개발을 하다보니 문뜩 내 코드가 너무 지저분하고 비효율 적인것 같다라는 생각이 들었다. 그래서 내가 사용하는 언어의 특징을 살려 최대한 효율적인 코드를 작성하기위해 복습겸 다시 학습을 해봤다
비효율적 코드의 문제점
-
코드 분석시간 증가 -> 변경시간 증가 -> 비용증가
-
소프트웨어의 가치는 ‘얼마나 유연하게 잘 변화’수 있냐이다
-
변화하는 세상에 알맞게 바뀌어야한다 / 앞으로 변화에 적응해야한다.
쉽게 말하면
=> 코드를 효율적으로 짜지 않으면 시간이 지날수록 코드의 변경/수정이 일어날수록 코드의 양이 증가한다. 그러므로 변경/수정 시간이 길어지게 되면서 비용이 증가하는 악순환이 계속된다.
절차지향 vs 객체지향
절차지향
;.png)
- 여기서는 절차 지향이 뭔지는 자세히 설명하지 않겠다. 절차지향은 말그대로 코드의 흐름 순서대로 위에서 아래로 실행되며 실행속도가 빠르지만 시간이 갈수록 코드양이 쌓여가며 관리, 변경,수정이 힘들 다는 단점이 있다. 그렇게 되면 당연히 비용이 증가할수 할 수밖에 없다.
객체지향
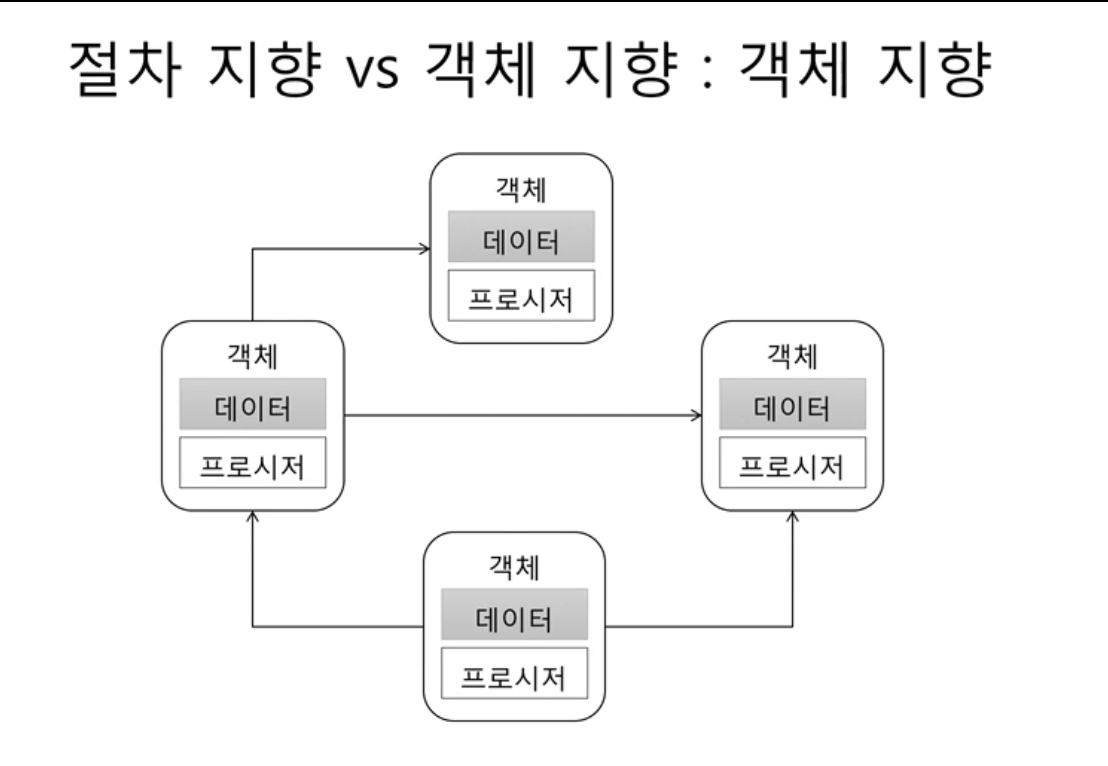
-해당 객체의 프로시저만 객체 데이터에 접근할수 있도록 객체로 묶는다.
그렇다면 객체란 무엇일까?
- 막상 생각없이 사용하다 이 질문을 받았을때는 약간은 멈칫했다. 그냥 클래스는 객체를 만드는 뼈대정도로 생각하고 그게 객체가 된다고 생각했다.
객체의 핵심 ->기능 제공
- 객체는 내부로 제공하는 기능으로 정의한다
- 내부적으로 가진 필드(데이터)로 정의하지 않음

- 이런건 객체라기보다는 데이터 클래스에 가깝다. 객체의 핵심은 기능제공!
- 특별한 기능이 없기 때문에… 객체는 기능으로 정의 한다!
캡슐화
= 데이터와 데이터와 관련된 기능을 묶는 방법!
캡슐화 특징
-
데이터와 관련된 기능을 묶고 상세내용 감추기
-
내부 변경에 대해 유연하다. -> 내부변경을해도 그것을 사용하는 코드는 바뀌지 않아야한다.
-
캡슐화를 잘해야 수정시간도 줄고 그만큼 비용도 낮아짐
-> 위에서 말한 비효율적 코드의 문제점 해결방법중 하나이다!
캡슐화를 왜 써야할까??
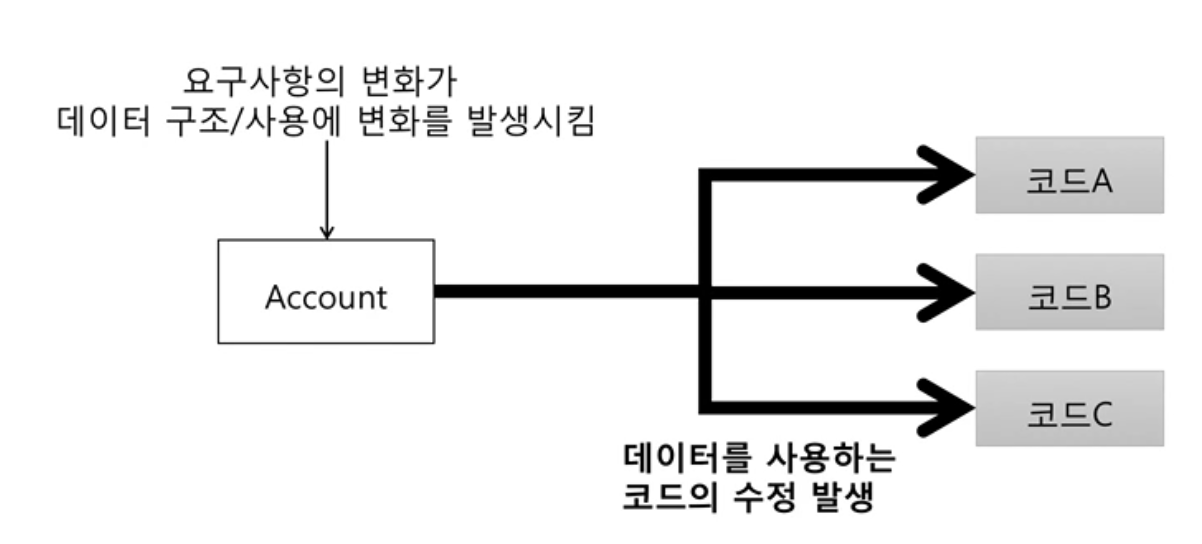
- 반복되는 코드가 많으면, 캡슐화가 되지 않았으면 그만큼 서로에게 독립적이지 않게되고 의존을 하여 영향을 주게된다.즉 이 상태에서 조금이라도 수정을 하면 전체코드를 수정해줘야한다.
