
_경주, 동궁과 월지의 야경
👍👍👍
저번 시간엔 경량 딥러닝 기술이 무엇인지 알아보았고, 그 중엔 새롭게 가벼운 모델을 만드는 기술 연구인 경량 딥러닝 알고리즘 연구와 기존 모델을 바탕으로 모델을 가볍게 만드는 알고리즘 경량화 기술이 있다고 알아보았습니다.
이번 시간에는 경량 딥러닝 알고리즘 연구 중, 첫 번째로 모델 구조 변경을 통해 접근하는 기술들에는 어떤 것이 있을 지 알아보겠습니다. 다양한 기술들이 있지만 그 중 흥미로웠던 DenseNet 모델을 중점적으로 알아보도록 하겠습니다. 🏃♂️
🤔 모델 구조 변경 기술이란
먼저, 경량 딥러닝 알고리즘 연구란, 새로운 모델을 만들 때 어떻게 하면 전체 파라미터 수를 줄이고 성능이 좋은 모델이 될지를 연구하는 것입니다. 모델 설계 단계부터 딥러닝의 알고리즘 자체를 적은 연산을 요하고 효율적인 구조로 설계하는 연구입니다.
그 중, 모델 구조 변경을 통한 접근 방법의 연구 방향은, 잔여 블록, 병목 구조, 밀집 블록 등 다양한 신규 계층 구조를 이용하여 파라미터 축소 및 모델 성능을 개선하는 연구입니다.
기술 발표 당시 새로운 기술로 파라미터를 줄인 대표적인 모델 구조는 ResNet, DenseNet, 그리고 SqueezeNet입니다. ResNet과 SquuzeNet의 기술에 대해 간략히 알아보고, DenseNet에 대해 좀 더 자세히 알아보며, 어떤 방식으로 파라미터를 줄이고 정확한 성능도 놓치지 않을 수 있었는지 알아보도록 하겠습니다.
- ResNet 모델
ResNet 모델은 기존 VGG 모델과 같이 CNN의 convolution 레이어들이 일직선으로 연결된 것과 다르게, 몇 개의 layer들의 앞뒤를 지름길(shortcut)로 이어 feature map이 뒤로 빠르게 전달될 수 있게 합니다. 아래의 그림과 같이, 일부 레이어를 건너뛰어 feature map x가 전달되고, 이는 레이어들을 통과한 F(x)와 '합쳐(summation)'집니다. 그림에서 나온 identity shortcut은 추가적인 연산이 없기에 x와 F(x)가 합쳐지려면 둘의 크기(W x H x C)가 완벽히 동일해야 합니다. 이러한 shortcut의 존재는 backpropagation 과정에서 점점 작은 수가 곱해지며 앞 레이어에 도달할 때쯤 학습할 gradient가 사라지는 gradient vanishing 문제를 개선할 수 있었습니다.
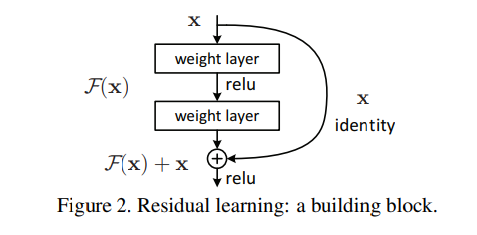
CNN에서는 이미지 크기 조절을 위한 downsampling이 필수적인데, ResNet에서는 shortcut이 지나는 레이어에 stride나 pooling layer 등의 downsampling 작업이 포함되면, 줄어드는 크기를 맞추기 위해 stride가 포함된 convolution을 shortcut에 추가합니다. 아래 그림은 VGG-19 모델과, ResNet 34모델 중 shortcut이 없는 모델, 있는 모델을 차례대로 나타낸 것입니다. 오른쪽 모델에서 실선은 convolution이 추가되지 않은 identity shortcut이고, 점선은 stride가 있는 convolution을 추가하여 feature map의 크기를 맞춰주는 것을 의미합니다.
