[BEB] Section3 : 분산원장 / Segwit / 머클트리와 머클루트 / 블룸필터 / 탭루트 / 보안성을 위한 시도들 / Prunning
코드스테이츠 BEB 블록체인 과정
분산원장 개요
🔥분산 데이터베이스란?
분산 데이터베이스는 하나의 데이터베이스 관리 시스템(DBMS, Database Management System)이 여러 CPU에 연결된 저장장치들을 제어하는 형태의 데이터베이스이다. 물리적으로 동일한 위치에 여러 대의 컴퓨터로 구성된 경우 또는 컴퓨터 네트워크를 통해 상호 연결된 컴퓨터로 분산되어 있는 구성 등을 말한다.
🔥분산 데이터베이스의 장단점
분산 데이터베이스는 기본적으로 다음 두가지 특징을 가진다.
- 분산은 투명하다. 사용자는 하나의 논리체계인것 처럼 상호 작용할 필요가 있다. 이를 통해 성능이나 사용방법 등 여러가지 면에 적용된다.
- 트랜잭션은 투명하다. 각 트랜잭션은 다중 데이터베이스에 걸쳐 일관성을 보장해야한다. 트랜잭션은 일반적으로 여러 하위 트랜잭션으로 분리된 개별 서브 트랜잭션이 하나의 데이터베이스에 대응한다.
이 특징으로 인해 다음과 같은 장단점을 가진다.
장점
- 조직 구조의 반영: 기업 등 부문별로 데이터베이스를 놓고 그들을 통합하여 분산 데이터베이스로 할 수 있다.
- 국소 자율성: 각 부서는 자체 보유한 데이터를 제어할 수 있다.
- 중요한 데이터의 보호: 화재 등의 재해가 발생했을 때 데이터가 분산되어 있으면 전체를 한 번에 잃는 것을 예방할 수 있다.
- 성능 향상: 자주 사용하는 데이터는 가까운 위치에 있으면서, 전체가 병렬적으로 작동하기 때문에 데이터베이스의 부하 분산이 가능하다. 일부가 과부하 되어도 분산 데이터베이스 전체에 미치는 영향이 작다.
- 경제성: 거대한 고성능 컴퓨터보다 동일한 정도의 성능을 발휘하는 소형 컴퓨터 네트워크 쪽이 싸다.
- 모듈화: 분산 데이터베이스의 다른 모듈(시스템)에 영향을 주지 않고 개별 시스템을 갱신, 추가, 삭제할 수 있다.
- 높은 신뢰성의 트랜잭션: 모든 거래는 ACID 특성에 따른다.
단점
- 복잡성: 간단한 데이터베이스보다 복잡하다. 또한 접속이 끊어졌을 때의 동작도 고려할 필요가있다. 예를 들어 결합을 여러 시스템간에 할 경우 성능 저하가 예상된다.
- 비용: 시스템의 규모와 복잡성이 증가함에 따라 관리 비용도 증가한다.
- 보안: 개별 사이트의 보안을 확보하고, 사이트 간 네트워크의 보안도 확보해야 한다
- 무결성 보장의 어려움: 분산 데이터베이스 무결성을 보장하려면 상당한 네트워크 자원을 필요로한다.
- 미성숙한 기술: 분산 데이터베이스는 미성숙한 분야이며, 경험적 지식의 축적이 적다.
- 표준의 부족: 중앙 DBMS를 분산 DBMS로 변환하기위한 도구와 방법론은 아직 존재하지 않는다.
- 데이터베이스 설계의 복잡성: 일반 데이터베이스 설계 이외에, 데이터를 각 사이트에 어떻게 배치하거나 복제를 어떻게 할 것인가 등 설계시에 고려해야 할 사항이 늘어난다.
- 추가 소프트웨어를 필요로한다, 운영 체제가 분산 컴퓨팅을 지원해야 한다, 동시성 제어가 중요하다.
🔥분산원장 기술의 이해
분산원장 기술(DLT, Distributed Ledger Technology)은 복제, 공유 또는 동기화된 디지털 데이터에 대한 합의 기술이다. 분산원장을 통해 저장된 데이터들은 중앙집중된 관리자나 중앙집중의 데이터 저장소가 존재하지 않고 P2P(Peer-to-Peer)네트워크에 분산하여 참가자가 공동으로 기록하고 관리하기 때문에 당연히 노드 간 복제 데이터에 대한 합의 알고리즘이 수행된다. 이런 설계중 하나의 기술로써 블록체인이 존재한다.
블록체인은 단지 분산원장기술을 구현하기 위한 하나의 데이터 구조일 뿐 모든 분산원장 기술이 블록의 체인을 만들 필요는 없다.
기존 중앙집중형 시스템과 한계점
기존 중앙집중형 시스템에서 대다수 자산에 대한 소유권은 실물 보관 여부와 무관하게 특정한 기관에서 관리하는 원장(Ledger)에 기록된 바에 따라 결졍되었다.이같은 방식은 자산을 직접 보관하는 방식에 비해 비용을 절감하고 소유권을 명확히 할 수 있는 장점을 가지는 반면, 기록을 관리하는 권한과 책임이특정 기관에 집중되어 제3의 기관에 대한 신뢰에 크게 의존하는 한계가 있다.
신뢰성을 보장하기 위해서는 감독과 감시등 규제를 제도화 해야했고, 이런 규제 및 감독은 혁신적인 신규 서비스 및 사업자의 진출을 제한한다. 또한 중앙화된 데이터는 공격지점이 집중되어 있기 때문에 IT인프라와 보안 등에 대해 대규모 인력 및 설비를 투자해야 한다. 이렇게 제3의 기관을 설립하여 운영하는 데 소요되는 높은 사회적 비용은 산업 발전의 제약 요인으로 작용할 수 있다.
장점
분산원장 기술은 모든 기록이 집중된 제3의 기관이 없기 때문에 기존 중앙집중형 시스템에 비해 다음과 같은 장점을 가질 수 있다.
- 효율성(Efficiency): 신뢰할 수 있는 제3의 기관을 설립·운영하기 위한 인력 및 자원 투입이 불필요하고 시스템 오류 등을 예방하고 해킹 등 보안사고를 방지하기 위한 인프라 투자비용도 절감 가능
- 보안성(Security): 모든 정보가 집중된 중앙 서버가 없고 이를 담당하는 조직도 존재하지 않기 때문에 해킹 등 내·외부의 악의적인 공격으로부터 안전함. 원장이 모든 참가자에게 공개되기 때문에 원천적으로 정보 유출 소지가 없음
- 시스템 안정성(Resilience): 단일 실패점(single point of failure)이 존재하지 않기 때문에 일부 참가 시스템에 오류 또는 성능저하가 발생하더라도 전체 네트워크에 미치는 영향이 미미
- 투명성(Transparency): 분산원장 기술은 모든 거래기록을 공개하기 때문에 높은 투명성을 가지며 거래 추적이 용이하고 규제(고객확인의무: Know Your Customer 등) 준수 비용도 낮음
단점
분산원장 기술에서는 신뢰를 담보해 줄 외부 기관 등이 존재하지 않기 때문에 시스템 자체에서 신뢰를 형성하는 메커니즘을 설계할 필요가 있다.
