질문의 핵심
- 페이징이란?
- 페이징의 장단점은?
- 세그멘테이션이란?
- 세그멘테이션의 장단점은?
- 내부 단편화와 외부 단편화의 차이?
- 메모리 단편화의 해결법은?
1. 주소 할당(Address Binding)
프로세스 주소(Process Address)
프로세스 주소는 논리적 주소(Logical Address)와 물리적 주소(Physical Address)로 나뉜다.
논리적 주소
가상 주소(Virtual Address)라고도 한다.
CPU가 생성하는 주소이며, 프로세마다 독립적으로 가지는 주소 공간이다.
물리적 주소
프로세스가 실행되기 위해 실제로 메모리(RAM)에 올라가는 위치이다.
주소 할당
어떤 프로그램이 메모리의 어느 위치에, 어떤 물리적 주소에 load될지를 결정하는 과정.
할당 시점에 따라 다음과 같이 분류된다.
Compile Time Binding
프로세스의 물리적 주소가 컴파일 때 정해진다. 프로세스가 메모리의 어느 위치에 들어갈지 미리 알고 있으므로 컴파일러는 고정된 주소를 생성한다. 만약, 위치가 변경된다면 재컴파일을 해주어야 한다. 컴파일 타임 주소 할당은 프로세스 내부에서 사용하는 논리적 주소와 물리적 주소가 동일하다.
Load Time Binding
프로세스가 메모리의 어느 위치에 들어갈지 미리 알 수 없어 컴파일러는 Relocatable code를 생성한다. Loader가 프로세스를 메모리에 load하는 시점에 물리적 주소를 결정한다. 따라서, 논리적 주소와 물리적 주소가 다르다.
Execution Time(Run Time) Binding
프로세스가 수행이 시작된 이후에 프로세스가 실행될 때 메모리 주소를 바꾸는 방법이다. 실행 도중 주소가 바뀔 수 있다.
런타임 주소 할당은 MMU(Memory Management Unit)라는 하드웨어 장치를 사용하여 논리적 주소를 물리적 주소로 바꿔준다.
2. 메모리(Memory)
메모리란?
운영체제에서 메모리란 메인 메모리(주 기억장치), 즉 RAM을 뜻한다. 프로그램 실행 시 필요한 주소, 정보들을 저장하고 가져다 사용할 수 있게 만드는 공간이다.
각각의 프로세스는 독립된 메모리 공간을 갖는다. 프로세스는 다른 프로세스나 운영체제의 메모리 공간에 접근할 수 없지만, 운영체제는 메모리 접근 제약이 없기 때문에 운영체제에서 메모리를 관리한다. 최근, 멀티프로그래밍 환경으로 변화하면서 한정된 메모리를 효율적으로 사용하기 위해 메모리 관리의 필요성이 생겼다.
효율적인 메모리 사용
동적 적재(Dynamic Loading)
- 프로그램 실행에 반드시 필요한 루틴과 데이터만 적재하는 기법.
- 모든 루틴과 데이터는 항상 사용하지 않고, 실행 시 필요하다면 그때 해당 부분을 메모리에 적재.
동적 연결(Dynamic Linking)
라이브러리 루틴 연결을 컴파일 시점에 하는 것이 아닌 실행 시점까지 미루는 기법.
스와핑(Swapping)
- 메모리에 적재되어 있으나 사용되지 않는 프로세스를 관리.
- 다중 프로그래밍 환경에서 CPU 할당 시간이 끝난 프로세스의 메모리를 보조 기억장치(backing store)로 내보내고 다른 프로세스의 메모리를 불러들임.
주 기억장치(RAM)으로 프로세스를 불러오는 과정을 swap-in, 보조 기억장치로 내보내는 과정을 swap-out이라고 한다. 가상 메모리 기법의 핵심으로 디스크를 활용하여 큰 메모리가 있는 것처럼 효율적으로 메모리를 사용할 수 있게 한다. 문맥 교환 비용이 크고 swap하는데 걸리는 시간의 대부분은 디스크 전송 시간이다.
