이제 나는 결합도도 낮추고, 테스트 코드도 작성했고.. 팀원 간의 보안 문제도 검수 끝냈고, 여기저기 코드 리뷰도 어느정도 했고..? 그러다보니 엘라스틱 서치를 할 때가 된 거 같다.
1. 엘라스틱 서치가 뭐지?
1. 엘라스틱 서치의 정의
Elasticsearch란 Apache Lucene 기반의 JAVA 오픈소스 분산 검색 엔진이라고 한다. 아파치 루씬이란, 자바언어로 이루어진 정보 검색 라이브러리라고 한다.
그니까 정보 검색 라이브러리를 기반으로 한 분산검색 엔진 되시겠다 이 말이다.
Elasticsearch는 Logstash나 Kibana와 같은 도구들도 함께 사용될 할 수 있다.
Logstash는 데이터 이동 과정에서 구문을 분석하고 변환하는 필터이며, Kibana는 Elasticsearch의 데이터를 분석하여 시각화하는 프로그램이다.
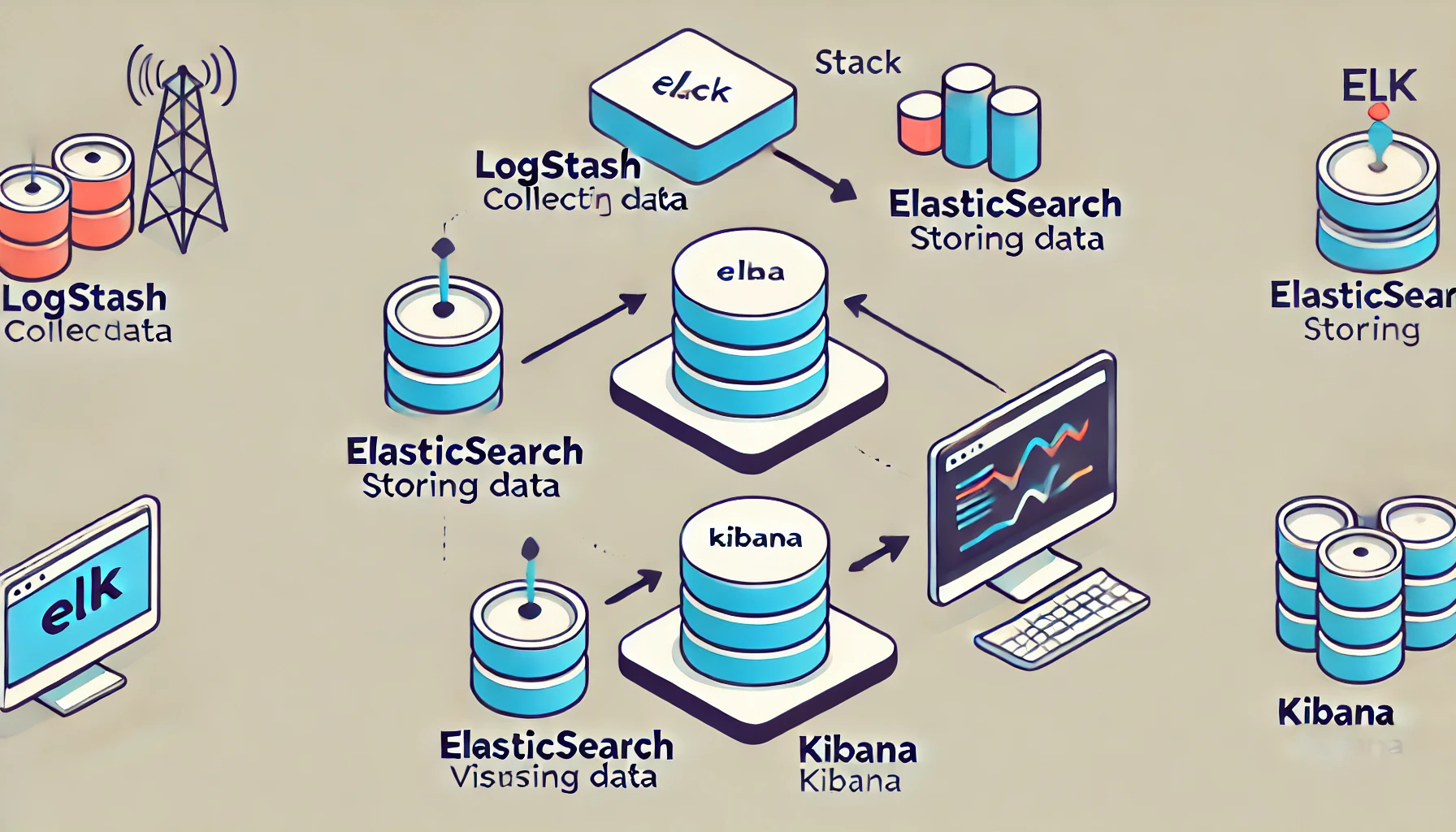
이렇게 3가지를 함께 사용하는 구조를 ELK 스택이라고 한다.
