엘라스틱 서치 데이터 스트림을 사용해야 하는데, 이 개념 자체가 나는 생소했기 때문에 도대체 뭐지? 싶어서 이곳저곳 찔러봐야 했다.
일단은 공식 문서를 참고하면서 어떤 것인지 탐구해보는 시간을 가져야겠다.
일단 공식 문서랑 이것저것 찾아본 결과, 키바나로 연결 후에 셋팅을 하라고 해서 키바나를 연결해보는데, 연결이 너무 느리게 되고 있다. 쿼드코어라서 그런건지 고질적인 문제인건지 연결 자체는 되었는데 로컬 로딩이 느려도 너무 느리다.
1. data Stream을 적용해보자
일단 이론적인 걸로는 엘라스틱 서치 데이터 스트림을 사용해서 API 호출 할 때 조회 이벤트를 저장하는 방식을 사용해야 한다고 한다.
솔직히 아직 이해는 잘 안되고 있다. 너무 어렵다.
일단 공홈이 하라는대로 해보기로 했다.

이걸로 문서를 추가해주고, 그 문서 안에 조회수에 대한 걸 넣어주면 그게 이벤트라는 거 아닌가..? 다른가? 일단 해보려고 한다.
추가해보니 이거 인덱싱인거 같다..? 음...?
뭔지 모르겠지만 일단 내부 구조가 타임스탬프, 유저, 메시지로만 추가된 게 마음에 안 드니까 삭제하고 별도로 만들어봐야겠다.
1. 인덱스 템플릿 만들기
위에서는 무작정 인덱스를 만들었었는데, 찾아보니 인덱스 만들기 전에 인덱스 탬플릿을 만들어줘야 한다고 해서 인덱스 탬플릿을 적어주고 API를 날렸다.
PUT /_index_template/jobopening-viewcount-template
{
"index_patterns": ["jobopening-viewcount*"],
"data_stream": {},
"template": {
"mappings": {
"properties": {
"@timestamp": { "type": "date" },
"jobOpeningId": { "type": "keyword" },
"viewCount": { "type": "long" },
"userId": { "type": "keyword" }
}
}
}
}이런 형태로 job
근데 PUT방식이라서 이게 맞나 긴가민가했는데, 생성한 템플릿을 조회하는 방법이 있어서 콘솔로 조회를 해봤다.
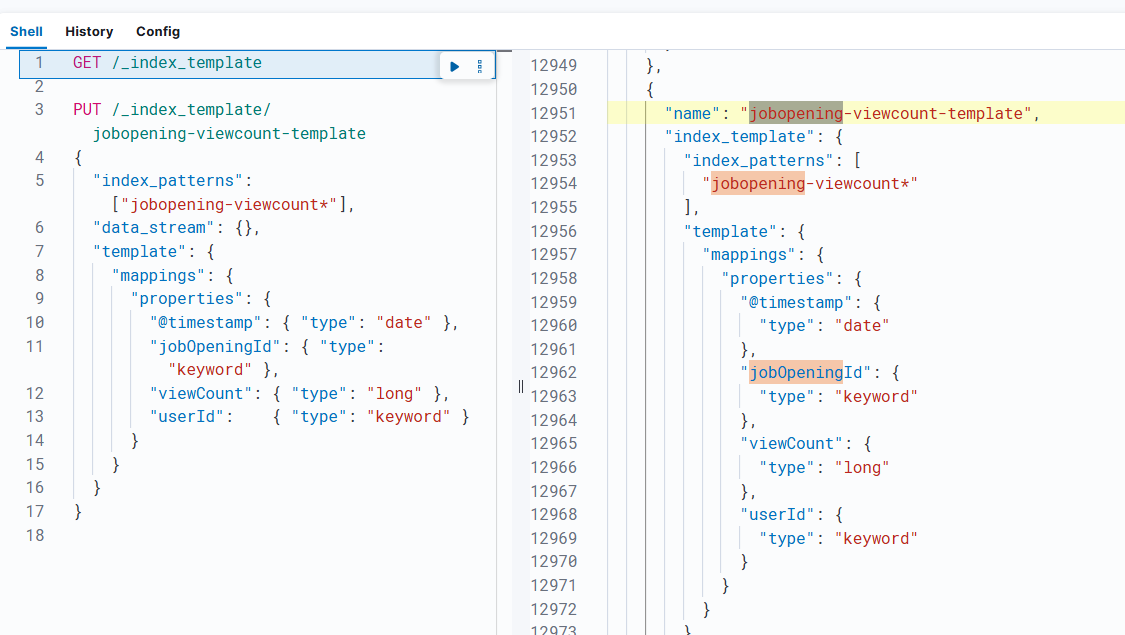
조회해보니 실제로 탬플릿이 잘 저장된 걸 확인 할 수 있었다. 솔직히 여기까지 해놓고 약간, 오? 이런건가? 싶다. 공홈을 보면서 차근차근 하면 다 될 지도 모르겠다는 희망을 가지고 계속 해보려고 한다.
2. 인텔리제이에서 Document 만들기
이제 도큐먼트를 만들어야 한다.