- 분산원장 기술에서는 모든 참가자가 새로운 거래를 반영하여 원장을 갱신하는 권한과 책임을 갖고 있기 때문에 특정 내부 참가자가 악의적으로 원장을 조작하여 배포하는 것을 방지할 필요가 있다
- 비트코인 개발 이전까지 분산원장 기술을 지급결제시스템 및 여타 금융서비스 등에 실제로 적용하지 못했던 것은 조작 가능성을 차단하면서 원장을 갱신할 수 있는 합의(Consensus) 절차를 마련하지 못했기 때문
분산원장 기술과 블록체인
🔥블록체인은 합의가 있는 분산원장 기술
합의가 있는 분산원장 기술이 블록체인이다.
- 블록체인(blockchain)기술은 과거의 거래기록부터 현재까지의 거래기록들을 블록으로 연결하여 과거의 기록에 대한 위변조 등의 불가능하고 해킹 시도를 방지하는 기술을 의미한다. 블록체인은 시간의 흐름을 따라서 수직적으로 연결된다.
- 블록체인은 분산원장에서 필요로 했던 인증기관 문제를 합의 알고리즘과 채굴, 노드로 해결했다. 즉 합의가 있는 분산원장 기술중 하나가 블록체인이라 볼 수 있다.
블록체인 도입을 위한 기술적 해결 과제
블록체인이 금융 서비스에 적용되기 위해서는 거래 비밀성, 권한 통제, 확장성 확보 등의 기술적 과제가 아직 남아있다.
블록체인에 저장되는 정보는 개인 정보이기 때문에 소유자와 합의된 관리자만 거래 내역에 접근이 가능해야 하고, 신뢰와 보안 유지를 위해서는 비트코인과 같은 퍼블릭 블록체인을 도입하는 것도 고려해야 한다.
💡 아이러니 하게도 신뢰및 보안에 관한 이슈도 있는데 스마트 계약을 분산원장기술과 결합해서 사용할 경우, 소프트웨어 자체의 오류 혹은 의도적인 디도스 공격으로 스마트 계약이 무효화되는 등의 위험성에 대해서 아직 검증된 바가 없다.
또한 실제 사용이 가능하게 하기 위해서는 적어도 초당 3,000건 이상 처리할 수 있는 성능을 보유한 블록체인이 필요하다.
금융권의 입장에서 가장 중요한 점은 대량의 거래 데이터를 신속하고 안전하게 처리하는 것이다. 블록체인 기반의 분산 원장 기술을 금융 서비스에 도입하는 것은 인프라 구축 비용 절감, 거래 효율성 증가, 안전성 향상 등의 측면에서 많은 이점이 있다. 하지만 위에 설명한 기술적 과제 해결이 우선이다.
거래 가변성과 Segwit
세그윗(SegWit) 이란 Segregated Witness의 약자로서, 비트코인의 블록에서 디지털 서명 부분을 분리함으로써 블록당 저장 용량을 늘리는 소프트웨어 업그레이드를 말한다.
💡 2017년 8월 1일을 기준 비트코인은 세그윗이라는 소프트포크를 진행하였다. 기존의 비트코인은 거래내역을 기록하는 블록 크기가 1MB에 불과하여 초당 7건, 하루 최대 60만건의 거래내역밖에 처리하지 못하는 한계가 있었는데, 이 문제를 해결하기 위해 비트코인 블록에서 디지털 서명 부분을 분리하여 별도로 저장함으로써, 블록당 저장 용량을 늘릴 수 있게 되었다.
한편, 세그윗을 진행할 경우 중국의 채굴업자들이 사용하던 에이식부스트(AsicBoost : 비트코인채굴 속도를 약 20% 정도 높이는 방법 ) 방식의 비트코인 채굴이 불가능해지게 되기 때문에, 중국의 채굴업체들을 중심으로 기존 에이식(ASIC) 채굴기를 사용한 비트코인 채굴을 지속하기 위해 기존 비트코인 체인에서 분리된 비트코인캐시(BCH, Bitcoin Cash)라는 이름의 새로운 암호화폐를 생성하였다. 암호화폐의 채굴자와 보유자의 이해관계가 상충되어 일어난 하드포크이다.
🔥특징
거래 속도의 확장성(Scalability)
비트코인은 현재 기술력으로 1초에 7개의 거래를 성사시킨다.
💡 마스터 카드와 같은 금융기관은 1초에 수백만 건의 거래를 성사시킴.
확장성 문제를 해결하지 못해 초당 7개의 거래를 처리한다면, 전 세계 사람들이 이용하는 경우 하나의 거래를 처리하는 데 몇 년이 걸릴 수 있기 때문에 이를 반드시 해결하지 않고선 비트코인의 대중화는 어렵다. 이 확장성 문제를 해결하기 위해 세그윗을 사용한다.
거래하기 위해서는 신원을 증명하기위해 거래를 하는 당사자의 서명이 필요하다. 이 디지털 서명은 돈을 보내는 사람의 개인 키로 암호화한 메세지를 돈을 받는 사람이 돈을 보내는 사람의 공개키로 해석하여 돈을 보내는 사람이 맞는지 신원을 확인하고 증명하는 것이다.
블록의 구조를 보면 디지털 서명란과 거래 내역이 하나로 뭉쳐 있다. 서명란에 서명이 실제로 차지하는 크기는 크지 않지만, 서명란 자체가 차지하는 부피가 크다. 이런 문제를 확장성 문제라고 하고 블록의 크기를 1MB 내외로 유지하면서 거래를 처리할 수 있는 속도를 더 빨리할 수 있는 방법이 세그윗이다. 세그윗은 서명 부분을 따로 Witness라는 데이터 영역으로 분리해 더 많은 거래를 처리할 수 있도록 업데이트한다.
세그윗은 블록에 불필요한 부분(서명란)을 줄여 블록의 크기를 줄인다. 블록의 불필요한 부피가 줄어들면, 더 많은 트랜잭션을 블록에 담을 수 있다.
단순히 블록의 크기를 키우는 것도 방법이 될 수 있지만 그것을 감당할 수 있는 해시파워가 전 세계적으로 많지 않아 탈중앙화라는 블록체인의 특성에 맞지 않는다. 따라서 블록 크기를 유지하면서 블록 내부의 내용을 업데이트하는 걸로 해결한다.
비트코인 개발에 큰 공헌을 한 할 피니(Hal Finney)는 사토시에게 블록의 크기를 제한하지 않으면, DDoS 같은 공격에 취약하다고 말하며 그에게 1MB의 블록 크기를 제안했다
거래 가변성(Transaction Malleability)
모든 비트코인 거래에는 해당 거래를 식별할 수 있는 거래의 ID(transaction ID : txid)를 포함한다. txid가 'ID'라면 txid를 따라다니는 전자서명은 '비밀번호'라고 할 수 있다. 거래 가변성은 실질적인 거래 내용에는 변화가 없지만, 거래 ID(txid)만 변경하여 새로운 거래를 만들어 낼 수 있는 일종의 버그이다.
