 어렵다- 3. 오차역전파법을 사용하여 가중치를 결정한다.
실제로 신경망에서학습을 할 때는 배치 사이즈의 개수만큼 순전파를 하고, 경사하강법과 오차역전파법을 사용해 가중치와 바이어스를 갱신한다. 이렇게 2와 3을 반복하여 가중치 w와 바이어스 b의 근사값을 찾는다.
7-10. 완성된 모델 평가하기
홀드아웃(holdout)교차 검증법 등 다양한 방법이 있다.
드랍아웃(dropout)은 과학습을 피하기 위해 정규화를 하는 대신 사용하는 방법. 이는 무작이로 뉴런(노드)를 제거하는 방법으로 정보의 전달을 막고, 학습 데이터의 노이즈나 특징에 영향을 덜 받게 만드는 방법.