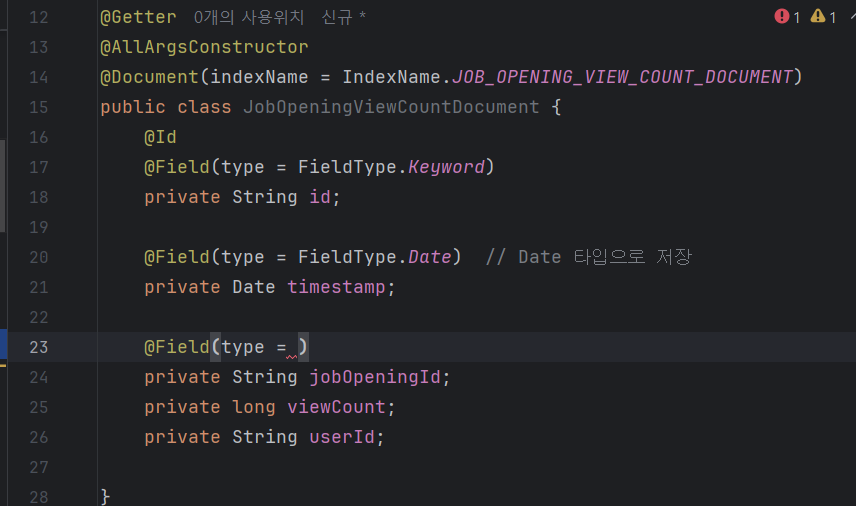
이런 식으로 만드는데, 문득 만들다가 보니 식별자를... url로 하자는 얘길 했었던 기억이 났다. 왜냐하면 우리는 실제 링크가 있는 채용공고 정보를 가져올 것이고, 크롤링을 적용한 후에 필터링을 해서 링크가 겹치지 않게 할 것이기 때문이다.
근데 이미 id 만들어놓고 탬플릿 세팅 해놔서 좀 짜증났다. ㅋㅋㅋ
사실 이거 쓰면서도 중간중간 탬플릿 잘못 써서 delete를 꽤 돌렸기 때문이다.
아무튼 그리하여 도큐먼트를 아래와 같이 완성했다.
@Document(indexName = IndexName.JOB_OPENING_VIEW_COUNT_DOCUMENT)
public class JobOpeningViewCountDocument {
@Id
@Field(type = FieldType.Keyword)
private String jobOpeningUrl; //식별자로 url을 사용하기 위함
@Field(type = FieldType.Date) // Date 타입으로 저장
private Date timestamp;
@Field(type = FieldType.Keyword)
private String jobOpeningId;
@Field(type = FieldType.Integer)
private long viewCount;
@Field(type = FieldType.Keyword)
private String userId;
}이제 API를 호출할 때 쓸 save메서드도 만들어줘야 한다. 이 와중에 3시가 되어 슬슬 자고싶어진다
2. 구현을 해보자
1. 컨트롤러에서 이벤트를 저장해보자
어제, 아니 오늘 새벽 3시에 작업을 하다가 눈이 너무 감겨서 수마에 빠져야 했다. ㅜㅜ 사람의 정신력은 아침 9시부터 새벽 3시까지 작업을 이틀 연속으로 하면 좀 약해지는 것 같다. 생각해보니 아무리 사무적으로 앉아서 하는 일이라지만 18시간을 이틀 연속으로 작업하는 건 힘든 게 맞는 거 같다.
아무튼 각설하고 현재 진행상황을 다시 돌아보기로 했다. 지금 해야할 일은 조회수 호출 시에 이벤트 저장까지 함께 되어야 하고, 리다이렉트도 되어야 하는데... 흠, 이게 생각보다 쪼끔 어려운 거 같다.
리다이렉트는 JobOpeningSerive에서 동작하도록 설계되어 있고, 조회수 이벤트는 JobOpeningViewCountService에서 동작하도록 설계되어 있기 때문이다.
이 부분을 어떻게든 고쳐봐야한다.
일단 entity 단에서 생성을 위해 정적 팩토리 메서드를 만들어줘야 하는데, 그 전에 나는 uesrId 값과 JobOpening Id 값 등을 서블릿 리퀘스트와 파라미터를 통해서 추출해와야 한다.
그래서 팀장님께 우리 보안 쪽 어떻게 되어있는지 물어보니 authUser로 가져오면 된다고 해서 그쪽으로 가져왔고, create를 만들었다.
public static JobOpeningViewCountDocument create(JobOpening jobOpening,Long userId) {
return new JobOpeningViewCountDocument(
jobOpening.getJobOpeningUrl(),
new Date(),
jobOpening.getId().toString(),
1,
userId.toString()
);
}jobOpening 값은 service 단에서 가져왔고, userId는 authUser로 추출해서 가져왔는데 약간 고민인 건 create에 JobOpening 전부를 이리 가져오는 게 맞을까?
일부 정보만 추출해서 가져오는 게 더 맞을지도 모르겠다는 생각이 문득 들어서 이쪽은 한 번 해보고 서비스에서 거르고 가져오는 방식을 택하는 걸로 고칠 수도 있을 거 같다.
