데이터베이스
데이터베이스
: 체계적으로 구성된 데이터의 모음
데이터를 효율적으로 저장 및 관리, 검색하기 위해 사용한다.
왜 사용하는가?
- 데이터의 일관성 및 무결성 유지
- 여러 사용자가 데이터에 동시에 접근 가능
- 데이터를 구조화하여 효율적인 검색 및 분석 가능
- 데이터 보안 강화
- 데이터 백업 및 복원 지원
DBMS
= 데이터베이스 관리 시스템 (Database Management System)
데이터베이스를 관리하는 소프트웨어로, 데이터를 저장, 검색, 업데이트 및 관리하는 기능을 제공한다.
일반적인 DBMS에는 MySQL, Oracle, Microsoft SQL Server 및 PostgreSQL과 같은 제품이 포함된다.
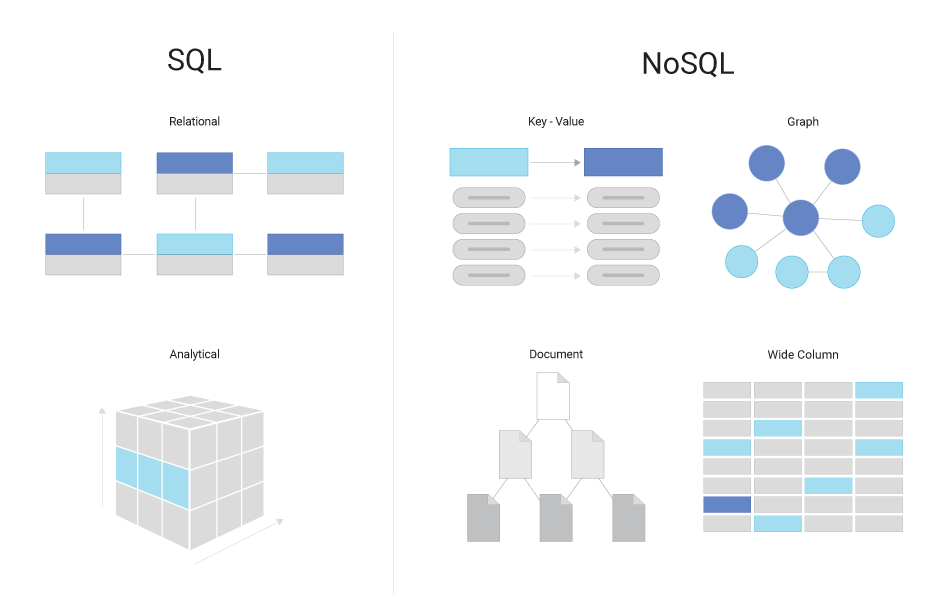
RDBMS
= 관계형 데이터베이스 (Relational Database Management System)
테이블로 구성된 데이터베이스로, 데이터는 열과 행으로 구성된 테이블에 저장된다.
