
JPA+Querydsl
- 이제 querydsl 과 JPA를 적용 시켜보자
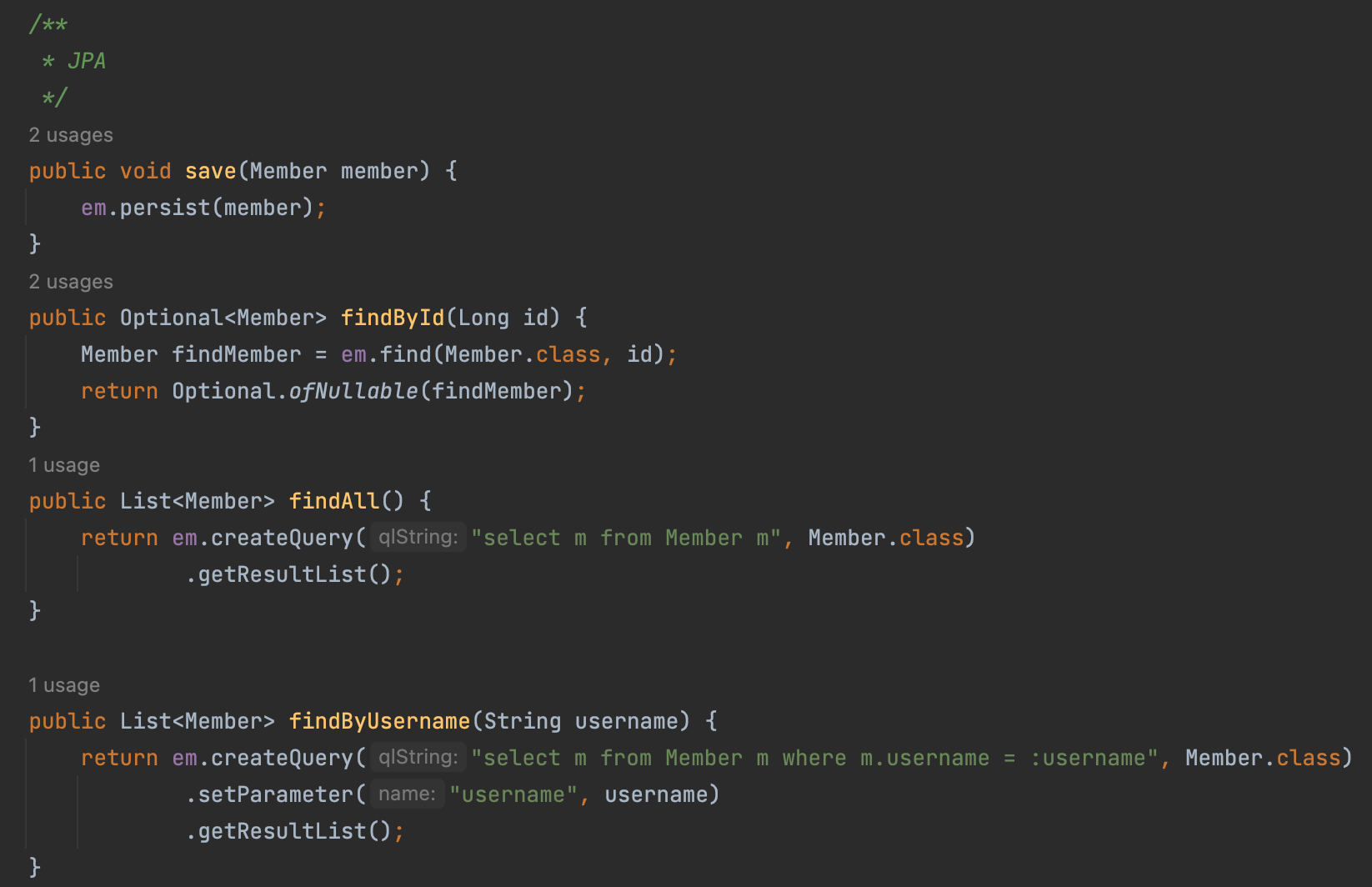
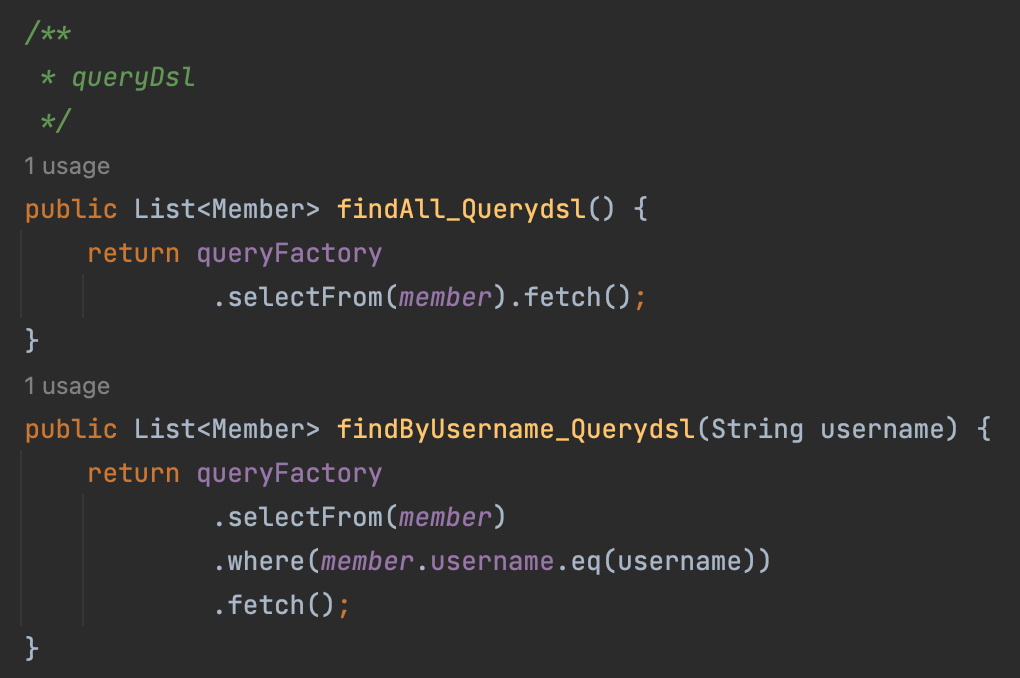