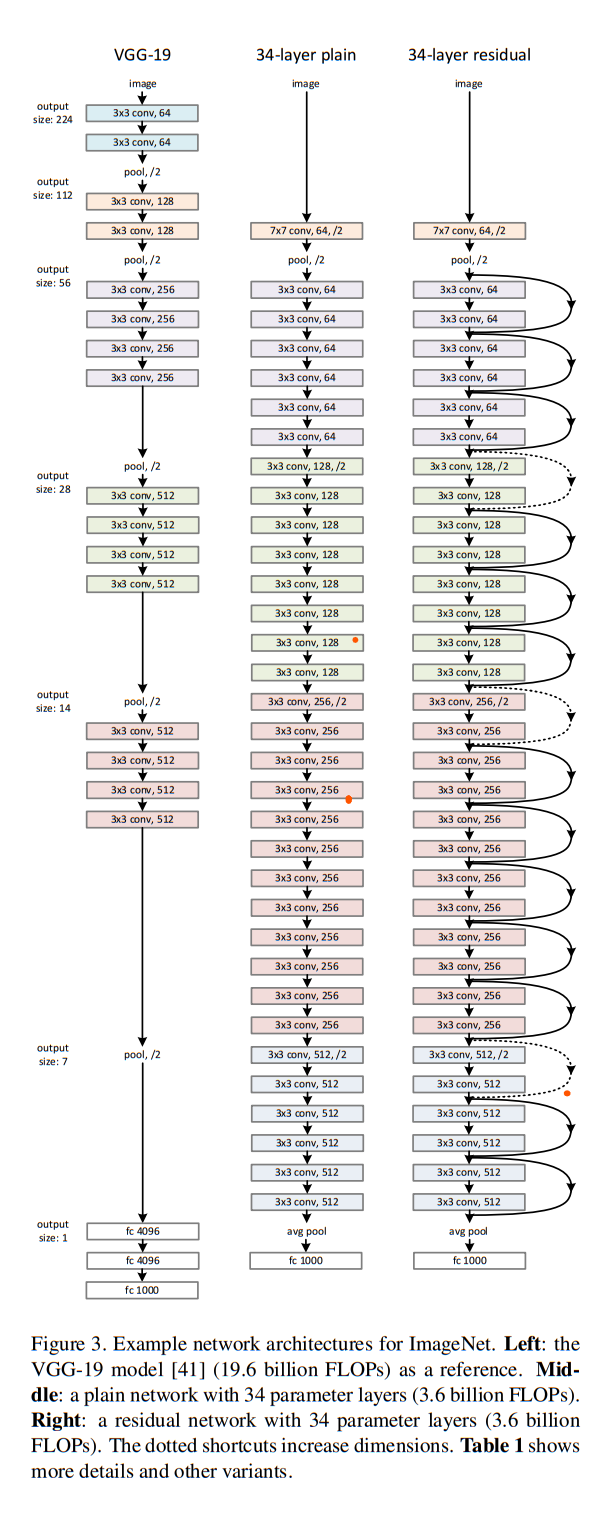
ResNet 이전의 CNN 연구에서는 레이어를 이어 붙여 모델의 깊이를 길게 하는 것이 정확도 향상에 기여하는 것은 알고 있었지만, 깊이가 깊어질수록 gradient vanishing 현상이 일어나면서 학습이 진행되지 않고, 오히려 error가 증가하는 문제점에 직면했습니다. 그러던 중 identity shortcut을 통해 연산량의 관점에서 덧셈만 추가되는 형태로 gradient vanishing 문제를 개선하고, 정확도를 향상시킬 수 있었습니다. 기존 연구했던 레이어들보다 더 깊은 레이어를 쌓고도 쉽게 최적화가 가능하다는 장점이 있습니다.
- SqueezeNet 모델
- SqueezeNet 소개
SqueezeNet 은 아래 그림의 Fire Module로 이루어진 모델입니다. Fire Module은 squeeze layer와 expand layer로 구성되어 있습니다. 처음 피처맵을 1x1 conv로 구성된 squeeze layer에 통과시켜 만큼의 채널을 가진 피쳐맵으로 만듭니다. 이후 이 피쳐맵을 동시에, 병렬적으로 1x1 conv와 3x3 conv로 구성된 expand layer에 통과시킵니다. 1x1 conv는 만큼의 채널을, 3x3 conv는 만큼의 채널을 출력하도록 합니다.