아래는 GPT에게 부탁해서 그려본 ELK 스택 구조 이미지화이다. 엘라스틱 서치가 진행되고, Log가 찍히고, kibana가 구현되는 이미지다.
Elasticsearch는 indexing작업을 통해 다양한 데이터를 빠르게 검색할 수 있는데 인덱싱(색인)이란 쉽게 말해서 정보에 번호(인덱스)를 붙이는 작업이라고 볼 수 있다.
번호를 붙이게 되어 더 빠르게 문서의 내용을 분석할 수 있고, 검색을 효율적으로 하기 위한 데이터 구조로 재탄생되는 과정이라고도 볼 수 있다.
인덱싱은 주로 문자열, 리스트 같은 자료구조에서 활용되는데 할당받은 번호로 원하는 문자를 가리키는데 사용된다.
2. 엘라스틱 서치의 특징
엘라스틱 서치에서는 index, shard, replica 등이 있는데 index는 위에서 설명했다시피 번호를 붙여서 데이터를 빨리 찾게해주는 것이다.
샤드는 데이터를 분산해서 저장하는 방법을 의미하는데 검색 기능 향상을 위해 index를 여러 샤드로 쪼개서 사용한다. 이러한 쪼개는 방식을 Scale-out이라고 한다.
그리고 레플리카는 샤드의 또 다른 형태라고 할 수 있다. 이는 노드를 손실했을 때 데이터가 신뢰받을 수 있도록 안전하게 샤드를 복제해두는 것이다. 이로 인해 엘라스틱 서치는 데이터의 안정성을 보장해줄 수 있다.
별도의 Schema 없이 Json 형태로도 Mapping 기능을 통해 스키마 정의가 가능한 것이 특징이라고 한다. 물론 자동 스키마 생성을 지원하긴 데이터 유형에서 오류 발생 확률이 있으므로 명시적으로 매핑 설정을 할 것이 권장된다고 한다.
그리고 추가 설명을 하자면 Elasticsearch는 스키마리스(Schema-less)처럼 동작하지만, 내부적으로는 매핑(Mapping)을 통해 데이터 구조를 정의하는 것이라고 한다. 솔직히 내 설명이랑 뭐가 다른지 모르겠다
그리고 CRUD 호출 시에도 HTTP RESTful API(POST,GET,PUT,DELETE)로 수행되는 것이 특징이다. 뭔가 포스트맨의 향기가 느껴진다
3. 엘라스틱 서치의 사용 이유
그래서 우리는 엘라스틱 서치를 왜 적용해야 하는가? 도대체 어째서?
일단 나는 사용자가 추가한 즐겨찾기와 키워드를 사용자가 입력한 연령대에 한정을 지어서 인기 순 10개를 검색하는 API를 구현했었다. 그런데 아무래도 직접 추가된 키워드나 즐겨찾기를 갯수 카운팅해서 정렬을 하다보니까 로직이 복잡해졌다.
