학습내용
새 강사님이 오셔서 오늘은 Ai에 대한 기본 이론을 학습하고,
Orange data mining이라는 프로그램을 사용했다. 통칭 orange라고 부르면 된다.
필기내용이 있기에 캡쳐본을 삽입.



대략적인 Ai의 기초내용이다.
이 사진은 Data에 대해 배울때 띄워주신 PPT.
Titanic호 승선자 들의 생존여부를 예측하는 시트이다.
불필요한 Column을 제거(Feature 밖에있는것들)하고, 필요한 column으로 data를작성 후 학습하게 한다. 어느정도 학습이 진행되면 새로운 데이터를 입력 시
학습한 내용을 바탕으로 컴퓨터가 판단하여 생존여부를 예측.
위와 비슷한 내용인데, 아래의 두 줄은 영역 내에서 test하기위해 빼놓은 영역이다
X-train영역은 Train dataset, X_Test영역은 Test dataset이라고 칭한다.
X_test는 test의 feature가 되며, Y_Test도 test의 label이 된다.
다음은 Random Split
Label 에는 true, false가 있는것을 볼 수 있다. 하지만 위에 적은 내용처럼 test영역을 아래 두 줄로 나누면 test영역에는 false밖에 없어서 적절한 test가 실행 될 수 없다. 이 때 사용하는게 random split. 랜덤한 영역으로 테스트해보자는 의미다.
우리는 Orange라는 프로그램을 설치해서 프로그램을 체험하는 정도의 시간을 가졌다.
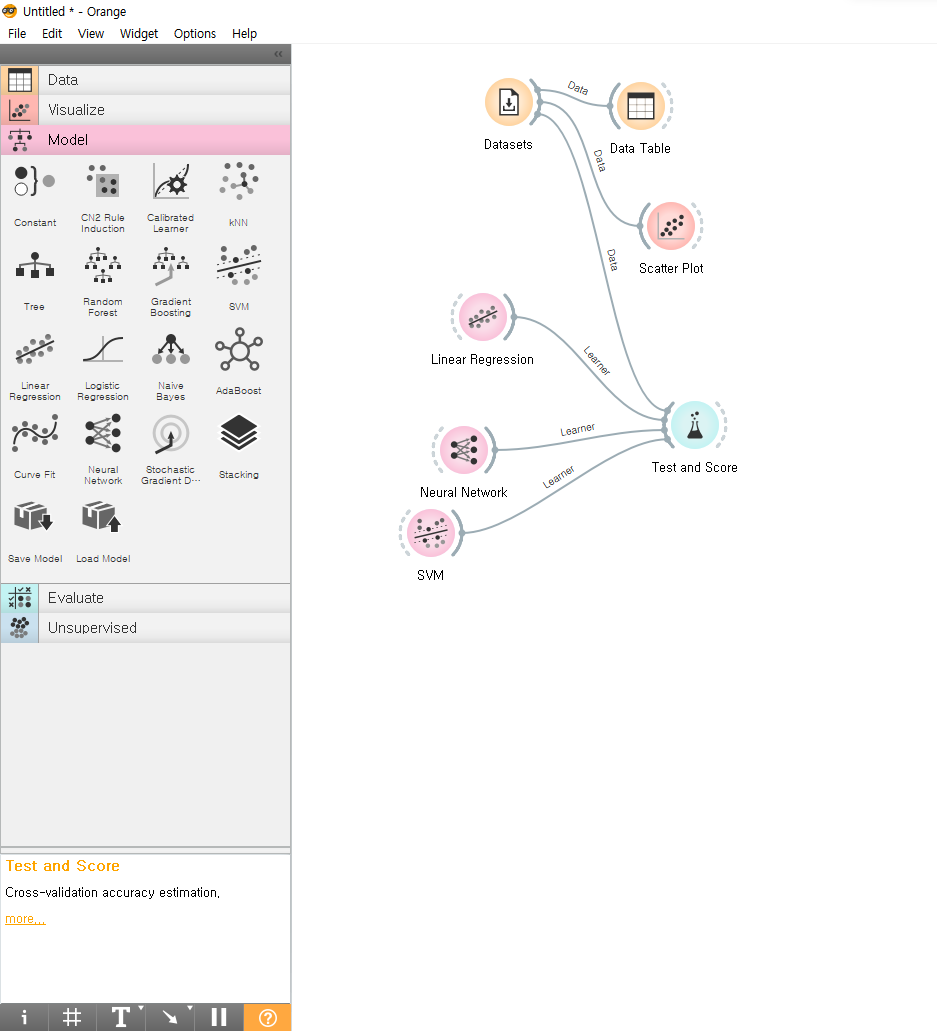
이와 같이 orange는 보기 쉽게 부품을 꺼내어 쓸 수 있도록 정리가 잘 된 프로그램이다. File에 데이터를 넣고, 주변으로 data table이나 알맞는 visualize를 화면에 보이듯 적당한 위치에 삽입하여 연결시켜주면 file에 넣은 데이터가 계산되어 각각의 부품과 연동한다.