단편화(Fragmentation)
메모리의 공간이 작은 조각으로 나뉘어 사용 가능한 메모리가 충분히 존재하지만 사용(할당)이 불가능한 상태.
1. 내부 단편화
프로세스를 고정된 크기의 페이지로 분할할 때, 프로세스 메모리 크기가 페이지 단위와 나누어 떨어지지 않았을 때 할당된 마지막 프레임이 가득차지 않는 현상.
2. 외부 단편화
프로세스들이 메모리를 차지하는 과정에서 외부에 여러 개로 작게 나누어진 공백이 생겨서 메모리를 할당할 수 없는 상태가 되는 현상. 압축(프로세스가 사용하는 공간을 한쪽으로 몰아 자유공간을 확보하는 방법론)으로 외부 단편화를 해소할 수 있지만, 작업 효율이 좋지 않다.
3. 메모리 관리 방법
단편화 현상을 줄이고, 적절한 swap으로 효율적으로 메모리를 관리하는 방법.
연속 메모리 할당(Contiguous Allocation)
프로세스를 메모리에 연속적으로 할당하는 기법. 할당과 제거를 반복하다보면 scattered holes가 생겨나고 외부 단편화가 발생한다.
연속 메모리 할당에는 두 가지 방식이 있다.
고정 분할
시스템 생성 시 주 기억장치가 이미 특정 크기로 고정된 파티션들로 분할되는 방식이다.
- 균등 분할
- 모든 파티션의 크기가 일정함.
- 프로세스의 크기 > 파티션 고정 크기: 프로세스를 모듈 단위로 나눠 디스크와 주 기억장치 사이에서 할당을 제어하는 오버레이(Overlay) 기법이 사용되어야 해서 부하가 증가한다.
- 프로세스의 크기 < 파티션 고정 크기: 프로세스가 파티션을 효율적으로 사용하지 못하고 공간이 남는 내부 단편화 문제가 발생한다.
- 비균등분할
- 파티션의 크기가 일정하지 않음.
- 프로세스 크기와 맞는 파티션에 할당하면 균등분할의 문제가 해결된다.
원리가 단순하고, 주기억장치가 미리 분할되므로 운영체제 부담이 줄어든다는 장점이 있다. 하지만, 파티션 수에 따라 프로세스 수가 제한받고, 크기가 작은 프로세스는 효율적인 공간 활용이 안 돼서 현재 고정분할을 사용하는 운영체제는 거의 없다.
동적 분할
프로세스가 주 기억장치에 적재될 때, 정확히 필요한 크기만큼 메로리를 할당하는 방식이다. 재배치를 반복하는 과정에서 외부 단편화 현상이 발생한다. 메모리 압축(compaction)이나 통합(coalescing)을 사용해 외부 단편화를 해결한다.
그리고, 외부 단편화를 줄이기 위해 다음 할당 방식을 사용한다.
- 최초 적합(First Fit): 가장 처음 만나는 빈 메모리 공간에 프로세스를 할당한다. 빠른 방식이다.
- 최적 적합(Best Fit): 빈 메모리 공간의 크기와 프로세스 크기 차이가 가장 적은 곳에 프로세스를 할당한다.
- 최악 적합(Worst Fit): 빈 메모리 공간의 크기와 프로세스 크기 차이가 가장 큰 곳에 할당한다. 이렇게 생긴 빈 메모리 공간에 또 다른 프로세스를 할당할 수 있을 거라는 가정에 기인한다.
페이징(Paging)
- 하나의 프로세스가 사용하는 메모리 공간이 연속적이어야 한다는 제약을 없애는 기법.
- 물리 메모리는 Frame이라는 고정 크기로 분리되어 있고, 프로세스가 점유하는 논리 메모리는 페이지라 불리는 고정 크기의 블록으로 분리된다.
