Hash Table (unordered_map)
- (key, value)로 데이터를 저장한다.
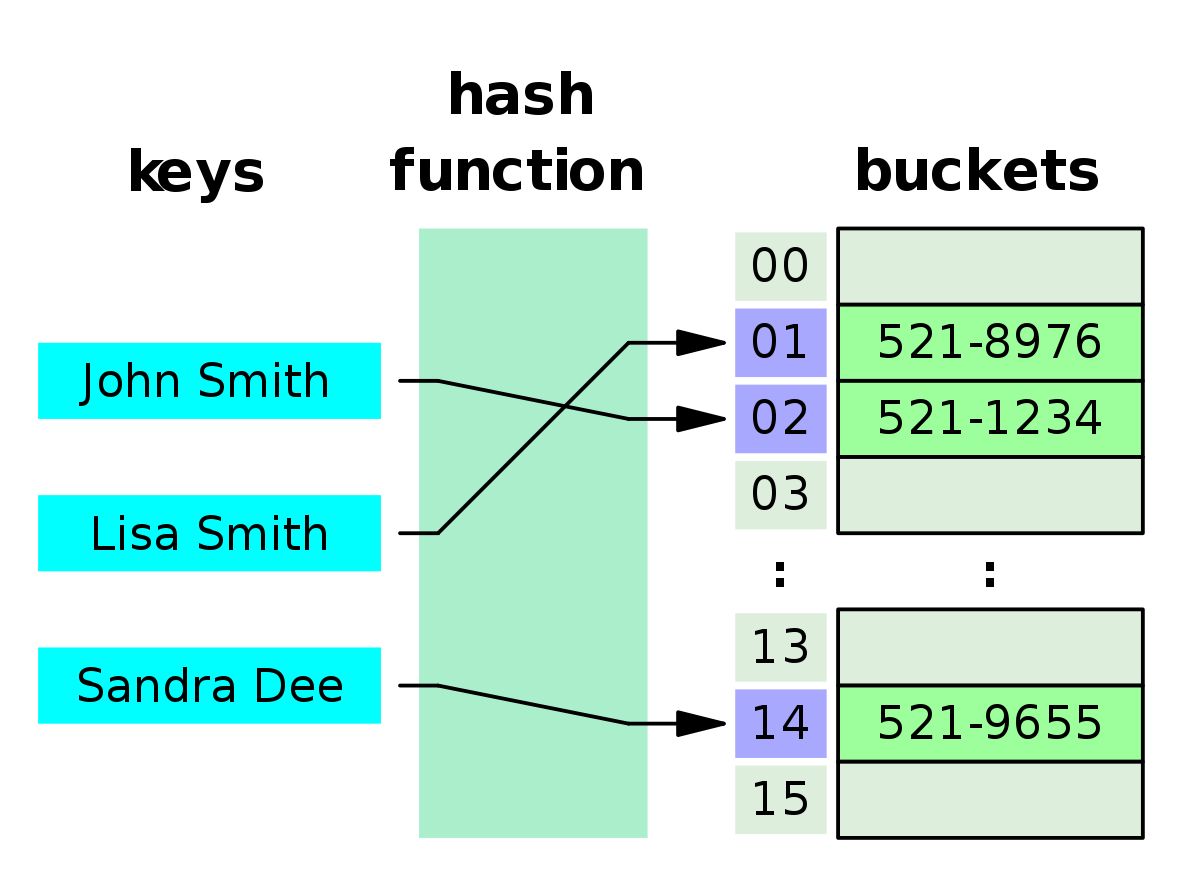
- 해시 테이블은 각각의 키값에 해시 함수를 적용하여 고유한 인덱스를 생성하고 이 인덱스를 통해 값을 저장하거나 읽는다. 여기서 실제 저장되는 공간을 bucket이라 한다.
- 추가/탐색/삭제의 시간복잡도가 O(1)로 매우 빠르다.
- 메모리를 내주고 속도를 취하는 구조
- 아파트 우편함처럼 자신만의 ID가 있어서 이를 통해 빠르게 접근할 수 있다.
- 하지만 아파트의 호수가 엄청나게 많아진다면 이걸 어느정도 늘릴지가 애매해진다.
- 충돌 문제
키값이 겹치는 경우에 충돌이 발생하는데 이럴 땐 충돌이 발생한 자리를 대신해서 다른 빈자리를 찾아나서면 된다.
- 선형 조사법 (linear probing)
hash(key) + 1 -> hash(key) + 2 충돌이 발생한 다음 자리로 간다.
- 이차 조사법 (quadratic probing)
hash(key) + 1^2 -> hash(key) + 2^2 선형 조사법보다 좀 더 분산시킨다.
- 체이닝
데이터를 연결 리스트처럼 엮어서 동일한 키 값이면 연이어서 데이터를 밀어넣는 방법
코드
void TestHashTableChaining()
{
struct User
{
int userId = 0;
string username;
};
vector<vector<User>> users;
users.resize(1000);
const int userId = 123456789;
int key = (userId % 1000);
users[key].push_back(User{ userId, "KANTAM" });
users[789].push_back(User{ 789,"FFF" });
vector<User>& bucket = users[key];
for (User& user : bucket)
{
if (user.userId == userId)
{
string name = user.username;
cout << name << endl;
}
}
}
map vs unordered_map
- map은 레드 블랙 트리로 이루어져 최악의 경우에도 시간복잡도 O(logN)을 보장하는 정도로 트리의 균형을 유지해 준다.
- unordered_map은 해시 테이블로 이루어져 시간복잡도 O(1)로 매우 빠르다.
해시 테이블의 크기만 크게 주어진다면 성능이 보장된다.
- 데이터가 많은 경우 unordered_map이 map에 비해 빠르다.
- 문자열을 키로 사용하는 경우 map이 unordered_map에 비해 빠르다.
- 유사도가 높은 문자열을 키로 사용하는 경우 unordered_map이 map에 비해 더 좋을 수 있다.
