어떠한 요구사항을 가지고 이를 만족하는 소프트웨어를 구축하려면 요구사항을 기반으로 데이터베이스를 설계해야 한다. 그런데 이 과정에서 DB 설계를 제대로 하지 못하면 많은 문제가 발생한다. DB를 부적절하게 설계하면 어떤 정보는 추출하기 힘들고, 검색에서 부정확한 정보를 얻는 위험을 감수해야 한다. DB 설계에 관심을 가져야 하는 주된 이유는 그것이 데이터베이스 내의 데이터의 일관성, 무결성, 그리고 정확성에 결정적으로 중요하기 때문이다. 이번에는 DB 설계 과정 중에 RDB를 더욱 논리적이고 직관적으로 만드는 과정인 정규화에 대해 알아보았다.
1. 정규화란?
정규화(Normalization)의 기본 목표는 테이블 간에 중복된 데이터를 허용하지 않는다는 것이다. 중복된 데이터를 허용하지 않음으로써 무결성(Integrity)를 유지할 수 있으며, DB의 저장 용량 역시 줄일 수 있다. 또한 정규화를 통해 데이터를 다루면서 생기는 이상현상을 방지할 수 있다.
이상현상
- 삽입 이상 : 새 데이터를 삽입하기 위해 불필요핚 데이터도 함께 삽입해야 하는 문제
- 갱신 이상 : 중복되는 데이터 중 일부만 변경하여 데이터가 불일치하게 되는 모순의 문제
- 삭제 이상 : 데이터를 삭제하면 꼭 필요핚 데이터까지 함께 삭제되는 데이터 손실의 문제
정규화에는 단계가 정의되어 있는데 테이블을 어떻게 분해되는지에 따라 1차 정규화, 2차 정규화, 3차 정규화로 나눠진다. 아래에는 단계별 정규화 과정에 대해 알아보았다.
2. 1차 정규화
제1 정규화란 테이블의 컬럼이 원자값(Atomic Value, 하나의 값)을 갖도록 테이블을 분해하는 것이다. 예를 들어 아래와 같은 고객 취미 테이블이 존재한다고 하자.
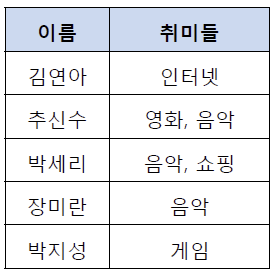
위의 테이블에서 추신수와 박세리는 여러 개의 취미를 가지고 있기 때문에 제1 정규형을 만족하지 못하고 있다. 그렇기 때문에 이를 제1 정규화하여 분해할 수 있다. 제1 정규화를 진행한 테이블은 아래와 같다.
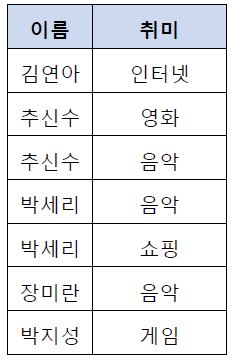
3. 2차 정규화
제2 정규화란 제1 정규화를 진행한 테이블에 대해 완전 함수 종속을 만족하도록 테이블을 분해하는 것이다. 여기서 완전 함수 종속이라는 것은 기본키의 부분집합이 결정자가 되어선 안된다는 것을 의미한다. 예를 들어 아래와 같은 수강 강좌 테이블을 살펴보자.
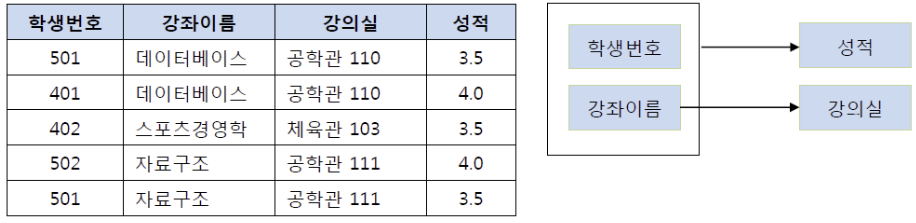
이 테이블에서 기본키(PK)는 (학생번호, 강좌이름)으로 복합키로 이루어져 있다. 그리고 오른쪽 그림과 같이 해당 기본키는 성적을 결정하고 있다. 그런데 여기서 강의실이라는 컬럼은 기본키의 부분집합인 강좌이름에 의해 결정될 수 있다. 즉, 기본키(학생번호, 강좌이름)의 부분키인 강좌이름이 결정자의 역할을 하기 때문에 위의 테이블의 경우 아래와 같이 기존의 테이블에서 강의실을 분해하여 별도의 테이블을 생성하여 제2 정규형을 만족시킬 수 있다.