- 시간이 지남에 따라 요구사항이 늘어날수록 기능을 수행하는 코드의 변화가 계속 일어난다
- 서로 의존 적이니 코드의 변화가 일어날때마다 모든 코드를 수정 해줘야 한다.
캡슐화 실습

- 가장 이상적인 방법이다. 수정이 일어나도 해당 기능만(오른쪽) 바꿔주면 되고 코드수행 구간(왼쪽) 은 전혀 변경 사항이 없어도 잘 작동 한다.
- 캡슐화는 연쇄적인 변경 전파를 최소화 시킨다
캡슐화와 기능
= 캡슐화 시도 -> 기능에 대한 (의도) 이해를 높인다.

-
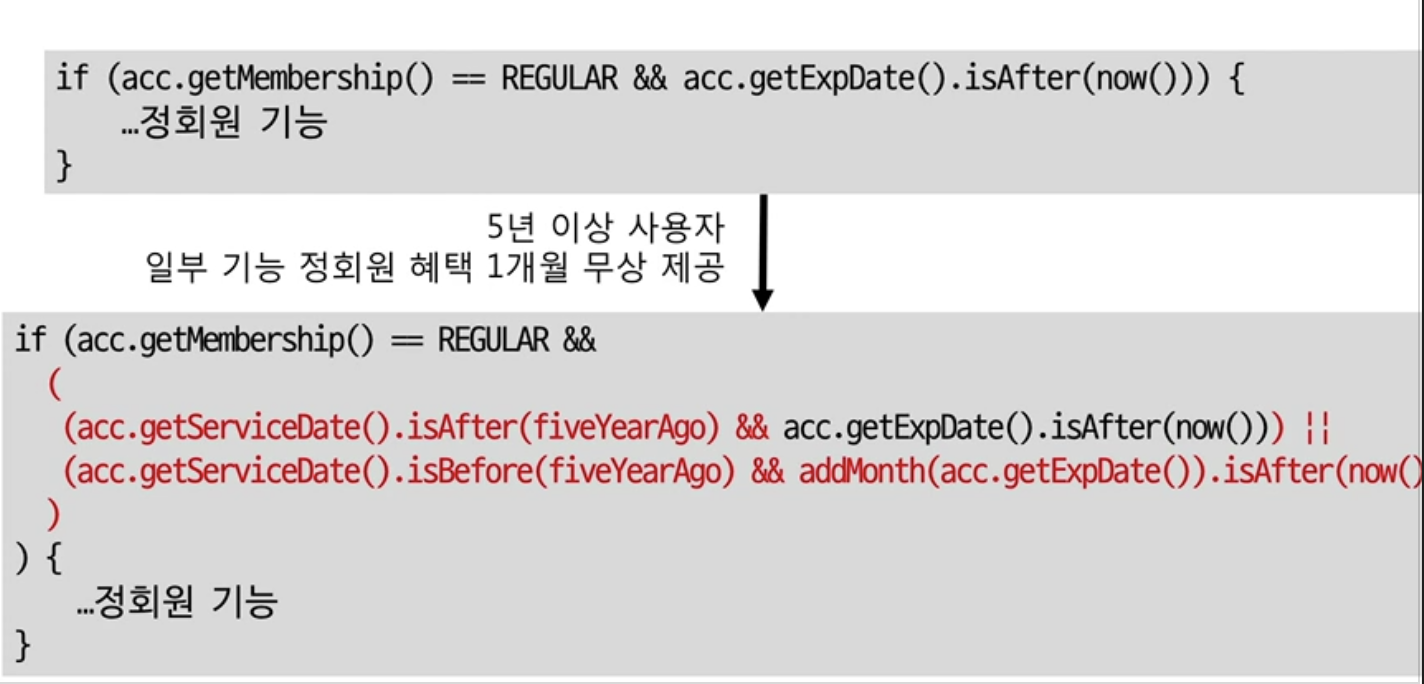
예시 코드이다. if문에서 왜 권한이 REGULAR 인지 검사를 하는 것일까?
-
간단하다 REGULAR권한을 가졌는지 확인하기 위함이다
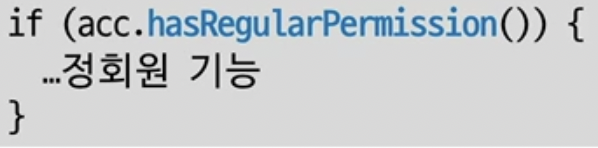
-
의도를 이해하면 캡슐화를 하기 쉬워진다.
캡슐화를 위한 규칙

1. Tell, Don't ask
= 데이터를 달라는 식이 아닌, 해달라는 식으로 생각을 하자!
= 약간 직접적으로 구하는게 아닌 우회해서 하는 느낌으로 그래야 그 직접적인 부분만 요구사항에 맞춰 수정하면 되기 떄문
2. Demeter's Law

- 특정 객체의 메서드만! 호출 하는 식으로 바꾸면 캡슐화에 가까워진다.
- 왼쪽이 여러 곳에 쓰여있다가 수정을 해야한다고 하면 일일이 다바꿔줘야 하지만 오른쪽 같이 한메서드로 묶어버리면 그 메서드 내용만 변경하면 여러곳에 적용이 한번에 가능하기때문
추상화
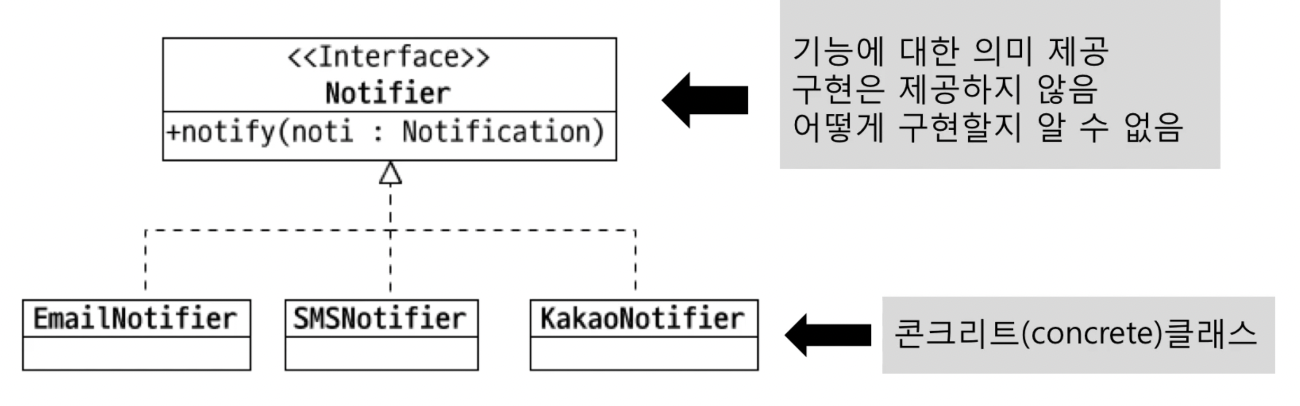
- 여러 구현 클래스를 대표하는 상위타입을 도출한다
추상화를 왜 사용할까?

