최근 면접을 보았는데 해시테이블에 대한 질문이 들어왔어서 적어보려고한다.
해시테이블
해시테이블이란 (Key,Value)로 데이터를 저장하는 자료구조 중 하나로 빠르게 데이터를 검색할 수 있는 자료구조이다.
해시테이블이 빠른 검색속도를 제공하는 이유는 내부적으로 배열(버킷)을 이용해 데이터를 저장하기 때문이다. 해시테이블은 각각 Key에 해시함수를 적용해 배열의 고유한 Index를 생성하고, 이 index를 통해서 값을 저장하거나 검색하게 된다.
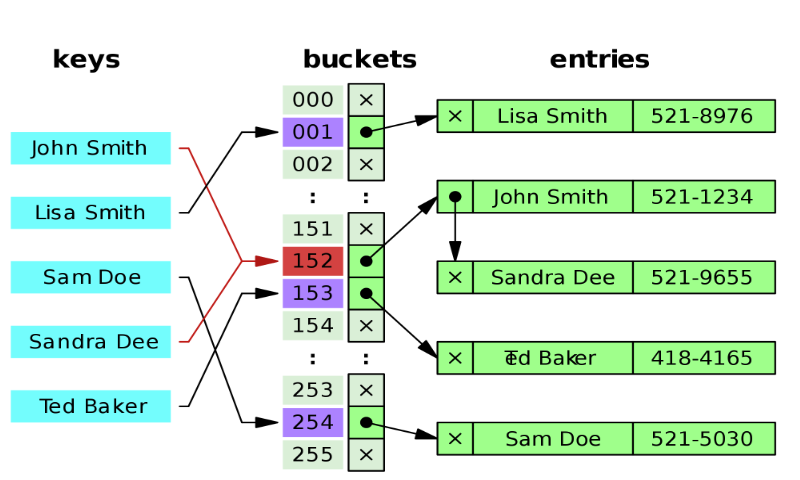
예로 (Key,Value)가 ("John smith, "521-1234")인 데이터를 크기가 255인 해시 테이블에 저장하려고한다면 일단 index를 hash_function("John Smith") % 255 연산을 통해 index 값을 계산해주게된다. 그리고 array[index] = "521-1234" 로 전화번호를 저장하게 된다. 그리고 해당 값을 찾을때는 index를 통해서 찾기 때문에 시간복잡도는 O(1)의 시간복잡도를 가지게된다.
해시테이블의 시간복잡도
각각의 Key값은 해시함수에 의해서 고유한 index를 가지게되어 바로 접근이 가능하기에 O(1)의 시간복잡도를 가지게된다. 하지만 데이터 충돌이 일어날 경우, Chaining에 연결된 리스트들까지 검색을 해야하므로 O(N)까지 시간복잡도가 증가할 수 있다.
충돌을 방지하는 방법들이 있지만, 공간을 많이 사용한다는 단점이있다. 만약 테이블이 꽉차있다면 확장해주어야하는데 이는 심각한 성능 저하를 불러오기에 가급적 확장을 하지않도록 테이블을 설계한다고 한다.
Java HashMap과 HashTable 차이
두개의 차이는 동기화여부에 있다.
해시테이블의 put에는 synchronized 키워드가 붙어있음에 이는 병렬 프로그래밍을 할때 동기화를 지원해준다는 것을 의미하며, 락으로 인해 시간이 조금 지연될 수가 있다.
그렇기에 병렬처리를 하며 자원의 동기화를 고려해야한다면 해시테이블, 병렬처리를 하지않거나 자원의 동기화가 불필요할 경우 해시맵을 사용한다.
DB에서 인덱스로 해시테이블을 안 쓰는 이유
해시 테이블기반 DB인덱스는 (칼럼의값, 데이터위치)를 key,value로 사용하여 칼럼의 값으로 생성된 해시를 통해 인덱스를 구현한다. 하지만 이는 DB인덱스에서 해시테이블을 사용되는 경우는 매우 제한적이다. 그 이유는 =연산에만 특화되어있기 때문이다. 해시 함수는 값이 1이라도 달라지면 다른 해시값을 생성하는데 이러한 특성에 의해 부등호연산이 자주 사용되는 데이터베이스 검색을 위해서는 해시 테이블이 적절하지않다. 이에 비해 B+Tree는 범위 검색과같은 쿼리에 굉장히 특화되어있기에 대부분은 DBMS는 인덱스로 B+Tree를 사용한다.