즉, 거래 ID는 한 사람에게 하나만 주어지는 것이 원칙이지만, 두 개 이상의 거래 ID로 서로 다른 거래처럼 보이지만 실제 거래 내역은 동일한 거래를 가질 수 있는 것이 가변성의 문제이다. 가변성의 문제를 세그윗이 이 txid를 따로 보관하고 관리함으로써 여러 개의 ID를 가지고 동일한 거래 내역 여러 개를 만드는 것을 막을 수 있다.
버전 호환
세그윗은 소프트포크이므로 비트코인 소프트웨어의 업그레이드를 하지 않아도 세그윗 이전과 세그윗 적용 버전을 모든 노드에서 사용할 수 있다. 세그윗 미적용 노드 비트코인 코어 기준 0.13.1 이전은 1MB 이상의 블록은 읽을 수 없다. 하지만 거래의 중요한 입출력 내용은 1MB 이내에 들어 있기 때문에 호환이 가능하다. 서명 부분이 빠져있기 때문에 구버전의 노드는 이를 검증하지 않고 그냥 받아들이지만, 세그윗이 가능한 버전의 노드들이 이를 증명해주기 때문에 문제가 되지 않는다.
장점
- 용량 증가
세그윗의 가장 큰 장점 중 하나는 블록 용량 증가이다. 트랜잭션 입력값에서 서명 데이터를 제거함으로써, 더 많은 트랜잭션이 단일 블록에 저장될 수 있게 되었다.
세그윗이 없다면 서명 데이터가 단일 블록의 65%까지 차지할 수 있다. 세그윗을 사용함으로써 실질 블록 크기는 1MB에서 4MB까지 증가한다. 세그윗을 통해 실제 블록 크기가 증가하는 것은 아니다. 세그윗은 블록 크기 제한(하드 포크가 필요함)을 늘리지 않고, 실질 블록 크기를 늘리는 기술적 해결책이다. 보다 명확하게 말하자면, 실제 블록 크기는 여전히 1MB이지만, 유효한 블록 크기 제한은 4MB이다.
세그윗은 또한 블록 무게라는 개념을 도입했다. 기본적으로 블록 무게는 모든 블록 데이터를 포함한 것으로, 트랜잭션 데이터(1MB)와 더는 입력 영역의 일부가 아닌 서명 데이터(최대 3MB)가 포함한다.
- 트랜잭션 속도 증가
더 많은 트랜잭션을 저장할 수 있는 블록을 통해 세그윗은 트랜잭션 속도를 증가시킨다. 하나의 블록을 마이닝 하는 데는 동일한 시간이 소요될 수 있지만, 하나의 블록 안에서 더 많은 트랜잭션이 처리될 수 있으며, 따라서 TPS가 증가한다. 트랜잭션 속도가 증가하면 비트코인 네트워크 트랜잭션 수수료 절감에도 도움이 된다. 세그윗 전에는 하나의 트랜잭션에 30달러 이상을 지출하곤 했다. 그러나 세그윗은 트랜잭션당 수수료를 1달러 미만으로 대폭 절감시켰다.
- 트랜잭션 가변성 해결
비트코인의 주된 문제는 잠재적으로 트랜잭션 서명을 조작할 수 있다는 것이었다. 서명이 변경되면 두 당사자 간의 트랜잭션에 오류가 생길 수 있다. 블록체인에 저장된 데이터는 사실상 불변하는 것이기 때문에, 유효하지 않은 트랜잭션이 블록체인에 영구적으로 저장될 수 있었다.세그윗을 사용하면 서명이 더 이상 트랜잭션 데이터의 일부가 아니기 때문에 해당 데이터를 변경할 수 없다. 이러한 해결책은 블록체인 커뮤니티 내에서 세컨드 레이어 프로토콜과 스마트 컨트랙트와 같은 추가적인 혁신이 이뤄질 수 있게 했다.
머클 트리와 머클 루트
머클 트리(Merkle tree) 의 개념은 80년대 랄프 머클(Ralph Merkle)이 제안했다. 머클 트리는 일련의 데이터 온전성을 효과적으로 검증하는 데 사용되는 구조이다. 이는 특별히 피어 투 피어 네트워크 맥락에서 참가자가 정보를 공유하고 독립적으로 검증해야 하는 경우와 관련된다. 머클 트리 구조의 핵심에는 해시 함수가있다.
커다란 파일을 다운로드하려고 한다고 가정해보자. 오픈 소스 소프트웨어를 통해, 다운로드하고자 하는 파일의 해시가 개발자에 의해 공개된 것과 일치하는지 확인해서 두 해시가 일치한다면, 컴퓨터에 존재하는 파일이 파일이 개발자들의 것과 정확히 일치한다고 말할 수 있다.
만약 해시가 일치하지 않는다면, 무언가 문제가 있는 것이다. 소프트웨어로 가장한 악성 파일을 다운로드 했거나, 혹은 파일이 제대로 다운로드 되지 않았을 수 있으며, 때문에 이는 제대로 작동하지 않을 것이다.
머클트리의 원리는 위의내용에 기반한다. 머클 트리를 이용하면 간단하고 효과적으로 이를 검증할 수 있다.
머클 트리로 파일을 덩어리로 분리한다 파일이 50GB였다면, 100개의 조각으로 나뉠 수 있다. 이렇게 조각낸다면 한 조각의 크기는 각 0.5GB 이다. 이후 파일은 조각별로 다운로드된다.
이런형태의 다운로드는 토렌트에 파일을 공유할때 해당함.
이렇게 파일을 다운로드 하면, 이 자료는 머클 루트(Merkle root)라 하는 해시를 제공한다. 이 단일 해시는 파일을 구성하는 모든 데이터 덩어리를 나타낸다. 그리고 머클 루트를 사용하면, 훨씬 간단하고 효과적으로 데이터를 검증할 수 있다.
🔥머클 트리의 동작 원리
보다 원활한 이해를 위해, 8GB 파일을 여덟 조각으로 나눠 사용하는 경우를 살펴보자. 서로 다른 조각들에 A부터 H까지 이름을 붙였다. 이후 각 조각들은 해시 함수를 통과하여 8개의 다른 해시를 제공한다.

이렇게 생성된 8개의 해시를 다시 2개씩 묶어 해싱한다. hA + hB, hC + hD, hE + hF, hG + hH를 해싱하면, 네 개의 해시를 가지게 됩니다. 이 방식을 반복해 마지막 하나의 해시, 머클 루트(또는 루트 해시)를 얻을 수 있다.
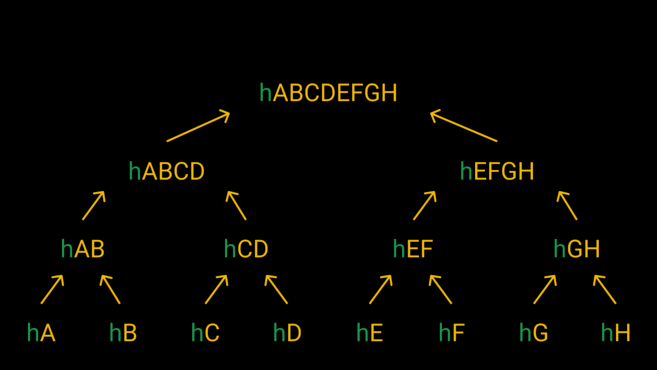
이 방식대로 생성한 머클 루트를 이용해 다운로드한 파일이 나타내는 머클 루트와 자료를 제공하는 사람이 함께 담아 보낸 머클 루트를 비교할 수 있다. 두 머클 루트의 해시값이 동일하다면, 모든 파일을 안전하게 전달받았다고 할 수 있다. 만약 두 해시값이 다른 값을 나타낸다면, 데이터가 위변조되었을 수 있다고 확신할 수 있다.