-
구현클래스(콘크리트) 클래스를 직접 사용할 경우 기능이 추가될때마다 추가한다.
-
수정/변경시 서로에게 영향을 줄 가능성이 크다(서로 의존적이다)
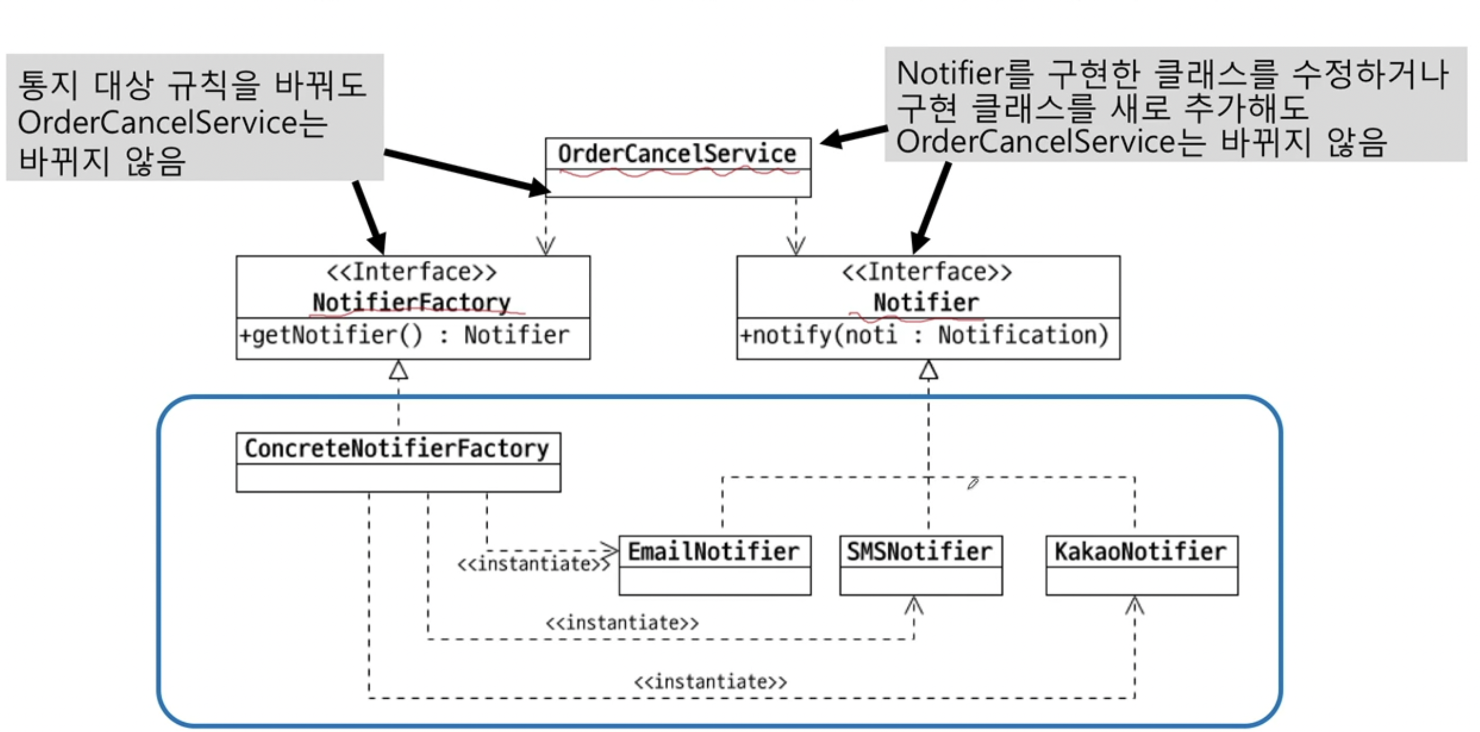
-
추상화를 사용해 대표하는 타입으로 묶어줄 경우 수정/변경시 콘크리트 클래스만 수정하면 된다. 기능 추가할 경우 그냥 구현클래스 추가해 주면 된다.
-
이러한 변동사항들이 있음에도 불구하고 실행 코드들은 전혀 변함이 없다.
추상화 사용시 주의점!

- 추상화 -> 추상타입증가 -> 복잡도 상승
= 아직 존재하지 않는 기능 에대한 이른 추상화는 복잡도만 증가 시킨다!
= 그러므로 실제 변경이나 수정시 추상화를 시도 해보자!
상속 보다는 조립

- 상속의 장점은 코드를 재사용 할수 있다는 점이 있지만 그 장점을 감안하고 가져가기에는 단점도 많다.
상속의 문제점
1.필요 없는 코드까지 상속 받아야 한다는점
2.상위 클래스 변경의 어려움(하위클래스 까지 영향을 다 주니까)
3. 기능추가 ->클래스 추가 ->복잡도 증가
이것을 해결하기 위해 사용한느 방법이 조립(주입) 이다. 조립(주입) 을 알아보자!
조립(주입)
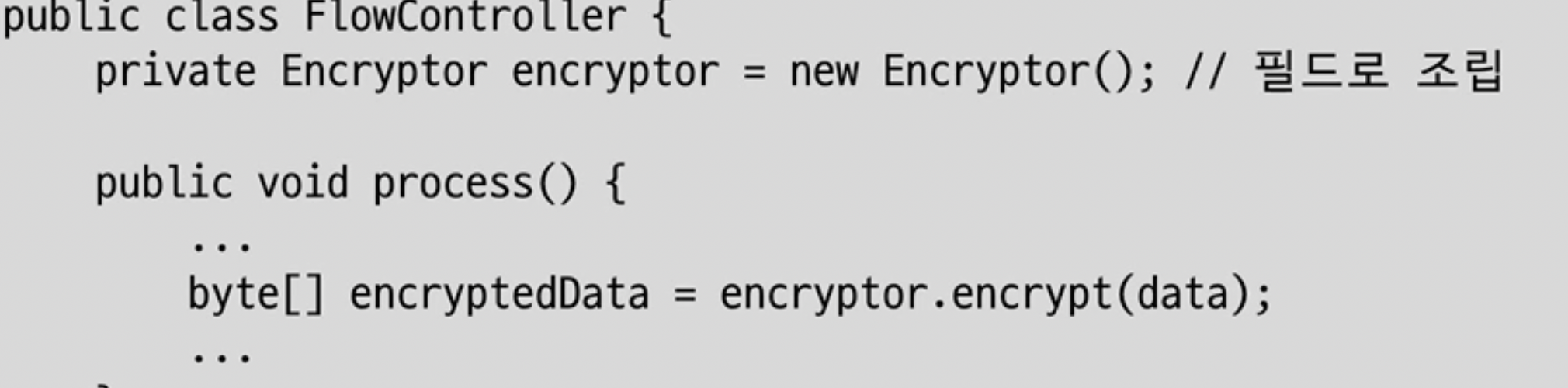
-
클래스 증식등 상속문제에 대해 해결이 가능하다. 원하는 기능이 있으면 클래스로 만든뒤 조립(주입) 시켜주면 된다
-
또한 조립(주입) 을 이용하면 하위클래스가 없으니 코드 변경이 용이하다.(서로 독립적이니까)
-
불필요한 기능들 상속도 방지할수 있다.(필요한것만 만들어서 주입시켜주니까)
-> SpringBoot 프로젝트에서 이제야 왜 굳이 애노테이션을써가며 IOC컨테이너에 등록을 하고 객체 주입을 해서 사용하는지 이유를 알게 됐다. 어떻게 사용하는지는 알았지만 왜 사용하는지 확실히 알게 됐다.