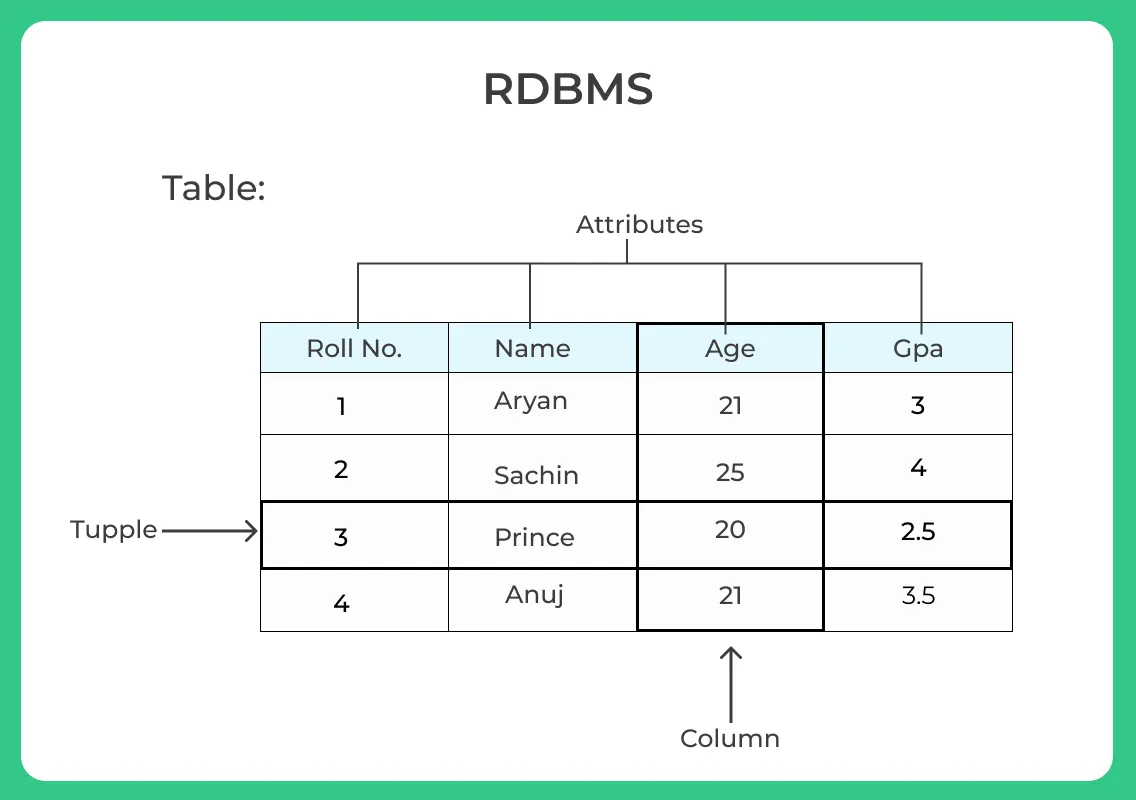
Table
: RDB에서 데이터를 저장하는 방식 중 하나로, 행과 열로 구성된 데이터의 집합
각 행은 개별 레코드를 나타내고, 각 열은 레코드의 속성을 나타낸다.
e.g. 고객 테이블은 고객 정보를 저장하는 데 사용하며, 각 열은 고객의 이름, 주소, 전화번호 등의 정보를 저장한다.
Tuple/Row
: 테이블에서 하나의 레코드
튜플은 테이블 내의 한 행에 해당하며, 여러 필드(attribute/column)의 조합으로 구성된다.
e.g. 고객 테이블의 각 튜플은 고객 한 명에 대한 정보를 담고 있다.
Attribute/Column
: 테이블의 열
테이블의 각 열은 특정 유형의 데이터를 저장하는 데 사용되며, 이 열은 특정한 속성이나 정보를 나타내게 된다.
해당 열에 저장된 값은 모든 튜플에 공통적이다.
e.g. 고객 테이블의 어트리뷰트는 이름, 나이, 주소일 수 있으며, 모든 튜플에서 이 어트리뷰트에 해당하는 고객 의 정보가 저장된다.
NoSQL
= 비관계형 데이터베이스 (Not Only SQL)
전통적인 관계형 데이터베이스 시스템(RDBMS)와는 다른 형태의 데이터베이스를 가리키는 용어
- NoSQL 데이터베이스는 다양한 형태의 데이터 모델과 저장 방식을 지원하며, 대량의 분산 데이터를 다루는 데 유용하다.
- 관계형 데이터베이스의 엄격한 스키마(테이블과 열의 구조)와는 달리, NoSQL은 스키마가 유연하며, 필요에 따라 데이터 구조를 동적으로 변경할 수 있다.
- 주요 NoSQL 데이터베이스에는 MongoDB(문서 지향), Cassandra(열 지향), Redis(키-값 저장), Neo4j(그래프 데이터베이스) 등이 있다.
