컬렉션 프레임워크 기초
컬렉션 프레임워크란. '데이터 군을 저장하는 클래스들을 표준화한 설계'를 뜻한다. 컬렉션(Collection)은 다수의 데이터, 즉 데이터 그룹을, 프레임워크는 표준화된 프로그래밍 방식을 의미한다.
필요성
- 유사한 객체를 여러 개 저장하고 조작해야 할 때가 빈번
- 고정된 크기의 배열의 불편함
구조
- 컬렉션 프레임워크는 인터페이스와 클래스로 구성
- 인터페이스는 컬렉션에서 수행할 수 있는 각종 연산을 제네릭 타입으로 정의해 유사한 클래스에 일관성 있게 접근하게 함
- 클래스는 컬렉션 프레임워크 인터페이스를 구현한 클래스
- java.util 패키지에 포함 (DelayQueue는 java.util.concurrent 패키지에 포함)
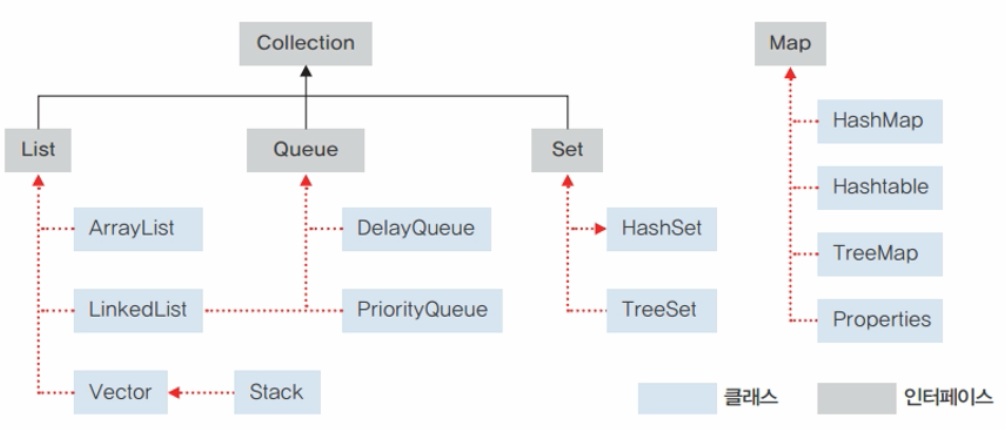
컬렉션 프레임워크의 핵심 인터페이스
-
List : 순서가 있는 데이터의 집합. 데이터의 중복을 허용한다.
예) 대기자 명단
= 구현 클래스 : ArrayList, LinkedList, Stack, Vector 등 -
Set : 순서를 유지하지 않는 데이터의 집합. 데이터의 중복을 허용하지 않는다.
예) 양의 정수 집합, 소수의 집합
= 구현 클래스 : HashSet, TreeSet 등 -
Map : 키와 값의 쌍으로 이루어진 데이터의 집합, 순서는 유지되지 않으며, 키는 중복을 허용하지 않고, 값은 중복을 허용한다.
예) 우편번호, 지역번호(전화번호)
= 구현 클래스 : HashMap, TreeMap, Hashtable, Properties 등
List
LinkedList
배열은 가장 기본적인 형태의 자료구조로 구조가 간단하면 사용하기 쉽고 데이터를 읽어오는데 걸리는 시간(접근 시간, access time)이 가장 빠르다는 장점을 가지고 있지만 다음과 같은 단점도 가지고 있다.
1. 크기를 변경할 수 없다.
- 크기를 변경할 수 없으므로 새로운 배열을 생성해서 데이터를 복사해야 한다.
- 실행속도를 향상시키기 위해서는 충분히 큰 크기의 배열을 생성해야 하므로 메모리가 낭비된다.
2. 비순차적인 데이터의 추가 또는 삭제에 시간이 많이 걸린다.
- 차례대로 데이터를 추가하고 마지막에서부터 데이터를 삭제하는 것은 빠르지만.
배열의 중간에 데이터를 추가하려면, 빈자리를 만들기 위해 다른 데이터들을 복사해서 이동해야 한다.이러한 배열의 단점을 보완하기 위해서 링크드 리스트(linked list)라는 자료구조가 고안되었다. 배열은 모든 데이터가 연속적으로 존재하지만 링크드 리스트는 불연속적으로 존재하는 데이터를 서로 연결(link)한 형태로 구성되어 있다.
