
정글 입과 전에 파이썬 자료구조 공부를 미리 시작한다.
4주동안 파이썬으로 알고리즘을 공부한다고 해서 미리 메서드 위주로 알아두면 좋을 것 같다.
잠깐! 파이썬은 배열이 있을까?
항상 파이썬을 사용할 때 고민한 점은 파이썬에서 배열과 리스트의 차이는 무엇인가이다.
예를들어, 자바를 사용할 때 차이가 분명했다.
- 배열은 순서가 있지만 크기가 고정된 자료형을 말하고(최초에 크기를 할당해야 한다.)
- 리스트는 크기가 고정되지 않은 자료형이다.
- 배열은 Class, 즉 객체이지만 리스트는 Interface이고 LinkedList, ArrayList 등 구현체가 존재한다.
여기서 ArrayList 구현체는 순서가 있지만, 크기가 고정되어있지 않아 배열의 특성을 갖고 있는 리스트이다. 공식 문서에서 파이썬의 자료 구조를 확인해보면 배열은 없고 리스트만 확인할 수 있다. 또 순서가 보장되어 있고, 크기는 할당되지 않았다. 즉 위에서 언급한 자바의 ArrayList의 역할을 한다고 생각하면 될 것 같다.

리스트
초기화
fruits = ['orange', 'apple', 'pear', 'banana', 'kiwi', 'apple', 'banana']list.append(x)
리스트의 끝에 항목을 추가한다.
fruits = ['orange', 'apple', 'pear', 'banana', 'kiwi', 'apple', 'banana']
fruits.append('watermelon')
print(fruits)
# 실행 결과: ['orange', 'apple', 'pear', 'banana', 'kiwi', 'apple', 'banana', 'watermelon']list.extend(iterable)
리스트 끝에 이터러블 항목을 덧붙여 확장한다.
- iterable은 하나씩 차례대로 반환 가능한 object를 말한다. 위 예시처럼, list, str, tuple 등이 있다.
fruits = ['orange', 'apple', 'pear', 'banana', 'kiwi', 'apple', 'banana']
fruits.extend(['watermelon', 'goldkiwi'])
print(fruits)
# 실행 결과: ['orange', 'apple', 'pear', 'banana', 'kiwi', 'apple', 'banana', 'watermelon', 'goldkiwi']만약 문자열을 넣는다면, 문자열의 알파벳을 넣는다.
fruits = ['orange', 'apple', 'pear', 'banana', 'kiwi', 'apple', 'banana']
fruits.extend('watermelon')
print(fruits)
# 실행 결과: ['orange', 'apple', 'pear', 'banana', 'kiwi', 'apple', 'banana', 'w', 'a', 't', 'e', 'r', 'm', 'e', 'l', 'o', 'n']list.insert(index, x)
주어진 위치에 항목을 삽입한다.
fruits = ['orange', 'apple', 'pear', 'banana', 'kiwi', 'apple', 'banana']
fruits.insert(3, 'watermelon')
print(fruits)
# 실행 결과: ['orange', 'apple', 'pear', 'watermelon', 'banana', 'kiwi', 'apple', 'banana']3번째 위치에 ‘watermelon’이 추가되었다.
list.remove(x)
리스트에서 값이 x와 같은 첫 번째 항목을 삭제한다.
fruits = ['orange', 'apple', 'pear', 'banana', 'kiwi', 'apple', 'banana']
fruits.remove('banana')
print(fruits)
# 실행 결과: ['orange', 'apple', 'pear', 'kiwi', 'apple', 'banana']맨 앞에 있는 ‘banana’만 삭제되었다.
list.pop([i])
해당 위치에 있는 항목을 삭제하고, 항목을 반환한다.
- 위치를 지정하지 않고 사용하면(
a.pop()) 리스트의 마지막 항목을 삭제하고 돌려준다.
fruits = ['orange', 'apple', 'pear', 'banana', 'kiwi', 'apple', 'banana']
print(fruits.pop(2)) # 실행 결과: pear
print(fruits) # 실행 결과: ['orange', 'apple', 'banana', 'kiwi', 'apple', 'banana']
print(fruits.pop()) # 실행 결과: banana
print(fruits) # 실행 결과: ['orange', 'apple', 'banana', 'kiwi', 'apple']list.clear()
리스트의 모든 항목을 삭제한다.
fruits = ['orange', 'apple', 'pear', 'banana', 'kiwi', 'apple', 'banana']
fruits.clear()
print(fruits)
# 실행 결과: []list.index(x[, start[, end]])
리스트에 있는 항목 중 값이 x와 같은 첫 번째 것의 0부터 시작하는 인덱스를 돌려준다.
fruits = ['orange', 'apple', 'pear', 'banana', 'kiwi', 'apple', 'banana']
print(fruits.index('banana')) # 실행 결과: 3
# 위치 4에서부터 시작하는 'banana'를 찾는다.
print(fruits.index('banana', 4)) # 실행 결과: 6list.count(x)
리스트에 x가 등장하는 횟수를 반환한다.
fruits = ['orange', 'apple', 'pear', 'banana', 'kiwi', 'apple', 'banana']
print(fruits.count('banana')) # 실행 결과: 2list.sort(*, key=None, reverse=False)
리스트 항목을 정렬한다.
