Tasklet vs Chunk 비교와 처리 테스트
📌 Spring batch에 대한 자세한 개념들은 아래 포스팅을 참고해주세요.
<스프링 배치(Spring batch)란?>
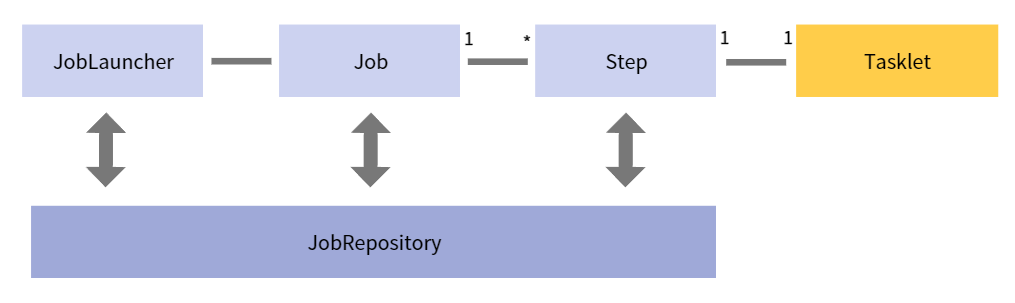
✏️ Tasklet
-
Step이 중지될 때까지 execute 메서드가 계속 반복해서 수행하고,
수행할 때마다 독립적인 트랜잭션이 얻어짐 -
초기화, 저장 프로시저 실행, 알림 전송과 같은 Job에서 일반적으로 사용
-
계속 진행할지 아님 끝낼지 두가지 경우만 제공
-
데이터의 처리 과정이 tasklet 안에서 한번에 이루어지고,
배치 처리 과정이 쉬운 경우 쉽게 사용됨
( 대용량 데이터 처리의 경우 더 복잡해질 수 있음 ) -
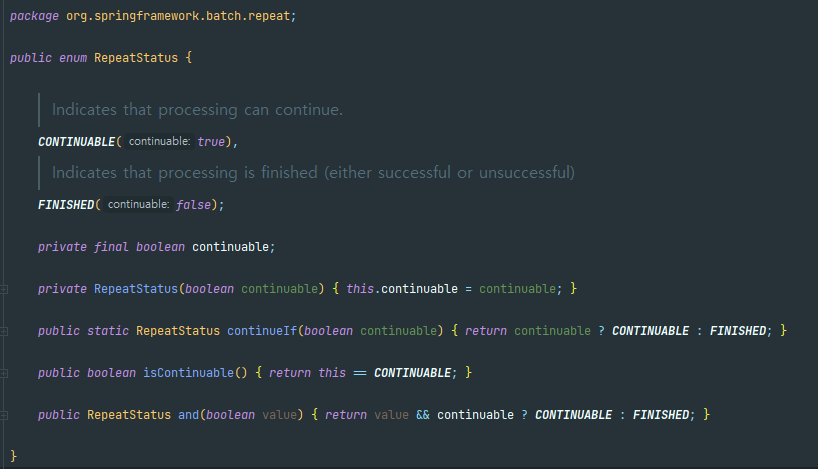
tasklet의 execute 메서드의 return 타입은 RepeatStatus
RepeatStatus.FINISHED- 종료 /RepeatStatus.CONTINUABLE- 다시 실행
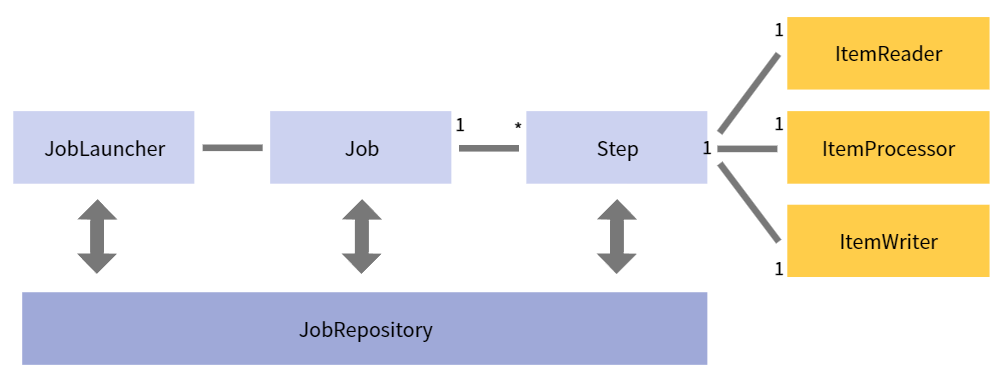
✏️ Chunk
-
한 번에 하나씩 데이터(row)를 읽어 Chunk라는 덩어리를 만든 뒤, Chunk 단위로 트랜잭션을 다룸
-
Chunk 단위로 트랜잭션을 수행하기 때문에 실패할 경우엔 해당 Chunk 만큼만 롤백이 되고, 이전에 커밋된 트랜잭션 범위까지는 반영이 됨
-
대용량 데이터를 처리할 경우 사용됨
-
