이제 성능 개선 동시성 쪽은 거의 막바지에 이르렀다. 이번에는 Redis를 활용해서 분산 락으로 성능을 개선해볼 수 있을지 해 볼 예정이다. 일단은 구현해보고 이게 잘 돌아가는지, 헛점은 없는 지 다양한 관점에서 볼 예정이다.
1. Redis 구현 전, 기술적 의사결정
사실 우리 코드에서는 Redis도 이미 구현이 되어있기 때문에 기초적인 셋팅은 내가 할 게 없고, Redis 코드가 어디서 어떻게 쓰이는지 공부하면서 내가 분산 락을 사용할 부분을 잘 찾아서 해보기로 했다.
1. AOP 적용? Key 생성기 사용?
일단 외부 코드들을 어떻게 적용하는지 찾아보니 AOP를 구현한 분이 꽤 있어서 나도 이 부분을 고민하게 되었다. 내 코드에서는 조회 수 동시성에만 Lock이 구현되고 있어서 AOP를 굳이? 써야하나? 라는 생각이 들었다.
그리고 구글링을 하다보니 키 생성기를 사용하시는 분도 계시던데 이 부분도 나는 굳이? 라는 생각이 들어서 튜터님께 여쭈어보고, 일단 두 개 다 하지 않고 구현에만 집중해보기로 했다.
2. 집계 테이블? 메인테이블?
레디스 분산 락을 구현하기 전에 고민한 부분은 메인 테이블(채용공고 테이블)에 직접 락을 걸지, 아니면 집계 테이블에 똑같이 락을 걸지에 대한 부분이었다.
도대체 내 머리랑 깡통(GPT)으론 결론이 안 나서 어떤 게 나은지 몰라서 비교를 해봐야하는데 뭐부터 구현해야 하냐고 물어보러 갔더니 먼저 현재와 똑같이 집계 테이블로 구현해 보고, 메인으로 락을 돌려보면 되는 거 아니냐고 하셨다.
나는 오늘도 바보였다고 한다
2. Redis 구현하기
일단 먼저 Redis를 락을 써서 구현하기 자체가 개념을 이해한 것과 다르게 어려웠다.
그래서 여기저기 구현 코드를 봤는데 하나같이 코드가.. 왜 이리 더러운 거 같지..?
일단 나는 역할 분리를 위해서 락 관리는 락만 관리하고, 카운팅 관리는 카운팅에 대한 메서드만 정의한 후에, 서비스 단에서 사용하게 하는 로직을 하려고 한다.
1. 레디스 집계 매니저
/**
* 특정 채용공고의 조회수를 증가시키는 메서드
*
* @param jobOpeningId 조회수를 증가시킬 채용공고 ID
*/
public void increaseViewCount(Long jobOpeningId) {
String key = VIEW_COUNT_KEY_PREFIX + jobOpeningId; // Redis 키 생성
redisTemplate.opsForValue().increment(key); // 조회수 증가 (INCR 명령어 사용)
}
/**
* 채용공고의 조회수를 가져오는 메서드
*
* @return 현재 Redis에 저장된 조회수 중 0보다 큰 값 전부
*/
public Map<Long, Integer> getViewCount() {
Set<String> keys = redisTemplate.keys(VIEW_COUNT_KEY_PREFIX + "*"); // 모든 조회수 키 찾기
Map<Long, Integer> viewCounts = new HashMap<>();
for (String key : keys) {
String count = redisTemplate.opsForValue().get(key);
Long jobOpeningId = Long.parseLong(key.replace(VIEW_COUNT_KEY_PREFIX, ""));
viewCounts.put(jobOpeningId, count == null ? 0 : Integer.parseInt(count));
}
return viewCounts;
}이런 식으로 증가 메서드와 조회 메서드만 구현해두고, 락은 별도로 작성해놨다. 근데 락이 제대로 작성된 건지는 잘 모르겠어서 일단 증가 메서드와 조회 메서드만 채용공고 서비스 단에 연결해서 작동시켜 볼 예정이다. 락 관리 매니저는 조금 있다가 적용해봐야겠다.
레디스부터 어렵다 엉엉
심지어 이 와중에 컨트롤러 리팩토링이 필요하다는 것도 깨닫고 좀 짜증이 났다. 총체적 난국이다. ㅎㅎ
private final JobOpeningService jobOpeningService;
private final JobOpeningFindByService jobOpeningFindByService;
private final JobOpeningViewCountService jobOpeningViewCountService;
/**
* 원하는 채용공고에 리다이렉팅 되게 하는 API입니다.