- reverse를 True라고 설정하면 역순으로 정렬된다.
fruits = ['orange', 'apple', 'pear', 'banana', 'kiwi', 'apple', 'banana']
fruits.sort()
print(fruits) # 실행 결과: ['apple', 'apple', 'banana', 'banana', 'kiwi', 'orange', 'pear']
fruits.sort(reverse=True)
print(fruits) # 실행 결과: ['pear', 'orange', 'kiwi', 'banana', 'banana', 'apple', 'apple']리스트를 스택으로 사용하기
스택은 LIFO(Last In, First Out) 이라는 특징을 갖는 자료 구조를 말한다.
크게 두 기능을 수행해야 한다.
- 원소를 넣을 때는 맨 꼭대기에 넣는다. → append(value)를 사용한다.
- 원소를 꺼낼 때는 맨 꼭대기의 원소를 꺼낸다. → 인덱스 지정없이 pop()을 사용한다.
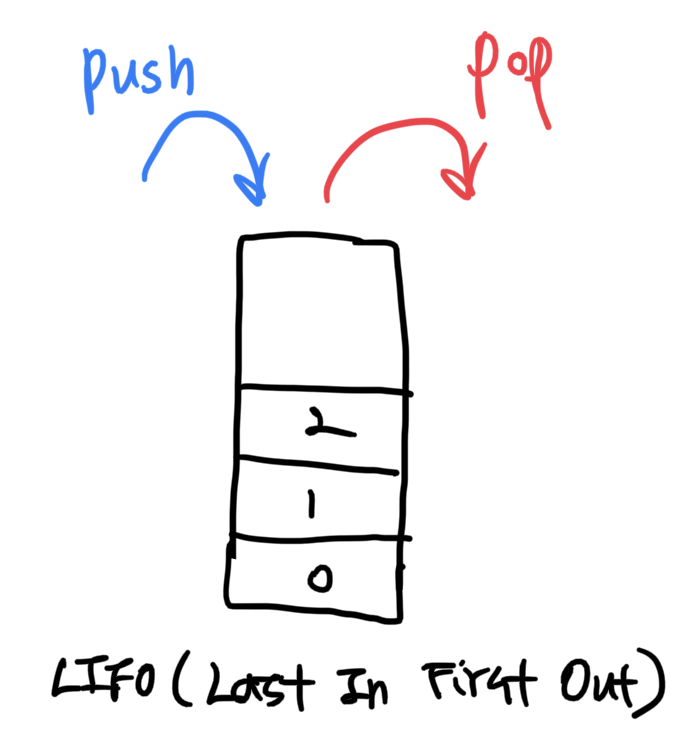
stack = [3, 4, 5]
stack.append(6)
stack.append(7)
print(stack) # 실행 결과: [3, 4, 5, 6, 7]
print(stack.pop()) # 실행 결과: 7
print(stack) # 실행 결과: [3, 4, 5, 6]리스트를 큐로 사용하기
큐는 FIFO(First-In, First-Out) 특징을 갖는 자료 구조를 말한다.
- 원소를 넣을 때는 맨 뒤에 넣는다. → append(value)
- 원소를 꺼낼 때에는 먼저 들어간 원소가 나온다. → pop(0)
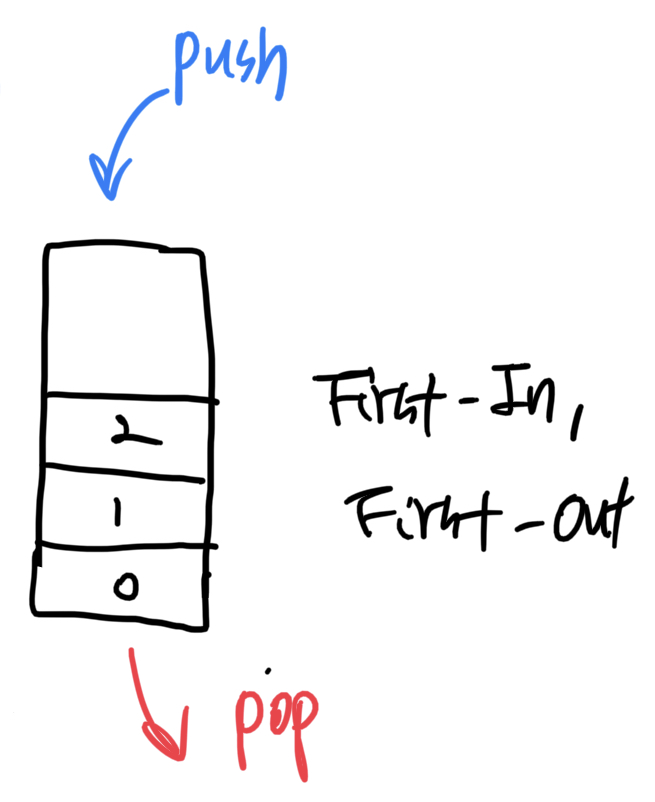
하지만 pop(0)을 사용하는 것은 적절하지 않다. 맨 앞에 있는 원소를 꺼낸다면, 리스트에 원소들을 모두 한 칸씩 이동시켜야 하기 때문이다.
이 경우에, 앞 뒤로 빠르게 덧붙이고 꺼낼 수 있도록 설계된 deque를 사용할 수 있다.
from collections import deque
queue = deque(["Eric", "John", "Michael"])
queue.append("Terry")
print(queue) # 실행 결과: deque(['Eric', 'John', 'Michael', 'Terry'])
print(queue.popleft()) # 실행 결과: Eric
print(queue) # 실행 결과: deque(['John', 'Michael', 'Terry'])더 공부할 부분
- 기타 자료형: tuple, set, dictionary, deque
- 루프 테크닉

https://mywnajsldkf.tistory.com -> 이사 중