- MMU의 재배치 레지스터 방식을 활용해 CPU가 마치 프로세스가 연속된 메모리에 할당된 것처럼 인식하도록 한다.
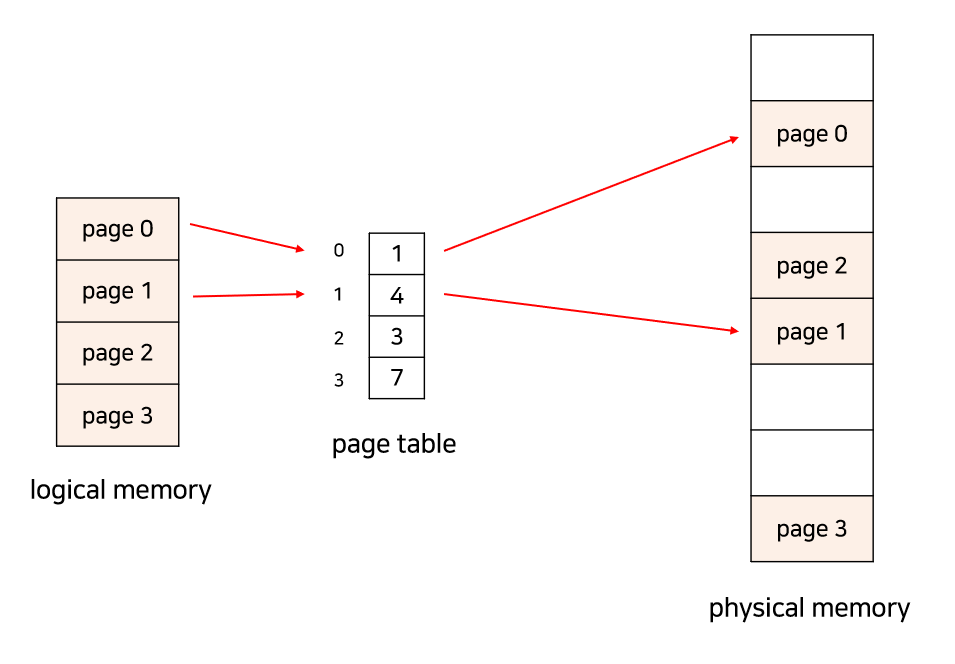
프로세스가 순서대로 메모리에 저장되어 있지 않으므로 page table이라는 테이블에 어떤 page가 어느 frame에 들어있는지 저장한다.
Page Table
- page table을 이용하여 논리적 주소를 물리적 주소로 변환한다.
- page table은 프로세스마다 존재하며 메인 메모리에 상주한다.
- page table에 접근할 때는 논리 주소의 page number을 사용한다. page table의 base address와 논리 주소의 page offset을 더하면 물리 주소를 구할 수 있다.
- 문맥 교환이 일어나는 경우, page table을 가리키는 PTBR(Page-Table Base Register)의 내용만 변경하면 된다.
- page table의 각 엔트리(entry)에는 정보를 담고 있는 bit가 포함되어 있다.
- Protection bit: page에 대한 접근 권한
- Valid-invalid bit: valid는 해당 주소의 frame에 그 프로세스를 구성하는 유효한 내용이 있고, invalid는 없음(접근 불허).
- page의 크기가 작으면 내부 단편화가 감소하고 필요한 정보만 있어 메모리 이용에 효율적이지만 page table의 크기가 증가하고 디스크 이동의 효율성이 감소하게 된다. 따라서 요즘은 page의 크기를 키워주는 흐름이다.
- page table을 효율적으로 구성하는 몇 가지 방법이 있다.
- Multi-level paging: 논리적 주소 공간을 여러 단개의 page table로 분할하여 오직 사용되는 page의 page table만 할당하는 기법.
- Hashed Page Table: hash table을 이용하여 page table을 관리하는 기법. 주소 공간이 32 bit보다 커지면 multi-level paging이 비효율적이므로 이 방식을 사용함.
