데이콘 월간데이콘 참여하다가 어떤분이 코드 공유해주셔서 돌리다가 베이스라인과 전처리 코드가 다른 것을 알게됨
url에 [.]을 . 로 바꾸는 작업인데 베이스라인에서는 str.replace를 사용하였지만 그 분은 apply lambda x: x.replace를 사용하심 같은 결과였지만 속도적으로 어떤 차이가 있을지 궁금해서 코드를 더 돌려보았음
import numpy as np
import pandas as pd
import os
import datetime
# Load data
data_path = "/home/juyoung-lab/ws/dev_ws/dacon/da_url_detection/open"
count = 10
results = []
for i in range(1, count+1):
train_df = pd.read_csv(os.path.join(data_path, 'train.csv'))
test_df = pd.read_csv(os.path.join(data_path, 'test.csv'))
tic = datetime.datetime.now()
train_df['URL'] = train_df['URL'].apply(lambda x: x.replace('[.]', '.'))
test_df['URL'] = test_df['URL'].apply(lambda x: x.replace('[.]', '.'))
tok = datetime.datetime.now()
time_result = tok - tic
results.append(time_result)
print(f"apply replace Average Time: {np.mean(results)}")
results = []
for i in range(1, count+1):
train_df = pd.read_csv(os.path.join(data_path, 'train.csv'))
test_df = pd.read_csv(os.path.join(data_path, 'test.csv'))
tic = datetime.datetime.now()
train_df['URL'] = train_df['URL'].str.replace(r"\[\.\]", ".", regex=True)
test_df['URL'] = test_df['URL'].str.replace(r"\[\.\]", ".", regex=True)
tok = datetime.datetime.now()
time_result = tok - tic
results.append(time_result)
print(f"str replace Average Time: {np.mean(results)}")
결과는 .apply(lambda x: x.replace('[.]', '.')) 를 사용하는 것이 약 1.2초 정도 빨랐음 ㄷㄷㄷㄷㄷ

str.replace는 pandas 문법인 것 같았는데 apply가 pandas 문법이 아니라는게 신기했음
여기서 gpt가 지적한게 regex=True 가 문제라고 해서 지우고 다시 해봄
이번엔 위 코드에서 regex=False로 바꾸고 다시 해봄

결과는 빨라졌지만 문제가 있음
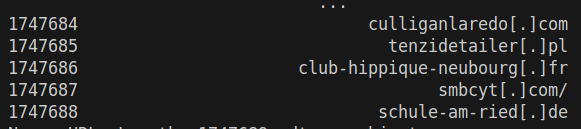
안바뀐다는거임
train_df['URL'] = train_df['URL'].str.replace('[', '', regex=False).str.replace(']', '', regex=False)
test_df['URL'] = test_df['URL'].str.replace('[', '', regex=False).str.replace(']', '', regex=False)
그레서 이렇게 문자를 하나 씩 바꿈
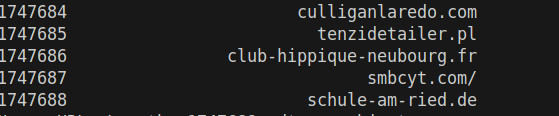
[.]에서 [ ] 가 지워지는걸 확인했지만

결과는 유사함
정규식 검사하는 속도가 무시못하는걸 알게됨

안드로이드와 인공지능에서 살아남기