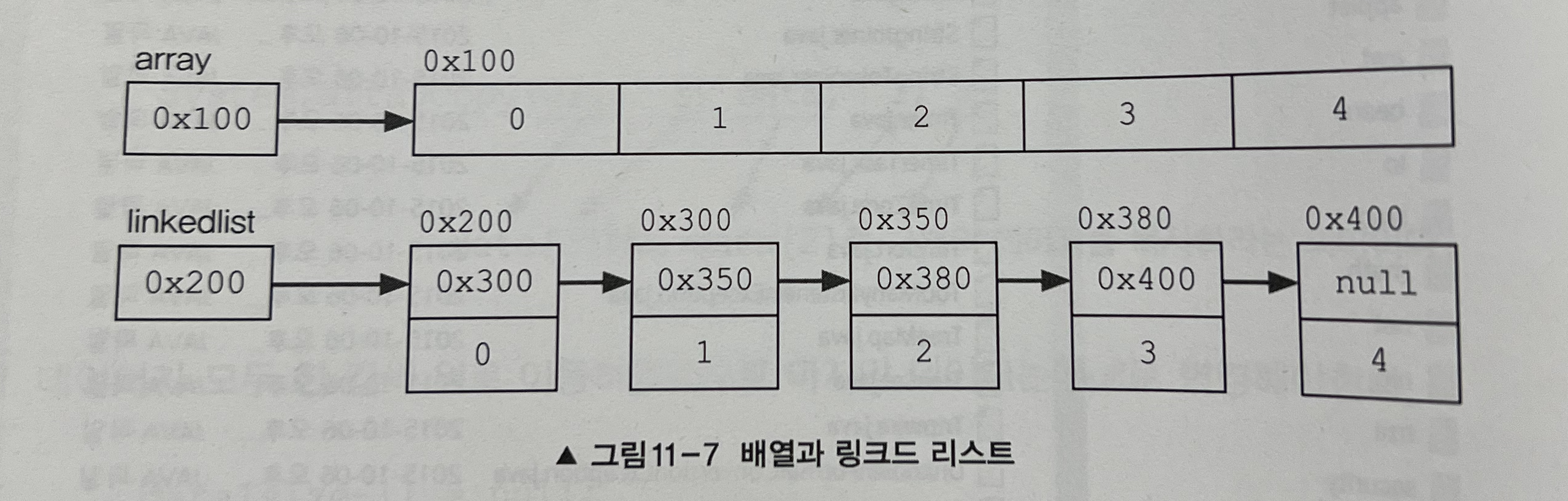
위의 그림에 알 수 있듯이 링크드 리스트의 각 요소(node)들은 자신과 연결된 다음 요소에 대한 참조(주소값)와 데이터로 구성되어 있다.
class Node {
Node next; // 다음 요소의 주소를 저장.
Object obj; // 데이터를 저장.
}
linked list는 이동방향이 단방향이기 때문에 다음 요소에 대한 접근은 쉽지만 이전요소에 대한 접근은 어렵다. 이 점을 보완한 것이 더블 링크드 리트(이중 연결 리스트, double linked list)이다.
더블 링크드 리스트는 단순히 링크드 리스트에 참조변수를 하나 더 추가하여 다음 요소에 대한 참조뿐 아니라 이전 요소에 대한 참조가 가능하도록 했을 뿐, 그 외에는 링크드 리스트와 같다.
더블 링크드 리스트는 링크드 리스트보다 각 요소에 대한 접근과 이동이 쉽기 때문에 링크드 리스트보다 더 많이 사용된다.
