Basic concepts
CPU I/O Burst Cycle
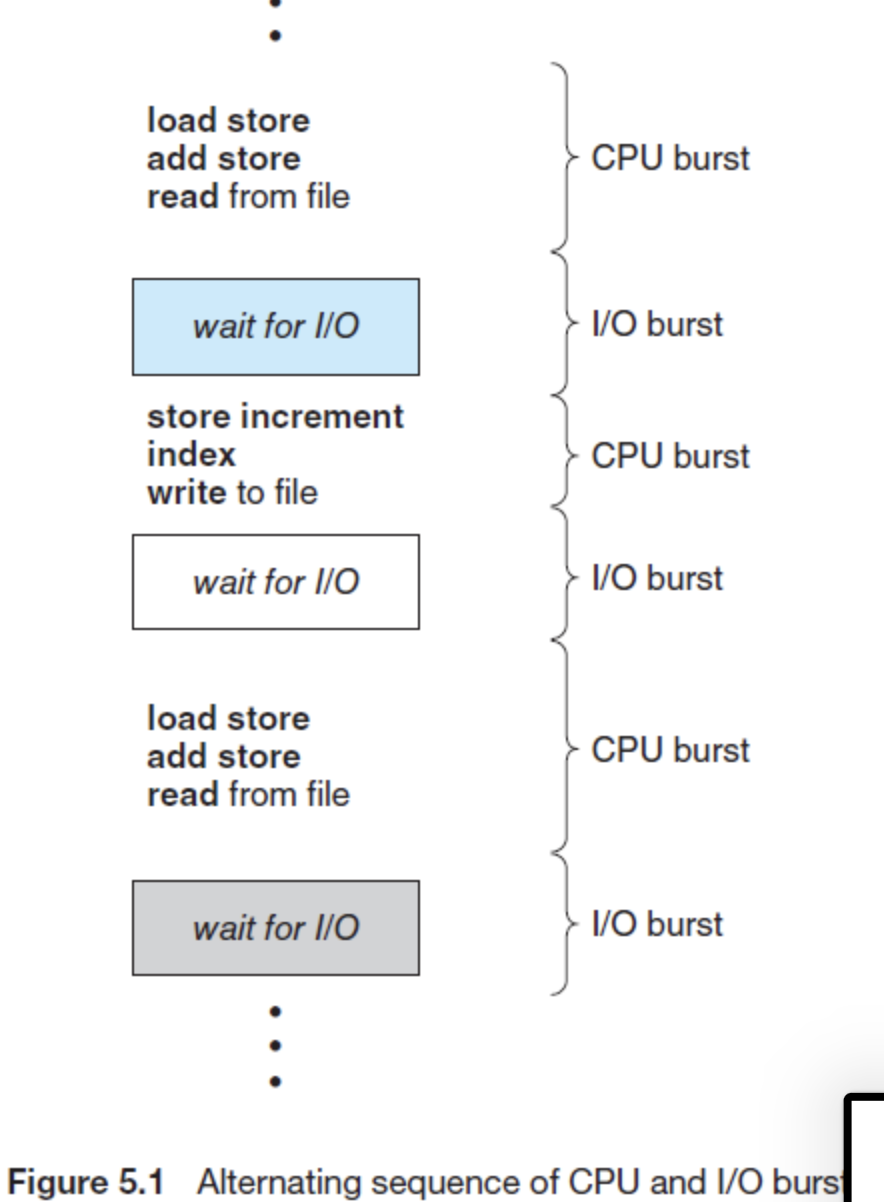
CPU → IO → CPU→ IO → CPU
프로세스 실행은 다음과 같이 CPU실행과 I/O wait의 연속인 cycle이다.
프로세스는 이 2개의 상태를 번갈아간다.
cpu busrt는 cpu 명령을 실행하는 것을 말하고
cpu burst time은 해당 프로세스의 어떤 특정 작업이 완료될때까지 필요한 cpu 이용시간을 말한다.
