
프로젝트 과정 중에 클라이언트로부터 영상을 받아서 S3에 저장하는 로직이 있었다.
처음엔 로컬 폴더에 저장했다가 경로만 DB에 입력하고... 클라이언트가 넘겨준 동영상을 직접 S3로 올렸다가... 여러가지로 해보다가 3가지 방법을 알게 되었다.
multer를 사용해서 올리는 방법, AWS S3 SDK만을 이용해서 올리는 방법, 마지막으로 임시 자격 증명을 사용해서 S3 객체를 다루는 방법을 알아보자!
1. Multer S3를 이용하는 방법
Nest에서는 클라이언트가 업로드 하는 파일을 받으려면 요청 받는 라우터에 FilesInterceptor() 데코레이터와 UploadedFile() 데코레이터를 사용해야 한다고 한다.
하지만 필자는 파일 하나를 받는 것이 아니라 2개를 받을 것이므로 FileFieldsInterceptor() 데코레이터를 사용했으며 사용한 옵션은 다음과 같다.
- name: 필드 이름
- maxCount: 해당 필드로 받을 수 있는 최대 파일 수
video.controller.ts
@Post()
@UseInterceptors(FileFieldsInterceptor([
{ name: 'video', maxCount: 1 },
{ name: 'image', maxCount: 1 }
]))
async upload(
@UploadedFiles() files: Express.MulterS3.File[],
@Body() uploadFilesDto: UploadFilesDto
) {
const { video, image } = JSON.parse(JSON.stringify(files));
const { userId: owner } = uploadFilesDto;
await this.commandBus.execute(
new UploadFilesCommand(owner, video[0].location, image[0].location)
);
}Nest의 인터셉터는 컨트롤러 도착 전에 동작하므로 클라이언트가 보낸 파일들 중 필드
이름이 일치하는 파일을 가져가 처리하고 업로드 되고 반환된 정보들은 UploadedFiles() 데코레이터를 통해 알 수 있다.
파일을 어디에 어떤식으로 저장할지는 multerOptions에 작성해야 하는데 Nest에서 MulterModule을 제공해주어서 config 파일들과 동적으로 구성하였다.
그럼 이제 작성에 필요한 패키지를 다운받고 작성해보자.
npm install --save multer-s3 npm install @aws-sdk/client-s3 // aws sdk 버전 3video.module.ts
@Module({
imports: [
MulterModule.registerAsync({
imports: [ConfigModule],
useFactory: multerOptionsFactory,
inject: [ConfigService]
}),
],
})이제 원하는대로 multerOption을 작성하면 된다.
multer-options.factory.ts
import { S3Client } from "@aws-sdk/client-s3";
import { ConfigService } from "@nestjs/config";
import { MulterOptions } from "@nestjs/platform-express/multer/interfaces/multer-options.interface";
import multerS3 from 'multer-s3';
import { basename, extname } from "path";
export const multerOptionsFactory = (configService: ConfigService): MulterOptions => {
return {
storage: multerS3({
s3: new S3Client({
region: configService.get('AWS.S3.REGION'),
credentials: {
accessKeyId: configService.get('AWS.S3.ACCESS_KEY_ID'),
secretAccessKey: configService.get('AWS.S3.SECRET_ACCESS_KEY')
}
}),
bucket: configService.get('AWS.S3.BUCKET'),
//acl: 'public-read',
contentType: multerS3.AUTO_CONTENT_TYPE,
metadata(req, file, callback) {
callback(null, {owner: 'it'})
},
key(req, file, callback) {
const ext = extname(file.originalname); // 확장자
const baseName = basename(file.originalname, ext); // 확장자 제외
// 파일이름-날짜.확장자
const fileName = ext === '.mp4' ?
`videos/${baseName}-${Date.now()}${ext}` :
`images/${baseName}-${Date.now()}${ext}`
callback(null, fileName)
}
}),
// 파일 크기 제한
limits: {
fileSize: 10 * 1024 * 1024
}
}
}옵션을 하나씩 살펴보자.