그나마 키워드는 양반인 게 45개가 전부였지만 즐겨찾기는 채용공고 자체가 1만건이었기 때문에 집계하는 것 자체가 오래걸리는 문제가 발생하는 것이다. 결과적으로 체감상 조회 버튼을 누르고 몇 초 이상 기다려야만 겨우 검색이 되는 결과가 나오게 되었다. 이게 단순 API 하나일 때 이정도라면 본격적인 서비스 로직 전부를 엮어두면 매우 느려질 것이라는 판단이 들었다.
이러한 이유로 인해 나는 속도 개선을 하려고 엘라스틱 서치를 적용하기로 한 것이다.
엘라스틱 서치의 사용 이유는 속도인 게 확실한데, 이게 왜 빠른가? 단순히 인덱싱이 되어서 빠른가? 그것 또한 알아야 한다고 생각한다.
엘라스틱 서치에는 역색인(역인덱스)이라는 것이 있다. 영어로는 inverted index라고 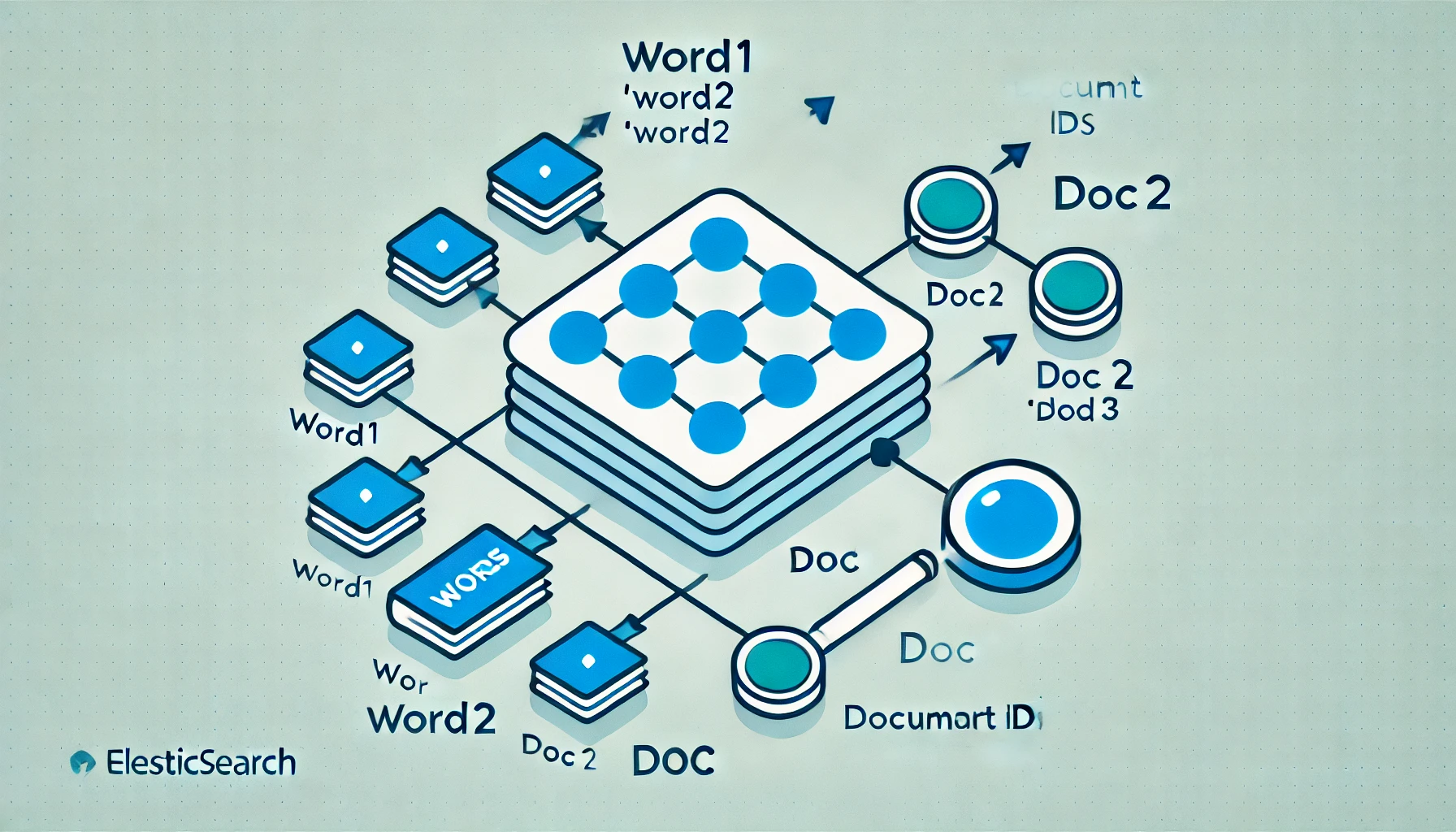
마치 이러한 형태로 문자(word)와 id(docs) 구조로 되어있다.
문서 id는 문자를 구별하는 숫자에 해당된다.
역색인에서는 우리가 알아야 하는 문자가 앞에 오고, 뒤에 번호가 붙어버리는 것이다. 똑같이 검색하는 것이지만 정보가 먼저 앞에 있어서 번호로 구분해서 찾을 수 있는 것과, 번호로 검색해서 정보를 찾는 것은 다르다. 번호로 특정 문자를 저장하게 되면 겹치는 문자가 있더라도 서로 다른 번호로 저장되어서 더 느려질 수 밖에 없다. 이에 반해 역색인을 사용하면 특정 문자를 여러 개의 번호로 나누어 저장할 수 있기 때문에 검색 속도가 빨라진다는 것이다.
4. Elasticsearch의 아키텍처
