이제 V2를 만들 때가 왔다. 동시성 제어!!!
그리고 이 사이에 우리에게 나름 큰 이슈가 있었다. 바로 크롤링 이슈였다.
1. 서론, 크롤링에 대하여
어제 저녁, 갑자기 시간이 조금 남은 나는 크롤링을 덥석 물었다. 근데 크롤링은 아무나 못 한다네!?!?!?
robot.txt 사이트로 합법적인 크롤링 사이트를 검수해야 하고, 마침 내가 크롤링하려 했던 사이트가 다 막혀있다는 걸 발견했다.
? 이거 IP차단이라는디유..?
팀원들 : ???
결국 회의, 또 회의, 또 이야기, 이야기를 거쳐서 결론이 안 나왔다.
불법인가요? > 아닌가요? > 돌아가나요? > 배포해도 되나요? > 일부 사이트만 하나요?
결론이 데굴데굴 굴렀는데 그 와중에 우리는 자바 스프링을 공부한 사람들인데 쌩판 모르는 파이썬 크롤링이 두-둥 하고 비중을 차지하는 문제로 인해 고민도 많고 실제로 힘들기도 했다는 이야기가 나왔다.
그리하여 오늘 아침, 우리는 크롤링을 안 하고 더미데이터를 적용해서 기능을 구현하는 것에 집중하기로 했다.
2. 락에 대한 고민
1. 비관적 락을 사용할까?
나는 최종은 Redis를 사용하기로 하고, 현재는 v2이므로 비관적 락을 적용하는 걸 생각했다. 왜냐하면 정합성을 생각하면 비관적 락이 조회수의 유실이 없게 잘 막아주어 데이터의 집계율이 정확할 거 같았기 때문이다.
그래서 비관적 락을 사용한 후에 테스트코드나 도커를 사용해서 동시성 체크가 잘 되는 지 확인하는 방법을 쓰려고 했던 것이다. 그런데 사실 이 부분이 나도 고민이 되었던 부분이라서 바로 결정을 해서 해버리는 게 아니라 다른 분들의 의견을 구해봤다.
일단 고민한 부분은 다음과 같았다.
- 비관적 락은 속도가 느려질 가능성이 높은데 괜찮을까?
- 굳이 비관적 락을 써야 할 만큼 이 코드가 조회수 하나하나가 중요할까?
- 그래도 인기는 채용공고를 확인하는 것이니만큼 조회수에 따라 순위가 매겨지는 건데정합성을 따지면 비관적 락이 낫지 않나?
그리고 나는 다른 팀원들과 의견을 모아 본 결과 단순한 카운팅 방식이고, 조회수 하나하나가 엄청나게 중요하지 않다는 판단을 내릴 수 있었다. 오히려 비관적 락의 단점이 우리의 코드에 부하를 줄 수 있다는 점을 생각할 수 있게 되었다.
2. 낙관적 락을 사용할까?
어제 썼던 게시글처럼 동시성 제어에는 100% 정답이 없다고 본다. 하지만 이번 프로젝트는 채용공고에 대한 조회수의 동시성 제어라는 점에서 낙관적 락을 해보자는 판단이 들었다.
사실 이야기 하던 중에 들어본 건데 채용공고 순위가 그렇게 조회수 1~2개 차이로 엎치락 뒤치락 할 거 같지 않다는 이야기였다. 결국은 수십, 수백회가 차이가 날 가능성이 더 높다는 판단이 들었고 그렇다면 굳이 여기서 비관적 락을 걸어서 db에 과부하를 유발하는 게 더 비효율적이라는 생각이 들었다.
3. 락을 걸고, 테스트 코드 파이어
테스트 코드를 몇 시간 째 수정, 또 수정, 또 수정하지만 진척이 안되고 있다. 흑흑.. 너무 슬프다.
이미 여러가지 예시코드를 보고 왔는데 일단 또 고민인 부분이 있었다. 테스트 코드를 작성할 때 나는 전에는 그냥 given, when, then으로 나눠서 given에 초기 데이터 그냥 임의로 다 때려넣는 방식을 했엇다. 근데 락을 걸기 위한 데이터는 그렇게 넣을 수가 없다는 생각이 들었다.
??? 그럼 어떻게 넣어야 하는가? 팀원 분의 도움과 구글링, GPT 등을 토대로 알아본 결과, @BeforeEach라는 어노테이션을 사용하는 걸 알게되었다. 이거 뭔가 AOP때 본 @Before 어노테이션이랑 비슷한 거 같은데? 라는 생각이 들었는데, 찾아보니 실제로 그런 느낌이었다. 테스트 시작 전에 조성되는 초기값을 세팅하는 용도로 쓰인다고 했다.
그리고 AfterEach도 테스트가 끝나고 더미들을 삭제하는 그런 기능이다.