* 결합도가 지나치게 높았던 관계로 채용공고 조회, 조회수 증가, 리다이렉트 세 가지 로직을 분리했습니다.
* @param id 조회할 채용공고 페이지의 식별 id값
* @return 리다이렉트 된 채용공고 사이트
*/
@GetMapping("/{id}")
public RedirectView getRedirectedView(@PathVariable Long id) {
JobOpening jobOpening = jobOpeningFindByService.findById(id);
jobOpeningViewCountService.increaseViewCount(id);
String url = jobOpeningService.getJobOpeningUrl(jobOpening);
return new RedirectView(url);
}이제 컨트롤러인데 서비스만 3개를 의존하고 있어서 극혐일정도로 별로다.
이걸 좀 잘 고쳐보면서 오늘은 락 구현까지 하는 게 목표라서 머리가 좀 아플 거 같다. ㅎㅎㅎ 그리고 이 와중에 dev가 두 번 정도 머지 되어서 나는 새 코드를 가져와야 할 판이다.
작업 도중에 커밋도 못 할 수준(코드는 일부 변경 되었으나 완성이 안된 상태)일 때 쓸 수 있는 방법이 바로 스태시이다.
git stash 해주고, git pull origin dev 해 준 뒤에 다시 git stash pop 해주면 pull이 안 될 때 도움이 된다. 단, 스태시는 임시 저장이므로 진짜진짜 중요한 정보일 경우 tmp 브랜치라도 파서 커밋 후에 스태시를 하는 걸 추천한다.
나의 경우 미완성이지만 기록도 계속 위에 써놨고, 몇 가지 코드는 GPT 선생님한테 물어본 것도 있어서 굳이? 이긴 해서 스태시로 작업하긴 했다. ㅋㅋ
그래서 이제 컨트롤러에 대한 생각을 해봤는데, 음... 이거 이렇게 id로 채용공고 조회 후에 url 리다이렉트가 필요할까? 현재 로직 상 id로 바로 URL을 땡겨올 수 있는 방법이 있다면 되는 거 아닌가? 하는 생각이 들었다. 그래서 일단 findByService를 다시 Service 단에 넣을까 하다가 근데 이렇게 서비스 -> 서비스 참조가 좋은 로직인지는 잘 모르겠다.
@GetMapping("/{id}")
public RedirectView getRedirectedView(@PathVariable Long id) {
jobOpeningViewCountService.increaseViewCount(id);
return new RedirectView(jobOpeningService.getJobOpeningUrl(id));
}그리하여 정리된 코드, url도 그냥 생략하고 이렇게 직접 넣어버렸다. 어차피 RedirectView가 뭔지 안다면 url이 안에 들어간다는 건 알 거라고 생각했다.
일단 레디스로 저장한다는 걸 가정하고 코드 변경 후, 실행을 했는데 실행이 되었고, 레디스에 저장된 값을 로그로 출력해서 확인을 해봐야겠다.
common 쪽에 레디스 있어서 순서는 잘못 되었지만 아무튼 되긴 한다. 조회 여러번 눌렀는데 카운팅이 되고 있긴 하다.
이제, 정합성을 체크해보기로 했다. 한번 울어주고 테스트 코드에 들어간다.
근데 생각해보니 테스트 코드를 하려면 동기화를 해줘야 하네..?
한번 더 울고 동기화 관련 글을 보고 참고하여 레디스 속의 값을 동기화해주기로 했다.
