갑자기 알고리즘 풀면서 어떻게 하면 더 효율적으로 풀 수 있을까 생각하다가,
배열만 주구장창 썼었는데 문제의 특성에 맞춰 자료구조를 활용하면 좋을 것 같아서 다시 공부하는 글
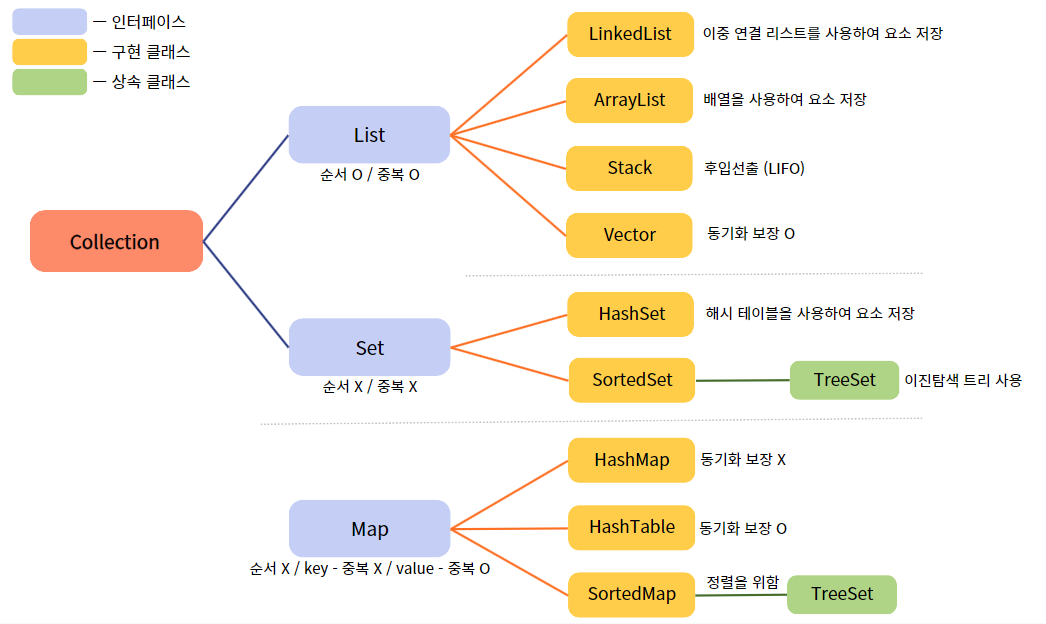
✏️ Collection Framework
-
Java 프로그래밍 언어에서 데이터를 구조화하고 관리하는 데 사용되는 클래스와 인터페이스의 집합
-
특정 자료 구조에 데이터를 추가/삭제/수정/검색하는 등의 동작을 수행하는 편리한 메서드들 제공
-
주요 인터페이스로 List / Set / Map 제공
➜ List와 Set은 공통점이 많아 그 공통점이 추출되어 Collection 인터페이스로 묶임
( 그 뒤의 것들은 각 인터페이스들을 구현한 클래스들 ) -
컬렉션에는 기본 타입은 넣을 수 없음, 객체만 저장 가능 ❗
➜ 래퍼클래스가 들어감✔️ 기본형
➜ 변수 타입의 데이터 ( 기본형 자료형 )
➜ data의 type에 따라 값이 저장될 공간의 크기와 형식을 정의한 것
⠀ ⠀
✔️ 래퍼클래스 (Wrapper class)
➜ 기본형을 객체로 다루기 위해 사용 ( 참조형 자료형 )✔ Boxing (객체화) == 자료형 변수 타입 데이터 ➜ 래퍼 클래스
➜int -> Integer의 경우 (Integer a = new Integer)
⠀ ⠀
✔ Unboxing == 래퍼 클래스 ➜ 자료형 변수 타입 데이터
➜Integer -> int의 경우 (int b = a.intValue();)
1. List
-
데이터의 순서 유지 O / 중복 저장 O
-
구현 클래스 : ArrayList, Vector, Stack, LinkedList 등
2. Set
-
데이터의 순서 유지 X / 중복 저장 X
-
구현 클래스 : HashSet, TreeSet 등
3. Map
-
키(key) - 값(value)의 쌍으로 데이터를 저장
-
데이터의 순서 유지 X / Key - 중복 저장 X / Value - 중복 저장 O
( Key는 값을 식별하기 위한 고유한 값이라 불가능 ) -
구현 클래스 : HashMap, HashTable, TreeMap, Properties 등
✔️ Collection 인터페이스의 메서드
add(Object o),addAll(Collection c)contains(Object o),containsAll(Collection c)equals(Object o)⠀isEmpty()⠀iterator()size()clear()⠀remove(Object o),removeAll(Collection c)retainAll(Collection c)toArray()toArray(Object[] a)
⠀
👉 컬렉션 인터페이스를 구현하는 Set / List에서 사용 가능
👉 Map은 사용 불가 ( 따로 가지고 있는 메서드만 사용 )
✔️ Iterator
Iterator<타입 파라미터> 변수명 = 앞에 선언된 list/set의 이름.iterator();
- 컬렉션에 저장된 요소들을 순차적으로 읽어오는 반복자
- Collection 인터페이스에 정의된
iterator()호출하면 Iterator 타입의 인스턴스가 반환
➜ Collection 인터페이스를 구현한 클래스들은 iterator() 메서드 사용 가능
( List / Set / Map )➜ Map은 컬렉션 인터페이스를 구현하지는 않았지만 컬렉션 프레임워크의 일부로 간주되기 때문에
일부 Map 구현체는 Iterable 인터페이스를 구현하여 요소 순회 가능
💡 Q ) 그런데 list의 경우에 그냥 for문이나 while문 사용해서 순회하면 되는데,
왜 굳이 iterator를 만들어서 순회할까?