큰 클래스 / 큰 메서드
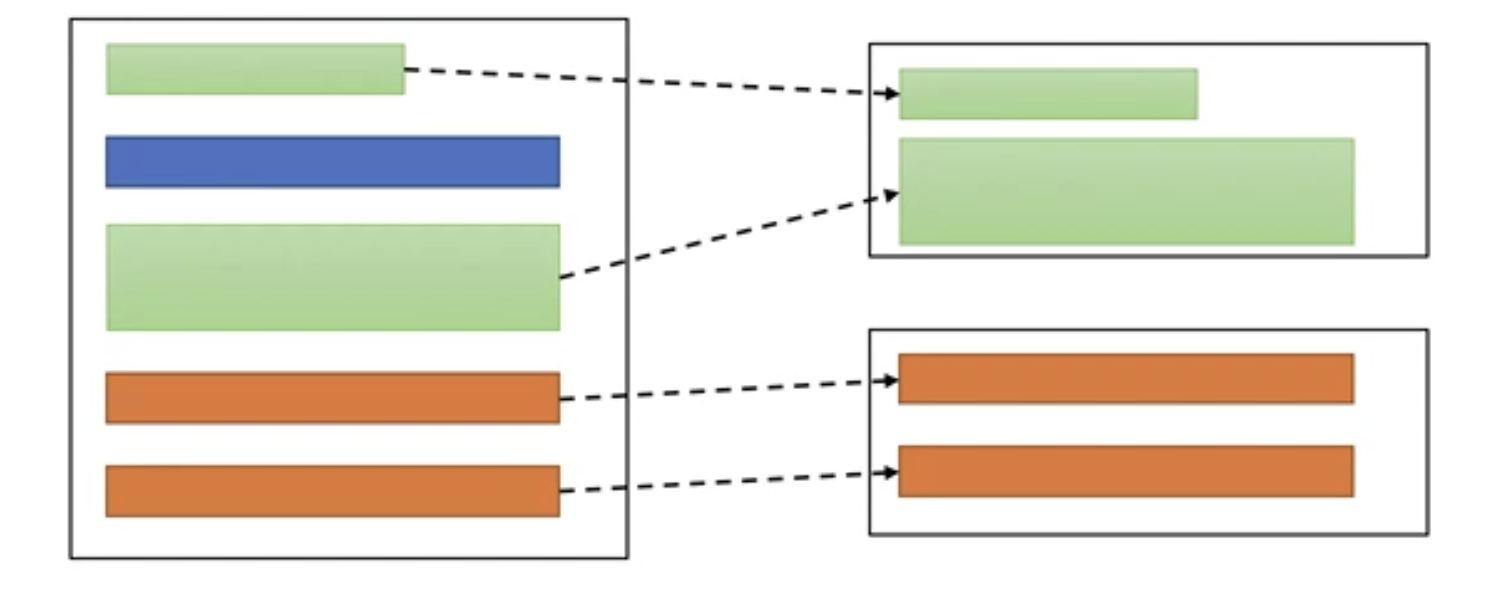
-
클래스나 메서드가 너무 커져버리면 절차지향 문제가 일어난다
-
큰 클래스 -> 많은 필드를 많은 메서드가 공유
-
큰 메서드 -> 많은 변수를 많은 코드가 공유
=> 책임에 따라 알맞게 분배를 해줘야 한다.
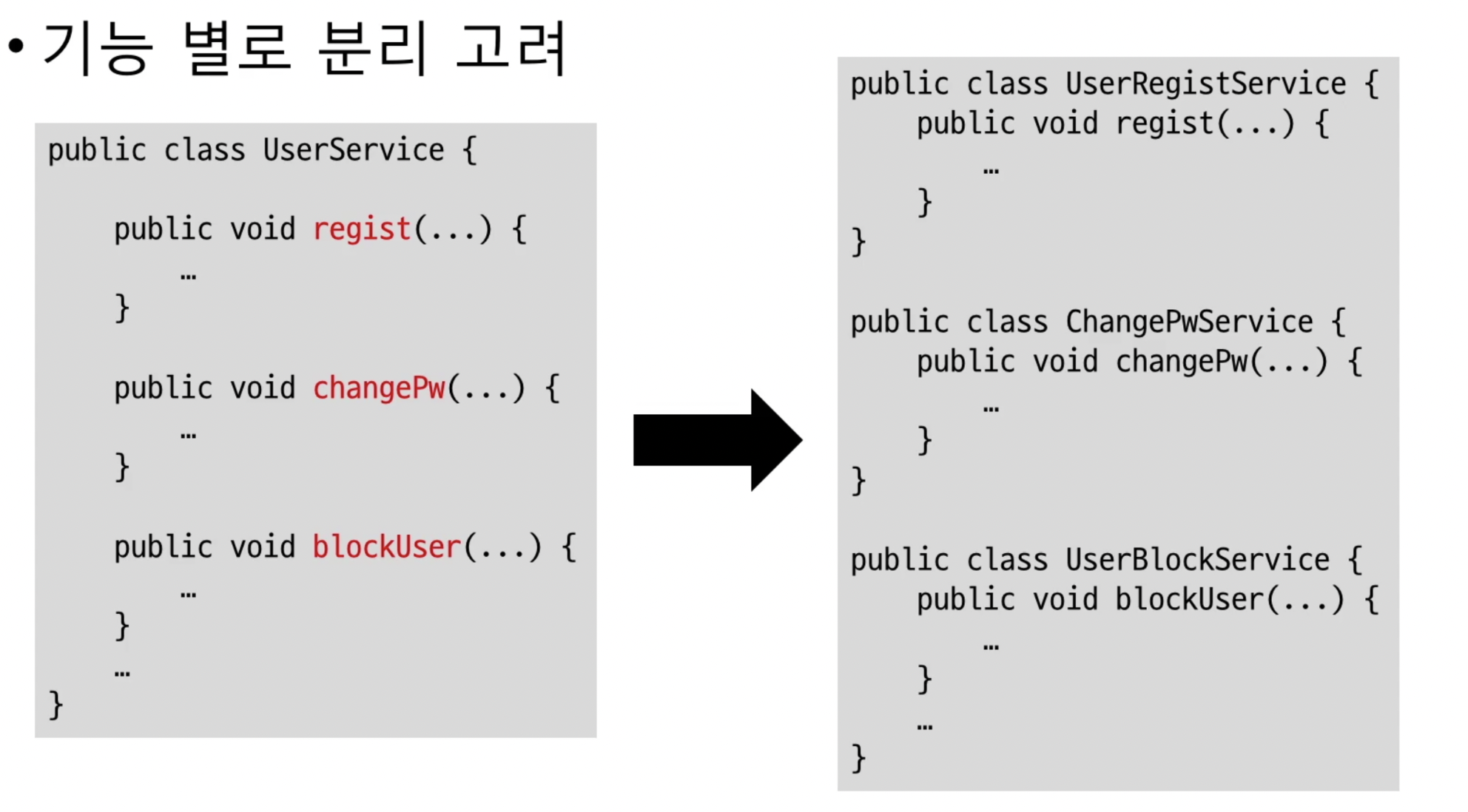
코드분리
코드분리방법에는 4가지가 있다
- 패턴적용
- 계산 기능 분리
- 외부 연동 분리
- 조건별 분기는 추상화



-
이 코드들의 공통점은 최대한 묶을수 있는것은 묶으며(캡슐화) 중복을 최소화로 만들어준다.