위 사진에 있는 dataets에는 boston의 집값 측정 기준들을 삽입해놨다. 각각의 영역들과 연결되어 있는것을 볼 수 있는데, 선 위에 data는 data가 흘러가고있다는 표시. learner도 비슷한 원리다. 여기서 data table을 클릭하면
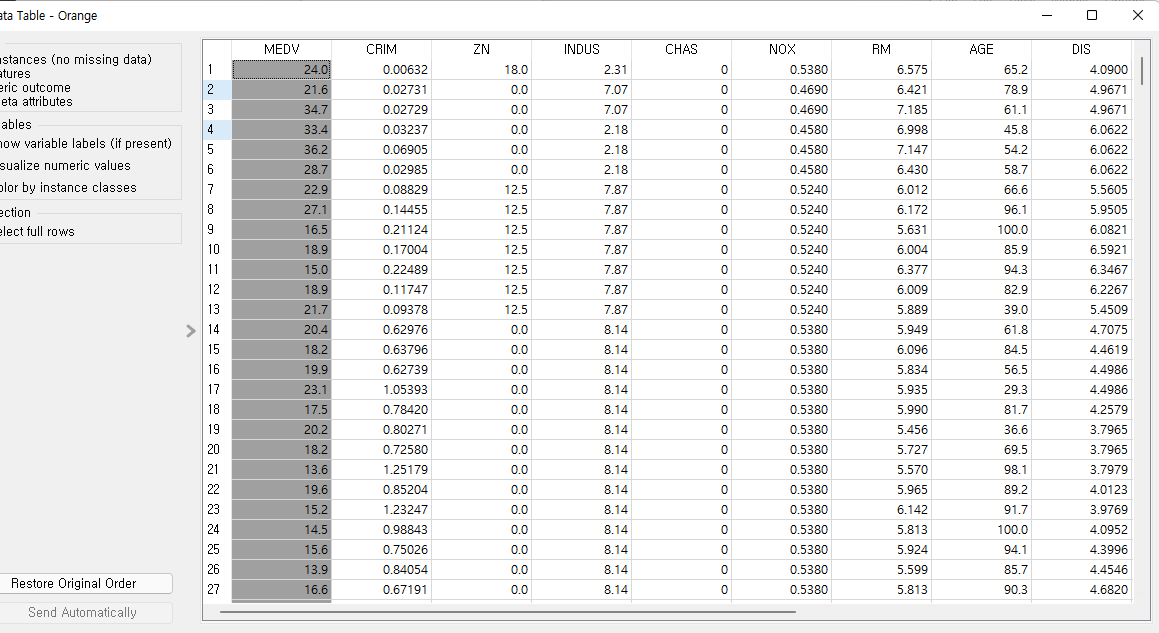
이러한 data table이 확인 된다.
