HashSet
-
HashSet 은 set인터페이스의 가장 대표적인 컬렉션이며 중복된 요소를 저장하지 않으며 저장순서를 유지하지 않는다.
-
저장 순서를 유지하고 싶으면 LinkedHashSet을 사용해야한다.
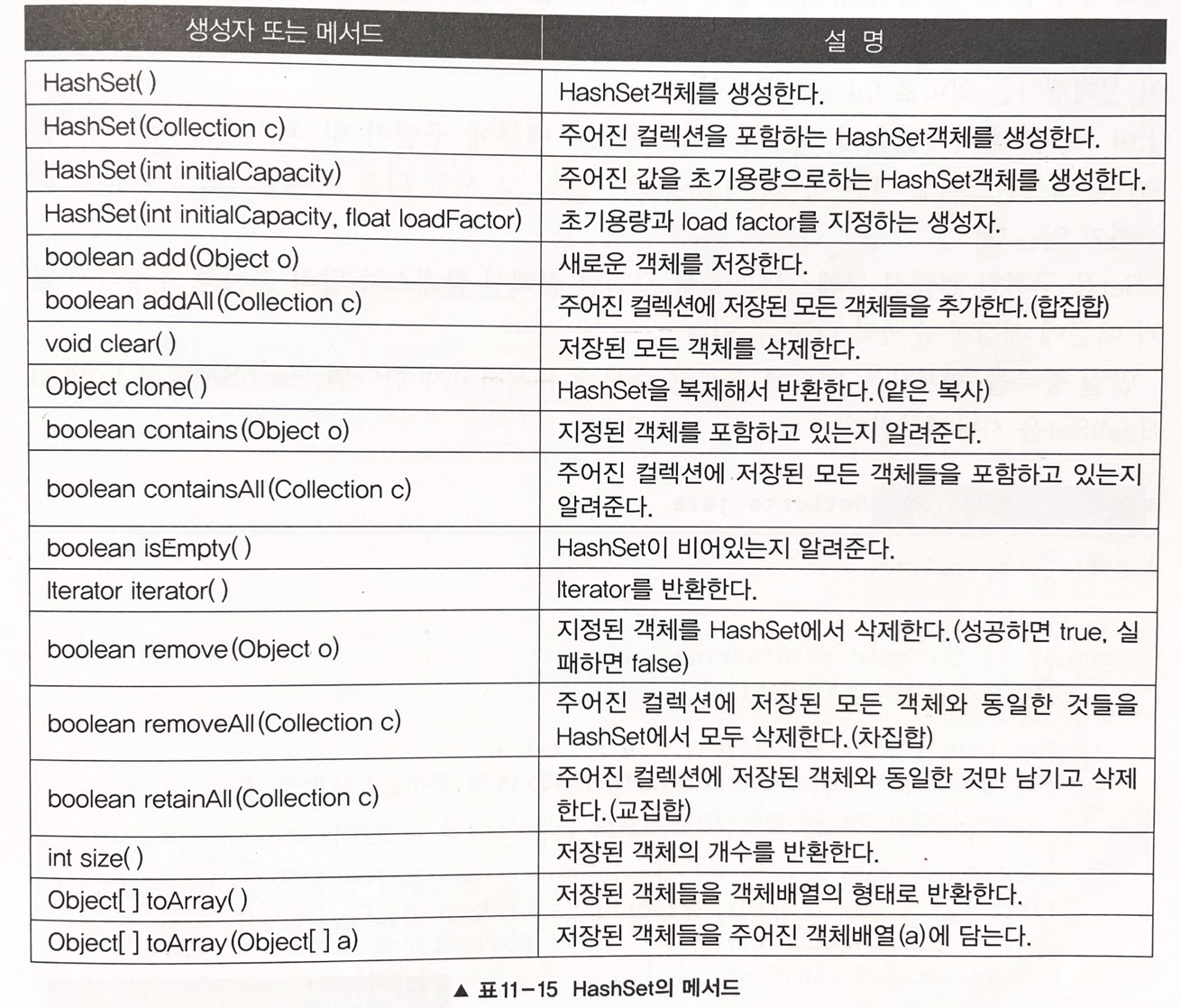
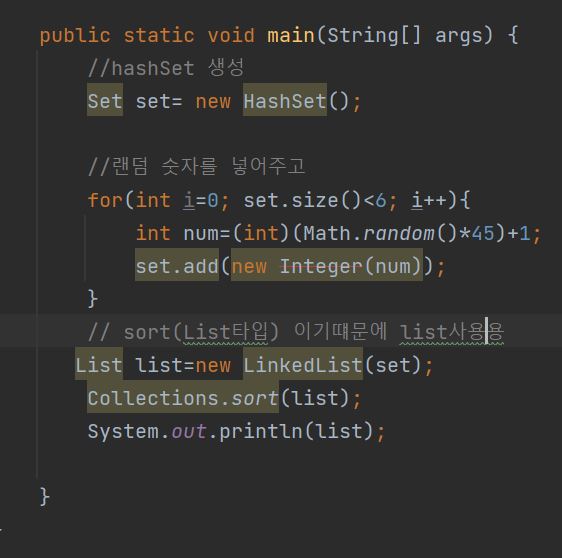
- 중요 포인트는 Collections 클래스의 sort(List타입) 이기때문에 sort를 쓰기위해 list타입에 set을 넣어준다.(linkedList(Collection c)
※ Arrays.sort() => sort(배열) / sort(배열, comparator c)
※ collections.sort() => sort(List list)/ sort(List, comparator c)