Chunk 기반 Step은 ItemReader, ItemProcessor, ItemWriter라는 3개의 주요 부분으로 구성
➜ ItemReader와 ItemProcessor에서 데이터는 1건씩 다뤄지고, ItemWriter에선 Chunk 단위로 한번에 처리
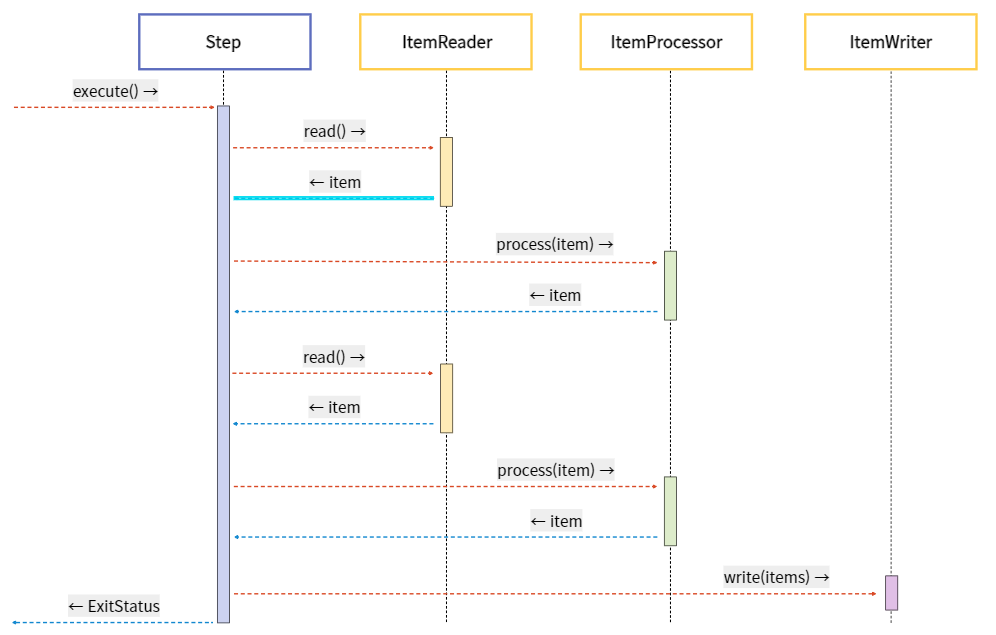
ItemReader
- Step(Database)에서 배치 처리할 Item을 읽어오는 역할
- ItemReader에 대한 다양한 인터페이스가 존재하고, 다양한 방법으로 Item을 읽어올 수 있음
⠀ItemProcessor
- Reader로 읽어온 Item을 데이터를 가공/처리하는 역할
- 배치를 처리하는데 필수 요소는 아님
- item을 필터 도중 null로 리턴하면, 그 item은 write로 전달되지 못함
( 값이 정확히 있는 item들만 write로 전달됨 )
⠀ItemWriter
- Processor로 가공/처리 된 데이터들(items : List< item >)을 Database에 저장하는 역할
- 처리 결과물에 따라 Insert / Update / Queue를 사용한다면 Send가 될 수도 있음
- ItemWriter에 대한 다양한 인터페이스가 존재
- 기본적으로 item들은 List 단위로 처리되며, 그 List는 Chunk 단위로 처리됨
❗ 일반적으로 스프링 배치는 대용량 데이터를 다루는 경우가 많기 때문에
Tasklet 보다 상대적으로 트랜잭션의 단위를 짧게 하여 처리할 수 있는 Chunk 지향 프로세싱을 이용 !!