1. 에러 발생
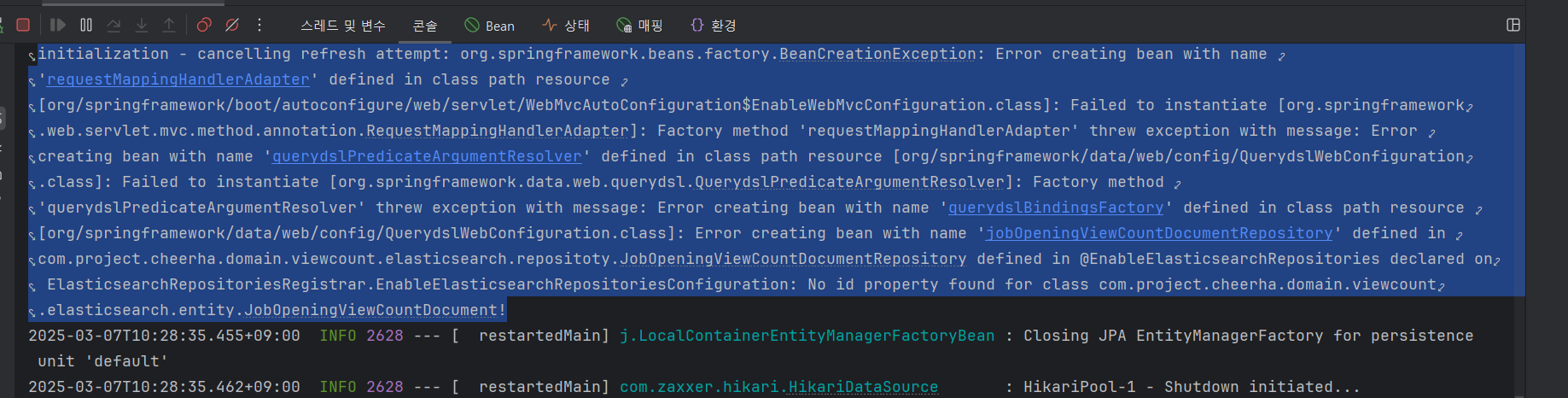
이게 뭘까...? 에러가 발생하기 시작했다. 파파고 돌려보니까 인스턴스 생성 실패, 뭐 이런거 같은데 보안 쪽 값을 가져오는 데에 실패한걸까? 아, 설마 키바나에 접속 로딩을 기다리다가 실행해서 이런건가?
뭔가 그거 일 수도 있을 거 같아서 일단 키바나에 접속 될 때까지 기다리고 로그인을 하고 다시 시도를 해보기로 했다. 나만 그런건지 모르겠지만 나는 키바나에 로컬로 바로 접속했을 때는 로그인 페이지가 안 보여서 키바나 로컬페이지를 통해서 엘라스틱 클라우드로 넘어가서 로그인하고 키바나 로컬 페이지를 다시 새로고침 하면 로그인 처리 되고 있다.
이걸 눌러주면 관리공간으로 이동되게 되고 거기서 Index Management를 눌러주면 인덱싱 쪽 공간이 나타나는 것이다.
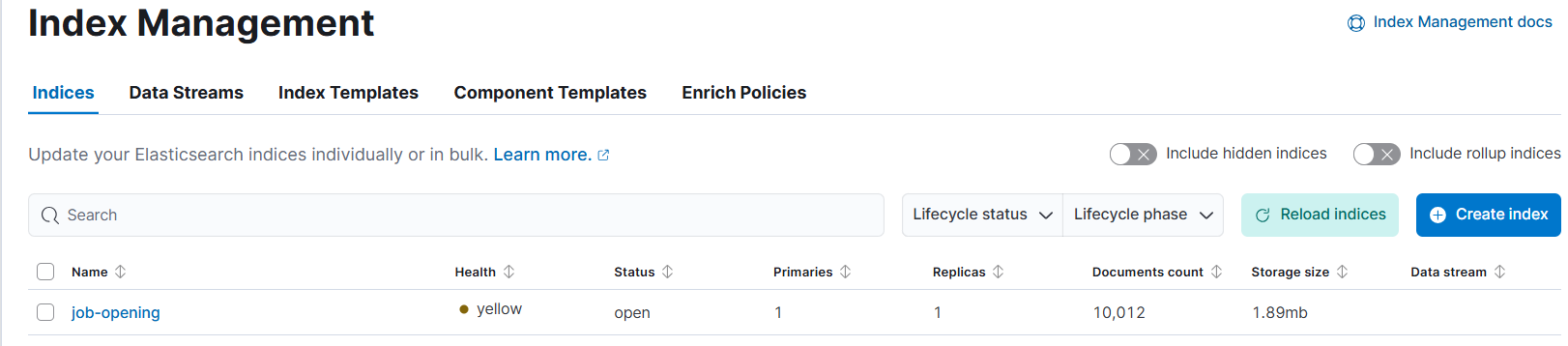
이와 같이 이미 다른 팀원이 만든 채용공고 인덱스가 나와있다면 제대로 접속이 된거다. 물론 이렇게 되려면 사전에 팀원이 내 이메일로 컨텍을 해와야 하고, 내가 그 이메일을 통해 로그인해야한다.