- storage: 파일을 어디에 저장할지 설정하는 옵션으로 S3용 multer가 아니라면 disk나 memory로 작성한다.
- s3: 자신의 자격 증명과 지역으로 S3 Client를 생성한다. 필자는 발급받은 액세스 키를 자격 증명으로 사용했기 때문에 위와 같이 작성했다. - bucket: 해당 객체를 올릴 bucket 이름
- contentType: mime type을 지정할 수 있는 옵션으로 위와 같이 작성하면 s3 multer가 자동으로 설정해주며 기본은 application/octet-stream
- metadata: 파일과 함께 설정할 metadata
- key: 파일명을 설정할 수 있는 옵션으로 위와 같이 작성한다면 확장자가 mp4면 설정한 bucket에 videos폴더에 지정한 파일 이름으로 올린다.
이렇게 작성한 옵션대로 S3에 업로드 하고 난 후 반환된 정보를 Controller의 UploadFiles() 데코레이터를 통해 받을 수 있다!
{
video: [
{
fieldname: 'video',
originalname: 'KakaoTalk_20230413_205438483.mp4',
encoding: '7bit',
mimetype: 'video/mp4',
size: 49240,
bucket: 'videodot-project-storage',
key: 'videos/KakaoTalk_20230413_205438483-1681389145640.mp4',
acl: 'private',
contentType: 'video/mp4',
contentDisposition: null,
contentEncoding: null,
storageClass: 'STANDARD',
serverSideEncryption: null,
metadata: [Object],
location: 'https://videodot-project-storage.s3.ap-northeast-2.amazonaws.com/videos/KakaoTalk_20230413_205438483-1681389145640.mp4',
etag: '"9d24e223c9b4a418017ce2abbd9d6d18"'
}
],
image: [
{
fieldname: 'image',
originalname: 'Screenshot_20230407-231725_storeProject.jpg',
encoding: '7bit',
mimetype: 'image/jpeg',
size: 306293,
bucket: 'videodot-project-storage',
key: 'images/Screenshot_20230407-231725_storeProject-1681389145641.jpg',
acl: 'private',
contentType: 'image/jpeg',
contentDisposition: null,
contentEncoding: null,
storageClass: 'STANDARD',
serverSideEncryption: null,
metadata: [Object],
location: 'https://videodot-project-storage.s3.ap-northeast-2.amazonaws.com/images/Screenshot_20230407-231725_storeProject-1681389145641.jpg',
etag: '"66fb668d4ffda88e0cbe6a2fbf9c17a2"'
}
]
}2. Multer 사용하지 않고 SDK만 이용하는 방법
이번엔 multer를 사용하지 않고 JS용 AWS SDK만 이용해서 S3 객체를 다뤄보자.
AWS S3 Client SDK를 다운받자.
npm install @aws-sdk/client-s3일단 필자는 S3용 Module을 만들어서 S3 Client가 필요할 때마다 토큰을 주입시켜서 사용하였다.
s3.provider.ts
import { S3Client } from "@aws-sdk/client-s3";
import { ConfigModule, ConfigService } from "@nestjs/config";
export const S3Provider = [
{
provide: 'S3_CLIENT',
import: [ConfigModule],
inject: [ConfigService],
useFactory: (configService: ConfigService) => {
return new S3Client({
region: configService.get('AWS.S3.REGION'),
credentials: {
accessKeyId: configService.get('AWS.S3.ACCESS_KEY_ID'),
secretAccessKey: configService.get('AWS.S3.SECRET_ACCESS_KEY')
}
})
}
}
]s3.module.ts
import { Module } from "@nestjs/common";
import { S3Provider } from "./s3.provider";
@Module({
providers: [...S3Provider],
exports: [...S3Provider]
})
export class S3Module {}이번엔 올린 객체를 삭제하는 경우를 살펴보자.