2. 레디스만 구현했을 때, 동기화를 해보자
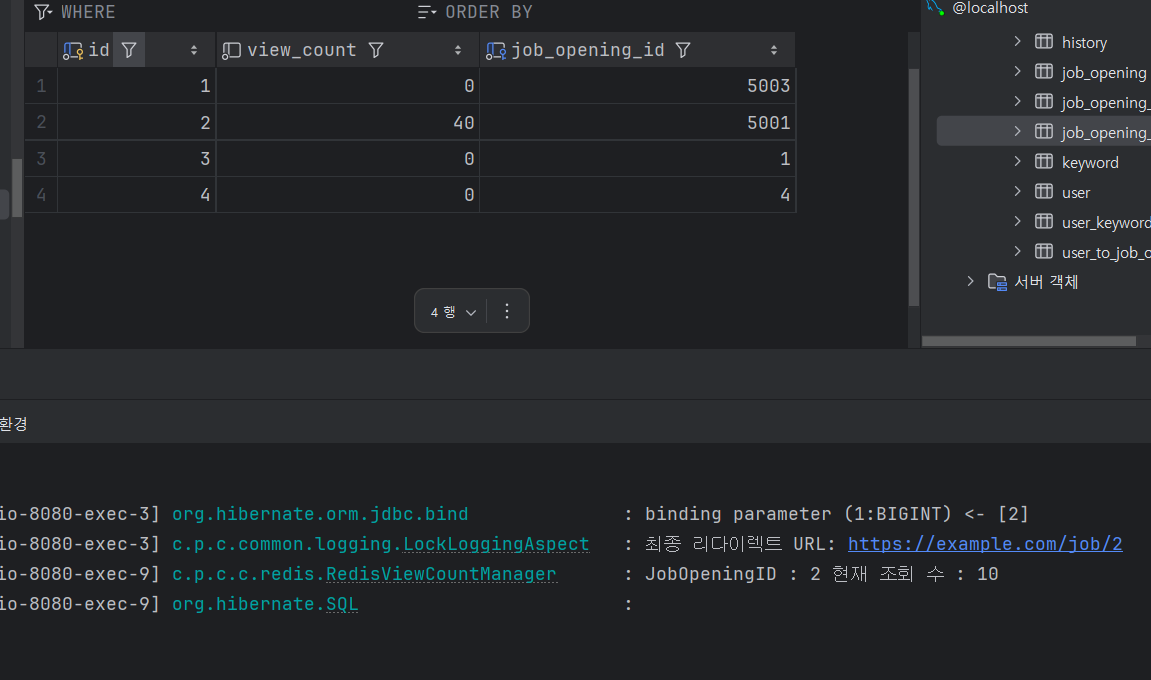
정합성 체크를 하기 전에 동기화 해야지^^ 이러고 구현했는데 ㅎㅎㅎ 매우 강력한 증가 문제가 발생한 모양이다 2~3번 누르니 10번씩 카운팅된다.
곰곰히 생각해보니 나레기가 리셋을 안 해주고 동기화를 했다. (바보) 일단 리셋하고, 속도 비교를 위해서 테스트 코드가 아니라 jmeter를 써보기로 했다. 테스트 코드로 했더니 단점이 테스트 코드 커밋으로 돌아가서 체크하는 게 한세월이 걸리고, 내가 테스트 코드를 이상하게 짜면 그것도 그것대로 문제라서 이번에는 어차피 고칠거 jmeter를 써보기로 했다.
레디스를 락 없이 조회 수 동기화한 결과
일단 기본적인 방식으로 동기화 결과 아래와 같은 결론이 나왔다.
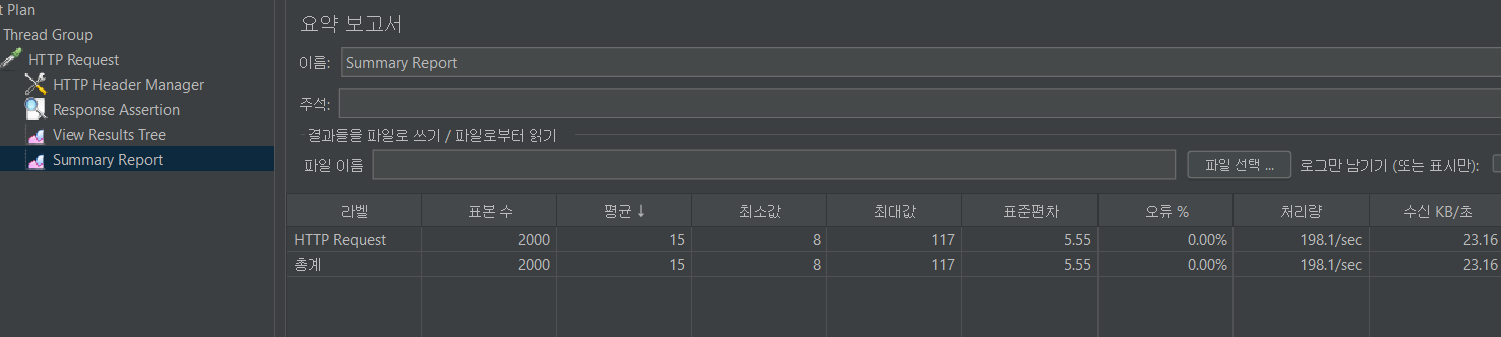
사실 제이미터로 더 잘 보이게 해보려고 힘썼으나, 조작문제로 인해 이 정도밖에 못 했다는 건 비밀
100개 스레드로 10초 기준을 잡고 했는데 평균 197ms가 나왔다. 근데 이게 흠... 그 전에 비관적 락이랑 얼마나 다른지 다시 체크를 해보고 싶다는 생각이 들어서 일단 제이미터로 기존 코드 클론 해와서 실험해보기로 했다.