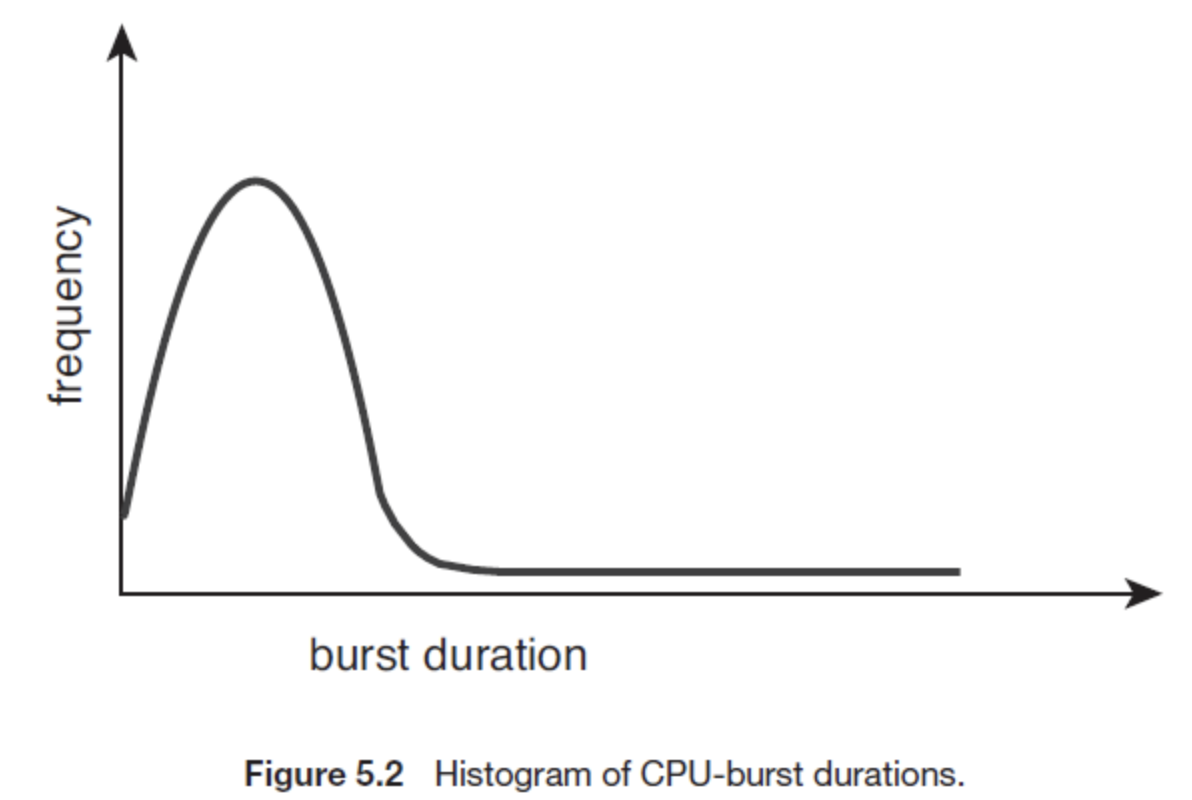
cpu burst time 경향
- 대개 short burst가 많으며
- large burst는 적은 경향을 보인다.
- 이런한 분포는 cpu 스케줄링 알고리즘 구현에 매우 중요
CPU Scheduler
Scheduler는 크게 long-term scheduler와 short-term scheduler로 나뉜다.
- Long-term scheduler는 ready 큐에 어떤 프로세스를 정할지 고른다.
- short-term scheduler(CPU scheduler)는 ready queue에서 어떠한 프로세스를 CPU에 할당할지 선택한다.
- CPU가 idle한 상태가 되면, OS는 CPU 스케쥴러를 통해, 같은 메모리(ready queue) 상에 있는 프로세스중 다음 실행할 프로세스를 선택한다.
Non-preemptive scheduling
scheduling이 필요한 상황
- 프로세스가 running 상태서 waiting 상태로 전환되는 경우(wait() by I/O request)
- 프로세스가 running 상태서 ready 상태로 전환되는 경우(interrput)
- 프로세스가 waiting 상태서 ready 상태로 전환하는 경우(I/O가 종료)
- 프로세스가 종료될때
CPU가 프로세스에 할당되면 프로세스 실행이 종료되거나 ready waiting 상태가 되기 전까지는 프로세스를 중간에 뺏는 것이 불가능
- 장점: 적은 Context-swtich 부담
- 단점: longer response time
Preemptive Scheduling
cpu에서 실행되는 프로세스를 중간에 중단시킬 수 있다.
- 장점: 낮은 response time, 효율적이다
- 단점: 많은 Context-switching overhead, race conditions(실행되는 순서에 의해 결과가 달라짐)
Dispatcher
CPU 스케쥴러에 의해 선택된 프로세스를 CPU에 부착하는 역할을 한다.
- context switching
- switching to user mode
- 프로그램 연산 재개를 위한, PCB의 Program Counter에 있는 메모리 주소로 jumping시켜준다
Scheduling Criteria
-
CPU utilization → cpu 활용도
T_total: 모든 프로세스를 다 실행시키는 시간 , T_cpu: 실제로 cpu가 사용한 시간
CPU Utilization = tcpu / t total
높을수록 좋다기 보다는 30%가 최적이다!