삭제하기 위해서는 Bucket과 Key가 필요한데 AWS에서 URL로부터 Bucket이나 Key를 파싱해주는 클래스는 JAVA용 SDK밖에 없었다.
객체를 업로드하는 SDK의 PutObjectCommand 클래스를 사용하면 Multer와는 다르게 객체가 저장된 URL을 반환해주지 않는다.
그래도 S3에 객체를 저장하면 생성되는 URL이 일정한 형식으로 지역과 버킷, 키만 알면 만들 수 있기 때문에 업로드시에는 만들면 되므로 문제가 되진 않았다.
하지만 삭제시에는 파싱해주는 라이브러리가 있어 이용하였다.
npm install amazon-s3-uriimport { DeleteObjectCommand, S3, S3Client } from "@aws-sdk/client-s3";
import { Inject } from "@nestjs/common";
import { ConfigService } from "@nestjs/config";
import { EventsHandler, IEventHandler } from "@nestjs/cqrs";
import AmazonS3URI from "amazon-s3-uri";
import { UploadVideoCompleteEvent } from "./upload-video-complete.event";
import { unlink } from 'node:fs';
@EventsHandler(UploadVideoCompleteEvent)
export class UploadVideoCompleteEventHandler implements IEventHandler<UploadVideoCompleteEvent> {
constructor(
@Inject('S3_CLIENT')
private readonly s3Client: S3Client,
private readonly configService: ConfigService,
) {}
private originVideoPaths: { Bucket: string, Key: string } [] // delete command array
async handle(event: UploadVideoCompleteEvent) {
const BUCKET = this.configService.get('AWS.S3.BUCKET');
const { thumbNailPath, videoPath, originVideoPath } = event;
originVideoPath.map((path) => {
-----> const { key } = AmazonS3URI(path);
this.originVideoPaths.push({ Bucket: BUCKET, Key: key })
})
try {
await Promise.all(
this.originVideoPaths.map((path, index) => {
if( index <= 1 ) {
const { Key } = path;
unlink(`/home/ubuntu/${Key}`, (err) => console.log(
'unlink error in uploadVideoCompleteEvent...', err
));
}
this.s3Client.send( new DeleteObjectCommand(path))
----> this.s3Client.send( new DeleteObjectCommand({Bucket: '버킷명', Key: '키 값})
})
)
}
catch(err) {
console.log('delete bucket error in UploadVideoCompleteEvent...', err);
}
}
}삭제를 한다면 Bucket과 Key값으로 DeleteObjectCommand 인스턴스를 생성하면 된다.
프로젝트에서 최종 동영상이 업로드가 된다면 필요없는 영상들은 전부 삭제 해야 했기 때문에 위와 같은 로직을 짰는데
new DelteObjectCommand({
Bucket: '버킷명',
Delete: {
Objects: [{ Key: "키값 1" }, { Key: "키값2" }]
}
})위와 같이 여러 파일을 하나의 DeleteObjectCommand 인스턴스를 통해 삭제할 수 있으니 이 방법을 사용하는게 좋을 것 같다.
3. 임시 자격 증명을 사용하는 방법
현재 EC2 인스턴스에서 동작하는 애플리케이션에서 S3에 액세스키를 통해 접근하기 위해 액세스키를 발급받으려 하면 다음과 같은 대안을 추천해준다.
EC2를 실행시키는 사람이 실행시키면서 EC2에 설정한 역할을 그대로 적용하면 해당 역할을 기반으로 자격 증명을 하고 코드상에선 AWS API를 호출하기 위한 자격 증명과 관련된 코드를 저장, 작성 하지 않는 것이다.
그러므로 EC2를 실행시키는 사람은 필요한 권한 이외에 너무 많은 권한을 가지고 있어도 안되고 필요한 권한이 없어도 안되므로 PassRole정책을 통해 구성했었다.
그 과정은 여기에 정리해 놓았습니다.
해당 글에서 설정한 사용자와 역할을 기반으로 실행했기에 이 방법을 사용하기 위해선 보고 오시는게 이해가 잘 되실겁니다!