1. 끝나지 않는 테스트 코드
그래서 열심히 만들고 있는데 도대체 끝날 기미가 안 보이네!?
솔직히 비관적 락은 시간이 좀 걸릴 거라고 생각했는데 낙관적 락은 방심했다.
아니 어쩌면 내 스스로가 테스트고자라는 점에 대해 방심한 걸지도 모른다. 내가 짜 놓은 낙관적 검증은 정말 해맑고 낙관적이게 버전만 적은 게 다란 말이다!!!! 싸우잔 거냐 테스트코드!!!
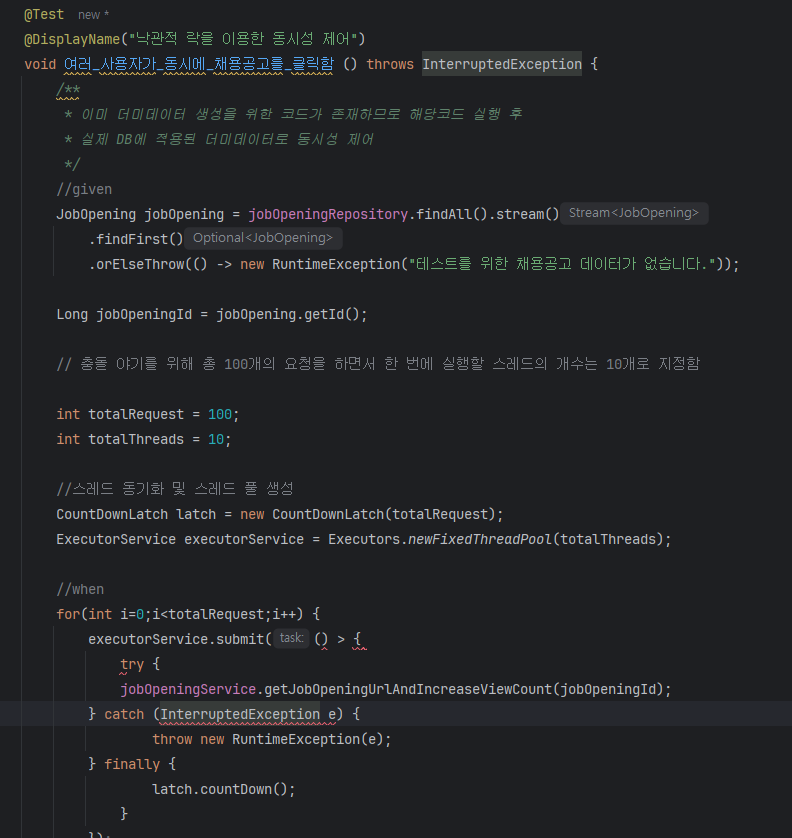
분명히 열심히 찾아보고 만드는데 저기서 왜 에러가 나지...??????????
인터럽트...인터럽트 exception에 대해 찾아봐야 한다. 결국 뭔 이유인지 모르고 일반 exception으로 처리하는 걸로 한 후에 뒷부분에 인터럽트를 추가해서 구성을 완료했다.
그리고 드디어 된건가? 하고 일단 더미데이터를 생성해보는데 이게 뭐지...
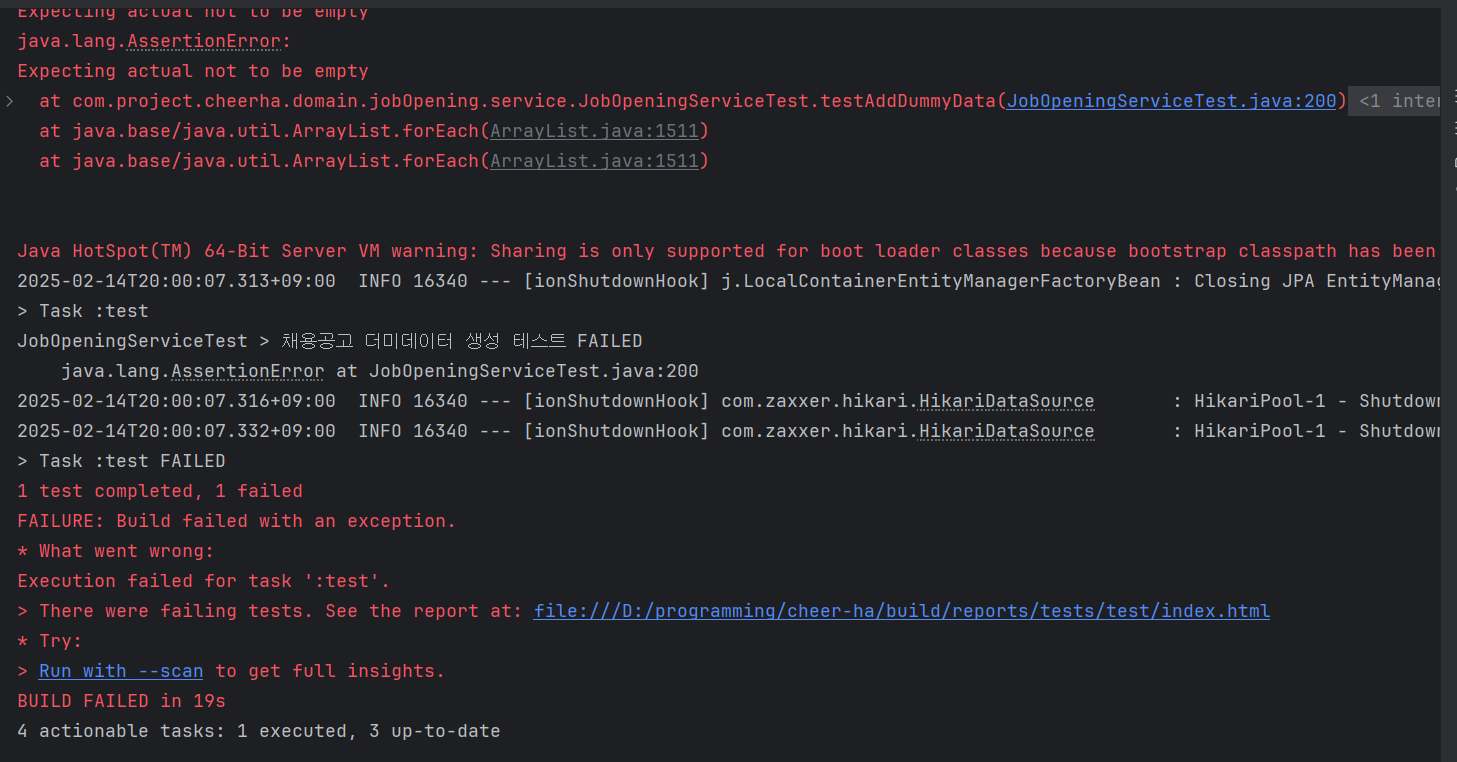
2. 테스트 코드가 너무해
테스트 코드가... 저건 심지어 내가 짠 것도 아닌데 이럴 리 없다. 어디가 안 맞는 게 분명하다.
그래서 일단 일반 모드로 돌려봤다.

근데 이건 또 되는데...???????????
도대체 뭔 말인지 알아먹을 수가 없어서 결국 GPT에게 물어보니 영속성 컨텍스트 문제라는 것 같다. 아무래도 내가 일부 데이터를 물리적으로 데이터 베이스에서 지웠는데 그게 문제가 생긴 것 같다.
ㅎㅎ 내 잘못인 걸 직감했지만 정말이었군.