⠀
1. iterator 사용하면 컬렉션을 순회하는 동안 요소를 삭제/추가 가능
Ex.iterator.remove()/iterator.add()( for loop은 불가 )
⠀
2. iterator는 인터페이스로써 컬렉션의 구현과 분리되어있기 때문에
컬렉션의 구현이 변경되더라도 iterator 코드 수정 필요 X
⠀
3. iterator 인터페이스를 구현한 다양한 클래스의 객체를 사용할 수 있어서 코드의 재사용성이 높아짐
⠀
4. 컬렉션의 크기와 상관없이 일관된 방식으로 순회할 수 있기 때문에 코드의 가독성 향상
✔ Iterator 인터페이스에 정의된 메서드
-
boolean
hasNext()
➜ 읽어올 객체가 남아 있으면 true를 리턴, 없으면 false 리턴 -
E
next()
➜ 컬렉션에서 하나의 객체를 읽어옴
( 이 때,hasNext()로 읽어올 다음 요소가 있는지 먼저 확인 후next()호출 )
( E - 요소의 유형을 나타내는 제네릭 타입 매개변수 ) -
void
remove()
➜next()를 통해 읽어온 객체 삭제
( 이 때,next()를 호출한 다음에remove()호출 )
📌 List 인터페이스
-
순서 O / 중복 O
-
배열과 같이 객체를 일렬로 늘어놓은 구조
-
객체를 인덱스로 관리하기 때문에 객체를 저장하면 자동으로 인덱스가 부여됨
-
컬렉션 인터페이스의 메서드 사용 가능
✔ 구현 클래스
1. ArrayList
List<타입 매개변수> 객체명 = new ArrayList<타입 매개변수>(초기 저장 용량);
-
list의 특성 모두 상속 받음
-
내부적으로 배열을 사용하여 요소 저장
-
데이터를 순차적으로 추가/삭제할 때 비교적 효율적
( 객체들이 연속적으로 저장되어 있기 때문에 )❗ But, 중간에 위치한 객체를 추가/삭제 할 경우 속도 저하
( 하나씩 객체가 앞/뒤로 밀리기 때문에 )
➜ 최악의 경우 O(n)의 시간 소요
➜ LinkedList 사용이 더 효율적 -
인덱스 기반으로 접근할 경우, O(1)의 시간 소요
-
크기가 가변적
➜ 저장 용량을 초과하여 객체가 추가되면 자동으로 기존 배열의 크기의 두 배로 증가 -
비동기화된 구조
- 멀티 스레드 환경에서 안전하지 않음
💡 < 배열(Array) vs ArrayList >
1. 공통점
-
둘 다 중복 허용
-
인덱스로 관리
2. 차이점
- 배열
➜ 초기화시 크기가 고정, 크기 변경 불가
( ➜ 정해진 길이의 배열을 다 채우면 새 배열을 만들어 새 데이터를 추가해야함 )
➜ 참조타입, 기본타입 모두 저장 가능
⠀ - Arraylist
➜ 초기화시 사이즈를 표시하지 않아도 되어 크기가 가변적
( ➜ 기본 저장용량 10의 배열을 다 채우면 자동으로 사이즈가 늘어남 )
➜ 참조타입의 객체 주소만 저장
2. LinkedList
-
list의 특성 모두 상속받음
-
모든 데이터가 불연속적으로 존재하고 이 데이터들이 서로 연결(link)되어 있음
( 배열, ArrayList에는 모든 데이터가 연속적으로 존재 ) -
내부적으로 노드(Node)들을 연결하여 요소를 저장
-
데이터를 효율적으로 추가, 삭제, 변경하기 위해 사용
( 각 요소(Node)들이 서로가 서로의 주소값이 되어 연결 )
➜ 데이터 삽입/삭제의 처리 속도가 빠름- 데이터 삭제 시
➜ 서로의 주소값 연결을 끊고 그것을 다른 요소에 붙여주면 혼자 남는 애가 삭제 됨 - 데이터 추가 시