-
Throughput
- 주어진 unit time 동안 끝낸 프로세스 수
- 높을 수록 좋다.
-
Waiting time : 레디큐에서 대기하고 있는 시간
-
Turnaround time
프로세스를 실행하는데 걸린 총 시간(레디큐 대기시간, CPU실행시간, I/O 등에 걸린 시간 포함)
-
Response time
프로세스가 처음으로 CPU할당 받을때까지 걸리는 시간
Scheduling Algorithms
First-come, First-served Scheduling
ready queue에서 먼저 온 프로세스를 먼저 처리한다!
구현하기에 가장 간단하다.
조건: (P1, 24), (P2, 3), (P3, 3) arriving in the order of P1, P2 & P3, at time 0
time 0에 p1, p2, p3 순서로 들어왔다. (p1은 24초 걸리고, p2 3초, p3 3초 걸림)
- Gantt Chart:

- average waiting time: (0 + 24 + 27) / 3 = 27
- What if processes arrive in the order P2, P3 & P1 ?? (→ 0+3+6) / 3 = 3
→ 프로세스가 도착한 순서에 따라서, 평균 대기 시간의 편차가 크다!
→ 어떤 performance가 되든, “예측”이 어려울수록 나쁜 알고리즘이다!!!
Dicussion
cpu - burst time이 매우 다양하다면 avg. waiting time이 매우 달라진다.
- convoy effect가 발생 가능성이 있음
SJF는 preemptive, non-preemptive방식으로 나뉜다. 새로운 프로세스가 레디큐에 도달했을때, 선택을 해주면 된다.
- Non-preemptive SJF
CPU가 프로세스에게 주어지면, 이것은 실행되고 있는 프로세스가 끝날때까지 허용한다. - Preemptive SJF
새로운 프로세스가 주어질때, remaining time이 작은 것부터 선택한다. 이 방법은 Shortest-remaining-time-first(SRJF)라고 알려져있다.
Non-preemptive
- 아래와 같은 상황이 아닌 이상 process는 cpu를 계속 유지한다.
- termination
- I/O request
- incoming interrupts (p1 실행중 interrupt 발생 후 interrupt service routine이 끝나면 p1이 실행되므로 p2, p3가 실행되지 않음)
SJF (Shortest-Job-First)
smallest next CPU burst을 cpu에 할당한다. → I/O burst는 포함되지 않음
그래서 이름을 더 정확히 말하면 Shortest-Next-CPU-Burst-First라고 할 수 있다.
만약 시간이 동일할 때(동점이 발생할 때) Tie-Breaker가 필요하다.
tie-breaker의 예시로는 fcfs manner가 있다.
Given: (P1, 6), (P2, 8), (P3, 7), (P4, 3)
- Gantt Chart:
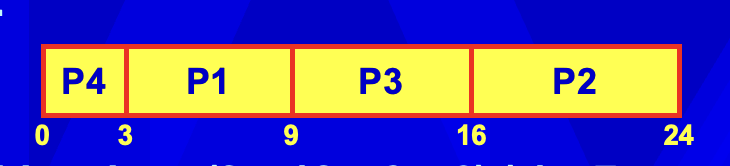
- Average waiting time: (3 + 16 + 9 + 0) / 4 = 7
Discussion
- SJF은 avg.waitint time이 작아진다는 점에서 대부분 optimal하다.
- SJF는 preemptive, non-preemptive방식으로 나뉜다. 새로운 프로세스가 레디큐에 도달했을때, 선택을 해주면 된다.
- Non-preemptive SJF
CPU가 프로세스에게 주어지면, 이것은 실행되고 있는 프로세스가 끝날때까지 허용한다. - Preemptive SJF
새로운 프로세스가 주어질때, remaining time이 작은 것부터 선택한다. 이 방법은 Shortest-remaining-time-first(SRJF)라고 알려져있다.
- Non-preemptive SJF
장단점
- 장점 : minimum average waiting time, 레디큐의 크기도 줄어들며, 전반적인 공간 사용량도 줄어든다. Fast response time
- 단점 : Starvation. Long process는 짧은 녀석들이 없어질 때까지 CPU할당을 받지 못한다. aging으로 해결 가능하다.
FCFS, SJF → 안쓴다.
Priority Scheduling → linux에서 쓴다.
프로세스 마다 우선순위를 부여한다. 작은 숫자일 수록 높은 우선순위를 의미한다.
높은 우선순위를 가진 프로세스가 cpu에 할당된다.
→ sjf 알고리즘은 cpu burst가 짧은 경우 높은 우선순위를 제공한다.