-
그래서 나중에 코드의 변경이나 기능 추가가 일어날때 코드 실행 부분은 변화가 없고 실질적 코드 기능부분들만 수정하면 정상작동하도록 만들어 준다.
-
어떻게 보면 지금 내가 당연하듯이 사용하는 컨트룰러/서비스/레파지토리/엔티티 등등 나누는 이유들에 해당되는 이야기들이다. 이번 기회로 왜 나눠야하는지에 대해 확실히 배웠다.
의존
= 기능 구현을 위해 다른 구성 요소를 사용하는 것
- 의존은 변경이 전파될 가능성을 의미한다. 즉 의존이 적으면 적을수록 좋다
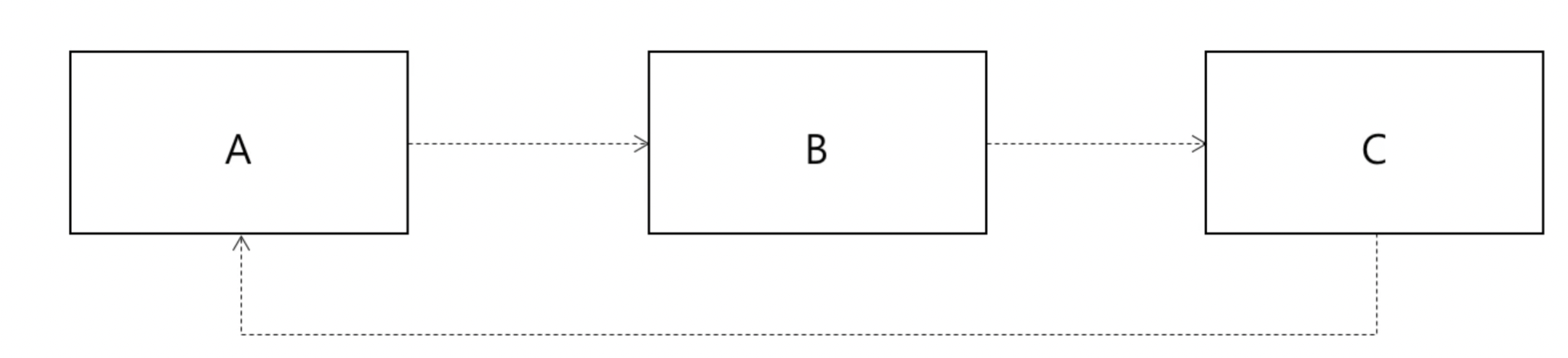
- 대표적인 문제 순환의존 문제이다.
- 서로 의존하면 최초 a가 변경시 변경이 전파되므로 오류 발생
- 그래서 의존하는 대상이 적어야 좋다 -> 그래야 내가 바뀔 가능성이 낮기 때문
기능분리
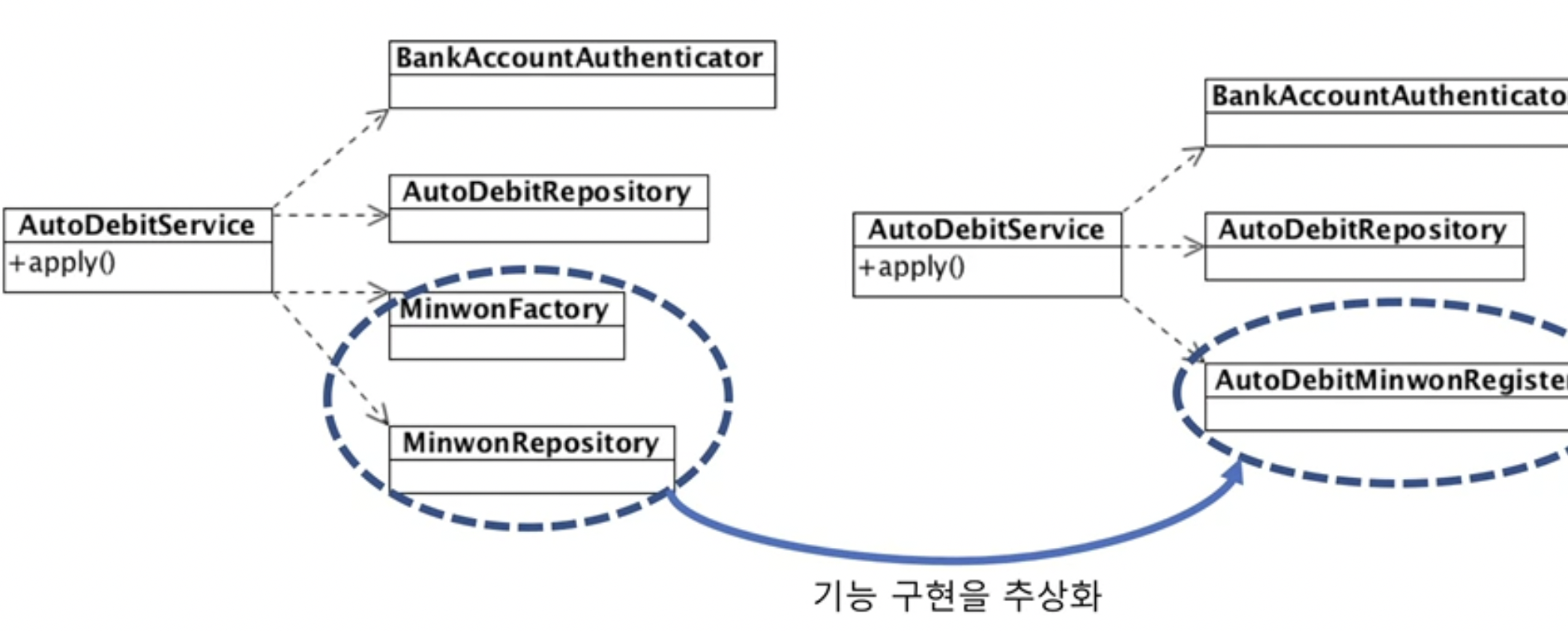
- 분리를 잘해 서로 최대한 의존하지 않도록 만들어야 코드 변경,수정시 서로 영향을 덜 줄수 있다.
그렇다면 의존 주입(DI)를 하는 이유는 무엇일까?
1. 생성클래스가 바뀌면 의존하는 코드도 바뀌기 때문, 그래서 외부에서 객체를 생성자나, 메서드를 이용해 주입시켜준다.
