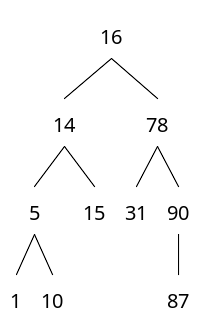
이진트리
각 노드가 최대 두 개의 자식 노드를 가지는 트리
- 이진 검색 트리의 특징
- 왼쪽을 타고 가면 현재 값보다 작다.
- 오른쪽을 타고 가면 현재 값보다 크다.
- N의 수가 엄청나게 많다면 벡터나 리스트로 이루어진 구조 O(N)보다 이진 탐색 트리가 훨씬 빠르다. 시간복잡도가 O(log N), 한번의 비교에 노드의 반을 날릴 수 있다.
트리에서 데이터 탐색
87이라는 노드가 있는지 탐색
1) 루트부터 87과 비교한다. 16보다 크므로 오른쪽
2) 78과 비교하여 크므로 오른쪽
3) 90과 비교하여 작으므로 왼쪽
4) 87과 비교하여 같으므로 탐색종료
총 4번 비교한다.
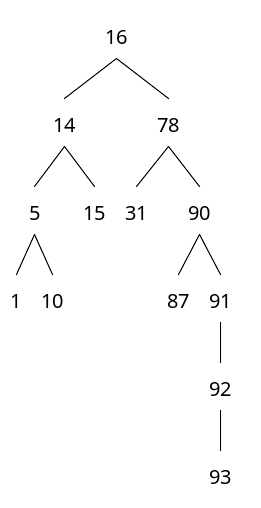
그냥 무식하게 추가만 한다면, 트리가 한쪽으로 기울어져서 균형이 깨진다. 트리 재배치를 통해 균형을 유지하는 것이 중요하다. 한번의 비교에 거의 절반을 날리는게 의의이다.
힙 트리
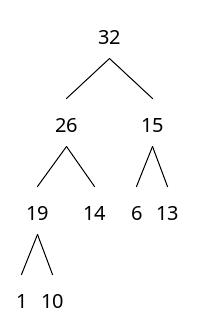
- 힙 트리 특징
- 부모 노드가 가진 값은 항상 자식 노드가 가진 값보다 크다.
- 노드의 개수를 알면, 트리 구조는 무조건 확정할 수 있다.
- 이진 탐색 트리와 마찬가지로 연산의 시간복잡도는 O(logN)
-
배열을 이용해서 힙 구조를 바로 표현할 수 있다.
1) i번 노드의 왼쪽 자식은 [(2*i) + 1]
2) i번 노드의 오른쪽 자식은 [(2*i) + 2]
3) i번 노드의 부모는 [(i-1) / 2]
(C++ 특성상 소수점 이하는 날리기에 이렇게 표현할 수 있다) -
힙 트리 구조
- 마지막 레벨을 제외한 모든 레벨에 노드가 꽉 차있다. (완전 이진 트리 이다.)
- 마지막 레벨에 노드가 있을 때는 항상 왼쪽부터 순서대로 채워야 한다.
힙에 새로운 값 추가
31이라는 노드를 추가해보자
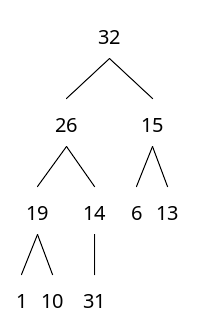
노드의 개수를 알면, 트리 구조는 무조건 확정할 수 있다.
1) 우선 트리 구조부터 맞춰준다.
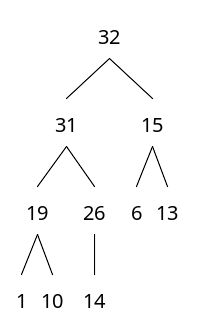
부모 노드가 가진 값은 항상 자식 노드가 가진 값보다 크다
2) 도장 깨기를 시작한다. 부모 노드와 추가한 노드와 데이터의 크기를 비교하면서 올라갈 수 있을 때까지 올라간다.
힙에서 최대값 꺼내기
힙 트리 특성상 최대값은 무조건 루트 노드에 있는 값이다.
1) 최대값(루트)를 먼저 제거한다.
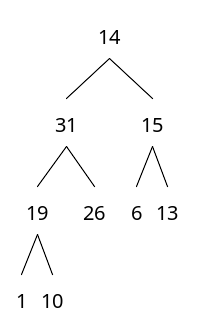
노드 개수를 알면, 트리 구조는 무조건 확정할 수 있다.
2) 제일 마지막에 위치한 데이터를 루트로 옮긴다.
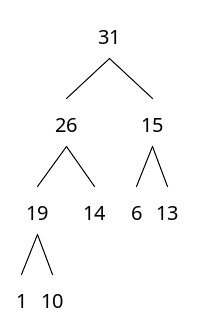
부모 노드가 가진 값은 항상 자식 노드가 가진 값보다 크다.
3) 역 도장 깨기를 시작한다. 루트로 옮겨진 노드의 자식 노드와 비교하면서 내려갈 수 있을 때까지 내려간다. 자식중에서 더 큰 값과 비교한다.