비관락 테이블 분리한 상태일 경우
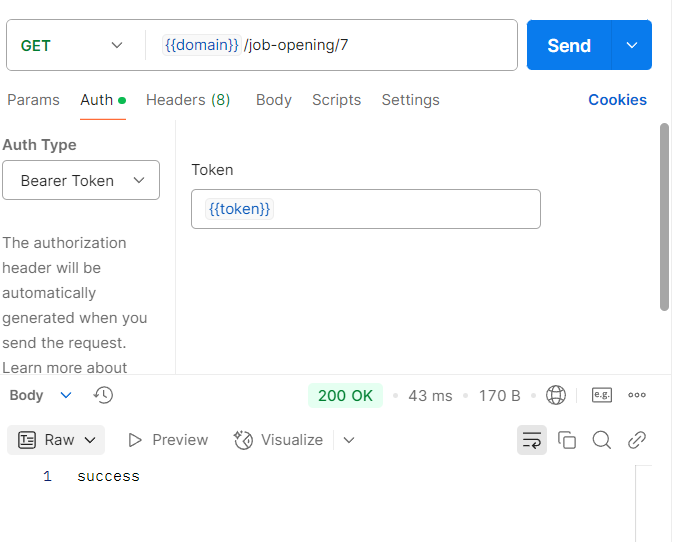
이거는... 편차가 이리도 심할 수 있나????? 편차가 이렇게까지 심할 줄 몰랐다. 이래서 다들 테스트 도구를 쓰는 거구나, 싶다.
3. 간략하게 부하테스트를 해보자
아무튼 그래서 이제 다시 한 번 부하를 늘려서 실험해봤다.
근데 계속 에러코드가 떴다.. 이유가 뭔지 몰라 튜터님께 여쭈어보니 페이지가 실제 페이지로 리다이렉트 되기 때문이라는 답변을 받았고, 페이지를 리다이렉트 할거라면 그 부분은 웹 사이트 포털이랑 사용자 환경(인터넷 등)에 영향이 너무 커지기 때문에 성능 테스트에서는 배제하고 가는 게 좋겠다고 하셨다.
그래서 쿨하게 리다이렉트 부분을 주석처리하고, 반환값을 없애서 다시 실험해봤다.
1. 비관적 락 테이블 분리할 경우
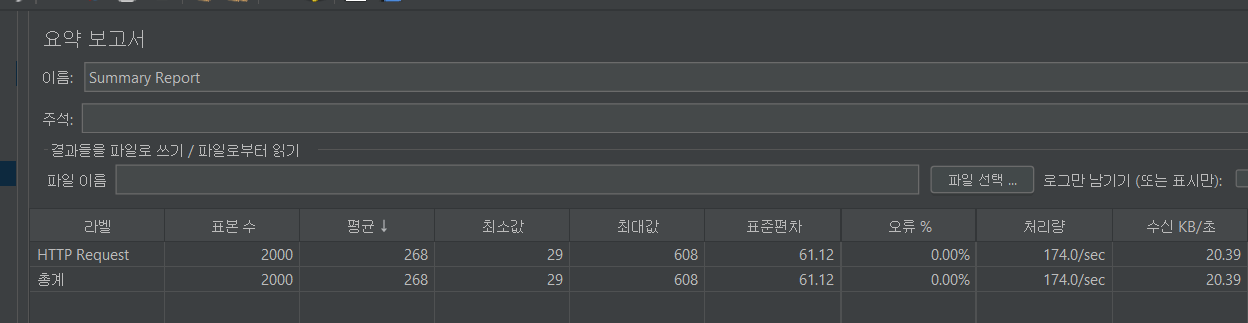
정합성 보장, 그리고 확실히 빠르다.