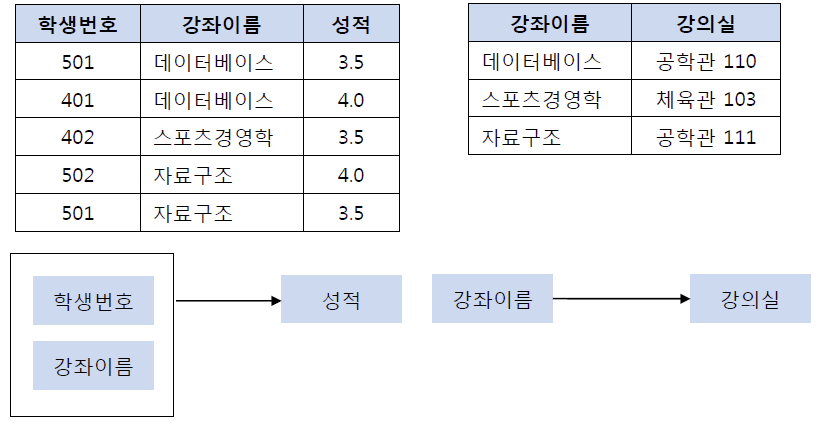
4. 3차 정규화
제3 정규화란 제2 정규화를 진행한 테이블에 대해 이행적 종속을 없애도록 테이블을 분해하는 것이다. 여기서 이행적 종속이라는 것은 A -> B, B -> C가 성립할 때 A -> C가 성립되는 것을 의미한다.예를 들어 아래와 같은 계절 학기 테이블을 살펴보자.
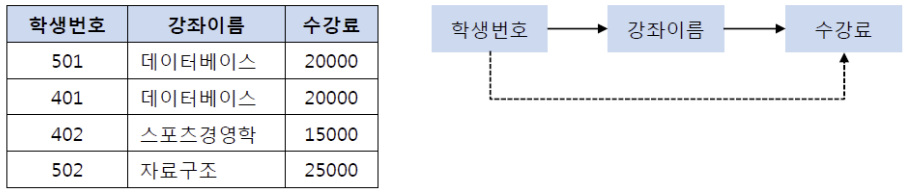
기존의 테이블에서 학생 번호는 강좌 이름을 결정하고 있고, 강좌 이름은 수강료를 결정하고 있다. 이를 이행적 종속이라 하며 따라서 (학생 번호, 강좌 이름) 테이블과 (강좌 이름, 수강료) 테이블로 분해해야 한다. 이행적 종속을 제거하는 이유는 비교적 간단하다. 예를 들어 501번 학생이 수강하는 강좌가 스포츠 경영학으로 변경되었다고 하자. 이행적 종속이 존재한다면 501번의 학생은 스포츠 경영학이라는 수업을 20000원이라는 수강료로 듣게 된다. 물론 강좌 이름에 맞게 수강료를 다시 변경할 수 있지만, 이러한 번거로움을 해결하기 위해 제3 정규화를 하는 것이다. 즉, 학생 번호를 통해 강좌 이름을 참조하고 강좌 이름으로 수강료를 참조하도록 테이블을 분해해야 하며 그 결과는 다음의 그림과 같다.
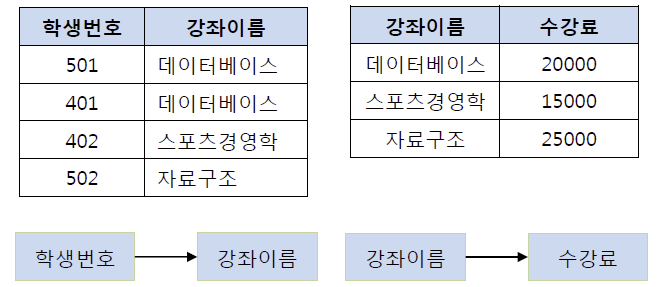
5. 역 정규화
이렇게 정규화는 데이터의 중복을 최소화하고 이상 현상을 방지하기 위해 테이블을 분해하는 과정이다. 그럼 테이블을 잘게 나누어 정규화를 많이 진행하는 것이 무조건적인 이득을 가져올까?
답은 아니다. 정규화된 모델은 저장된 자료를 검색하는데 걸리는 시간을 증가시키기 때문에 성능이 떨어진다. 이를 해결하기 위해 등장한 개념이 역 정규화이다.
역 정규화는 정규화된 테이블에 중복을 허용하고, 다시 통합하거나 분할하여 구조를 재조정하는 과정이다. 역 정규화를 통해 물리적 설계 과정에서 성능을 향상시킬 수 있다.