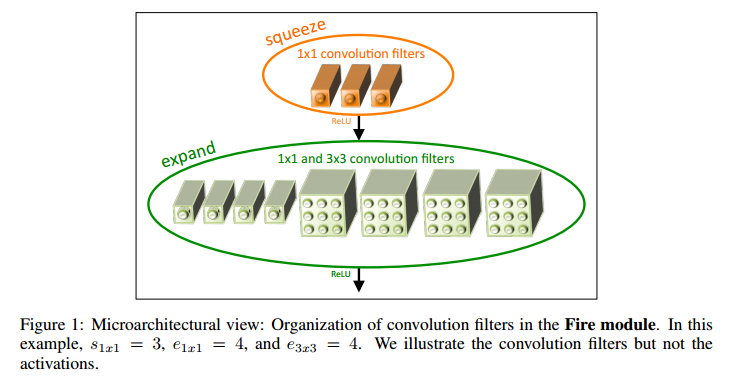
논문 저자가 파라미터를 줄이려는 세 가지 전략은 다음과 같습니다.
-
3x3 filter를 1x1 filter로 대체합니다. 연산량을 9배 줄이고자 합니다.
-
3x3 filter로 입력되는 입력 채널의 수를 감소시켜 연산량을 감소합니다.
-
pooling layer를 최대한 늦춥니다. 큰 크기의 feature map은 고해상도를 가지므로 최종 정확도를 높일 수 있다고 말합니다. (🤔큰 크기의 피처맵을 유지하면 연산량이 많아질 것으로 보입니다.)
Fire module에서 필터 수를 < ( + ) 의 조건에 맞도록 설정하여, 3x3 conv의 입력을 줄이겠다는 2번 전략을 만족하도록 하였습니다.
- 결과와 의미
2016년 개제된 논문에서, SqueezeNet의 파라미터와 성능은 AlexNet과 비교되었습니다. AlexNet보다 파라미터가 50배나 감소하였으면서 성능이 약간 더 향상되었습니다. AlexNet 자체의 ImageNet 실험 성능이 지금 모델들과 비교하면 높은 편은 아니지만, 당시로선 의미있는 결과였습니다. 논문에서는 SqueezeNet에 Deep Compression을 적용시켜 더 압축시킬 수 있다고 말합니다.
- DenseNet 모델
1. DenseNet 모델 소개
DenseNet은 ResNet에서 선보인 shortcut 구조를 활용하되 크게 두 가지 차이점이 있습니다.
- convolution 레이어의 앞뒤의 feature map 끼리만 연결하는 것이 아니라, 해당 feature map을 후반의 모든 feature map으로 연결시킵니다. 즉, 각 layer들은 모든 선행 layer의 feature map을 input으로 사용합니다.
- Convolution 연산을 거친 feature map과, 선행 layer의 feature map을 합치는 방법이 다릅니다. ResNet에서는 더하기(summation)로 합쳤다면, DenseNet에서는 concatenate 하여 독립적으로 합치고 차원이 확장됩니다.
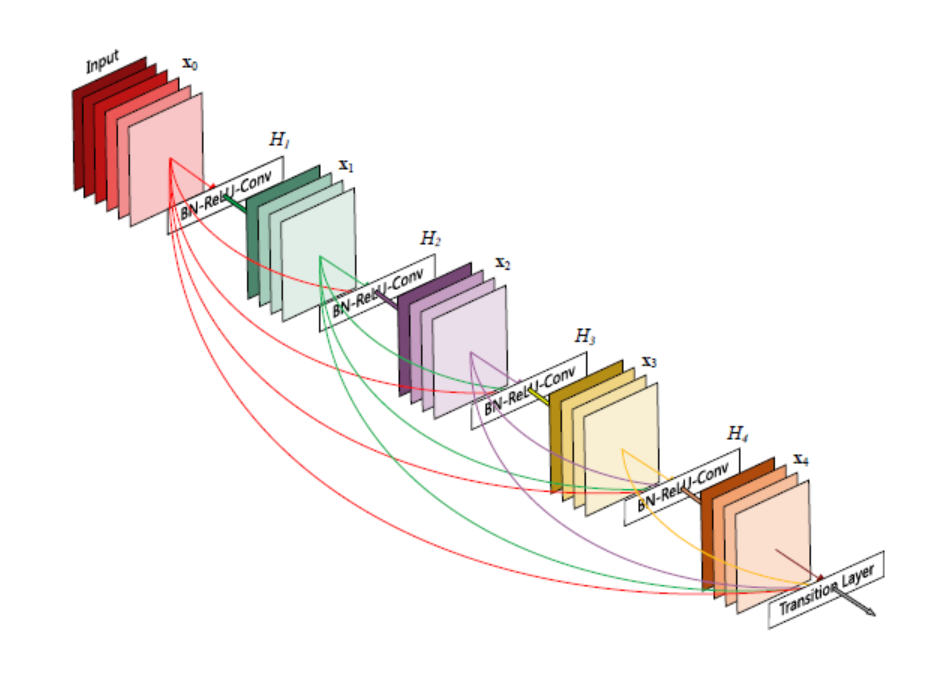
그림에서 보이는 Convolution 레이어의 결과는 전부 k개의 피쳐맵입니다. 뒤쪽 레이어도 k channel을 갖는 피쳐맵을 만들어 냅니다. 현재 레이어의 입력은 앞단의 레이어의 피쳐맵을 전부 concat한 것과 같기에, 후반으로 갈수록 Convolution 레이어의 입력 채널의 수가 쌓이고 많아지게 됩니다. 한 레이어를 거칠수록 합쳐진 피쳐맵의 채널이 k씩 증가하게 되는데, 이 k를 네트워크의 growth rate라 하고, 논문에서는 이를 하이퍼 파라미터로 하여 조절할 수 있게 합니다.