아예 싹 밀어주고 재실행하니 더미데이터는 다시 성공적으로 돌아왔다. 다른 사람 코드를 내 꺼 때문에 망친건가!? 연관이 있던 부분이 있었나!?!? 하고 놀랐는데 아니어서 다행이다.
그리고 어....???? 낙관적 락을 위한 테스트 코드가 잘 작동되긴 했다.

설마.... 이게 실화인가..????? 이게 맞나..??????
설마 낙관적 락이 이렇게까지 성공률이 낮을 수도 있구나.... 싶었고 근데 현실적으로 충돌 날 가능성이 낮아서 낙관적 락 아니던가? 테스트 코드를 잘못 짰나? 너무 타이트하게 마치 비관적 락 테스트하는 것마냥 100개의 요청을 하면서 10개의 스레드를 작성한 게 문제 아니었을까?
일단 내가 낙관적 락 테스트의 개념을 제대로 못 이해하고 작성한 거 같다는 생각이 문득 들었다.
3. 테스트는 되었지만 공부를 더 해라 휴먼
위에서 판단한 것을 고친 후, 20과 5, 5와 5로도 테스트를 진행했으나 다 비슷한 느낌의 결과가 나왔다. 락이... 좀 많지 않나? 라는 생각이 들긴 했지만 한편으로는 우리 더미데이터가 현재 테스트로 생성하는 데이터 말고 csv 파일을 만들어놔서 ...그게 1만개라는 이야기를 들었다.
그러면 낙관적 락도 나쁘지 않을지도 모른다.
정말 모르겠다는 생각에 결국 튜터님께 찾아갔는데 내가 정말 바보같았다는 답변을 받았다. 낙관적 락의 모토는 낙관적인 생각으로 ... 시작되는 거라는 얘기였다.
애초에 충돌이 안 날 거라고 생각하고 작성하는 락이잖아요? 당연히 충돌을 내면 그만큼 많이 락이 걸리겠죠?
아, 그렇구나....
비관적 락도 해봐야겠구나, 하는 슬픔이 느껴졌다.