class Node {
Node next; // 다음 요소에 주소를 저장
Node previous; // 이전 요소의 주소를 저장
Object obj; // 데이터를 저장
}
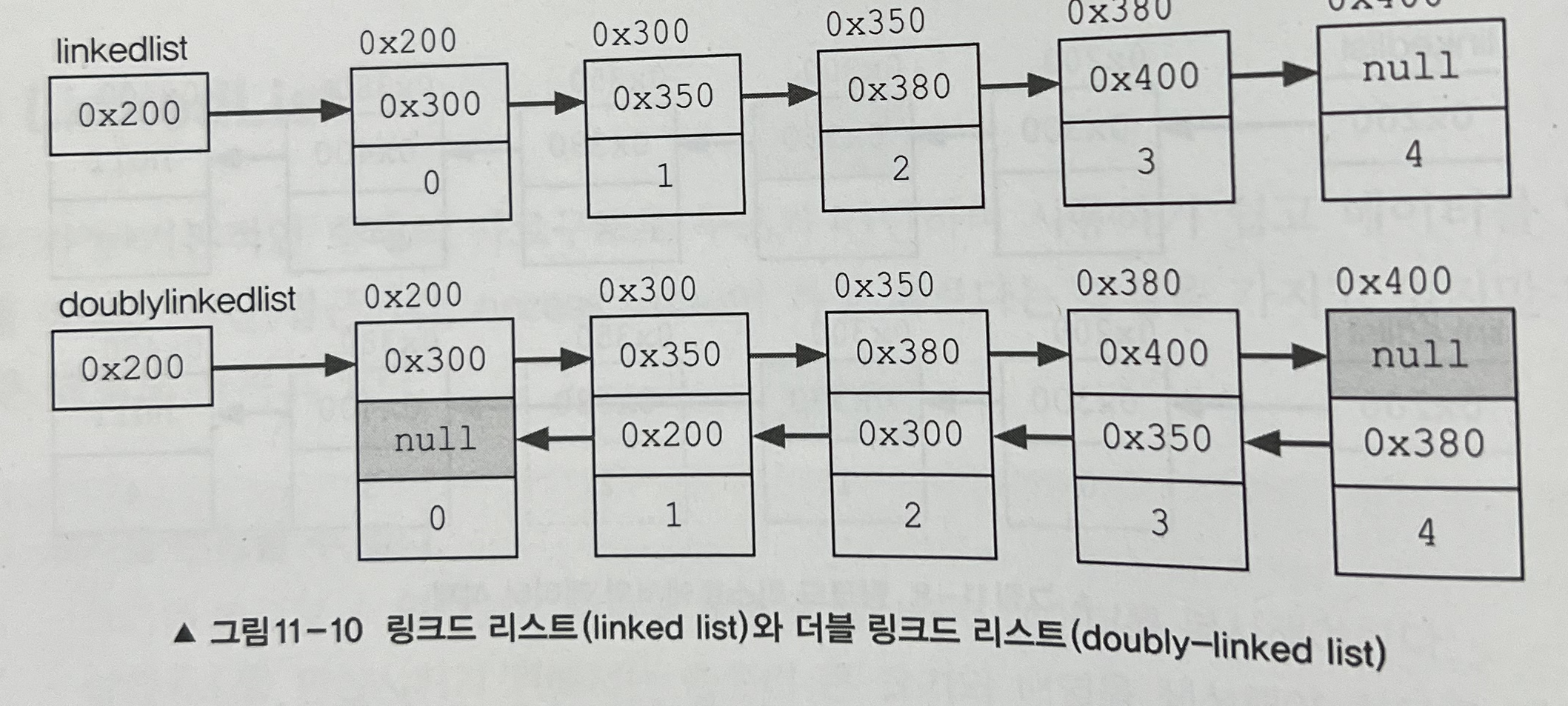
더블 링크드 리스트의 접근성을 보다 향상시킨 것이 '더블 써큘러 링크드 리스트 (이중 원형 연결리스트, doubly circular linked list)'인데, 단순히 더블 링크드 리스트의 첫 번째와 마지막 요소를 서로 연결시킨 것이다. 이렇게 하면, 마지막요소의 다음요소가 첫번째 요소가 되고 첫번째 요소의 이전 요소가 마지막 요소가 된다. 마치 TV의 마지막 채널에서 채널을 증가시키면 첫 번째 채널로 이동하고 첫 번째 채널에서 채널을 감소시키면 마지막 채널로 이동하는 것과 같다.
실제로 LinkedList클래스는 이름과 달리 '링크드 리스트'가 아닌 '더블 링크드 리스트'로 구현되어 있는데. 이는 링크드 리스트의 단점인 낮은 접근성(accessability)을 높이기 위한 것이다.
LinkedList 역시 List 인터페이스를 구현했기 때문에 ArrayList와 내부 구현방법만 다를뿐 제공하는 메서드의 종류와 기능은 거의 같기 때문에 이에 대한 설명은 따로 필요없을 것 같다.
public class Java_bible {
public static void main(String[] args) {
// 추가될 데이터의 개수를 고려하여 충분히 잡아야한다.