해시함수의 특징에 의해, 어느 하나의 데이터 조각이라도 조금만 위변조되면 전혀 다른 머클 루트를 가지게 됨
만약 파일을 전송받는 과정에서 어느 한 데이터에 변경이 생겼다면, 모든 파일 조각을 처음부터 다시 다운로드해야 할까? 머클 트리를 사용하면, 데이터에 변경이 일어난 파일 조각을 찾고, 그 파일만 새롭게 다운로드 받을 수 있다.
위 그림에서 hE에 결점이 있다고 해보자. 한 부분에 결점이 있으므로, 파일을 다운로드 한 뒤 생성한 머클 루트와, 전달받은 머클 루트의 해시값이 다를 것이다. 이 경우, 파일을 전달한 피어(peer)에게 머클 루트(hABCD와 hEFGH)를 생성하는 두 개의 해시를 요청할 수 있다. 전달받은 두 개의 해시값 중에서, hEFGH에 문제가 있다는 것을 확인할 수 있고, 이런 방식을 반복해 hE의 데이터에 변경이 있었다는 걸 확인할 수 있다. 마지막으로 hE를 해시한 파일 조각만 다시 다운로드하면, 파일 전송을 보다 효율적으로 할 수 있게 된다.
요약하자면 머클 트리는 데이터를 여러 조각으로 나누며 생성되며, 머클 루트를 형성하기 위해 반복적으로 해시화된다. 이후 데이터 조각이 잘못된 경우, 이를 효과적으로 검증할 수 있다.
🔥머클 트리와 비트코인
머클 트리는 비트코인과 다른 많은 암호화폐에 필수적인 요소이다. 머클 루트는 블록 헤더에서 찾을 수 있는 각 블록의 필수 요소이다. 머클 트리의 잎(leaf; 트리의 종단)을 얻기 위해, 블록에 포함된 모든 트랜잭션의 트랜잭션 해시(TXID)를 사용한다. 머클 루트가 암호화폐 마이닝(채굴)과 트랜잭션 검증에 어떻게 적용되는지 살펴보자.
마이닝(채굴)
블록체인은 두 가지 요소로 구성되어 있습니다. 하나는 블록 헤더이며, 이는 블록의 메타데이터를 포함하는 고정된 크기 요소이다. 다른 하나는 사이즈가 가변적인 트랜잭션 목록이며, 보통 헤더보다 더 큰 경향이 있다.
마이너는 유효한 블록을 마이닝하기 위해 특정 조건에 부합하는 결괏값을 생성하기 위해 데이터를 반복적으로 해시화해야 합니다. 마이너들은 이를 찾기 위해 수 조 번의 시도를 할 수 있다. 각각의 시도마다 마이너들은 블록 헤더의 임의의 숫자(논스, nonce)를 변경한다. 그러나 블록의 다른 부분은 동일하게 유지된다. 수천 개의 트랜잭션이 존재할 수 있으며, 매번 이를 해시화해야 한다.
머클 루트는 이러한 과정을 크게 간소화시킨다. 마이닝을 시작할 때, 머클 트리에 포함하고 구성하려는 모든 트랜잭션을 정렬한다. 루트 해시(32바이트) 결과를 블록 헤더에 집어넣는다. 이후, 블록을 마이닝할 때는 전체 블록 대신 블록 헤더만 해시화하면 된다.
이는 쉽게 변경할 수 없는 것이기 때문에 가능한 일이다. 모든 블록 트랜잭션을 효과적으로 압축된 형식으로 요약할 수 있다. 유효한 블록 헤더나 이후에 변경한 트랜잭션 목록을 발견할 수는 없는데, 그렇게 되면 머클 루트가 변경될 것이기 때문이다. 다른 노드에 블록이 전송되면, 이들은 트랜잭션 목록에서 루트를 계산한다. 이것이 헤더에 있는 것과 일치하지 않는다면, 노드는 블록을 거부한다.
검증
머클 루트에는 또 다른 특성이 있다. 이는 라이트노드와 관련된다. 한정된 자원을 가진 기기로 노드를 운영할 경우, 모든 블록의 트랜잭션을 다운로드하고 해시화하고 싶지 않을 수 있다. 그 대신 단순히 풀 노드로부터 트랜잭션이 특정 블록 안에 있음을 입증하는 증거인 머클 증명을 요청할 수 있다. 이를 보통 단순화된 결제 검증(Simplified Payment Verification) 또는 SPV라 한다.
TXID가 hD인 누군가의 트랜잭션 정보를 알고 싶다면 아래의 이미지에서 빨간색으로 표시된 해시만 있으면 된다.
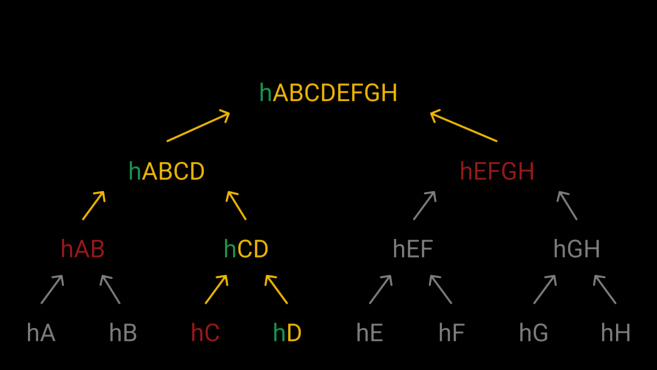
hC가 제공될 경우, hCD를 작업할 수 있다. 다음으로 hABCD를 계산하기 위해 hAB가 필요하다. 마지막으로 hEFGH를 통해 블록 헤더와 일치하는 머클 루트 결과를 확인할 수 있다. 만약 일치한다면, 이는 해당 트랜잭션이 블록에 포함되어 있었음을 증명한다. 다른 데이터를 가지고 동일한 해시를 생성하기란 거의 불가능하다.
💡 hAB를 계산하기 위해선 hA와 hB가 필요하다. 이 과정을 왜 생략하는지 의아했는데, 지금 검증하고자 하는 트랜잭션은 TXID가 hD인 트랜잭션이고 이 데이터가 위변조 되었음을 검증하기 위해선 블록의 머클루트를 비교해야한다. 다른 트랜잭션의 온전성여부는 필요가 없기때문에 머클루트를 만들기위한 해시 값만 따로 요청해 해싱하는 것 이다.
위의 예시에서 단 세 번만 해시화를 진행했다. 머클 증명이 없다면 일곱 번을 진행해야 했을 것이다. 오늘날의 블록에는 수천 개의 트랜잭션이 포함되기 때문에, 머클 증명을 사용하면 상당한 시간과 컴퓨터 자원이 절약된다.