IAM 사용자 중 BackEnd 사용자로 로그인하고 EC2 인스턴스를 실행시켜 보았다.
이 사용자는 실행시키면서 EC2에 S3에서 객체를 저장, 삭제, 조회 권한을 가지고 있는 역할을 넘겨주었다.
그러므로 해당 EC2 인스턴스에서는 별도로 자격 증명을 하지 않아도 되는 것이다.
첫번째 Multer를 이용한 코드를 다시보자.
import { S3Client } from "@aws-sdk/client-s3";
import { ConfigService } from "@nestjs/config";
import { MulterOptions } from "@nestjs/platform-express/multer/interfaces/multer-options.interface";
import multerS3 from 'multer-s3';
import { basename, extname } from "path";
export const multerOptionsFactory = (configService: ConfigService): MulterOptions => {
return {
storage: multerS3({
s3: new S3Client({
region: configService.get('AWS.S3.REGION'),
/*
credentials: {
accessKeyId: configService.get('AWS.S3.ACCESS_KEY_ID'),
secretAccessKey: configService.get('AWS.S3.SECRET_ACCESS_KEY')
}
*/
}),
bucket: configService.get('AWS.S3.BUCKET'),
//acl: 'public-read',
contentType: multerS3.AUTO_CONTENT_TYPE,
metadata(req, file, callback) {
callback(null, {owner: 'it'})
},
key(req, file, callback) {
const ext = extname(file.originalname); // 확장자
const baseName = basename(file.originalname, ext); // 확장자 제외
// 파일이름-날짜.확장자
const fileName = ext === '.mp4' ?
`videos/${baseName}-${Date.now()}${ext}` :
`images/${baseName}-${Date.now()}${ext}`
callback(null, fileName)
}
}),
// 파일 크기 제한
limits: {
fileSize: 10 * 1024 * 1024
}
}
}위에서 작성했던 credentials를 작성하지 않고도 S3에 파일을 올릴 수 있었다.
하지만 region은 입력해줘야 했다.
입력하지 않았더니 build 과정에서 실패하고
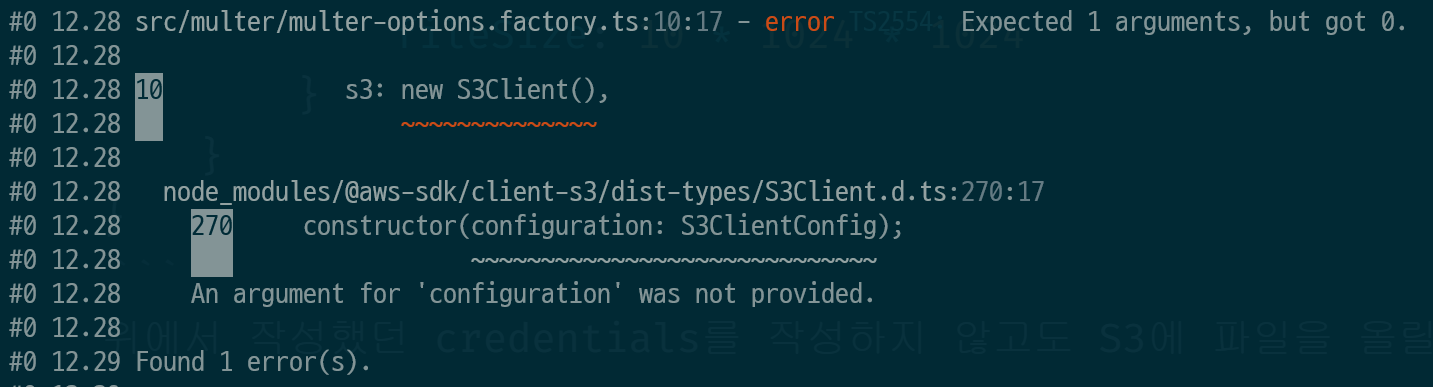
{}만 입력했더니 아래의 오류를 마주쳤다.