아무튼 이제, 한 번 더 새벽에 만든 템플릿을 확인해주고 다시 api를 실행시켜보기로 했다. 오 근데 어제처럼 콘솔로 조회하지 않아도 Index Management에 있는 IndexTemplates를 보면 내가 저장해둔 탬플릿을 확인 할 수 있다는 걸 알게되었다.
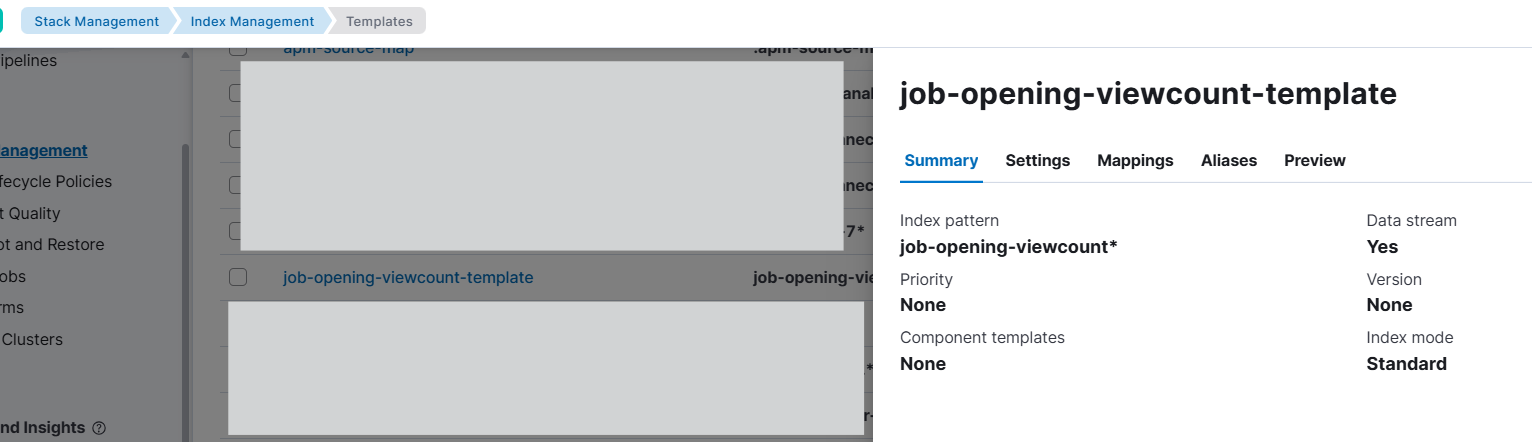
이런 느낌으로 조회가 가능하니 오히려 좋아? 심지어 삭제도 delete 안 날려도 여기서 삭제가 가능했다. 새벽에도 이 부분이 있는 건 알고 있었는데 너무 졸려서 정신이 없었던 모양이다.
또 에러메시지가 나오는데 아무래도 이게 엘라스틱 서치 쪽의 컨트롤러를 완전히 분리하지 않으면 문제가 생기는 것 같아서 컨트롤러에서는 엘라스틱 서치 관련해서 건들이지 않도록 아예 서비스 쪽에서 엘라스틱 서치 서비스로 접근하는 방식을 해보기로 했다.
여전히 같은 이유로 에러가 난다.
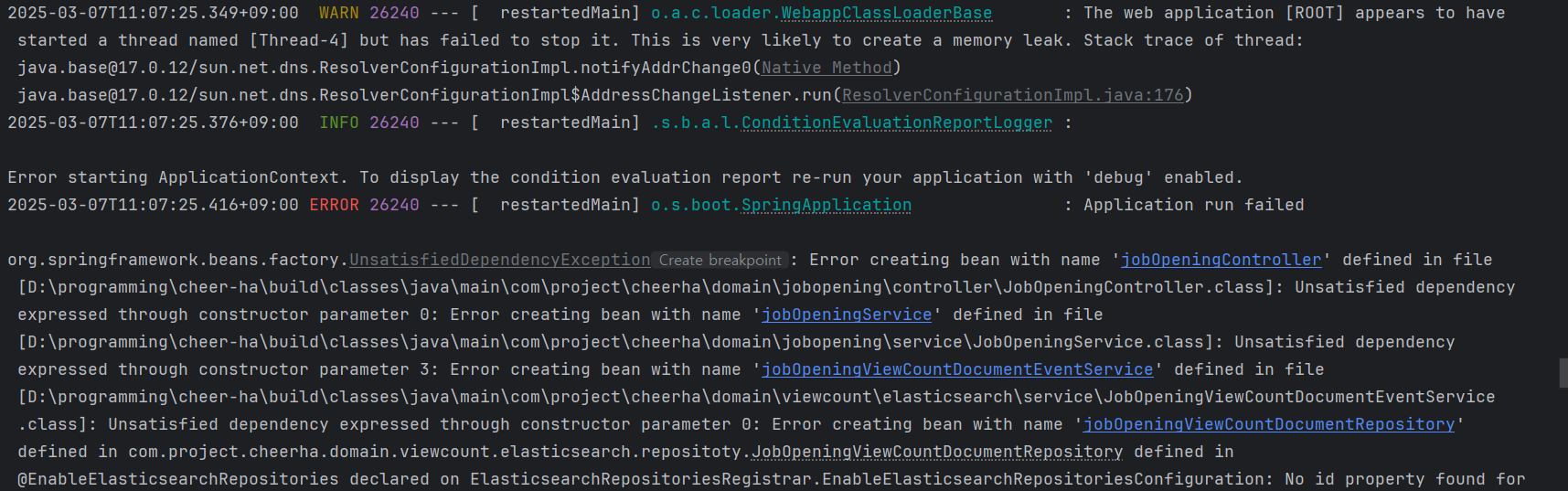
일반 컨트롤러 -> 일반 서비스 -> 엘라스틱 서치 서비스-> 이벤트 저장 이런 로직으로 했는데도 에러가 나서 진짜 리다이렉트 로직을 엘라스틱 서치에서 할 수 있게 새로 짜야하나 고민이 되기 시작했다.