2. 자세한 구조 설명
DenseNet의 전체 모델 구조는 다음과 같습니다.

- Downsampling
CNN 모델에서는 후반 레이어로 가면서 downsampling이 필수적입니다. downsampling을 통해 피쳐맵의 크기를 줄여, 전체를 대변하는 특징을 추출할 수 있다는 장점이 있기 때문입니다. 그러나 downsample을 하면 피쳐맵의 크기가 달라져서 피쳐맵간의 concat이 불가능하므로, DenseBlock을 만들고 그 안에서만 Dense한 connection을 연결합니다. Denseblock의 안에서는 L개의 레이어를 거치도록 하고, 그 안의 레이어는 growth rate인 k개의 output channel을 만드는 컨볼루션을 진행합니다.
- Transition layer - Compression & Down sampling
Denseblock의 사이에서는 Transition Layer를 위치시킵니다. 실험에 사용 된 transition layer는 Batch Normalization과 1x1 conv layer, 그리고 2x2 average pooling layer가 이어지는 형태입니다. 2x2 average pooling layer는 위에서 설명한대로 downsampling을 하게 됩니다.
모델의 Compactness를 개선하기 위해, 1x1 convolution으로는 Denseblock간 전달되는 피쳐맵의 채널의 수를 조절할 수 있습니다. Dense 구조를 지나면 피쳐맵의 채널 수는 상당히 증가하게 됩니다. 이런 상태를 끝까지 유지한다면, 총 3개의 Denseblock을 지나면서 피쳐맵의 채널 수는 방대해지고, 연산이 매우 많이 필요할 것입니다. 이를 막기 위해 하이퍼 파라미터인 0 < < 1 를 도입합니다. 이는 compression factor라고 하는데, Dense block의 출력인 피쳐맵이 m개의 채널을 가진다면, 1x1 conv의 결과로 floor(m)개의 채널을 가진 피쳐맵을 만듭니다. 논문에서는 = 0.5으로 실험하였고, 이 조건을 DenseNet-C라 불렀습니다.
- Bottleneck layers
bottleneck 구조는 연산을 줄이기위해 많이 사용합니다. 3x3 크기의 kernel을 가진 conv로 연산을 하고 싶어도, 입력 피쳐맵의 채널 수가 많아서 연산량이 너무 많아지는 것이 우려될 때, 이 전에 1x1 conv를 먼저 계산하여 채널 수를 줄인 뒤, 3x3 conv를 수행하게 하는 것입니다. BN과 ReLU를 포함하여 추가하는 방법은 모델의 비선형성도 증가시켜 줍니다. 실험에서는 Dense block 내에서 단일 conv를 Bottleneck layers로 바꾼 경우를 DenseNet-B라 하였습니다. (참고로, ResNetv2에서 사용한 pre-activation 중 (e) full pre-activation 구조를 사용했습니다. 이는 최적화가 쉽고 overfitting을 줄이는 효과가 있습니다.) 그리고 위에서 = 0.5로 하여 compression을 준 조건과 Bottleneck layer를 동시에 사용한 조건을 DenseNet-BC라 하였고, 대부분의 실험에서는 이 조건에서 정확도가 가장 높았습니다.