2.그래야 코드도 독립적이고 의존성이 낮아지기때문
3.독립성이 높아지면 기능추가나 수정이 일어나도 의존객체만 바꾸고 나머지는 바꾸지 않아도 되기때문
OCP
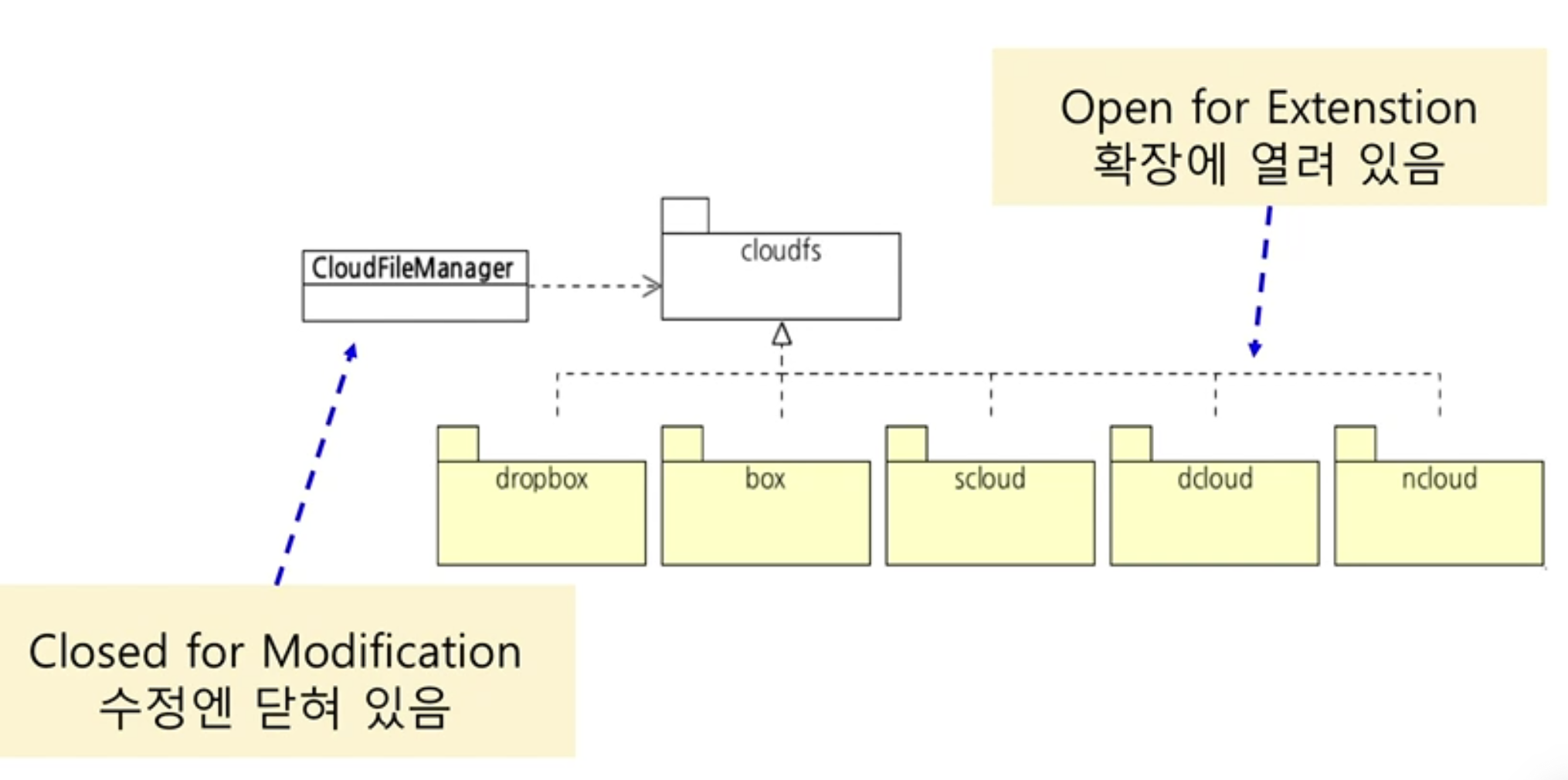
-
개팡폐쇄 원칙
= 확장에는 열려있어야하고수정에는 닫혀있어야한다 -
구현 클래스만 추가하면(확장에는 열려있고) 실제로 실행하는 코드들은 변경 안해도(수정에는 닫혀있고) 기능이 추가된다.
DIP
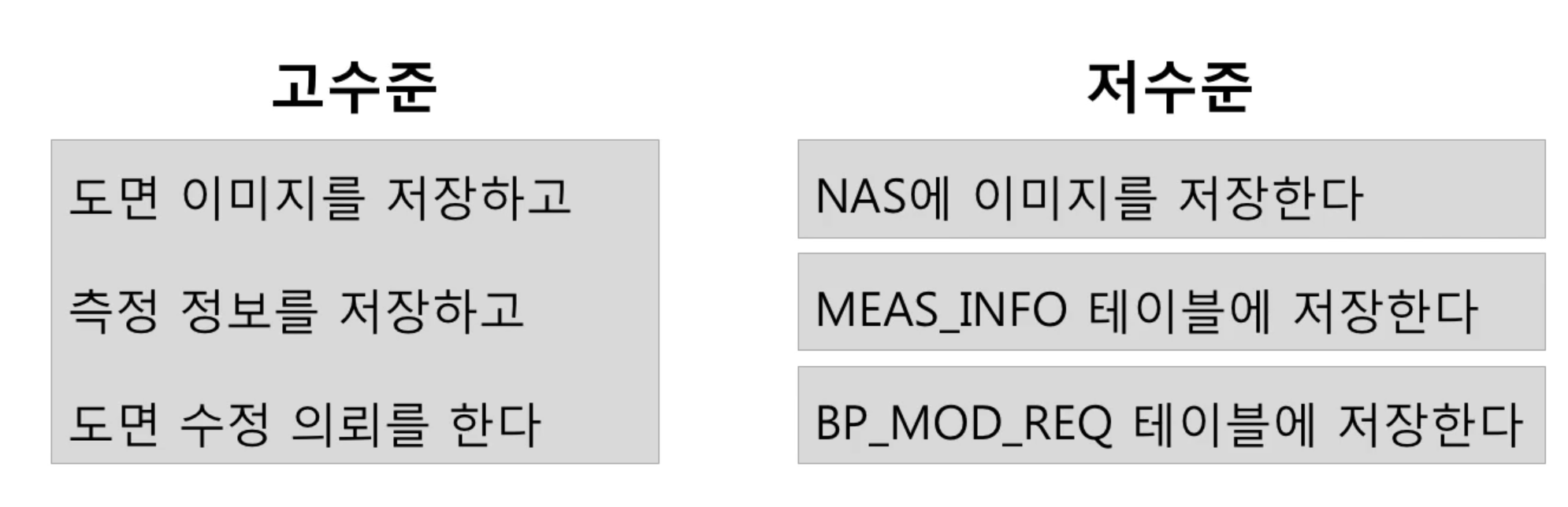
DIP를 배워보기전에 고수준모듈과 저수준 모듈에 대해 알아보자