Elasticsearch는 분산 시스템으로, 여러 개의 노드(Node)로 이루어진 클러스터(Cluster) 구조를 가지고 있다.
-
Cluster: 여러 노드(Node)로 구성된 하나의 Elasticsearch 시스템.
- 클러스터는 Elasticsearch 시스템을 구성하는 가장 큰 단위이다.
- 독립적으로 운용되기 때문에 서로 다른 클러스터끼리는 데이터 접근이나 복제 등이 제한 된다.
-
Node: Elasticsearch의 실행 인스턴스. (Master Node, Data Node, Ingest Node)
- 모든 노드는 클러스터 내에서 각자 역할을 부여받아 실행된다.
-
Shard: 데이터를 분산 저장하는 기본 단위.
- 샤드를 통해 대량의 데이터를 효율적으로 관리할 수 있다.
- 스케일 아웃 방식으로 사용된다.
-
Replica: 샤드의 복제본으로, 데이터 백업 및 가용성을 높인다.
- 데이터가 손실되었을 때 복구할 수 있게 된다.
5. Elasticsearch의 데이터 흐름
1. 데이터 저장 (Indexing)
- 데이터 수집: Logstash, Beats, 혹은 API를 통해 데이터를 수집한다.
- 데이터 변환 및 처리: Logstash를 사용하여 데이터를 정규화하고, 필요한 경우 변환 작업을 수행한다.
- 데이터 인덱싱: 데이터를 Elasticsearch에 저장할 때, JSON 형식으로 문서(Document)를 생성하고 이를 인덱스(Index)에 저장한다.
- 데이터를 저장할 때 JSON 형식을 사용하기 때문에 스키마없이도 구현이 된다.
- 이러한 특징으로 인해 정형화 되지 않은 자료라 해도 인덱싱이 쉽게 가능하다.