※ collection 은 인터페이스 collections 는 클래스이다
hashSet 연습
1
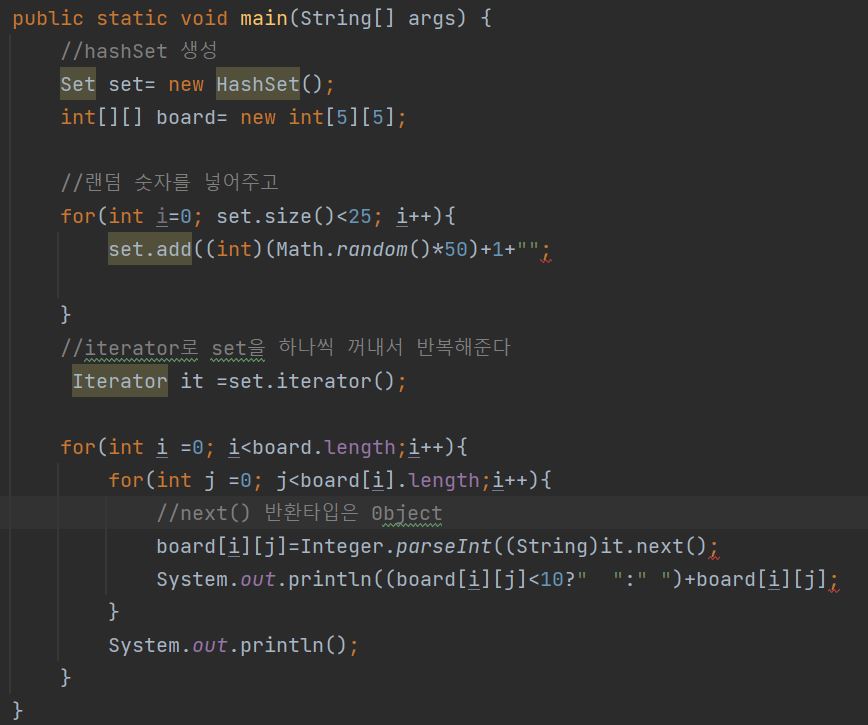
-
빙고를 만든 예제이다. set에 랜덤숫자를 문자열로 넣어주고 set을 iterator로 하나씩 꺼내 반복시키면서 이차배열에 넣어준다
-
next() 반환타입은 object이므로 String으로 맞춰주고 inter.parseInt로 기본형으로 변환시켜준다
2
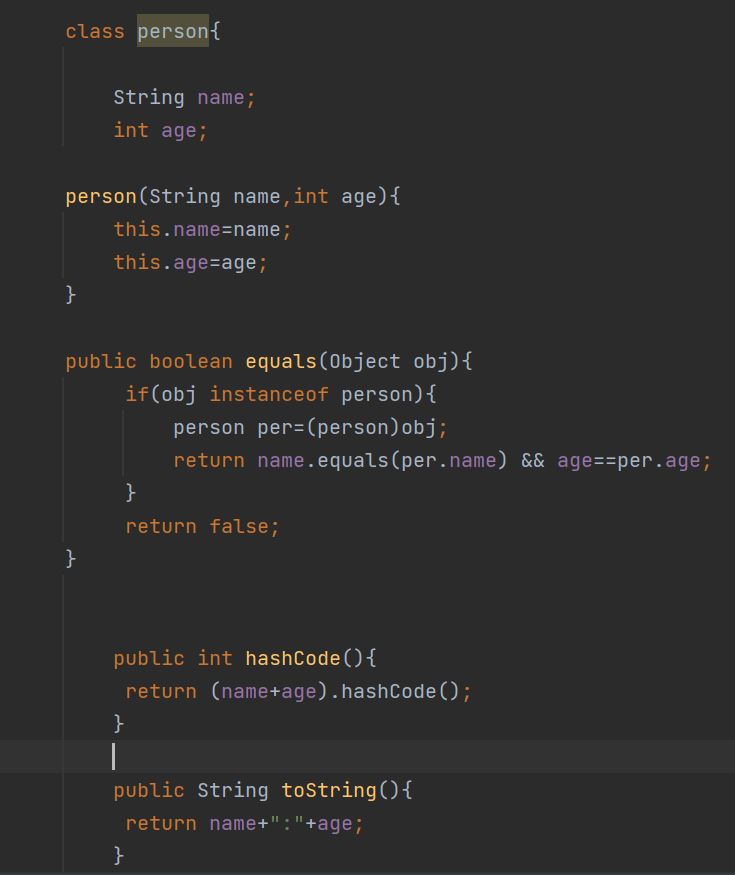
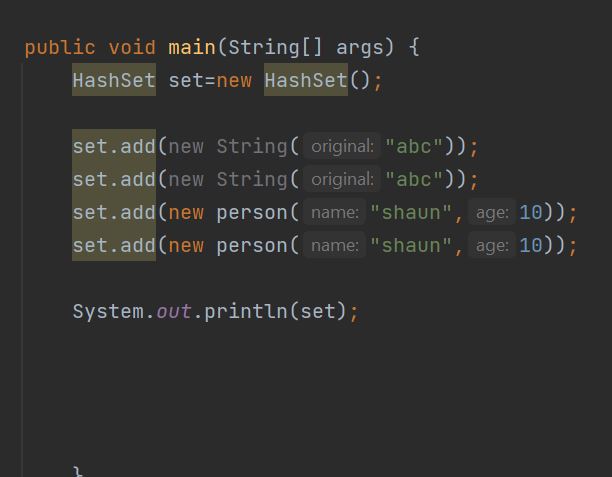
두번쨰 사진처럼만 하면 name 과 age가 같음에도 불구하고 다른것으로 인식하여 shaun,10을 두번 출력하게 된다.
※hashSet 기본적으로 중복허용이 안된다. 어떻게 중복을 체크할까? 그 이유는 add메서드 즉 새로운 요소를 추가하기전에 equals()와 hashCode()가 호출된다.
※ equals()(논리적비교) hashCode() 를 재정의 해야한다.
-
재정의한 equals 값이 ture면 hashCode() 결과도 같아야한다.
-
equals값이 flase면 hascode() 결과가 같아도 허용을 하지만 해싱을 사용하는 Hashtable HshMap과 같은 컬렉션 검색 속도가 떨어진다. 그래서 다른값을 반환하도록 해주자
★ equals 메서드를 호출한 결과가 true 면 hashCode()결과 도 같아야하지만 두객체의 해시코드가 같다고 해서 equals 메서드의 호출결과가 반드시 true이어야 하는 것은 아니다.
TreeSet
-
treeSet은 이진 검색 트리 라는 자료구조의 형태로 데이터를 저장하는 컬렉션 클래스이다.