- Inverted Page Table: 지금까지 각 page마다 하나의 항목을 가진 것과 달리, 메모리의 frame마다 한 항목씩 할당한다. 그러면 물리적 frame에 대응하는 항목만 저장하면 되므로 메모리를 훨씬 적게 사용한다. 각 page table entry는 각각의 메모리의 frame이 담고 있는 내용(PID, 논리 주소)을 표시한다.
장점
논리 메모리는 물리 메모리에 저장될 때 연속되어 저장될 필요가 없어 외부 단편화를 해결할 수 있다. 할당과 해제가 빠르고 swap out이 간단하다.
단점
내부 단편화 문제의 비중이 늘어나게 된다. page table을 저장하기 위한 메모리가 추가로 소모한다.
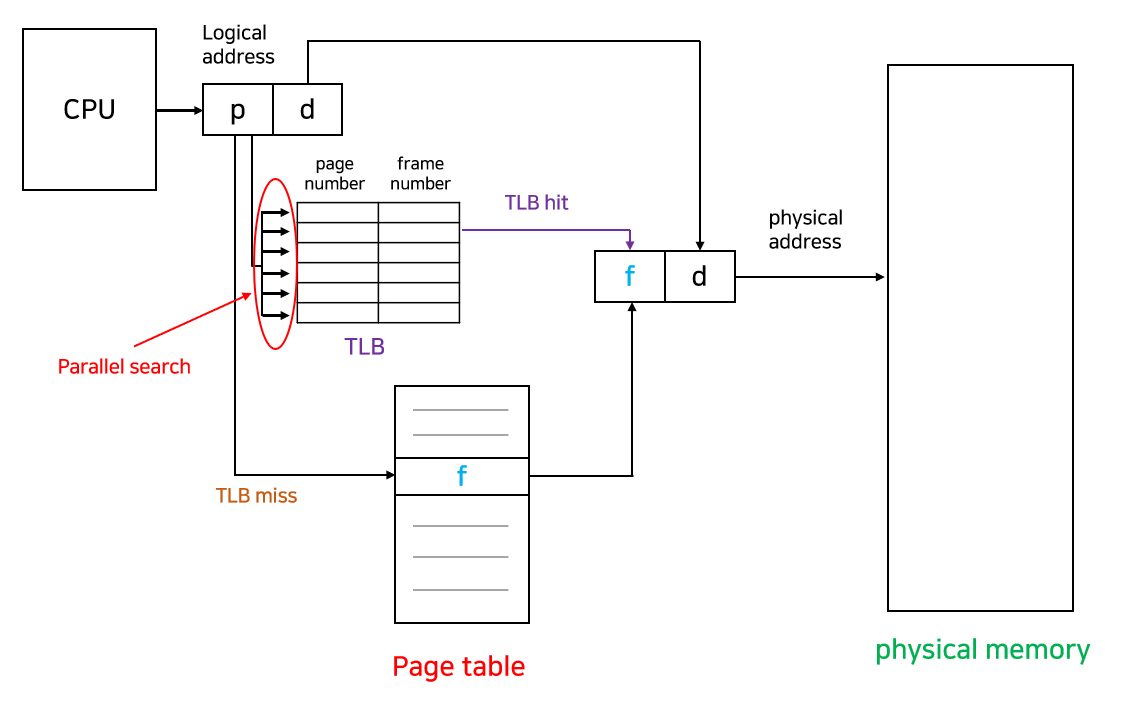
메모리 접근에 필요한 연산은 두 번의 메모리 접근(page table에 접근 + 실제 연산)이 필요하게 되어 속도가 느려진다. 이를 해결하기 위해 Associative register 혹은 TLB(Translation Look-aside Buffer)라 불리는 고속의 하드웨어 캐시를 사용한다.