고수준모듈
- 의미있는 단일 기능을 제공
- 상위 수준의 정책 구현
저수준모듈
- 고수준 모듈의 기능을 구현하기위해 필요한 하위 기능의 실제 구현
고수준이 저수준에 의존하는 경우
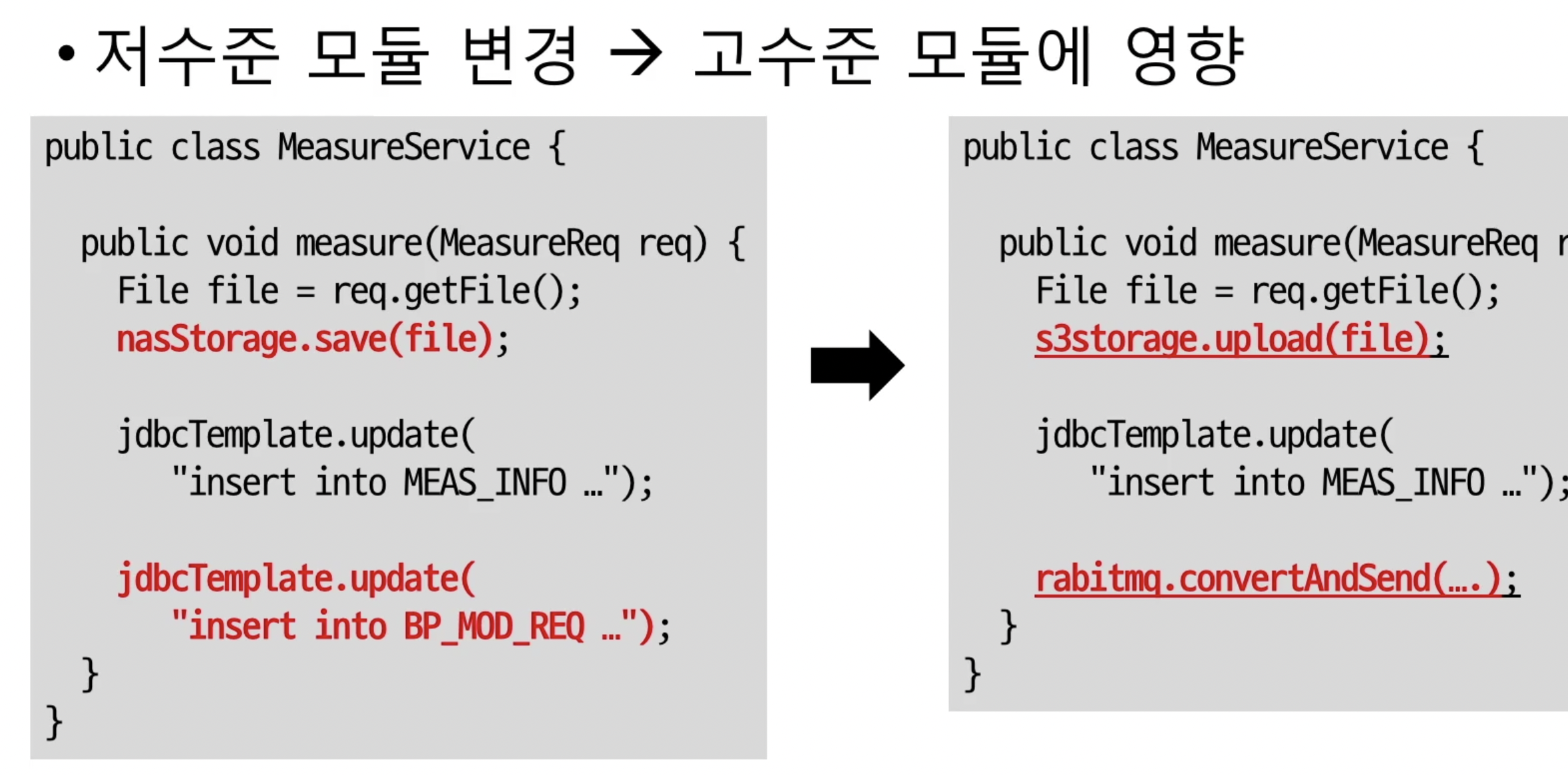
-
매번 변경,수정/ 기능 추가가 일어날때마다 코드를 수정함으로 인해 고수준 모듈(MeasureService)의 코드도 바뀌므로 영향을 받게된다.
-
저수준모듈로 인해 고수준모듈 까지 영향을 받게되는 상황을 방지하고자 해서 나온 법칙이 DIP이다.
DIP란?
=> 의존 역전 원칙