탭루트
탭루트(Taproot) 는 슈노르 서명(Schnorr Signatures)과 함께 세그윗 도입 이후 많은 기대를 모으고 있는 비트코인의 기술적 업그레이드이다. 탭루트의 목표는 프라이버시, 확장성, 보안을 강화하기 위해 비트코인 스크립트 작동 방식에 변화를 주는 것이다.
비트코인은 공개 블록체인으로 누구나 네트워크상에서 발생하는 트랜잭션을 살펴볼 수 있다. 특정 이들에게 이는 중요한 사안이다. 탭루트 업그레이드는 비트코인의 프라이버시 결여 및 기타 관련 사안들을 해결하기 위한 중요한 첫 번째 단계로 많은 기대를 모으고 있다.
🔥탭루트 소프트포크
탭루트 업그레이드를 통해 모든 비트코인 트랜잭션의 이동 과정을 "은폐"할 수 있다. 따라서 트랜잭션에 해당 기능들이 포함된다 하더라도 단일한 트랜잭션처럼 보일 것이다. 이는 비트코인 프라이버시 결여를 어느정도 해결해 줄 수 있다.
실제로 탭루트를 통해 비트코인 스크립트가 실행되었다는 사실을 숨길 수 있다. 예를 들어, 탭루트를 사용하여 비트코인을 사용하면 라이트닝 네트워크 채널을 통한 트랜잭션 처리나 P2P 거래, 또는 복잡한 스마트 콘트랙트를 구별할 수 없게 된다. 그러나 초기 전송자와 최종 전송자의 지갑은 노출된다는 사실에는 변함이 없다.
탭루트 소프트 포크는 2018년 1월 비트코인 코어 개발자 그레그 맥스웰(Greg Maxwell)에 의해 처음으로 제시되었다. 2020년 10월 현재, 탭루트는 피터 바일라(Pieter Wuille)가 생성한 코드 반영 요청 이후 비트코인 코어 라이브러리에 통합되었다. 업그레이드가 완전히 구현되기 위해서는 노드가 탭루트의 새로운 합의 규칙을 채택해야 한다. 상황이 어떻게 전개되느냐에 따라 활성화가 되기까지는 수개월이 걸릴 수도 있다.
탭루트는 슈노르 서명이라 하는 또 다른 업그레이드와 함께 구현될 것으로 보인다. 이를 통해 탭루트 구현이 가능할 뿐만 아니라 서명 통합이라 하는 기대되는 기능도 사용할 수 있다.
🔥슈노르 서명
슈노르 서명은 암호학자인 클라우스 슈노르가 개발한 암호학적 서명 체계로 구성되어 있다. 여러 장점들 중에서도 슈노르 서명은 짧은 서명을 생성하는 데 있어 간결하고 효율성이 좋은 것으로 알려져 있다.
비트코인의 창시자 사토시 나카모토가 채택한 서명 체계는 타원 곡선 디지털 서명 알고리즘(ECDSA)이었다. 슈노르 서명 대신 이를 선택한 이유는 이미 널리 사용되고 있었고, 잘 알려져 있었으며, 안전하고, 튼튼하고, 오픈 소스였기 때문이다. 그러나 슈노르 디지털 서명 체계(SDSS)의 개발은 비트코인 및 다른 블록체인 네트워크 서명의 새로운 시대를 여는 출발점이 될 수 있다.
슈노르 서명 방식(Schnorr Signature)은 기존의 서명 방식인 다중 서명 방식의 단점을 보완하기 위해 도입되었다. 기존 다중 서명은 트랜잭션의 크기가 커지기 때문에 외부에서 추적하기 더 쉬워지고, 이로 인해 프라이버시에 취약해진다는 단점이 있다. 또한 트랜잭션의 크기 자체가 커지기 때문에 트랜잭션 처리 속도에도 영향을 준다. 슈노르 서명은 기존 다중 서명처럼 여러 개의 서명을 받는 것이 아니라, 여러 개의 서명을 기반으로 단일하고 고유한 공동 서명을 만들기 때문에 트랜잭션의 크기가 커지지 않는다. 이는 트랜잭션에 포함된 다수의 주체가 진행한 서명이 단일한 슈노르 서명으로 “통합”될 수 있다는 것이다. 이는 서명 통합(signature aggregation)이라고도 알려져 있다.
💡 탭루트는 어떻게 비트코인에 도움이 될까?
- 비트코인 트랜잭션의 프라이버시향상
- 블록체인상에서 전송 및 저장해야 하는 데이터 양의 감소
- 블록 당 더 많은 트랜잭션 처리(더 높은 TPS 비율)
- 보다 저렴한 트랜잭션 수수료
- 탭루트의 또 다른 장점 중 하나는 서명을 더 이상 변경할 수 없다는 것이다.
서명 가변성은 비트코인 네트워크에 존재하는 보안 위협 중 하나였다. 이 서명 가변성(Signature Malleability)이란 트랜잭션이 승인되기 전에 서명을 변경할 수 있다는 것이다. 이러한 공격을 통해 트랜잭션이 발생한 적이 없었던 것처럼 보이게 할 수 있다. 그 결과 비트코인은 이중 지출 문제에 노출되며, 이는 분산화된 원장의 무결성을 훼손할 수 있다.
탭루트는 주목받는 비트코인 업그레이드이다. 슈노르 서명과 함께 구현될 경우 프라이버시, 확장성, 보안 등의 측면에서 상당한 개선이 이뤄질 것입니다. 또한 해당 업그레이드를 통해 라이트닝 네트워크 전반에 대한 관심이 더욱 높아지고, 다중 서명이 업계 표준이 되도록 장려할 수 있다.
블룸필터
1970년대 Burton Howard Bloom에 의해 고안된 블룸필터(Bloom Filter) 는 구성요소가 집합의 구성원인지 검사하는데 사용할 수 있는 확률형 자료 구조이다.
블룸 필터에 의해 어떤 원소가 집합에 속한다고 판단된 경우 실제 원소가 집합에 속하지 않는 긍정 오류가 발생하는 것은 가능하지만, 반대로 원소가 집합에 속하지 않는 것으로 판단되었는데 실제로는 원소가 집합에 속하는 부정 오류는 절대로 발생하지 않는다는 특성이 있다.
💡 블룸필터를 통해 존재하지 않는다는것은 절대적으로 존재하지 않음을 확신할수 있음
블룸필터를 통해 존재한다는 것은 존재할 가능성이 있다는것이지 반드시 존재한다는것은 아님
집합에 원소를 추가하는 것은 가능하나, 집합에서 원소를 삭제하는 것은 불가능하다. 집합 내 원소의 숫자가 증가할수록 긍정 오류 발생 확률도 증가다.
🔥비트코인은 블룸필터를 어떻게 적용하는가?
이에대한 상세 작동원리는 상당히 지엽적인 내용이기 때문에 이 포스팅에서는 spv노드가 블룸필터를 사용하는 이유(필요성)와 사용함으로써 해결할 수 있는 문제들만 짚고 넘어가자.
SPV 노드는 전체 블록을 다운로드하지않고, 블록헤더만 다운로드한다. 블록의 헤더에는 거래의 해쉬정보( txid)가 포함된 머클트리 루트가 포함되어 있다. 이렇게 SPV 노드는 인근의 풀노드에게 헤더와 거래정보를 요청하여 트랜잭션의 유효성을 검증할수있다.