TLB(Translation Look-aside Buffer)
- 메모리 주소 변환을 위한 별도의 캐시 메모리.
- page table에서 빈번히 참조되는 일부 엔트리를 caching하고 있다.
- key-value 쌍으로 데이터를 관리한다. key에는 page number, value에는 frame number가 대응된다.
페이지 교체 알고리즘(Page Replace Algorithm)
필요한 페이지가 메모리에 없을 때 page-fault가 발생하고, backing store에서 찾아온 페이지를 빈 프레임(메모리)에 로딩해야 한다. 이 때, 빈 프레임이 없을 경우 희생당할 프레임을 선택하는 알고리즘이다. 페이지 교체 알고리즘은 page-fault 발생 비율을 줄이는 방향을 목표로 한다.
- FIFO(First-In First-Out) 알고리즘
- 가장 먼저 메모리에 올라온 페이지를 가장 먼저 내보낸다.
- 구현은 간단하지만, 성능은 좋지 않다.
- Belady's Anomaly 현상(프레임의 개수가 많아져도 page-fault가 줄어들지 않고 늘어나는 현상)이 발생할 수 있다.
- OPT(Optimal) 알고리즘
- 앞으로 가장 오랫동안 사용하지 않을 페이지를 내보낸다.
- page-fault 발생이 가장 적고, Belady's Anomaly 현상이 발생하지 않는다.
- 프로세스가 앞으로 사용할 페이지를 미리 알아야하기 때문에 실제 구현이 거의 불가능하다.
- LRU(Least Recently Used) 알고리즘
- 가장 오랫동안 사용하지 않은 페이지를 내보낸다.
- Linked List로 구현할 수 있다.
- 성능이 좋아 많은 운영체제가 채택하는 알고리즘이다.
- LFU(Least Frequently Used) 알고리즘
- 참조 횟수가 가장 적은 페이지를 내보낸다.
- MFU(Most Frequently Used) 알고리즘
- 참조 횟수가 가장 많은 페이지를 내보낸다.
- NRU(Not Recently Used) 알고리즘
- 최근에 사용하지 않은 페이지를 내보낸다.
- 교체되는 페이지의 참조 시점이 가장 오래되었다(LRU)는 것을 보장하지는 못한다.
- 클럭 알고리즘이라고도 부른다.
세그멘테이션(Segmentation)
- 페이징에서처럼 논리 메모리와 물리 메모리를 같은 크기의 블록이 아닌, 서로 다른 크기의 논리적 단위인 세그먼트(Segment)로 분할한다. 일반적으로 하나의 세그먼트는 code, data, stack 부분으로 정의된다.
- 사용자가 두 개의 주소(세그먼트 번호 + offset)로 지정, 세그먼트 테이블에는 각 세그먼트의 기준(세그먼트의 시작 물리 주소)과 limit(세그먼트 길이)를 저장한다.
장점
paging과 마찬가지로 세그먼트들이 연속적으로 할당될 필요가 없다. Stack과 heap이 독립적으로 커질 수 있다. 세그먼트마다 protection을 따로 수행할 수 있다.
단점
서로 다른 크기의 세그먼트들이 메모리에 적재되고 제거되는 일이 반복되다 보면 외부 단편화 현상이 발생할 수 있다.
메모리 풀(Memory Pool)
- 필요한 메모리 공간을 필요한 크기, 개수만큼 사용자가 직접 지정하여 미리 할당받고 필요할 때마다 사용하고 반납하는 기법.
- 메모리의 할당, 해제가 잦은 경우 효과적이다.
장점
미리 공간을 할당해놓고 가져다 쓰고 반납하므로 외부 단편화가 발생하지 않는다. 또, 필요한 크기만큼 할당해놓기 때문에 내부 단편화도 생기지 않는다.
단점
단편화로 인한 메모리 낭비량보다 메모리 풀을 만들어놓고 쓰지 않는 메모리 양이 더 커질 경우, 효율적이지 않다.
참조