4. 마주쳤던 오류
1) public read
위의 multerOptionsFactory 코드에서
MulterOptions => {
return {
storage: multerS3({
s3: new S3Client({
region: configService.get('AWS.S3.REGION'),
credentials: {
accessKeyId: configService.get('AWS.S3.ACCESS_KEY_ID'),
secretAccessKey: configService.get('AWS.S3.SECRET_ACCESS_KEY')
}
}),
bucket: configService.get('AWS.S3.BUCKET'),
//acl: 'public-read',주석으로 표시해둔 acl이 보일 것이다.
올리는 파일에 대한 액세스를 설정하는 옵션인데 public-read는 누구나 읽을 수 있게 설정해서 올리는 것이다.
public-read로 하고 올렸더니 해당 오류를 만났다.
ERROR [ExceptionsHandler] The bucket does not allow ACLs
AccessControlListNotSupported: The bucket does not allow ACLs처음에는 IAM 정책을 잘못 설정해서 그런 줄 알았지만 버킷을 생성할 때 public 접근을 전부 차단해서 public-read로 파일을 설정하면 업로드가 안됐던 것이다.
acl 옵션을 사용하지 않으면 기본으로 private으로 설정되기 때문에 제거해서 해결할 수 있었다.
2) Object: null prototype
위의 Controller에서 작성한 코드를 봐보자.
@Post()
@UseInterceptors(FileFieldsInterceptor([
{ name: 'video', maxCount: 1 },
{ name: 'image', maxCount: 1 }
]))
async upload(
@UploadedFiles() files: Express.MulterS3.File[],
@Body() uploadFilesDto: UploadFilesDto
) {
const { video, image } = JSON.parse(JSON.stringify(files));여기서 왜 parsing을 할까?
parsing을 하기 전 log를 찍어보면 다음과 같이 나온다.
[Object: null prototype] {
video: [
{
fieldname: 'video',
originalname: 'KakaoTalk_20230413_205438483.mp4',
encoding: '7bit',
mimetype: 'video/mp4',
size: 49240,
bucket: 'videodot-project-storage',
key: 'videos/KakaoTalk_20230413_205438483-1681408396664.mp4',
acl: 'private',
contentType: 'video/mp4',
contentDisposition: null,
contentEncoding: null,
storageClass: 'STANDARD',자바스크립트에서는 객체를 생성하면 기본적으로 prototype을 상속받는다.
prototype에는 우리가 사용할 수 있는 toString(), valueOf()와 같은 메소드들이 정의되어 있는데 위와 같이 null prototype으로 출력이 되는 객체는 prototype들을 상속받지 않았다는 말이다.
그래서 저 안에 있는 데이터들을 꺼낼 방법이 없다.
async upload(
@UploadedFiles() files: Object,
@Body() uploadFilesDto: UploadFilesDto
) {
console.log(files.toString())위와 같이 타입을 Object로 주고 toString()메소드를 사용해도 찾을 수 없다.
ERROR [ExceptionsHandler] files.toString is not a function
TypeError: files.toString is not a function
at VideoController.upload (C:\Users\user\video-dot-project\video-service\src\video\video.controller.ts:49:27)그래서 안에 데이터에 접근하기 위해 먼저 JSON.stringify로 문자열로 만들고 Parsing하는 것이다.
마치면서
처음 영상하고 이미지를 다뤄보면서 로컬 폴더부터 S3오기까지 많이 헤맸지만...
헤맨만큼 기억에도 많이 남긴 한다.
아직 해봐야 한다고 생각하는건 S3 객체의 사용 빈도별로 스토리지 클래스를 다르게 보관하는거는 공부해보고 싶다.
참고
File upload
JavaScript and object with null prototype
Multer S3
Loading Credentials in Node.js from IAM roles for Amazon EC2
AWS SDK를 사용한 Amazon S3에 대한 작업