Opensearch
: 검색 엔진과 검색 결과를 표준화하는 오픈 소스 표준
- 검색 엔진, 웹 사이트, 애플리케이션 및 다른 소스에서 생성된 검색 결과를 일관된 방식으로 쿼리하고 표시할 수 있는 표준화된 방법을 제공
- 검색 쿼리, 검색 결과 형식, 필터, 정렬 방법 및 기타 관련 기능에 대한 지침을 제공하여, 서로 다른 시스템 간의 상호 운용성을 개선함
인덱스란?
: Elasticsearch나 Opensearch와 같은 검색 엔진에서 데이터를 저장하고 검색하기 위한 구조적인 단위로, 도큐먼트들이 모여 있는 논리적인 데이터의 집합을 의미
- 단일 데이터 단위를 도큐먼트(document)라고 하며, 이 도큐먼트를 모아놓은 집합을 인덱스(Index)라고 한다.
- 도큐먼트들은 검색 및 쿼리를 위해 인덱싱되고 구조화되어 있다.
- 인덱스는 기본적으로 샤드(shard)라는 단위로 분리되고, 각 노드에 분산되어 저장된다.
샤드란?
: 인덱스를 물리적으로 분할한 조각
- 대용량의 데이터를 다룰 때, 데이터를 여러 노드에 분산하여 저장하고 처리하기 위해 인덱스를 샤드로 분할한다.
- 각 샤드는 독립적으로 검색 및 색인 작업을 수행할 수 있다.
따라서 데이터의 양이 많을 때 샤드를 사용하여 데이터를 여러 개의 조각으로 분산 저장함으로써 성능을 향상시킬 수 있다. - 즉, 데이터를 저장하고 검색하는 데 필요한 핵심 단위
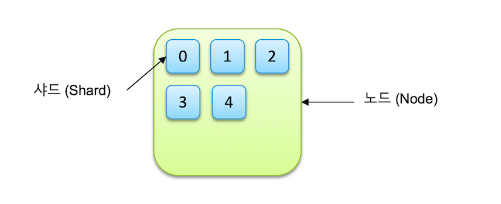
ㄴ> 하나의 인덱스가 5개의 샤드로 저장되도록 설정된 예
Opensearch에서 데이터가 저장되면 어떻게 저장될까?
프라이머리 샤드(Primary Shard)
인덱스를 생성할 때 지정한 샤드는 프라이머리 샤드로 분할되며, 프라이머리 샤드는 원본 데이터를 저장하고 검색하는 데 사용된다.
레플리카 샤드(Replica Shard)
프라이머리 샤드의 복제본으로 데이터의 안정성과 가용성을 위해 사용된다.
각 프라이머리 샤드는 여러 개의 레플리카 샤드를 가질 수 있으며, 이 복제본들은 다른 노드에 위치하여 데이터 백업을 담당하며, 검색 요청에 대해서도 빠르게 응답할 수 있게 한다.
➡️ 각 샤드는 인덱스의 일부를 저장하며, 복제본을 통해 데이터의 안전성을 보장한다.
쿼리 유형
Term 쿼리
: 정확한 단어 일치
해당 필드에 정확히 일치하는 문서만을 반환한다.
{
"query": {
"term": {
"user": "John Doe" // user 필드에서 'John Doe'를 가진 문서 검색
}
}
}Terms 쿼리
: 여러 용어에 대한 일치
Terms 쿼리는 OR 로직으로 작동하여 주어진 여러 용어 중 하나라도 일치하면 문서를 반환한다.
{
"query": {
"terms": {
"status": ["pending", "approved", "rejected"]
// status 필드에서 'pending', 'approved', 'rejected' 값을 가진 문서 검색
}
}
}Match 쿼리
: 텍스트를 기반으로 한 텍스트 검색
특정 필드에서 일부 텍스트를 검색하고 싶을 때 사용하며, 부분적인 일치도 허용한다.
{
"query": {
"match": {
"message": "Elasticsearch is powerful"
// message 필드에서 'Elasticseach is powerful'`이라는 문장을 포함한 문서 검색
}
}
}



노드를 또 세분화 할 수 있다는 건 처음알았네요..!
좋은 정보 읽고 갑니다 ~