🌼 Tasklet / Chunk 방식 테스트
✔️ 1. Tasklet 테스트
private String JOBNAME = "testTaskChunkJob"; ⠀ @Bean public Job testTaskChunkJob(){ return jobBuilderFactory.get(JOBNAME) .incrementer(new RunIdIncrementer()) .start(this.taskStep1()) .build(); } ⠀ @Bean public Step taskStep1(){ return stepBuilderFactory.get("taskStep1") .tasklet(tasklet()) .build(); } ⠀ private Tasklet tasklet(){ //tasklet으로 모두 처리 return (contribution, chunkContext) -> { List<String> items = getItems(); ⠀ log.info("items : "+ items.toString()); ⠀⠀ return RepeatStatus.FINISHED; }; }
private List<String> getItems() { List<String> items = new ArrayList<>(); ⠀ for (int i = 1; i <= 100; i++) { items.add("No." + i); } ⠀ return items; }
위는 단순하게 100개의 숫자를 가져와서 log를 출력하는 tasklet이다.
tasklet은 함수 안에서 모두 처리되어 1~100까지 모두 출력된다 !
⠀⠀
결과 :
items : [No.1, No.2, No.3, ... No.99, No.100]
✔️ 2. Chunk 테스트
private String JOBNAME = "testTaskChunkJob"; ⠀ @Bean public Job testTaskChunkJob(){ return jobBuilderFactory.get(JOBNAME) .incrementer(new RunIdIncrementer()) .start(this.taskStep1()) //tasklet 처리 .next(this.chunkStep1()) //chunk 처리 .build(); } ⠀ // ... ⠀ @Bean public Step chunkStep1() { //chunksize로 처리 return stepBuilderFactory.get("chunkStep1") .<String,String>chunk(10) .reader(itemReader()) .processor(itemProcessor()) .writer(itemWriter()) .build(); } ⠀ private ItemReader<String> itemReader() { return new ListItemReader<>(getItems()); } ⠀ private ItemProcessor<String, String> itemProcessor() { return item -> item + " now processor!!"; } ⠀ private ItemWriter<String> itemWriter() { return items -> log.info("### writer : " + items.toString()); }
chunksize로 처리 시,
Step에 .chunksize(크기) 로 정의하며 앞에 처리될 타입을 정의한다.
.<String,String>chunk(10)➜ 앞의 String : reader에서 읽은 데이터의 타입
➜ 뒤의 String : writer에서 받을 데이터의 타입
따라서 processor 처리 함수에서는 앞/뒤 타입을 모두 선언해서 필터나 데이터 변형 처리가 가능하다.
-
readerprivate ItemReader<String> itemReader() { return new ListItemReader<>(getItems()); }-
ListItemReader
➜ Spring batch에서 제공하는 item처리 클래스 -
getItems에서 가져온 List을 LIstItemReader에서 알아서 item 반환해줌
⠀⠀
-
-
processorprivate ItemProcessor<String, String> itemProcessor() { return item -> item + " processor"; }-
<reader에서 읽은 타입, writer에 보낼 타입> 으로 정의해 처리
-
지금은 그냥 읽은 item에 문자열만 더해서 처리하도록 하였음
⠀⠀
-
-
writerprivate ItemWriter<String> itemWriter() { return items -> log.info("### writer : " + items.toString()); }-
writer에서 < String >이지만, List< String >단위로 처리됨
-
items를 받아 log를 출력하면, chunksize = 10개씩 읽은 String이 List로 출력됨
⠀⠀
-
결과 :
writer : [No.1 processor!!, 2 processor!!, ... No.10 processor!!] writer : [No.11 now processor!!, No.12 processor!!, ... 20 processor!!] ... writer : [No.91 processor!!, No.92 processor!!, ... No.100 processor!!]
log를 총 10개 출력했으며, 각 로그는 items를 출력한다.
reader에서 10개씩 읽고 List< String > 으로 items가 writer에서 chunksize=10만큼 처리된다.
📌 다음 포스팅은 프로젝트에서의 Spring batch 적용에 대한 내용입니다.
⠀
👉 [Project] 프로젝트에 Spring Batch 적용하기 !