2. Id에 대한 에러 해결 후, viewCount 업데이트
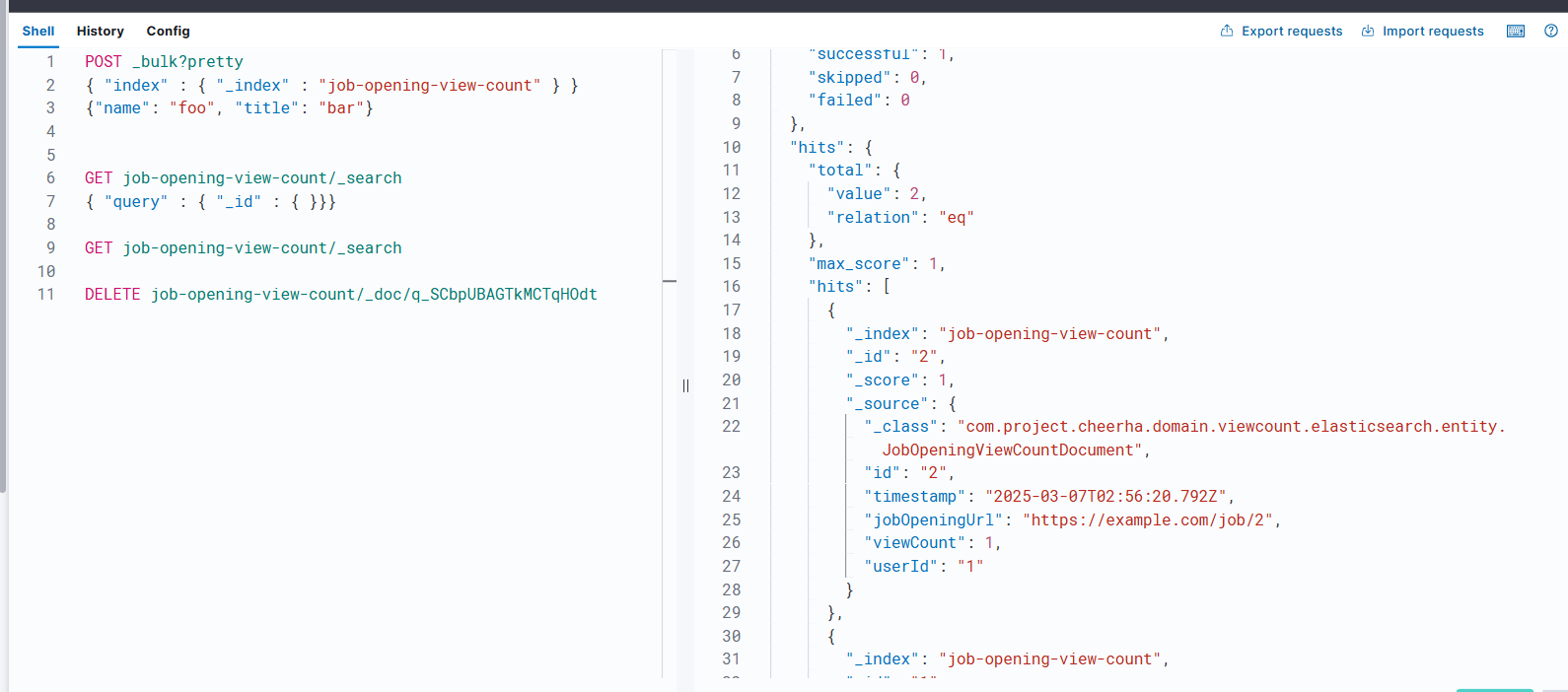
계속 id를 못 찾는 문제였기 때문에 url을 id로 삼는 걸 포기하고 그냥 식별자 id를 별도로 채용공고 id로 설정 후에 해보니 위와 같은 결과가 나왔다.
내 생각엔 채용공고 url로 식별을 하고 싶다면 채용공고 url 관리하는 테이블을 따로 빼야 맞다는 생각이 든다. 일이 너무 커지는건가?