ArrayList al = new ArrayList(2000000);
LinkedList ll = new LinkedList();
System.out.println("= 순차적으로 추가하기 =");
System.out.println("ArrayList : " + add1(al));
System.out.println("LinkedList : " + add1(ll));
System.out.println();
System.out.println("= 중간에 추가하기 =");
System.out.println("ArrayList : " + add2(al));
System.out.println("LinkedList : " + add2(ll));
System.out.println();
System.out.println("= 중간에서 삭제하기");
System.out.println("ArrayList : " + remove2(al));
System.out.println("LinkedList : " + remove2(ll));
System.out.println();
System.out.println("= 순차적으로 삭제하기 =");
System.out.println("ArrayList : " + remove1(al));
System.out.println("LinkedList : " + remove1(ll));
}
public static long add1(List list) {
long start = System.currentTimeMillis();
for (int i = 0; i < 10000000; i++)
list.add(i + "");
long end = System.currentTimeMillis();
return end - start;
}
public static long add2(List list) {
long start = System.currentTimeMillis();
for (int i = 0; i < 10000; i++)
list.add(500, "X");
long end = System.currentTimeMillis();
return end - start;
}
public static long remove1(List list) {
long start = System.currentTimeMillis();
for (int i = list.size() - 1; i >= 0; i--)
list.remove(i);
long end = System.currentTimeMillis();
return end - start;
}
public static long remove2(List list) {
long start = System.currentTimeMillis();
for (int i = 0; i < 10000; i++)
list.remove(i);
long end = System.currentTimeMillis();
return end - start;
}
}
실행 결과
= 순차적으로 추가하기 =
ArrayList : 791
LinkedList : 1640
= 중간에 추가하기 =
ArrayList : 66213
LinkedList : 16
= 중간에서 삭제하기
ArrayList : 69301
LinkedList : 165
= 순차적으로 삭제하기 =
ArrayList : 27
LinkedList : 442
순차적으로 추가/삭제하는 경우에는 ArrayList가 LinkedList보다 빠르다.
- 단순히 저장하는 시간만을 비교할 수 있도록 하기 위해서 ArrayList를 생성할 때는 저장할 데이터의 개수만큼 충분한 초기용량을 확보해서, 저장공간이 부족해서 새로운 ArrayList를 생성해야하는 상황이 일어나지 않도록 했다. 만일 ArrayList의 크기가 충분하지 않으면, 새로운 크기의 ArrayList를 생성하고 데이터를 복사하는 일이 발생하게 되므로 순차적으로 데이터를 추가해도 ArrayList보다 LinkedList가 더 빠를 수 있다. 순차적으로 삭제한다는 것은 마지막 데이터부터 역순으로 삭제해나간다는 것을 의미하며, ArrayList는 마지막 데이터부터 삭제할 경우 각 요소들의 재배치가 필요하지 않기 때문에 상당히 빠르다. 단지 마지막 요소의 값을 null로만 바꾸면 되니까.
중간 데이터를 추가/삭제하는 경우에는 LinkedList가 ArrayList보다 빠르다.
- 중간 요소를 추가 또는 삭제하는 경우, LinkedList는 각 요소간의 연결만 변경해주면 되기 때문에 처리속도가 상당히 빠르다. 반면에 ArrayList는 각 요소들을 재배치하여 추가할 공간을 확보하거나 빈 공간을 채워야하기 때문에 처리속도가 늦다.
위에서는 ArrayList와 LinkedList의 차이를 비교하기 위해 데이터의 개수를 크게 잡았는데, 사실 데이터의 개수가 그리 크지 않다면 어느 것을 사용해도 큰 차이가 나지는 않는다. 그래도 ArrayList와 LinkedLis의 장단점을 잘 이해하고 상황에 따라 적합한 것을 선택해서 사용하는 것이 좋다.
