Set
요소의 중복을 허용하지 않고, 저장 순서를 유지하지 않는 컬렉션
- HashSet
- TreeSet
📁 Set 인터페이스 공통 메서드
객체추가
add(객체) : 주어진 객체를 추가하고, 성공하면 true 중복이면 false 반환
// 만약 두 번 추가해도 중복이라 한 번만 저장객체 검색
contains(객체) : 주어진 객체가 Set에 존재하는지 확인 // boolean
isEmpty() : Set이 비어있는지 확인 // boolean
Iterator() : 저장된 객체를 하나씩 읽어오는 반복자를 리턴 // Iterator
size() : 저장된 전체 객체의 수를 리턴 // int객체 삭제
clear() : Set에 저장된 모든 객체를 삭제 // void
remove(객체) : 주어진 객체를 삭제 // boolean| HashSet
// HashSet 생성
HashSet<String> HashSet명 = new HashSet<String>();- 요소에 접근 시, 인덱스를 사용하지 않고 반복자(iterator)를 사용해야 한다
| TreeSet
- 이진 탐색 트리(Binary Search Tree) 형태로 데이터 저장
하나의 부모 노드가 최대 두 개의 자식 노드와 연결되는 이진트리 - 정렬과 검색에 특화된 자료 구조
- 루트 : 최상위 노드
- 모든 왼쪽 자식의 값이 루트나 부모보다 작고, 모든 오른쪽 자식의 값이 루트나 부모보다 큰 값을 가지는 특징
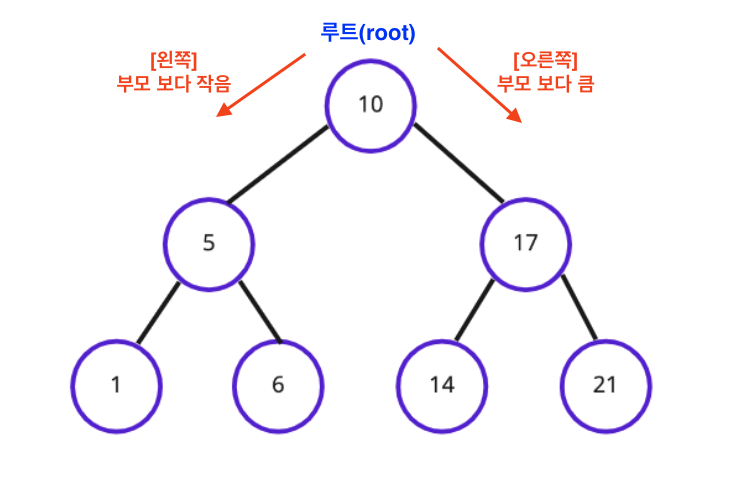
// 위 그림의 각 노드들은 아래 Node 클래스를 인스턴스화한 인스턴스에 해당
class Node {
Object element; // 객체의 주소값을 저장하는 참조변수
Node left; // 왼쪽 자식 노드의 주소값을 저장하는 참조변수
Node right; // 오른쪽 자식 노드의 주소값을 저장하는 참조변수💻 예시
// TreeSet 생성
TreeSet<String> workers = new TreeSet<>();
// TreeSet에 요소 추가
workers.add("Lee Java");
workers.add("Park Hacker");
workers.add("Kim Coding");
// TreeSet의 기본 정렬 방식이 오름차순
System.out.println(workers); // [Kim Coding, Lee Java, Park Hacker]
System.out.println(workers.first()); // Kim Coding
System.out.println(workers.last()); // Park Hacker
// .higher : 주어진 요소보다 큰 가장 작은 요소를 반환
System.out.println(workers.higher("Lee")); // Lee Java
// .subSet : 시작점 이상 끝점 미만인 요소 반환
System.out.println(workers.subSet("Kim", "Park")); // [Kim Coding, Lee Java]

백엔드 개발자 김예인입니다.