아무튼 이건 개인적인 고민이었고, 이제는 업데이트를 적용해보기로 했다.
공홈에 보니 업데이트는 이런 식의 쿼리 구조를 가진다고 한다.
POST /my-data-stream/_update_by_query
{
"query": {
"match": {
"user.id": "l7gk7f82"
}
},
"script": {
"source": "ctx._source.user.id = params.new_id",
"params": {
"new_id": "XgdX0NoX"
}
}
}이제 이것을, 어떻게 인텔리제이에 업데이트 해야할까?
그리고 다시 어제 받은 피드백을 봤는데, 이거..? 업데이트 하는 게 아니란 걸 깨달았다. 이벤트 자체를 생성해서 viewCount는 1로 고정하고, 식별 아이디를 각각 다르게 가진 조회이벤트를 만들라는 얘기였고, jobOpeningId나 url등으로 그룹핑해서 집계해와서 동기화하면 되는 이야기였다.
오, 드디어 이해했다. 유레카..! 이렇게 하면 동시성 문제도 해결되고 (하나씩 이벤트가 만들어지기 때문에), 동기화하는 것도 문제가 없을 것이다. 후후...
3. 자동생성 id 찾아 삼만리
공식문서를 보면 엘라스틱 서치에서도 자동생성 id를 쓸 수 있는 모양이다. 근데 아무리 해도 자동생성 id를 어떻게 하는지 몰라서 찾고 또 찾아보니, 자동으로 uuid를 생성해준다는 모양이다. 근데 id 필드를 삭제해버리니까 난 또 아까처럼 id 못 찾는 에러가 나오는데... ㅠㅠ 어떻게 해야할까?
너무 안되서 GPT쳐봤더니 id 필트를 만들고 null로 매핑하란다..? 뭐지...? 이런 이상한 방식이 될 리가 없잖아!! 일단 혹시 모르니 속는 셈 치고 한 번 해봤다.
근데 왜 되지..?
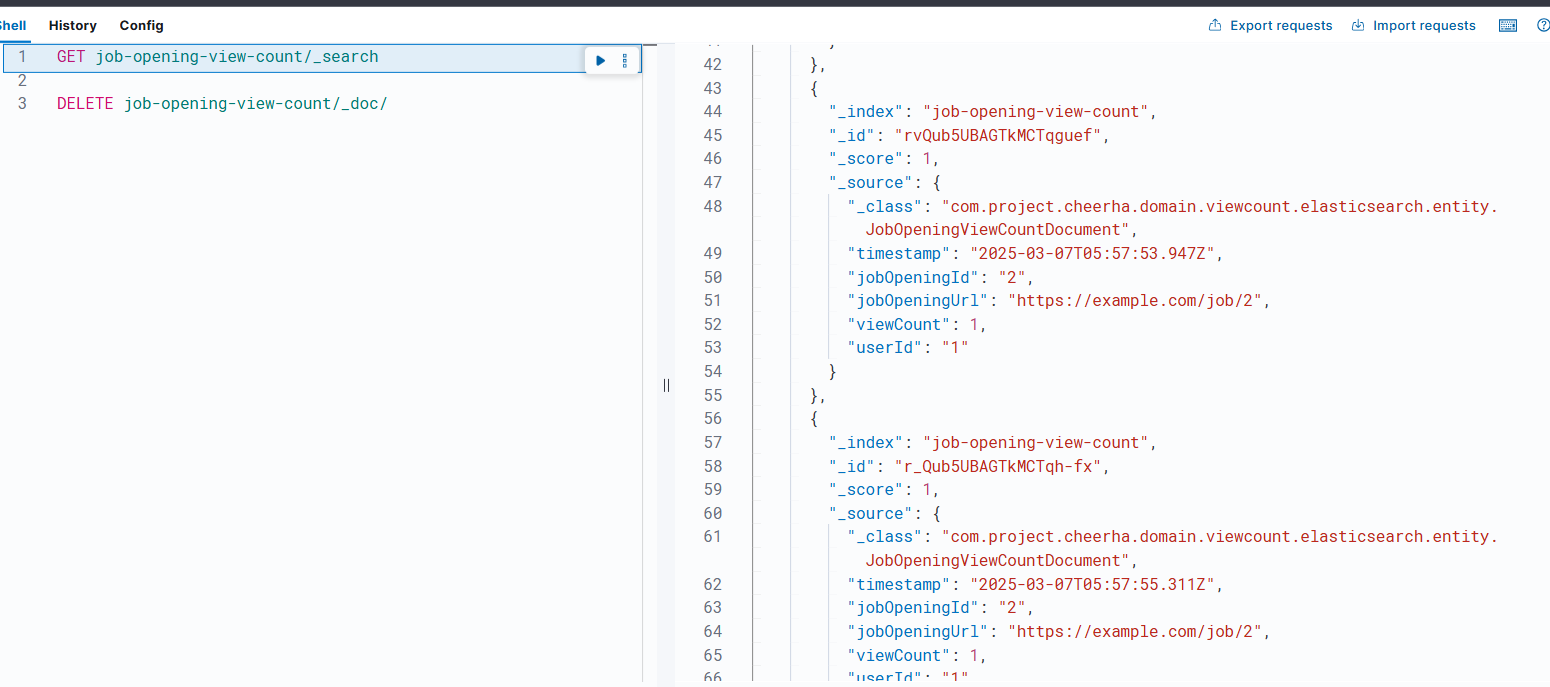
이게 되네..????????????
id에 속는 셈 치고 null을 넣었더니 진짜 uuid로 자동매핑 되어버리는 결과가 나왔다.