➜ 새 요소 이전 요소와 다음 요소를 새 요소와 각각 연결해주면 됨
- 데이터 삭제 시
-
데이터 삽입/삭제의 경우, 노드의 링크만 변경하면 되기 때문에 O(1)의 시간 소요
❗ But, 데이터를 검색할 때는 맨 앞부터 순차적으로 검사(선형 검색)해야하기 때문에 시간이 오래 걸림 ( O(n)의 시간 소요 )
순차적으로 추가/삭제 하는 것도 ArrayList에 비해 느림
🌈🔊 요약하자면,
- ArrayList는 순서 보장 O / 중복 O이고,
인덱스 기반 접근이 빠르지만(O(1)) 삽입/삭제가 느리며(O(n)),
⠀ ⠀- LinkedList는 순서 보장 O / 중복 O이고,
삽입/삭제가 빠르지만(O(1)) 인덱스 기반으로 접근할 경우 시간이 오래걸릴 수 있음(O(n)) !
3. Vector
-
ArrayList와 유사
( 동기화의 여부만 다름 ) -
동기화된 동적 배열 구현 클래스
- 멀티 스레드 환경에서 안전
-
크기가 가변적
➜ 저장 용량을 초과하여 객체가 추가되면 자동으로 기존 배열의 1.5배 만큼 증가
4. Stack
-
후입선출(LIFO) 구조를 따르는 자료구조
-
Vector를 확장한 클래스로 구현됨
-
push()메서드로 요소 추가 /pop()메서드로 요소 삭제 -
스택의 맨 위에 있는 요소에만 접근 가능
-
주로 재귀 알고리즘을 사용하는 경우나 후위 표기법(postfix notation) 계산에 활용
✔️ Queue
- 선입선출(FIFO) 구조를 따르는 자료구조
- 인터페이스 형태로 정의되어 있고, 구현 클래스로는 LinkedList 등
offer()메서드로 요소를 큐에 추가 /poll()메서드로 요소를 큐에서 제거하면서 반환peek()메서드로 큐의 맨 앞 요소를 제거하지 않고 조회 가능
Ex. 주로 작업 대기열(Work Queue) 등에 활용- Deque 인터페이스를 상속받는 Priority Queue 클래스도 있어서 우선순위 큐(priority queue) 구현 가능
📌 Set 인터페이스
-
중복 허용 X, 저장 순서 유지 X (List와 반대)
-
컬렉션 인터페이스의 메서드 사용 가능
✔ 구현 클래스
1. HashSet
-
Set의 특성 모두 상속 받음
-
각 요소의
hashCode()값을 이용하여 해시 테이블의 버킷에 요소 저장 -
검색/삽입/삭제 연산이 빠름
➜ 평균적으로 O(1)의 시간 복잡도
But, 정렬된 순서로 순회 / 범위 검색 불가✔️ 범위 검색
일정 범위에 해당하는 요소들을 검색하는 것
Ex. 1 - 100 까지 숫자 중에 50 - 80 사이에 속하는 것들을 찾아라 -
요소를 추가할 경우,
hashCode()+equals()로 해당 데이터가 존재하는지 판단 가능
( 해당 요소의 해시코드 가져와서 이거랑 같은지 다른지 비교해서 같으면 중복 ! )
➜hashCode()/equals()를 오버라이드하여 중복 객체를 어떻게 정의할 것인지도 구현할 수 있음 !Ex. 고객 정보가 있을 때,
이름, 성별, 나이가 모두 같아야 동등한 것으로 간주하겠다! 하면,
👉equals()메서드를 해당 내부 상태인이름, 성별, 나이를 비교하도록 오버라이드하고,
👉 동일한 내부 상태를 갖는 객체(이름, 성별, 나이가 모두 같은 객체)는 동일한 해시 코드를 반환하도록hashCode()메서드를 오버라이드하여,
중복 객체의 정의를 입맛대로 할 수 있음
⠀
But, 이 경우에는hashCode()의 리턴값이 같은 객체들끼리는equals()의 결과도 반드시 true가 되어야 함 !