-
set 의 특징을 그대로 가져온다. 중복허용 x, 저장순서 x
-
저장할때 자동으로 정렬 해준다. 떄문에 읽어올때 따로 정렬x
-
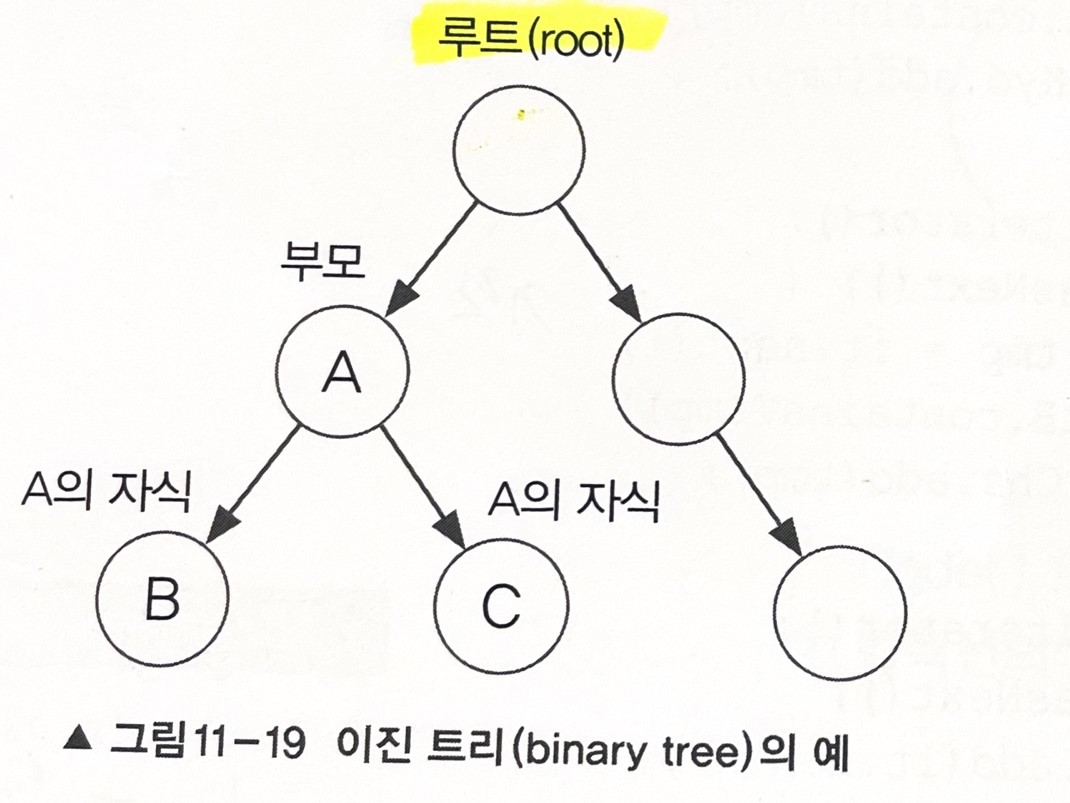
이진 트리 링크드리스트처럼 노드가 서로 연결된 구조로 각노드에 최대 2개의 노드를 연결할 수 있으며 루트 라고 불리는 하나의 노드에서 부터 시작해서 계속해서 확장해 나간다.
-
왼쪽에는 부모노드의 값보다 작은값의 자식노드, 오른쪽엔 큰값의 자식노드를 저장하는 이진트리이다.
-
TreeSet에 저장되는 객체가 Comparable(기본 정렬)을 구현하던가 아니면 TreeSet에게 Comparator(기본 정렬 외)를 제공해서 두 객체를 비교하는 방법을 알려줘야 한다.
-
첫번쨰 저장하는 값이 루트가 되며, 두번쨰 값은 루트부터 시작해 값의 크기를 비교하며 내려간다.
TREE
-
데이터를 순차적으로 저장X, 저장위치를 찾아서 저장해야한다.(비교를 하고 저장해야 하니까)
-
삭제하는 경우에는 트리의 일부를 재구성해야하므로 링크드 리스트보다 데이터의 추가/삭제 가 더걸린다.
-
대신 배열이나 링크드 리스트에 비해 검색과 정렬 기능은 뛰어나다.
-
arryList와 linkedList를 비교할때 arryList와 조건이 비슷하다.