@Id
@Field(type = FieldType.Keyword)
private String id;
@Field(type = FieldType.Date) // Date 타입으로 저장
private Date timestamp;
@Field(type = FieldType.Keyword)
private String jobOpeningId;
@Field(type = FieldType.Keyword)
private String jobOpeningUrl;
@Field(type = FieldType.Integer)
private long viewCount;
@Field(type = FieldType.Keyword)
private String userId;
/**
* todo:이렇게 jobOpening 값 전부를 가져오는 게 맞을까? 서비스 단에서 1차 거르고 url과 id만 빼서 가져와야 할까? 고민중입니다.
* 위의 사유로 인해 리팩토링 할 가능성 있음
* @param jobOpening service에서 가져온 JobOpening 값
* @param userId 마찬가지로 Service에서 가져온 UserId값
* @return JobOpeningViewCountDocument 생성자를 이용하여 현재 이벤트에 대한 Document인덱스를 생성(내부에서 Post로 동작)
*/
public static JobOpeningViewCountDocument create(JobOpening jobOpening,Long userId) {
return new JobOpeningViewCountDocument(
null,
new Date(),
jobOpening.getJobOpeningId().toString(),
jobOpening.getJobOpeningUrl(),
1,
userId.toString()
);
}난 결국 상상 못한 방식? 인 위와 같은 방식으로 이벤트 저장에 성공해버렸다. ㅋㅋㅋㅋ
2. 저장된 이벤트를 집계해보기
집계에 대한 걸 공홈에서 뒤져보니 많긴 엄청 많았다.
이 중에 내가 하는 방식에서 맞는 집계가 무엇인지 찾아야 한다. (먼 산)
그리고 이것저것 눌러보다 뭔가 맞는 듯 한 sum에 대한 문서를 찾아냈다.
이걸 가지고.. 이제 인텔리제이에서 1분 간격으로 날리라는 건데, 스케줄러는 이미 많이 돌아가고 있다고 했더니 피드백으로 스프링 배치나 bulk insert를 쓰라고 들었다. 스프링 배치는 보다는 엘라스틱 서치 내부에서 할 수 있는 버크 인서트를 먼저 도전해 보려고 한다.
그리고 혼자 시도하다가 안되서 또 다시 공식 홈페이지를 찾아서 튜터님께 도움을 구했다.
1. 친해져라 엘라스틱 서치
일단 내가 구현부터 급하게 할 게 아니라 이쯤 되면 엘라스틱 서치에 대한 API 구조를 명확히 더 잘 이해해야 한다는 이야기를 들었다. 그래서 하나하나 보면서 집계 검색을 해보고 있다.
튜터님이 주신 약간의 꽤 큰 힌트, Terms 검색 관련 공식문서를 참고하여 집계 검색을 먼저 도전해봤다.
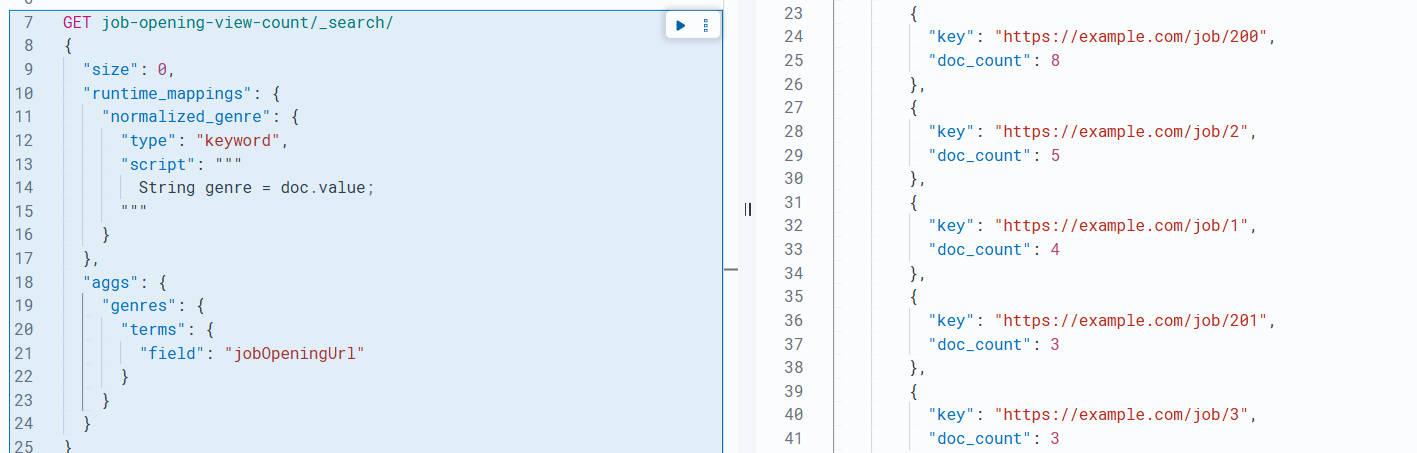
오...나 쫌 잘하나? 뭐지?? 된 거 같다는 생각이 든다. 근데 여기서 이 용어가 뭔 뜻인지, 엘라스틱 서치에서 어떤 역할을 하는지 찾아봐야겠다는 생각이 들어서 검색을 좀 해봤다. 근데 이 와중에 엘라스틱 서치 한국유튜브에 나온 개발자분이 쓴 가이드북 한글버전을 발견했다. 그래서 이 자료를 읽으면서 쓸데없는 부분을 조금 없애봤다.