하지만 풀노드에게 헤더와 트랜잭션의 해쉬정보를 요청하는 과정에서 자신의 정보가 노출 될 수 있다. 즉, 자신의 지갑주소가 포함된 거래를 요청하는경우, 해당지갑주소가 노출되어 익명성이 위배될수 있다. 따라서 SPV 노드는 익명성을 유지하기 위해서 블룸필터를 추가하여 거래에 사용한다.
SPV 노드는 자신이 원하는 거래와 지갑주소를 사용하여 블룸필터를 생성하고, 해당 블룸필터를 인근 풀노드에 전달하여 필요한 헤더, 트랜잭션 정보를 요청하게 된다. 이러한 방식으로 SPV 노드가 자신의 주소와 거래정보를 노출시키지 않고, 필요한 정보를 요청하여 거래를 할수 있다
보안성을 위한 시도
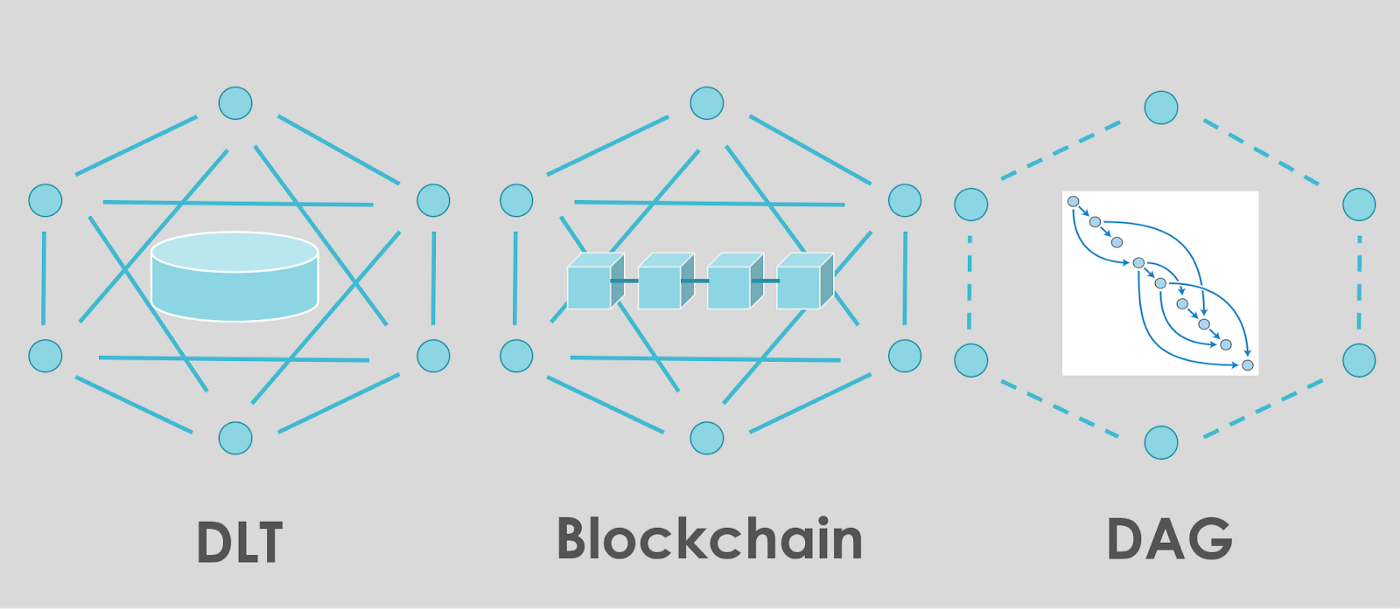
🔥DLT
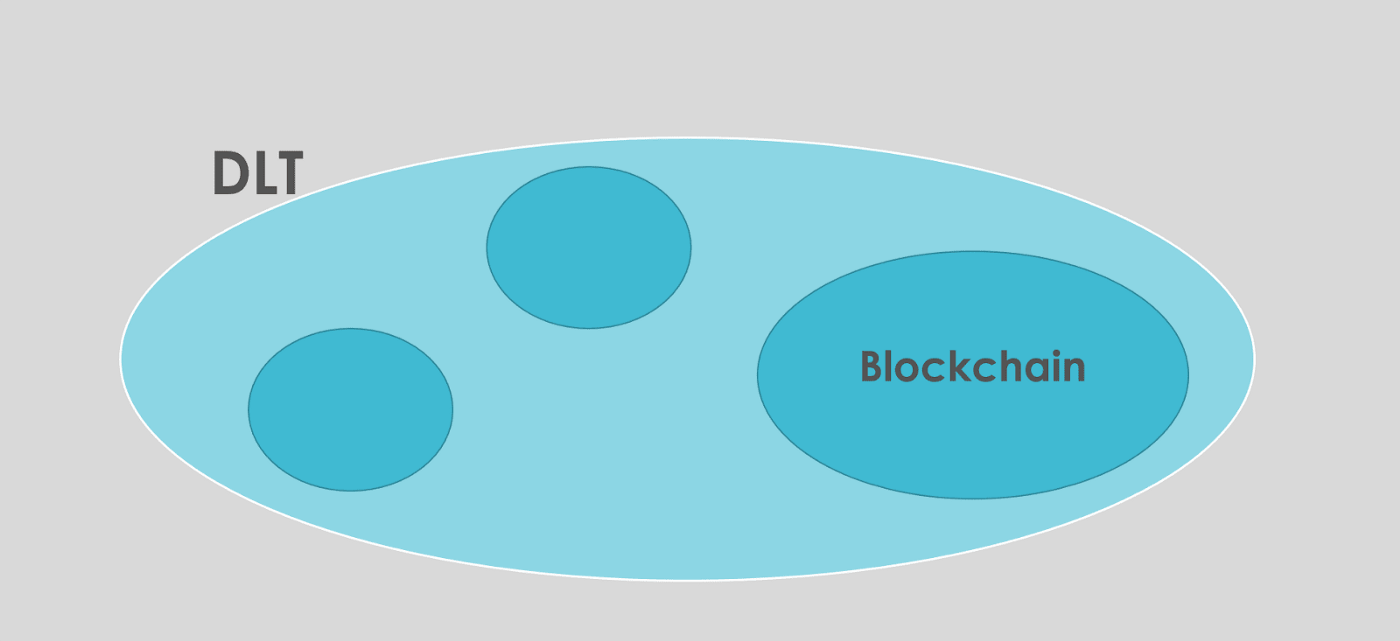
DLT (Distributed Ledger Technology; 분산원장기술)
지금까지 주구장창 배운 분산원장 기술이다. 블록체인이 DLT에 포함되는 관계가 된다
🔥DAG
DAG는 Directed Acyclic Graph의 약자로, 방향성 비사이클 그래프를 뜻한다.
퍼블릭 블록체인은 확장성 문제가 있다. 블록당 처리할수있는 트랜잭션은 한계가 있고, 처리를 우선하기 위해서는 채굴자에게 많은 수수료를 내야 한다. DAG는 이를 해결하기 위한 기술이다.