( 그니까 오버라이드한hashCode()의 리턴값이name, gender, age라면 이 리턴 값이 같은 객체 (중복 객체)는 오버라이드한equals()가 꼭 true를 return 해야함 )
2. TreeSet
-
Set의 특성 모두 상속 받음
( But, 값들 자동 오름차순 정렬 해줌 ) -
정렬된 순서로 순회 / 범위 검색 가능
But, 해시테이블에 비해 더 많은 메모리 공간을 사용하고,
삽입/삭제 연산 시 시간 복잡도가 더 높을 수 있음 ! -
내부적으로 이진 탐색 트리의 형태로 요소 저장
✔️ 이진 탐색 트리
- 한 노드에 2개의 노드가 쭉 연결되어있는 구조
- 한 부모노드의 모든 왼쪽 자식은 부모 노드보다 값이 작아야하고 오른쪽 자식은 부모노드보다 값이커야 함
⠀
Ex. 8 5 9 1 6 을 TreeSet으로 저장하면,
맨 위 부모 노드 8, 그의 왼쪽 자식 5, 그의 오른쪽 자식 9, 왼쪽 자식 5의 자식 중 왼쪽 자식에 1, 오른쪽 자식에 6 저장
3. LinkedHashSet
-
Set의 특성을 모두 상속 받음
-
내부적으로 HashTable과 LinkedList를 결합하여 요소 저장
-
저장하는대로 순서 보장 O
But, 정렬된 순서로 순회 / 범위 검색이 불가능 -
HashSet보다는 약간 느리지만, HashTable에 의해 빠른 검색/삽입/삭제 가능
➜ O(1)의 시간 복잡도
🌈🔊 요약하자면,
- HashSet은 순서 보장 X / 정렬 X / 중복 X라서
빠른 검색/삽입/삭제 연산이 필요하고 순서가 중요하지 않은 경우 유용 !
⠀ ⠀- TreeSet은 정렬된 순으로 저장 / 중복 X라서
요소들을 정렬된 상태로 순회하거나 유지해야하는 경우 유용 !
⠀ ⠀- LinkedHashSet은 순서 보장 O / 정렬 X / 중복 X라서
추가된 순서대로 순회할 때 유용 !
📌 Map<k, v> 인터페이스
-
키(key)와 값(value)의 쌍으로 구성된 객체를 저장하는 구조
( key-vlaue 쌍 값을 Entry 라고 부름 )👉 Map 인터페이스 안에 키 객체와 값 객체 이루어진 엔트리 객체들이 있다 !
-
순서 보장 X
-
key는 중복 저장 허용 X
➜ 고유한 것이여야 하기 때문에
( 기존 키에 값을 새로 저장하면 기존 키 값이 새로운 값으로 변함 ) -
value는 중복 저장 허용 O
➜ 고유한 key로 식별 가능하기에 중복 허용
✔ 구현 클래스
1. HashMap
HashMap<key타입, value타입> 변수명 = new HashMap<>();
-
Map의 특성 모두 상속 받음
-
가장 일반적으로 사용되는 Map 구현 클래스
-
해싱(Hashing)을 사용하여 데이터를 저장
✔️ 해싱 ( Hashing )
- 키(Key) 값을 해시 함수(Hash Function)라는 수식에 대입시켜 계산한 후,
나온 결과를 주소로 사용하여 바로 값(Value)에 접근하게 할 수 하는 방법 - 해시 함수를 통해 저장되는 위치가 결정되므로 사용자는 위치, 순서 모두 알 수 없음
- 키(Key) 값을 해시 함수(Hash Function)라는 수식에 대입시켜 계산한 후,
-
Key나 Value에 null 허용
-
많은 양의 데이터를 검색하기 좋음
➜ 검색/삽입/삭제에 대해 평균적으로 O(1)의 시간 복잡도 -
비동기화된 구조
- 단일 스레드 환경에서 HashTable 보다는 속도가 빠름
- 멀티 스레드 환경에서 안전하지 않음
➜ 멀티스레드 환경에서 사용 시 동기화를 직접 처리해야함
-
해시 함수가 서로 다른 두개의 Key에 대해 동일한 해시 값(해시코드)을 생성하면 해시 충돌 발생
➜ 체이닝(Chaining) / 개방 주소법(Open Addressing) 등의 방법 사용✔️ 체이닝(Chaining)
➜ 해시 충돌이 발생하면 충돌 지점에 연결 리스트를 생성하여 여러 개의 키-값 쌍을 저장하는 방식
⠀ ⠀
✔️ 개방 주소법(Open Addressing)
➜ 해시 충돌이 발생하면 이를 해결하기 위해 다른 빈 슬롯을 찾아 키-값 쌍을 저장하는 방식
➜ 선형 탐사, 이차 탐사, 이중 해싱 등의 기법을 사용 가능
❗ Map은 Key와 Value을 쌍으로 저장하기 때문에 iterator() 직접 호출 불가 !