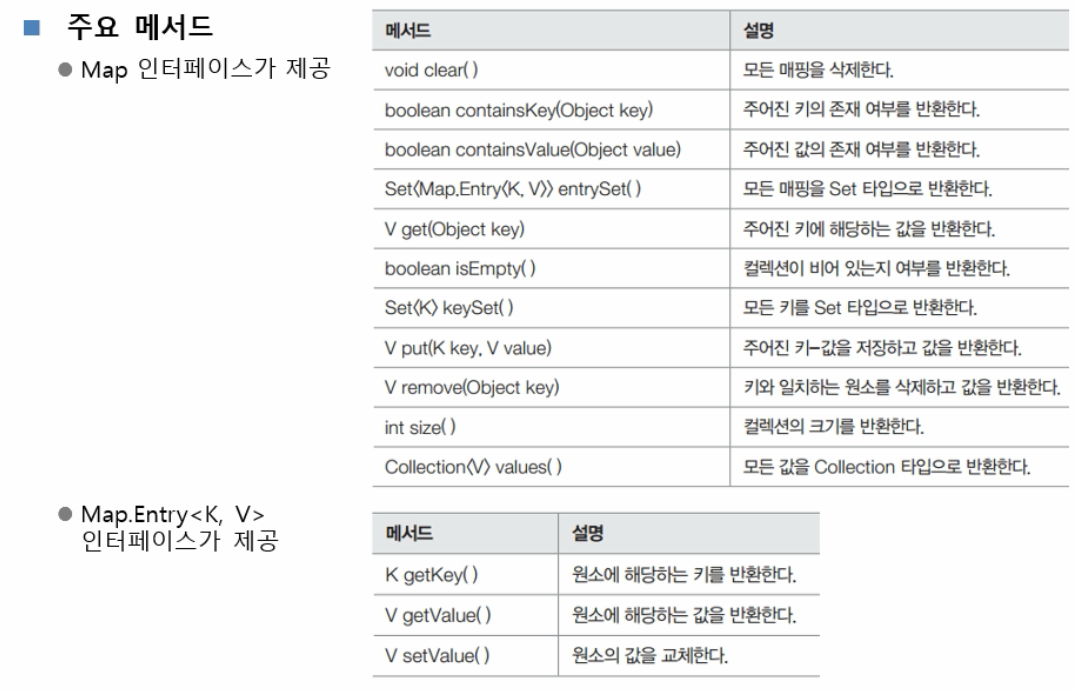
Map 인터페이스
특징
- 키와 값, 이렇게 쌍으로 구성된 객체를 저장하는 자료구조
- 맵이 사용하는 키와 값도 모두 객체
- 키는 중복되지 않고 하나의 값에만 매핑되어 있으므로 키가 있다면 대응하는 값을 얻을 수 있다.
- Map 객체에 같은 키로 중복 저장되지 않도록 하려면 Set 객체처럼 키로 사용할 클래스에 대한 hashCode()와 equals() 메서드를 Overridng 해야 한다.
- 구현 클래스 : HashMap, Hashtable, TreeMap, Properties

Map 예제
import java.util.Map;
public class MapDemo {
public static void main(String[] args) {
Map<String, Integer> fruits = Map.of("사과", 5, "바나나", 3,
"포도", 10, "딸기", 1);
System.out.println(fruits.size() + "종류의 과일이 있습니다.");
System.out.println(fruits);
System.out.println(fruits.entrySet());
for (String key : fruits.keySet()) {
System.out.println(key + "가 " + fruits.get(key) + "개 있습니다.");
}
String key = "바나나";
if (fruits.containsKey(key)) {
System.out.println(key + "가 " + fruits.get(key) + "개 있습니다.");
}
fruits.forEach((k, n) -> System.out.println(k + "(" + n + ") "));
// fruits.put("키위", 2);
// fruits.remove("바나나");
}
}
HashMap
HashMap 예제
import java.util.HashMap;
import java.util.Map;
public class HashMap1Demo {
public static void main(String[] args) {
Map<String, Integer> map = Map.of("사과", 5, "바나나", 3, "포도", 10, "딸기", 1);
Map<String, Integer> fruits = new HashMap<>(map);
System.out.println("현재 " + fruits.size() + "종류의 과일이 있습니다.");
fruits.remove("바나나");
System.out.println("바나나를 없앤 후 " + fruits.size() + "종류의 과일이 있습니다.");
fruits.put("망고", 2);
System.out.println("망고를 추가한 후 현재 " + fruits + "가 있습니다.");
fruits.clear();
System.out.println("모두 없앤 후 " + fruits.size() + "종류의 과일이 있습니다.");
}
}
HashMap에 인스턴스를 사용
import java.util.HashMap;
import java.util.Map;
public class HashMap2Demo {
public static void main(String[] args) {
Map<Fruit, Integer> map = new HashMap<>();
map.put(new Fruit("사과"), 5);
map.put(new Fruit("바나나"), 2);
map.put(null, 3);
System.out.println(map.size());
System.out.println(map);
}
}TreeMap
import java.util.Iterator;
import java.util.Set;
import java.util.TreeMap;
public class TreeMapDemo {
public static void main(String[] args) {
TreeMap<Integer, String> treeMap = new TreeMap<>();
treeMap.put(65, "Kim");
treeMap.put(35, "Park");
treeMap.put(26, "Choi");
treeMap.put(45, "Lee");
Set<Integer> keySet = treeMap.keySet();
System.out.println(keySet);
for (Integer integer : keySet) {
System.out.print(integer.toString() + '\t');
}
System.out.println();
System.out.println();
for (Integer integer : keySet) {
System.out.print(treeMap.get(integer).toString() + '\t');
}
System.out.println();
System.out.println();
for (Iterator<Integer> itr = keySet.iterator(); itr.hasNext();) {
System.out.println(treeMap.get(itr.next()));
}
}
}