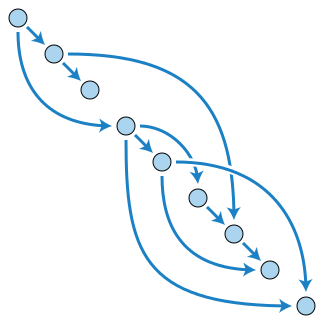
위 그림처럼 거래 시계열에 방향은 있지만 블록 용량에 상관없고 한 줄로 나란히 되어 있지 않아도 된다. 블록체인이 사슬이라면 DAG는 그물처럼 거래를 맺는 기술이며, 블록체인이 거래 길이로 신뢰성을 유지한다면, DAG는 거래 무게로 신뢰성을 유지한다.
이 기술의 큰 특징은 “채굴이 필요하지 않는 것”과 “거래이력을 각자 스스로가 관리하는 것”, 이 두 가지이다. 이에 의해 채굴자에서의 수수료가 없고 확장성 문제도 해소된다.
🔥DHT
분산해시테이블(Distributed hash tables, DHT)은 해시테이블(hash table)을 분산하여 관리하는 기술이다. 해시테이블은 실제 값에 해시함수를 적용하여 형성한 다이제스트들을 테이블화해서 빠른 검색을 하기 위한 자료 구조이다. 분산해시테이블은 이 해시테이블을 네트워크 환경에 위치한 노드들에 분산하여 적용한 것이다.
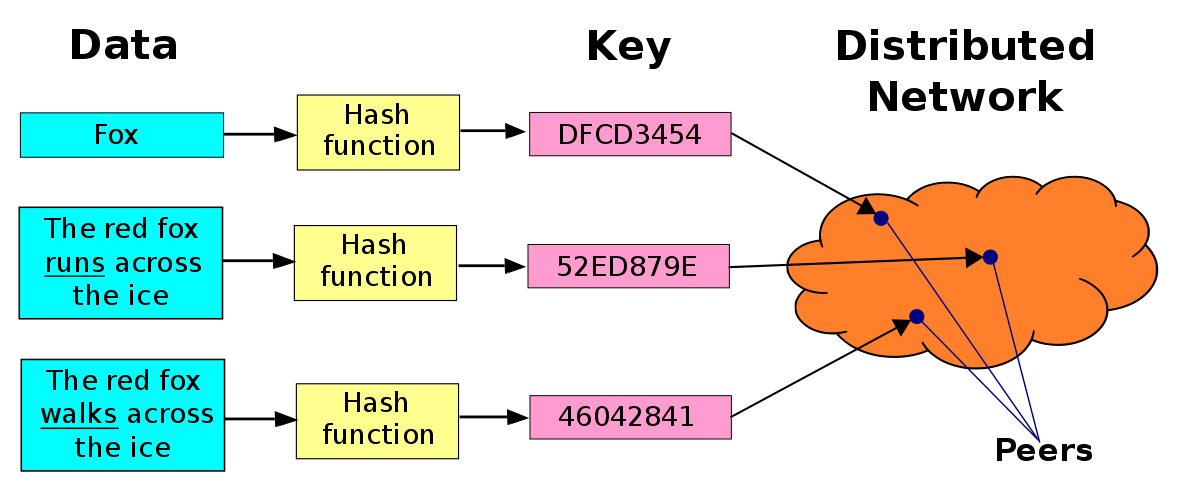
특징
분산해시테이블은 시스템 전체를 중앙에서 관리하는 조직이 없고, 시스템을 이루고 있는 노드 수에 영향을 받지 않고 확장 가능하며, 시스템 내부에 노드가 추가되거나 없어지거나 오동작을 하더라도 시스템 전체의 기능에 영향을 끼치지 않는다. 보통 어떤 항목을 찾아갈 때 해시테이블을 이용하는데, 분산해시테이블은 이때 중앙 시스템이 아닌 각 노드들이 이름을 값으로 맵핑하는 기능을 하는 방식이다.
분산해시테이블은 P2P 네트워크에 특히 많이 사용된다. 이전의 P2P 솔루션은 냅스터(Napster)처럼 중앙 집중 관리 방식과 그누텔라(Gnutella)처럼 주변 노드들을 활용하여 분산된 네트워크를 구성하는 방식이 있다. P2P 네트워크를 중앙에서 컨트롤 할 경우 네트워크의 이용효율이 좋아진다는 이점이 있지만 컨트롤이 중앙화 되어 있어 중앙 관리 시스템이 취약점이 될 수 있다. 반면에 피어에 의지하는 방식은 중앙 집중 조직이 없기 때문에 뚜렷한 취약점은 없지만 네트워크가 비효율적으로 사용된다는 문제가 있다. 분산해시테이블은 Structured key based routing 방식을 통해 P2P 시스템의 한계를 극복했다.
장단점
분산해시테이블은 부하가 집중되지 않고 분산된다는 장점이 있어 순수 P2P라도 네트워크의 부하를 억제하여 네트워크상의 콘텐츠를 빠르고 정확히 검색할 수 있다. 또한 기존의 순수 P2P에서 채택했던 방식에서는 수십만 노드 정도가 한계였으나 극단적으로 큰 규모의 노드들도 관리할 수 있으며 수십억 개의 노드를 검색범위로 할 수 있게 되었다. 하지만 분산해시테이블은 실질적으로 구현하는데 어려움이 따르는데, 특히 완전한 일치검색만 가능하여 와일드카드 등을 활용한 복잡한 검색은 할 수 없다는 단점이 있다.
속성
- 자율성과 탈중앙화 : 노드들은 어떠한 중앙 조정 없이 집합적으로 시스템을 형성한다.
- 장애 허용 : 시스템은 노드들이 지속적으로 추가, 제거, 고장나더라도 신뢰할 수 있다.
- 확장성 : 시스템은 수천 또는 수백만 개의 노드에서도 효율적으로 작동한다.
🔥IPFS
IPFS는 InterPlanetary File System의 약자로, P2P 파일 공유 시스템으로 정보가 전세계적으로 배포되는 방식을 근본적으로 바꾸는 것을 목표로 하고 있다.
IPFS는 분산형 파일 시스템에 데이터를 저장하고 인터넷으로 공유하기 위해 파일과 아이디(ID)로 처리되는 프로토콜과 분산화 시스템에 걸쳐 구성된다. 이를 통해 기존에 없는 파일 시스템을 구현할 수 있다.
파일코인(file coin)의 초기 모델이기도 하다.
특징
- HTTP는 효율적이지 않고 비용이 많이 든다. IPFS는 파일 조각을 동시에 여러 컴퓨터 노드로부터 가져오는 구조이다. 기존 대역폭 비용을 60% 이상 절감할 수 있다.
- 인류 역사의 데이터들은 지금 이 순간에도 소멸하고 있다. IPFS는 데이터 미러링을 위한 백업과 버전 관리 시스템인 깃(git)이 제공된다.
- 웹의 중앙화를 제한한다. IPFS는 개방적이고 중앙집중화되어 있지 않다.
- DApp들의 백본은 블록체인화되어 있다.
- DHT, Git, Merkle DAG(머클트리 + DAG), Self-certifying FIle Sysetem(자기 증명 파일 시스템) 등으로 이루어져 있다.