- 그러나 자동으로 인덱싱을 해주면서 오타나 문제 발생 시에 이중으로 자료가 전송되어 제대로 된 결과값이 안 나오는 경우도 발생할 수 있다.
- 역색인(Inverted Index) 생성: Elasticsearch는 데이터를 저장할 때 자동으로 역색인을 생성하여 검색 속도를 높인다.
내가 인덱싱 부분에서 오타나 문제 발생을 언급한 이유는 실제로 우리 팀에서 나보다 더 먼저 엘라스틱 서치 API를 적용하시던 분이 테이블명에_가 붙은 것과 -가 붙은 차이를 모르고 API를 구현한 것 때문에 결괏값이 제대로 안 나온 적이 있다. 이 오타를 찾을 때까지 몇 시간이고 고생하시는 걸 보니 확실히 이 부분은 어찌보면 단점이라고도 생각이 들었다.
2. 데이터 검색 (Query DSL 사용)
- Query DSL (Domain Specific Language): Elasticsearch에서 제공하는 JSON 기반의 검색 언어
- 매칭 질의 (Match Query): 사용자가 입력한 키워드와 가장 잘 맞는 문서를 검색
- 범위 질의 (Range Query): 특정 범위에 속하는 데이터를 검색할 때 사용
- 날짜, 숫자 범위 등을 검색할 때 사용
- 집계 (Aggregation): 데이터를 그룹화하거나 통계를 계산할 때 사용한다.
- 인기 순위, 평균 계산, 조회 수 등을 검색할 때 사용
- 필터링 (Filtering): 검색 결과에서 특정 조건에 맞는 데이터만 남긴다.
데이터 검색 엔진이니 만큼 확실히 검색에 있어서 편리한 기능들이 많이 있는 것 같다. QueryDSL의 동적쿼리를 써서 이미 대부분 구현이 되어있긴 하지만 그래도 같은 검색조건이어도 엘라스틱 서치가 빨라진다고 해서 기대를 하고 있다.
6. 성능 최적화 및 주의점
1. 성능 최적화 방법
- Shard 수 조정: 데이터 양과 클러스터의 노드 수에 맞춰 적절한 샤드 수를 설정
- Replica 설정: 안정성을 위해 레플리카를 사용하지만, 과도한 레플리카는 오히려 성능을 저하를 야기할 수 있다.
- Refresh Interval 설정: 검색 빈도가 낮은 경우, 인덱스의 refresh interval을 늘려 성능개선 가능
- Bulk API 사용: 대량의 데이터를 처리할 때 Bulk API를 사용하면 성능이 대폭 향상되게 할 수 있다.
- 필터 캐싱: 자주 사용되는 필터는 캐싱을 통해 속도를 개선할 수 있다.
2. 주의할 점
- Shard가 너무 많거나 적으면 문제 발생
- 샤드가 많으면 메모리 소모가 커진다.
- 샤드가 너무 적으면 데이터 분산 효과가 떨어진다
- 메모리 관리: JVM 메모리를 적절히 설정하고, Out of Memory (OOM) 에러를 방지하기
- 데이터 모델링: 인덱스 구조를 잘 설계하여, 불필요한 데이터 중복을 피해야 한다.
<출처>
https://victorydntmd.tistory.com/308
https://ko.wikipedia.org/wiki/%EC%95%84%ED%8C%8C%EC%B9%98_%EB%A3%A8%EC%94%AC
https://www.elastic.co/kr/logstash
https://www.elastic.co/Kr/kibana
https://escapefromcoding.tistory.com/693
https://aws.amazon.com/ko/what-is/elk-stack/
https://tecoble.techcourse.co.kr/post/2021-10-12-scale-up-scale-out/
https://velog.io/@koo8624/Database-Elastic-Search-2%ED%8E%B8-%EC%95%84%ED%82%A4%ED%85%8D%EC%B2%98Architecture
https://twofootdog.tistory.com/53
수제비 2024 정보처리기사 실기 1권 p6-171