또 다른 scatter plot을 클릭하면
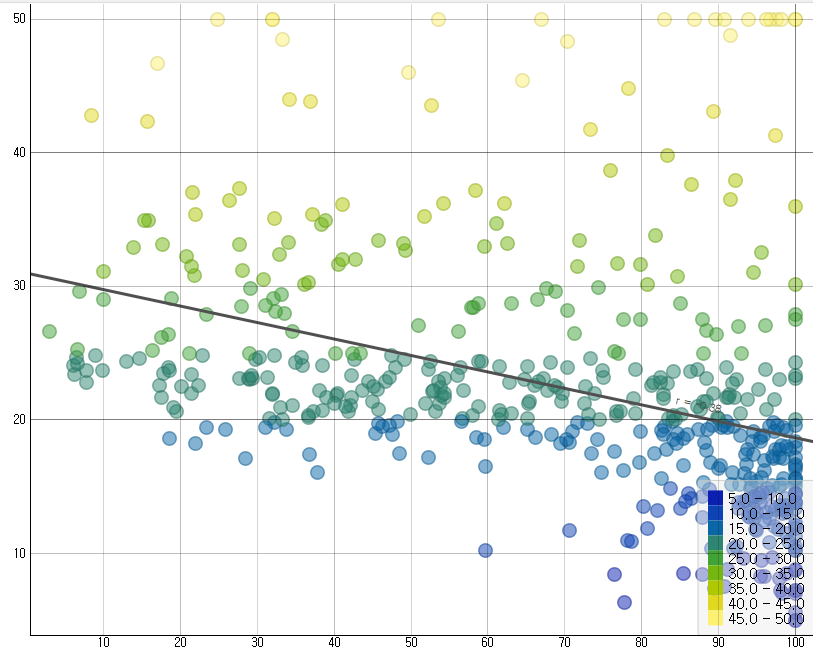
이런 차트가 뜬다. 각각의 x,y축을 설정해 내가 원하는 기준을 찾을 수 있다.
여기서 test and score를 누르면
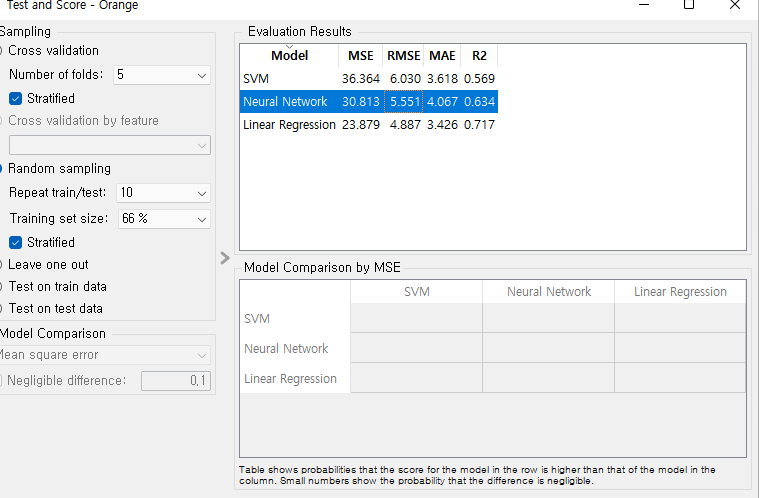
이런 창이 뜨는데, 저 표중에 Mse,rmse,mae,r2라는게 보일 것이다.
이것들은

이렇게 정리되며, 이 중 MAE는

대강 이런 공식으로 정의되며,
RMSE에 대한 정의도 있는데, 캡쳐를 못했다.
RMSE는 Root-Mean-Square-Error 라는 뜻을 가진다.
어려웠던 점
어렵다기 보다 생소한것들이 많아 허둥대던 하루였다.
해결방법
저녁 복습 예정
학습소감
새로운 강사님이 오셔서 수업을 했다.
그래도 재밌으시고 배려심도 있으신 강사님이셔서 수업이 즐거웠다.
수업시간이 길어졌지만 길어진 만큼 뭔가 제대로 할 때(?)라는 생각이 들었다.
지난주 까지 강의를 하셨던 이고잉 강사님도 참 생각이 많이 났다.
Orange라는 프로그램은 생소했지만 재미있었다! 내일도 열심히.