In UNIX/LINUX, it is called the “nice” value
- Given: (P1, 10, 3), (P2, 1, 1), (P3, 2, 3), (P4, 1, 4), (P5, 5, 2)
- Gantt Chart:

- Average waiting time: (0 + 1 + 6 + 16 + 18) / 5 = 8.2
Ways of Determining Priorities → 우선순위 따지는 법
- Internally defined priorities time limits, memory requirements: 메모리 사용량, # of open files: 열린 파일 개수
- unix →> “Accumulated CPU-use time” cpu를 많이 쓸수록 우선순위 가 낮다.
- externally defined priorities
- importance of process
Discussion
- preemptive, non-preemptive할 수 있다. 프로세스가 레디큐에 새로오면, 현재 진행중인 프로세스와의 우선순위를 비교할 수 있다.
- preemptive priority면, 만약 새 프로세스의 우선순위가 높다면, 진행중인 프로세스를 중단하고 새 프로세스를 CPU에 전달할 것이다.
- Non-preemptive의 경우 새로운 프로세스를 레디큐에 그냥 넣을 것이다.
문제점
우선순위 방식의 가장 큰 문제점은 starvation이다. 즉, 우선순위가 매우 낮은 프로세스들은 CPU할당을 받기 매우 어렵다. 이를 해결하기 위해서는 aging이라는 방법이 있으며, 기다릴수록 우선순위를 높여주는 방식이다.
- solution → aging
시간이 지날수록 우선순위를 증가시킨다. → 많은 OS에서 이것을 선택
Round-Robin
기본적인 알고리즘을 매 Q마다 실행!
Round-Robin 알고리즘은 FCFS와 유사하나, preemption이 프로세스 교환할때 사용되는 것이 큰 차이점이다. time-quantum 또는 time-slice라 불리는 시간단위가 정의
레디큐를 FIFO 큐로 취급하면서, CPU 스케쥴러는 이 레디큐를 time quantum만큼 각 프로세스를 할당한다.
위 3개 프로세스 중에 priority scheduling을 하여 순서를 결정한다. (but 이책에서는 fcfs)
- Gantt Chart:

- Average waiting time: (6 + 4 + 7) / 3 = 5.66
→ 매우 큰 “Context Switch Overhead”를 고려할 필요가 있다.
근데 이걸 왜 쓸까? 하드웨어 덕분에 context switch로 인한 오버해드가 상당히 적어졌다.
Rule-of-thumb은 보통 CPU burst의 80프로보다 time quantum이 작아야한다. Piroiry Scheduling은 또한 preemptive, non-preemptive할 수 있다. 프로세스가 레디큐에 새로오면, 현재 진행중인 프로세스와의 우선순위를 비교할 수 있다. preemptive priority면, 만약 새 프로세스의 우선순위가 높다면, 진행중인 프로세스를 중단하고 새 프로세스를 CPU에 전달할 것이다. Non-preemptive의 경우 새로운 프로세스를 레디큐에 그냥 넣을 것이다.
Discussion
이 time quantum이 어느정도가 optimal한가?
RR의 성능은 Q의 사이즈에 많이 영향을 받는다.
- Q가 너무 크면 RR은 FCFS이다.
- Q가 너무 작으면 RR은 precessor sharing(virtual CPU)가 됨
100개 프로세스 중에 80개의 cpu burst가 Q보다 작아야한다!
장단점
- Average turnaround time(수행시간)이 높다.
- response time이 짧아서, Interactive/time-sharing한 시스템에 적합하다
- context swtich로 인하여 CPU독점을 막는다. 하지만 너무 빈번이 일어나면, overhead가 커진다.
Multilevel Queue
Priority, RR방식 모두 단일 큐를 사용
우선순위 기준이 다른 분리된 큐들을 두어서, 그 우선순위에 맞게 스케쥴링을 하는 것이 훨씬 쉬울 것이다. 이러한 접근방법을 multilevel queue라 한다.
process can move between queues → 프로세스가 queue를 이동할 수 있다.
만약 어떤 프로세스가 cpu를 많이 사용했다면 아래 큐로 이동한다.
어떤 프로세스가 오래 기다리고 있다면 aging을 적용하여 높은 큐로 이동한다.
→ forms of aging: prevents starvation
프로세스들을 프로세스 타입에 따라 다른 큐들에 분리할 수 있다. Foreground(interactive), Background(batch)프로세스로 분리할 수 있으며, 다른 스케쥴링 방식을 필요로한다. 각각의 큐들은 다른 스케쥴링 알고리즘을 사용할 수 있다