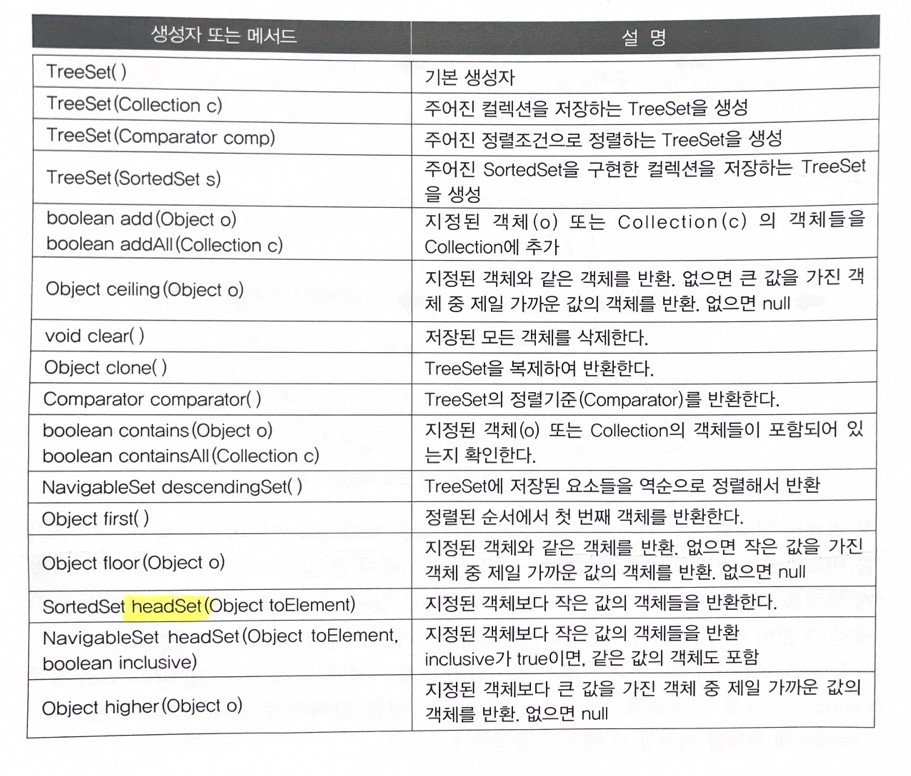
TreeSet 메서드 표
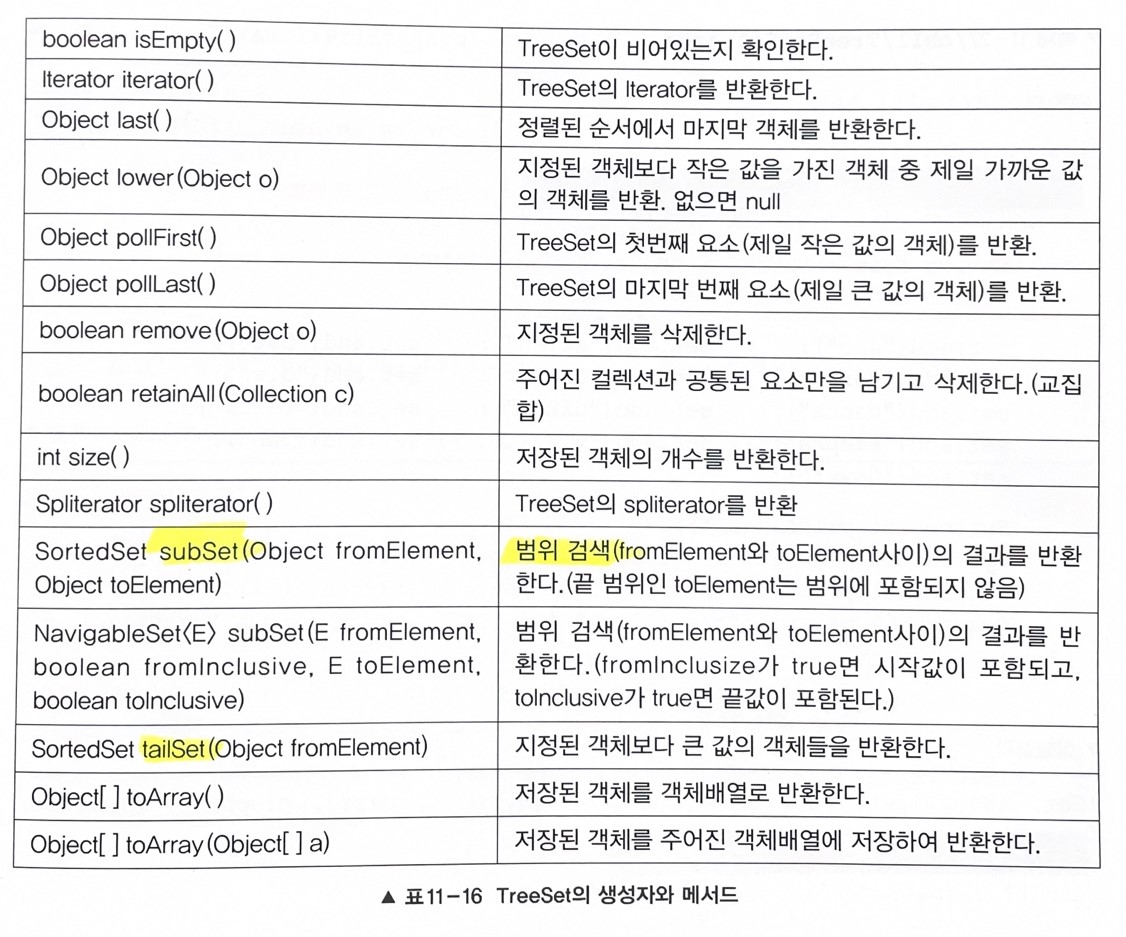
연습 - subset() 범위검색
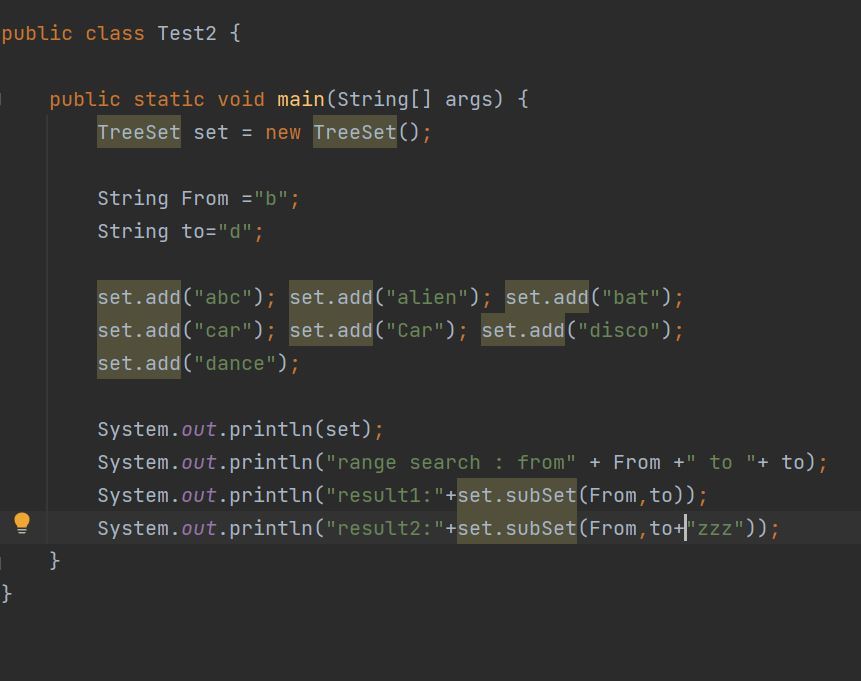
-
subSet()을 이용해 범위검색을 할떄는 시작범위는 포함되지만 끝 범위(to) 는 포함되지 않는다.
-
result1 은 b~c로 시작하는 단어까지만 검색한다. b~d까지 하고싶으면 to에 "zzz"와 같은 문자열을 붙이면 된다. dzzz 다음에 오는 단어는 없을 것이기 떄문에 d로시작하는 모든 단어들이 포함될 것이다.
-
대문자가 소문자보다 더 우선시 되기때문에 대문자 또는 소문자로 통일하는게 좋다.
※ 반드시 대소문자가 섞여있어야하면 Comparator을 이용해 다른방식으로 정렬해준다.
문자열 정렬순서
코드값이 기준이 되므로, 오름차순 정렬의 경우 코드값의 크기가 작은 순서에서 큰순서, 즉 공백,숫자,대문자,소문자 순으로 정렬되고 내림차순은 그 반대가 된다.