2. 자바로 구현해라 엘라스틱 서치
일단 나 혼자 데굴데굴 하고 있는 와중에 공식 홈페이지에 JAVA API 관련 문서가 있다는 걸 알계되었다. 후후.. 그 중에 집계에 대한 설명인데, 음.. 나름 할 수 있을지도 모르겠다!! 라는 생각을 하며 구현을 시작해봤다.
public List<JobOpeningViewCountDocumentResponseDto> jobOpeningViewCountDocumentResponseDtoList (){
SearchResponse <JobOpeningViewCountDocumentResponseDto> response = null;
try {
response = elasticsearchClient.search(b -> b
.index(IndexName.JOB_OPENING_VIEW_COUNT_DOCUMENT)
.size(0)
.aggregations("jobOpeningUrl", a -> a
.terms(t -> t
.field("jobOpeningUrl")
)
),
JobOpeningViewCountDocumentResponseDto.class
);
} catch (IOException e) {
throw new RuntimeException(e); //todo:checked exception 과 unchecked exception 차이 공부하기 必
}
List<StringTermsBucket> buckets = response.aggregations()
.get("jobOpeningUrl")
.sterms()
.buckets().array();
List<JobOpeningViewCountDocumentResponseDto> result = new ArrayList<>();
for (StringTermsBucket bucket: buckets) {
result.add(new JobOpeningViewCountDocumentResponseDto(bucket.key().stringValue(), bucket.docCount()));
} //todo:toString과 StringValue 차이 공부하기
return result;
}그리하여 집계하는 데에 성공했다. 근데 여기서 또 문제, 집계를 어떻게 조회 수에 동기화하지...? (멍)
다른 분들이 이미 인덱싱 해 놓은 정보가 있고, 그 정보로 인기순 조회도 하고 계신데 그걸 어떻게 고쳐야할지가 난제다.
3. 조회 수를 어떤 방식으로 동기화할까?
DB에 반영을 하는 방식을 써야할까? 어떻게 반영해야할까?
이 와중에 엘라스틱 서치는 이미 구현된 인덱싱이 있다고 한다. 인덱싱을 어떻게 반영해야 할까?
PATCH나 PUT으로 엘라스틱 서치를 관리하는 방식을 쓰려고 했는데, 엘라스틱 서치를 PATCH나 PUT으로 한다고 해도 기존 값을 DELETE 하고 새로 POST 하는 방식이라고 한다. 나는 여기서 멘붕이 왔다. 어떻게 인덱싱을 집계해서 반영해야 하지?
일단 의문과 함께 이 부분을 팀장님께 이야기 했고, 회의를 더 해봐야 할 거 같다. 엘라스틱 서치를 어째서 쓰는가의 문제까지 이야기가 나와서 말이 길어졌다.
나중에 회의를 더 해봐야 할 거 같다.
<출처>
https://velog.io/@wndid2008/TIL-최종-프로젝트-11-윈도우-로컬-환경에서-엘라스틱-서치-키바나-설치법#2-키바나와-엘라스틱-서치-연결하기
https://www.elastic.co/guide/en/elasticsearch/reference/current/data-streams.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/use-a-data-stream.html#add-documents-to-a-data-stream
https://www.youtube.com/watch?v=JqKDIg8fgd8&t=46s
https://blog.naver.com/ghostlover23/222234345558
https://stdhsw.tistory.com/entry/Elasticsearch%EC%9D%98-Index-template-%EC%84%A4%EC%A0%95
https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-update.html
https://docs.spring.io/spring-data/elasticsearch/reference/elasticsearch/object-mapping.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/tune-for-indexing-speed.html#indexing-use-faster-hardware
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-metrics-sum-aggregation.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-bulk.html
https://docs.spring.io/spring-data/elasticsearch/reference/elasticsearch/misc.html
https://esbook.kimjmin.net/08-aggregations/8.2-bucket-aggregations
https://flambeeyoga.tistory.com/entry/엘라스틱서치elasticsearch-집계
https://www.elastic.co/search-labs/blog/esql-queries-to-java-objects
https://www.elastic.co/guide/en/elasticsearch/client/java-api-client/current/aggregations.html