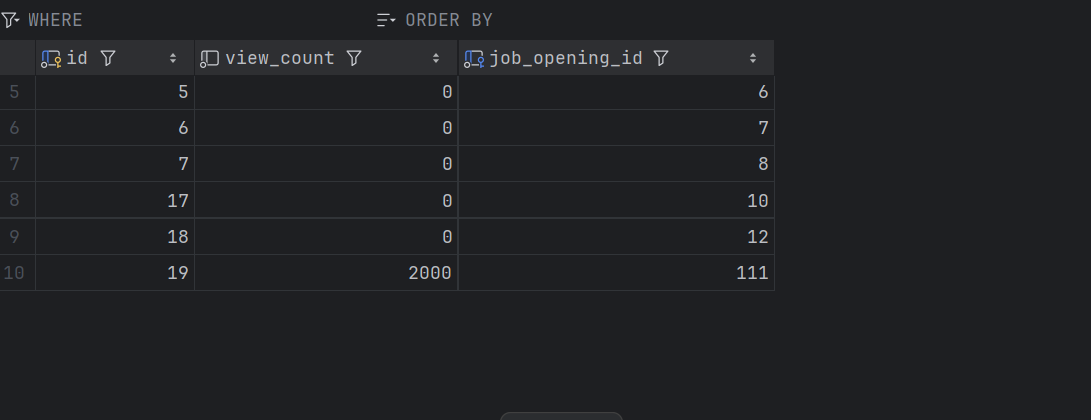
실제 데이터베이스 쪽에도 아무 이상이 없고 정확히 들어간 걸 알 수 있었다. 오예..
2. 레디스만 적용할 경우
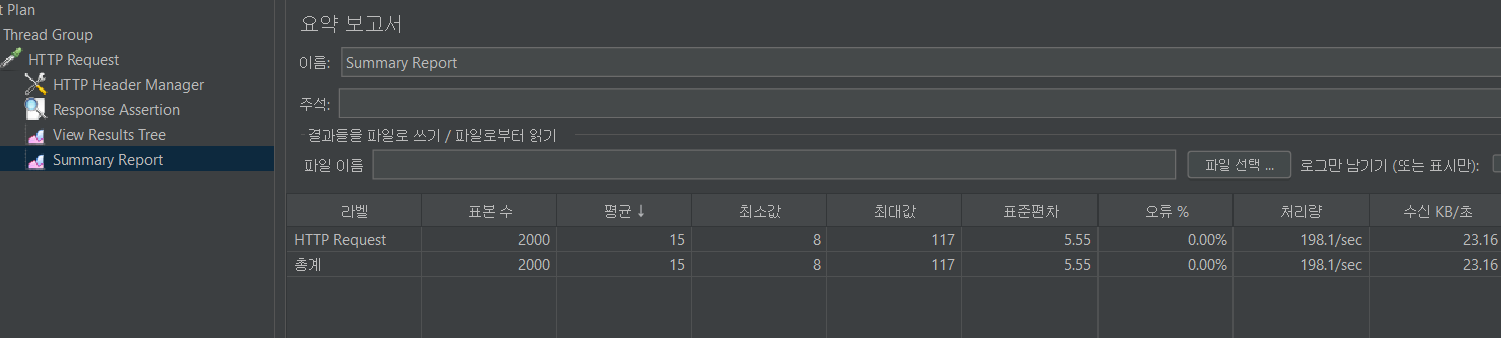
표에서는 이상이 없는 거 같은데 실제로 조 회해 본 결과 정합성에 문제가 발생했음을 알 수 있었다.
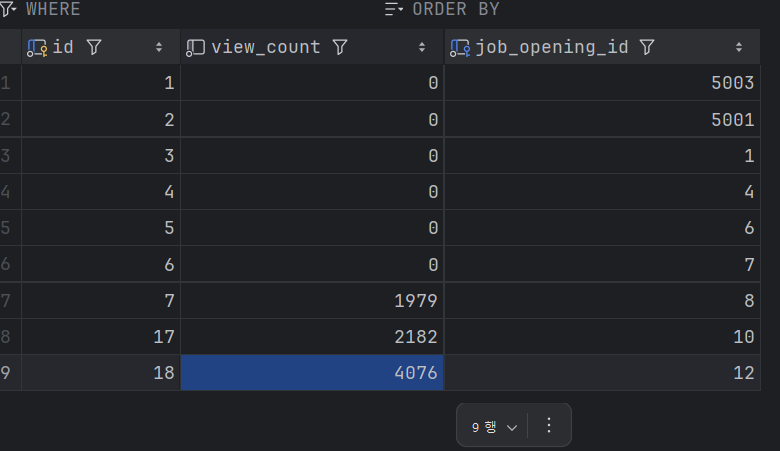
분명 2천, 2천, 4천이어야 맞는데 어째 이리 이상한 결과일까? 동시성 문제가 발생한 게 분명했다. 이제 그럼, 분산 락을 적용해보자.