➜ keySet() 이나 entrySet() 메서드를 이용해 Set 형태로 반환된 컬렉션에 iterator()를 호출하여 반복자를 만든 후, 반복자를 통해 순회 가능
keySet()- 모든 키들을 set으로 변환하여 저장 ⬇️Set<key타입> 변수명 = hashMap변수명.keySet();
entrySet()- 모든 엔트리(키-값 쌍)를 set으로 변환하여 저장 ⬇️Set<Map.Entry<key타입, value타입>> 변수명 = hashMap변수명.entrySet();
✔️ HashMap 클래스의 메서드
( 컬렉션 인터페이스를 구현하지 않기 때문에 메서드가 별개로 존재)
equals(Object o)getKey()getValue()hashCode()setValue(Object value)
2. LinkedHashMap
-
HashMap의 기능을 확장한 Map 구현 클래스
-
HashMap과 유사하게 작동하지만 LinkedList로 구현되어 있어 삽입 순서나 액세스 순서를 보존
-
- Key나 Value에 null 허용
3. TreeMap
-
Key를 기준으로 순서가 정렬된 상태로 이진 검색 트리에 데이터 저장
➜ 저장된 순서와 Key의 순서가 일치 -
데이터를 검색/삽입/삭제할 때 O(log n)의 시간 복잡도
-
Key나 Value 중 하나라도 null인 경우 NullPointerException
4. HashTable
-
Map 인터페이스가 아닌,
java.util패키지의Dictionary클래스를 상속받아 구현된 클래스
( But, 이것도 Map 자료구조의 일종 ) -
동기화된 구조
- 단일 스레드 환경에서 HashMap보다 성능이 떨어질 수 있음
- 멀티 스레드 환경에서 안전하고, HashMap보다 속도가 빠름
But, 모든 메서드가 스레드 동기화되어있기 때문에 멀티 스레드 환경에서 안전하지만, 성능이 저하될 수 있음
-
Key나 Value 중 하나라도 null인 경우 NullPointerException
5. ConcurrentHashMap
-
스레드 안전한 HashMap
-
멀티 스레드 환경에서 안전하게 사용 가능
-
동기화된 구조
- 단일 스레드 환경에서 성능이 떨어질 수 있음
- 멀티 스레드 환경에서 안전하고, HashTable보다 속도가 빠름
세분화된 동기화 방법을 사용하여 읽기 작업과 일부 쓰기 작업이 동기화되므로 멀티 스레드 환경에서 안전하면서도 HashTable보다 성능이 더 우수
-
Key나 Value에 null 허용
6. WeakHashMap
-
Key에 대한 참조가 Garbage Collection의 영향을 받지 않는 Map 구현 클래스
➜ Key가 더이상 사용되지 않으면, 해당 Key와 연결된 Value가 자동으로 제거됨 -
Key나 Value에 null 허용
🌈🔊 요약하자면,
- HashMap은 순서 보장 X / 정렬 X / 중복 O이라서
빠른 검색/삽입/삭제 연산이 필요하고 순서나 정렬이 중요하지 않은 경우 유용 !
⠀ ⠀- LinkedHashMap은 순서 보장 O / 정렬 X / 중복 O이라서
삽입된 순서대로 순회해야하는 경우 유용 !
⠀ ⠀- TreeMap은 Key를 기준으로 정렬된 순으로 저장 / 중복 O이고
정렬된 데이터를 순회해야 하는 경우나 범위 검색이 필요한 경우 유용 !
⠀ ⠀- HashTable은 순서 보장 X / 정렬 X / 중복 O이고,
동기화되어있어 멀티 스레드 환경에서 안전 !
⠀ ⠀- ConcurrentHashMap은 순서 보장 X / 정렬 X / 중복 O이고,
동기화되어있어 멀티 스레드 환경에서 안전한데 HashTable보다 성능 좋음 !
✔️ 단일 스레드 환경에서의 성능 순위
1. HashMap
2. ConcurrentHashMap
3. HashTable
⠀ ⠀
✔️ 멀티 스레드 환경에서의 성능 순위
1. ConcurrentHashMap
2. HashTable
3. HashMap