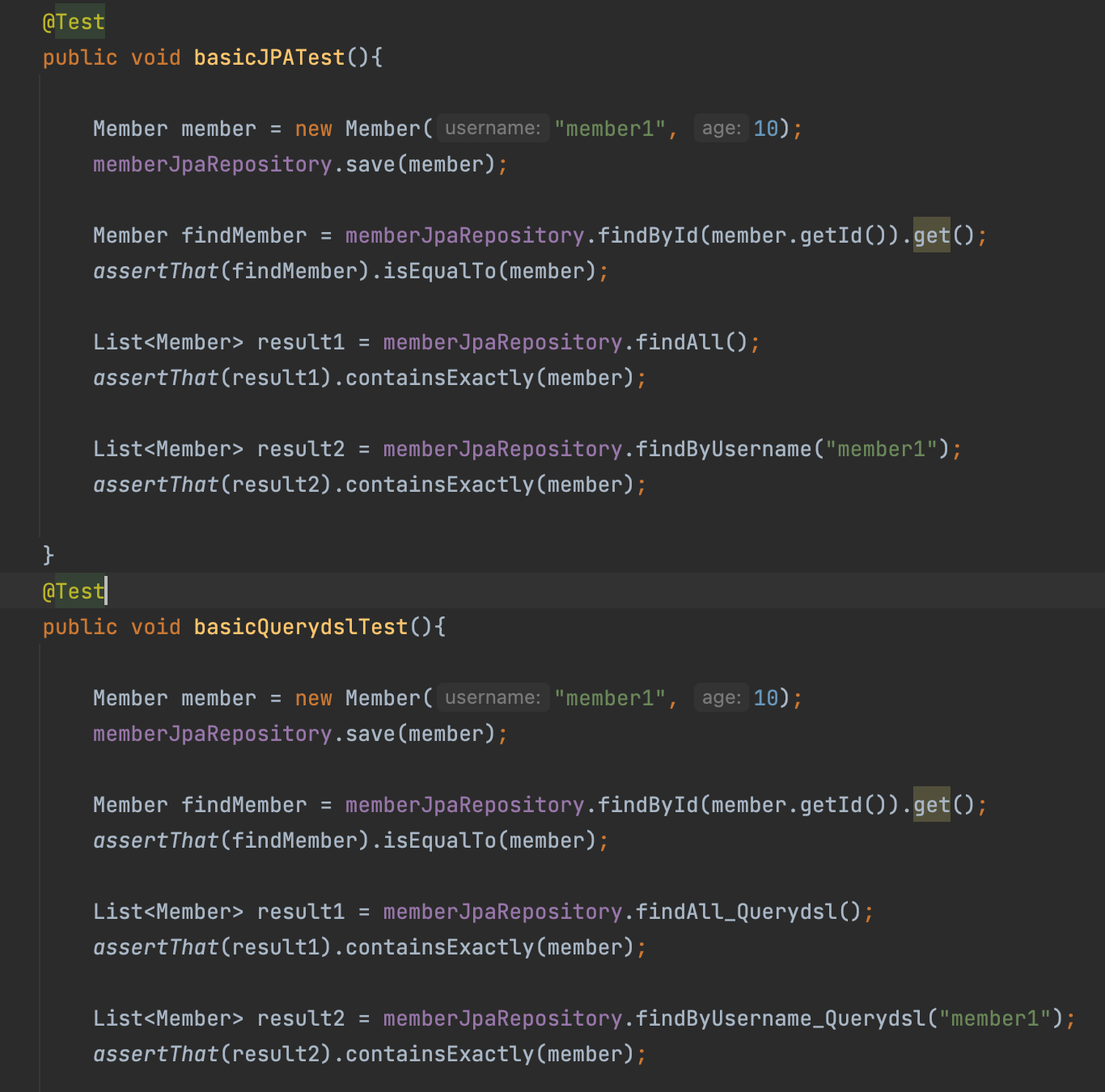
- pure jpa , querydsl 테스트 , 어렵지 않다
동적 쿼리-BooleanBuilder 활용