왜 비관적 락은 안해요? 라는 질문을 혹시나 누군가 한다면, 애초에 레디스에는 비관적 락을 지원하지 않는다고 답하겠다.
3. 분산 락 구현하기
1. 에러, 또 에러!
이상하다 이상해..
/**
* 레디스에 있는 채용공고 조회수를 집계테이블로 업데이트 하는데 사용하는 메서드
* @param jobOpeningId
*/
public void updateViewCount(Long jobOpeningId) {
String lockKey = "JOB_OPENING_VIEW_COUNT_" + jobOpeningId;
boolean success = redisDistributedLockManager.tryLockAndRun(
lockKey,
3,
5,
TimeUnit.SECONDS,
() -> {
// 실제 처리할 비즈니스 로직 (생략)
});
if (success) {
// 락 획득에 성공한 케이스
log.info("로직 실행 완료");
} else {
// 락 획득 실패한 케이스
log.info("다른 스레드/서버에서 락 사용 중. 실행 불가");
}
}분명히 이런 식으로 코드를 열심히 짰고, 구현까지 되었다고 생각해서 돌렸는데 부하테스트랑 실제 DB반영이 달랐다.
분명히 여기서는 문제가 없다. 제이미터는 Response 조건이 200이라서 200OK 기준으로 되어있어서 그런걸까?
코드를 변경하고 성공 같은 메시지가 return 되어야할지도 모르겠다.
일단 그래서 아래와 같이 성공 메시지가 뜨게 하는 건 성공했다.
근데 정합성이 누락된다 ㅎㅎ
아무래도 문제가 생긴 거 같아서 결국 하다하다 GPT한테 물어보니 락을 획득하지 못했을 때 재시도 로직이 없으면 문제가 생긴다고 했다.
근데 이상하다, 락 획득을 못하면 제이미터에서도 실패가 떠야하는데 .... ? 그래서 스레드를 500까지 늘린 후로 재시도해보니 에러율이 높아졌다.

정합성 문제가 아직 제대로 해결되지 않은 것이다. 분산 락이다보니, 락을 걸고 해제하는 타이밍이 중요한 거 같다.
일단 제이미터에서 문제가 생긴 게 모니터링이 안되는 문제로 인해 update 메서드에서 마지막 if-else 내부를 약간 바꿨다.
if (success) {
// 락 획득에 성공한 케이스
log.info("JobOpeningId: {} 락 획득 로직 실행 완료", jobOpeningId);
return "success";
} else {
log.warn("JobOpeningId: {} 락 획득 실패", jobOpeningId);
return "fail";
}이런 식으로 락 획득 여부를 로그로 제대로 출력하고 return으로 실패인지 성공인지 여부를 반환하게 했다. 그리고도 뭔가 이상해서 재시도 로직까지 추가했는데 에러파티가 나버렸다.

으아아악 살려줘...새벽 2시의 절규와 함께 오늘도 코드가 망그러지고 있다. 진짜진짜 아쉽지만 오늘은 이정도로 하고, 내일 멀쩡한 정신으로 조금 더 해볼 생각이다. (두통이 심하다 솔직히 .ㅋㅋㅋㅋㅋ)
<출처>
https://alswns7984.tistory.com/92
https://velog.io/@ktf1686/Spring-RedisRedisson-분산락을-활용한-동시성-문제-해결
https://evga7.tistory.com/145
https://yuricoding.tistory.com/185
https://velog.io/@rkdalstj4505/Redis-분산-락Lettuce-Redisson
https://dev-monkey-dugi.tistory.com/151
https://wana.tistory.com/31
https://curiousjinan.tistory.com/entry/redis-to-rdb-data-sync