- 고수준 모듈은 저수준 모듈에 의존을 하면 안됀다.
- 저수준 모듈이 고수준 모듈에서 정의한 추상타입에 의존해야함.
DIP 특징
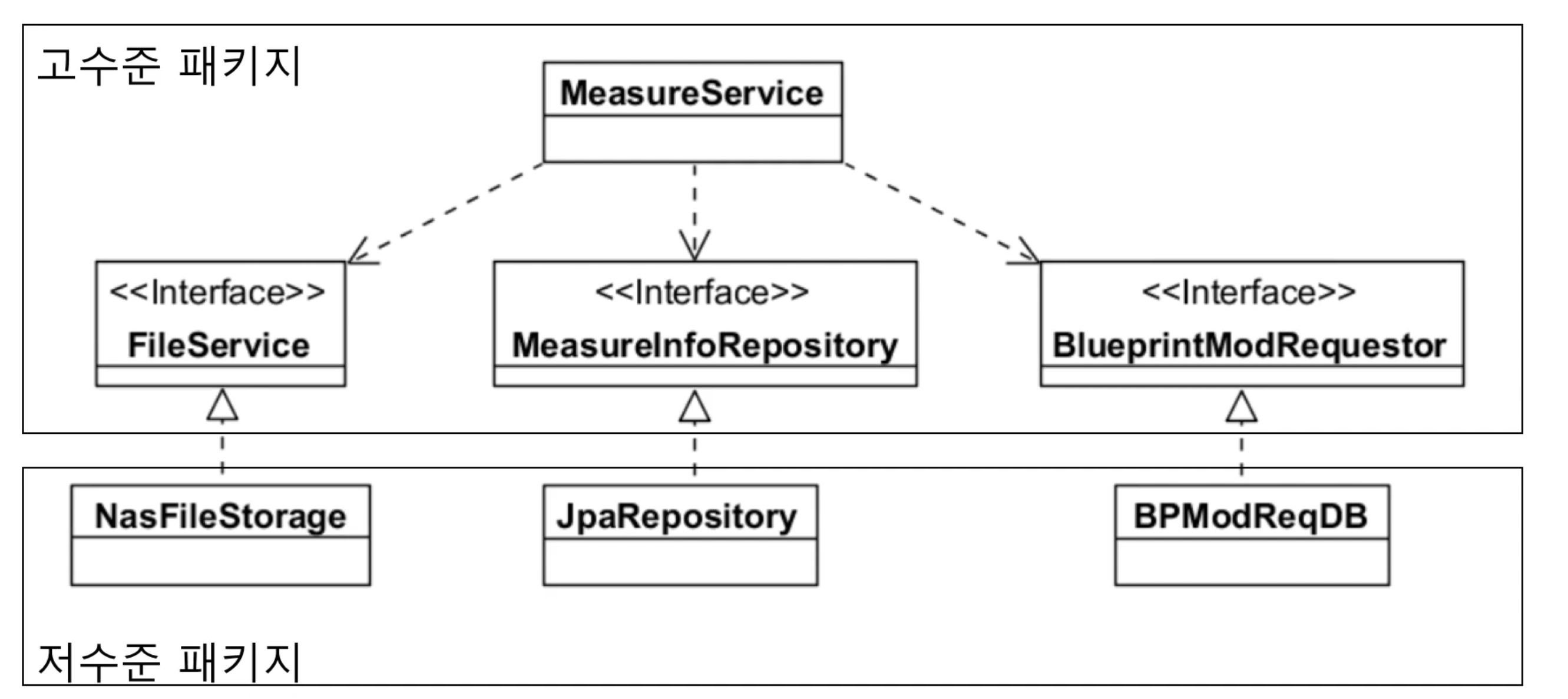
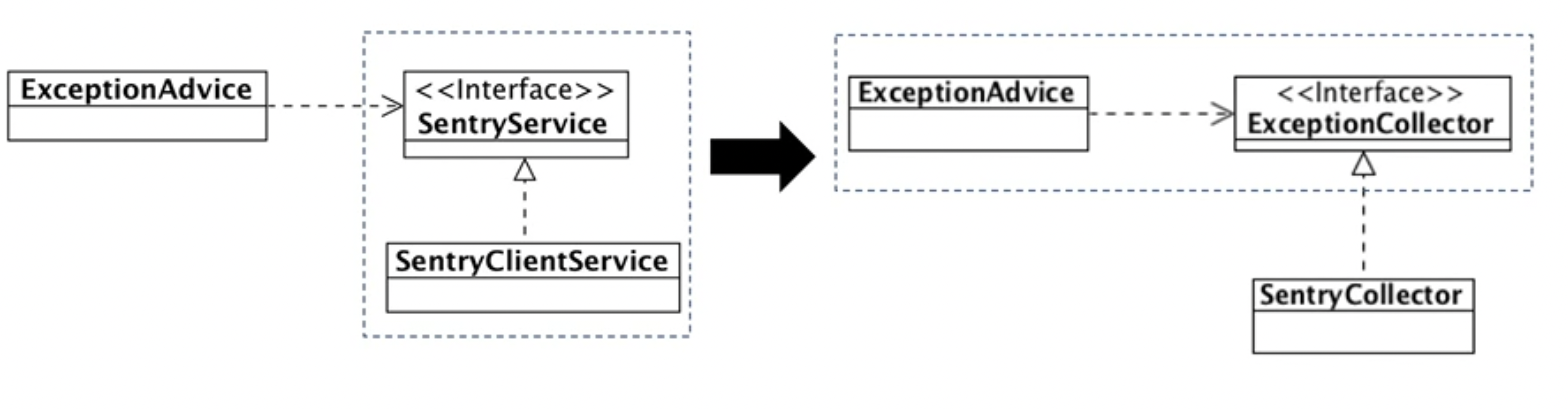
- 저수준 모듈 관점에서 추상화를 하면 저수준 모듈 중심이 돼서 고수준 모듈 관점에서 추상화를 해야한다.
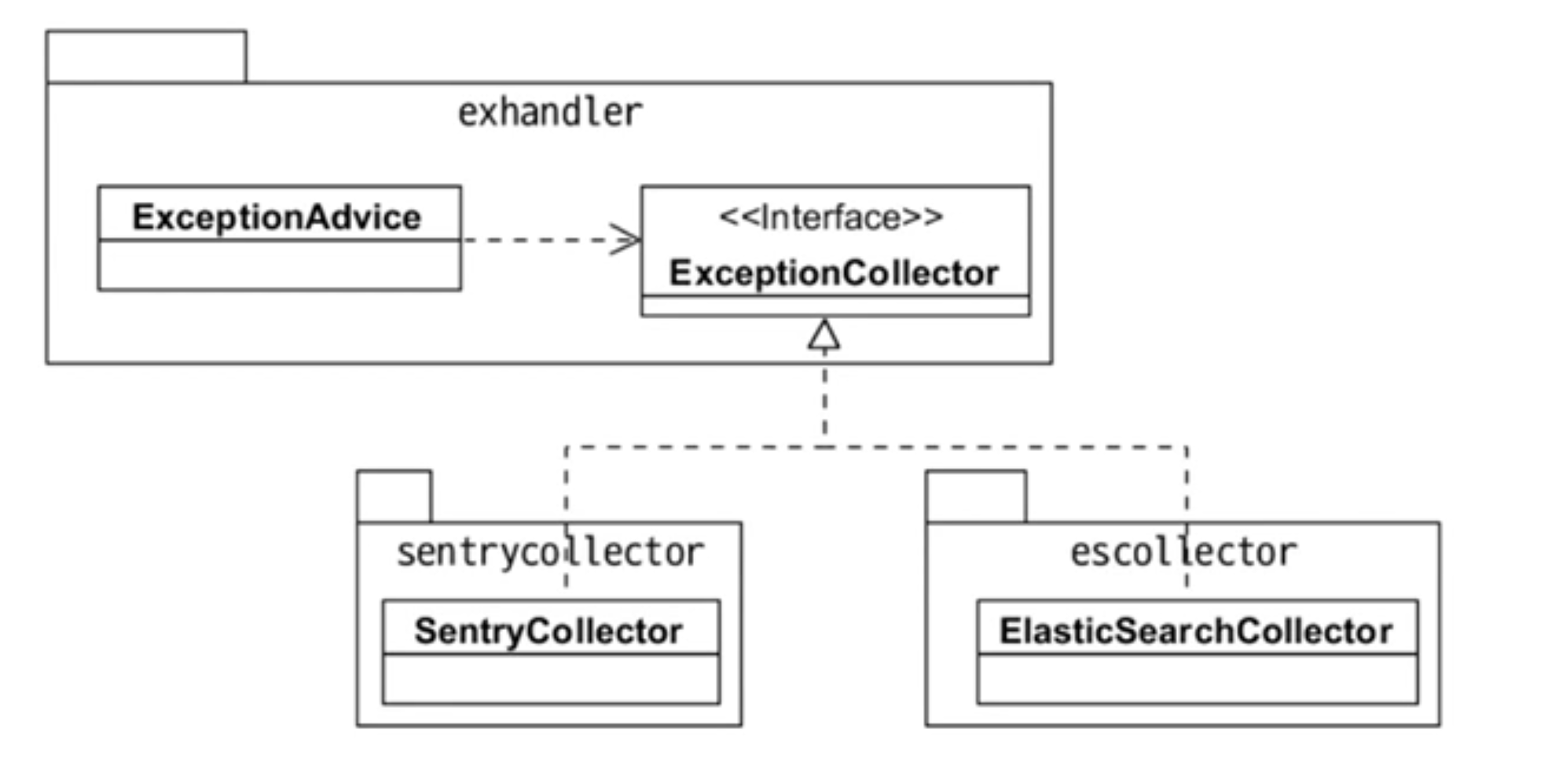
- 고수준 모듈관점에서 추상화(DIP)를 하게되면 고수준 모듈의 변경은 최소화하면서 저수준 모듈 변경의 유연함을 높일수 있다.