3. DenseNet 구조의 효과
- Summation vs. Concatenation
'ResNet은 더하고(Sum), DenseNet은 쌓는다(Concat).' Sum의 결과로 정보가 보존되지만 결국 새로운 피쳐맵이 생성되는 것이고, Concat을 하면 기존 피쳐맵과 새로운 피쳐맵이 명확하게 구분되면서 정보가 보존됩니다.
- Dense Connection
뒤쪽 a번째 레이어에서의 연산을 생각해보면, 앞단부터 쌓여온 레이어들이 입력이 되고 출력으로 나온 새로운 k 채널의 피쳐맵이 새로 쌓이게 됩니다. a+1번째 레이어의 연산은 앞단의 모든 레이어도 물론 고려하겠지만, 주된 관심은 새롭게 추가된 마지막 k 채널의 피쳐맵에 있을 것입니다. 이처럼 네트워크가 진행됨에 따라, feature map을 그대로 보존하면서, 레이어의 연산으로 생긴 새로운 피쳐맵을 뭉쳐있는 정보 덩어리에 추가하는 과정을 반복합니다. 이 새로운 정보 위주의 처리만으로도 충분하기에 각 레이어의 convolution 연산의 out channel이자 growth rate인 k는 기존의 convolution 연산들이 썼던 큰 값이 아닌, 작은 값이어도 좋은 성능을 낼 수 있었을 것입니다. (🤔개인적인 해석입니다.) 또한 k 값이 너무 크다면 피쳐맵이 쌓이며 늘어나는 양이 너무 커져서 연산이 많아지는 문제가 생길 것입니다. 이는 기존의 연구들이 레이어의 필터 수를 매우 깊게 쌓아도, 의미있는 영향을 주지 못한 채 불필요하고 장황하기만 했던 현상과 비교해볼 수 있으며, 이 결과로 파라미터를 엄청나게 줄일 수 있었습니다.
Dense Connection을 통해 gradient back propagation이 용이하여 학습이 매우 쉬운 특징이 있습니다. 추가로, 논문에서는 dense connection은 regularizing 효과가 있어 오버 피팅을 줄여준다고 합니다.
DSN(deeply-supervised nets)라는 모델에서는, 네트워크의 마지막 단에서 추론을 하고 back propagation을 진행하는 구조에 추가로, 레이어마다 분류를 진행한 뒤 학습시키는 과정을 거칩니다. Dense Connection의 효과에 대한 추가적인 해석으로는, 레이어마다 맨 마지막과 연결된 이 구조로 인해 loss function을 공유하여 추가적인 supervision 정보를 얻을 수 있다는 것입니다. 마치 DSN과 같은 효과를 주며 DenseNet을 deep supervision이라 볼 수 있는 것입니다.
- 결론
오늘은 모델 구조를 변경하여, 새롭게 파라미터를 줄이고 정확도를 늘리는 알고리즘 기술에 대해 알아보았습니다. 무에서 유를 창조하는 것은 거의 불가능하지만, 많은 연구를 보면 기존의 연구에서 아이디어를 얻기도 하는 것 같습니다. 혹시 지금 하는 연구가 의미있는 결과를 내지 못하더라도, 이 연구를 다른 누군가가 보고 영감을 얻어 분야를 발전시키기도 하는 것 같습니다.
다음 시간에는 경량 딥러닝 알고리즘 연구 중 두 번째인 '합성곱 필터 변경'을 소개하는 글로 찾아뵙겠습니다.
경량 기술에 관련해 간략하게나마 알려드리고 싶어서, 최대한 많은 글들을 찾아보고 정리하려고 노력했지만 아직 익숙하지는 않은 것 같습니다. 많은 연습을 더하여 보기 좋은 글 보여드리도록 노력하겠습니다. 혹시 이 글에서 틀린 부분이 있거나, 추가로 알려주실 부분이 있다면 댓글로 알려주세요. 감사합니다!
참고 문헌
[DenseNet] https://arxiv.org/abs/1608.06993
[ResNet] https://arxiv.org/abs/1512.03385
[SqeezeNet] https://arxiv.org/abs/1602.07360

훌륭한 게시물 잘 봤습니다.