- 직접 노드를 운용할 수도 있고, 다른 노드에 데이터를 저장하는 것도 가능하다.
더 알아보면 좋을 키워드 SWARM, RLP
체인 별 Pruning
프루닝(Pruning) 은 인공지능에서 문제 해결을 위한 검색을 그래프 검색으로 표현했을 때, 검색할 가지를 줄이는 일이다. 맹목적인 검색에서는 계산량이 많아진다. 따라서 바람직하지 않은 노드를 제외하여 검색의 효율성을 높이기 위해 가지치기가 이루어진다. 이는 블록체인에서 오래된 블록체인 데이터를 자동으로 삭제하기 위해 사용된다.
🔥비트코인에서의 프루닝
비트코인에서의 프루닝은 0.11.0버전에서 추가되었다. Block file pruning으로 설명되어 있는 가지치기 시스템을 통해 비트코인의 용량을 최적화 할 수 있다.
🔥이더리움에서의 프루닝
이더리움에서는 State Trie Pruning이라고 한다. 이더리움은 현재 상태를 Prefix tree의 일종인 Modified merkle particia trie(MPT)로 저장한다. MPT는 state root의 hash를 계산하기 위해 state trie 전체를 볼 필요가 없이, 수정된 branch의 hash만 다시 계산하면 되기 때문에 빠르게 root hash를 찾을 수 있다.
MPT를 이용하면 새로 추가되는 노드의 수도 최소화할 수 있다. 예를 들어 아래 그림에서 block N과 block N + 1의 차이는 A의 오른쪽 자식의 값이 10에서 20으로 변경된 것 뿐이다. 이 경우 10에서 20으로 변경된 노드의 부모 외의 다른 노드는 전부 기존의 노드를 재활용할 수 있다. 따라서 푸른색으로 그려진 3개의 노드만 새로 추가하면 된다.
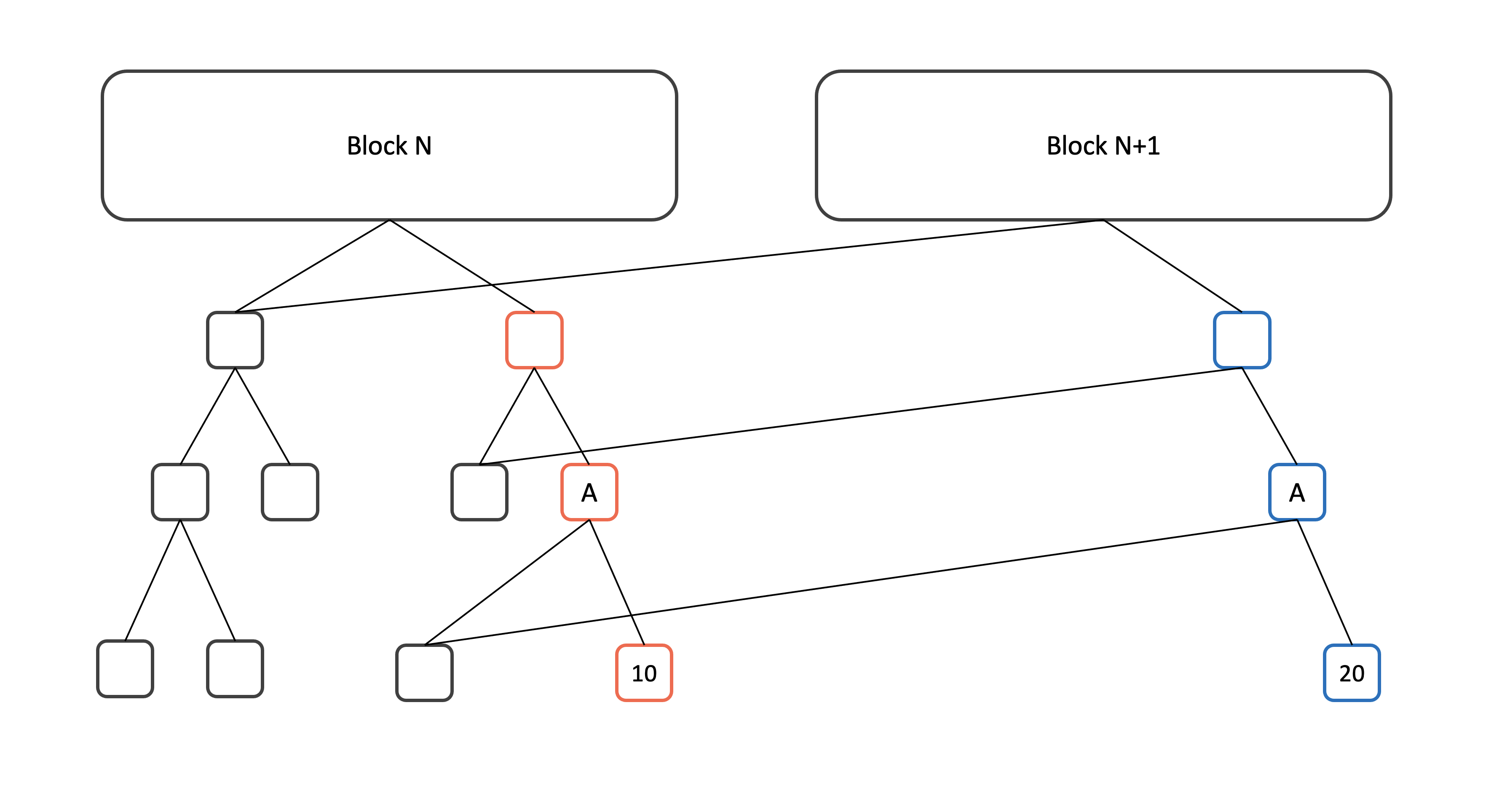
위의 그림에서 붉은색으로 표시된 3개의 노드는 block N + 1에서는 필요 없는 노드이다. 그렇다면 삭제해도 될까? 이더리움은 블록의 finality를 보장하지 않는다. 다른 말로 언제든지 block N + 1이 block N으로 retract 될 수 있다. 게다가 Web3 API를 통해서 과거의 state에 접근하는 것도 가능하기 때문에 현재 상태에서 안 쓰이는 노드를 바로 지울 수는 없다.
그렇다고 영원히 남겨둘 수도 없다. 현재 이더리움에서 최신 state의 크기는 약 25GB 정도지만, 과거 state를 전부 저장하면 300GB를 넘어간다. 게다가 이 크기는 점점 커질 것이기 때문에 이를 전부 저장하는 것은 현실적이지 않다.
이더리움은 접근할 수 있는 과거 state를 127개로 제한하여 그보다 오래된 state에만 포함된 노드는 지워도 되도록 했다. 하지만 지워도 된다는 것과 지울 수 있다는 것은 별개의 문제이다. DB에 저장돼있는 노드 중 최근 127개의 노드에서 접근할 수 없는 노드만 찾아 지우는 것은 쉬운 문제가 아니다.
이외에도 여러 문제들로 현재 매우 한정적으로 state trie pruning을 한다. State trie에 대해 cache를 사용하는데, 이 cache에만 저장된 노드에 대해서는 pruning을 하고 DB에 저장된 노드는 pruning을 하지 않는 방식이다.