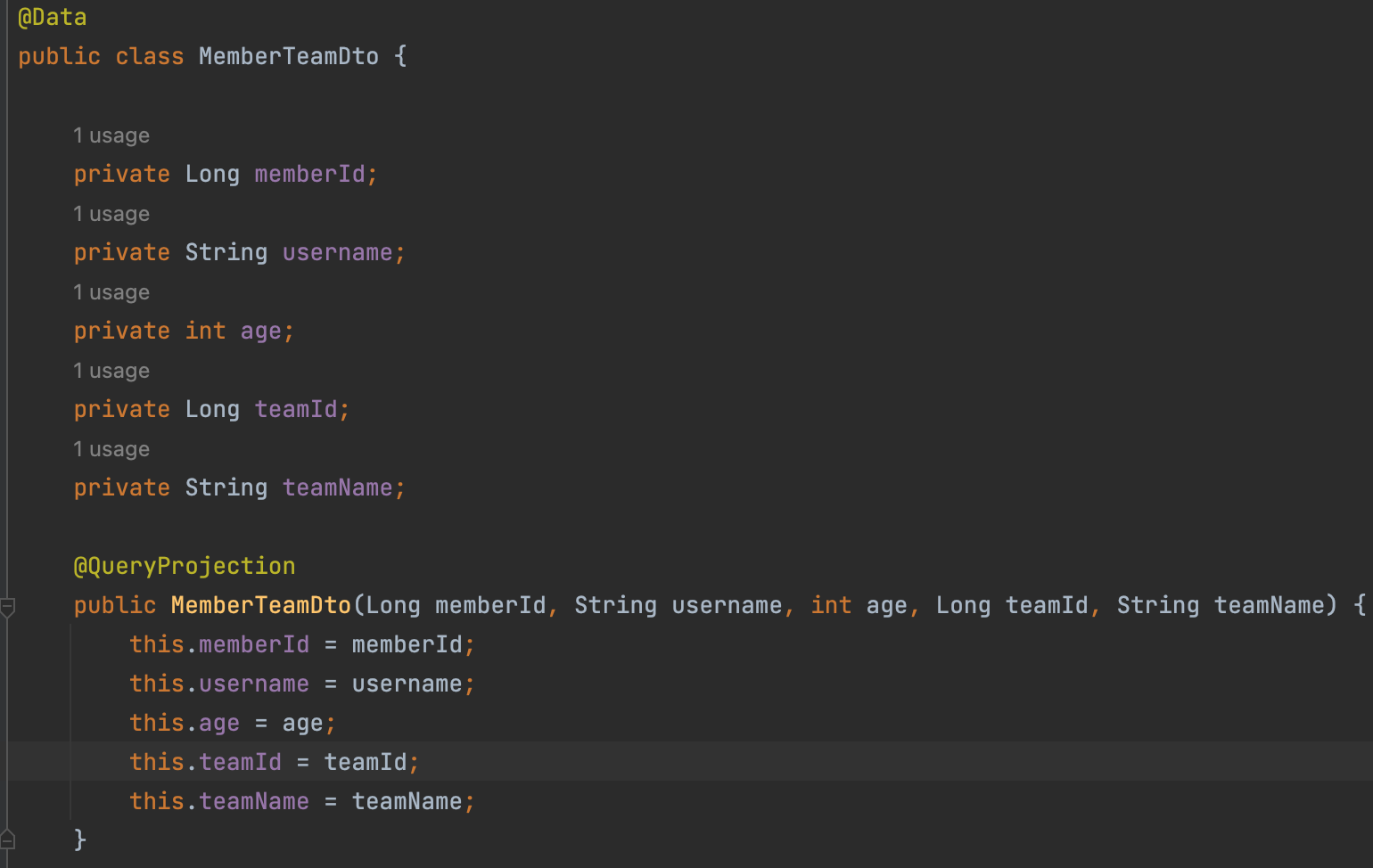
- 조회용 dto -> @QueryProjection 사용
-> dto 가 querydsl 의존 하는게 싫으면 기존 방법 Projection.bean(), fields(), constructor() 을 사용
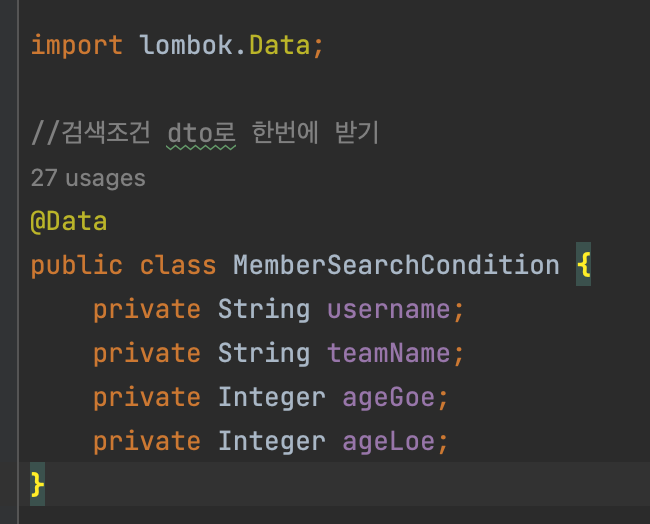
- 검색 조건 한번에 받을 Dto 생성
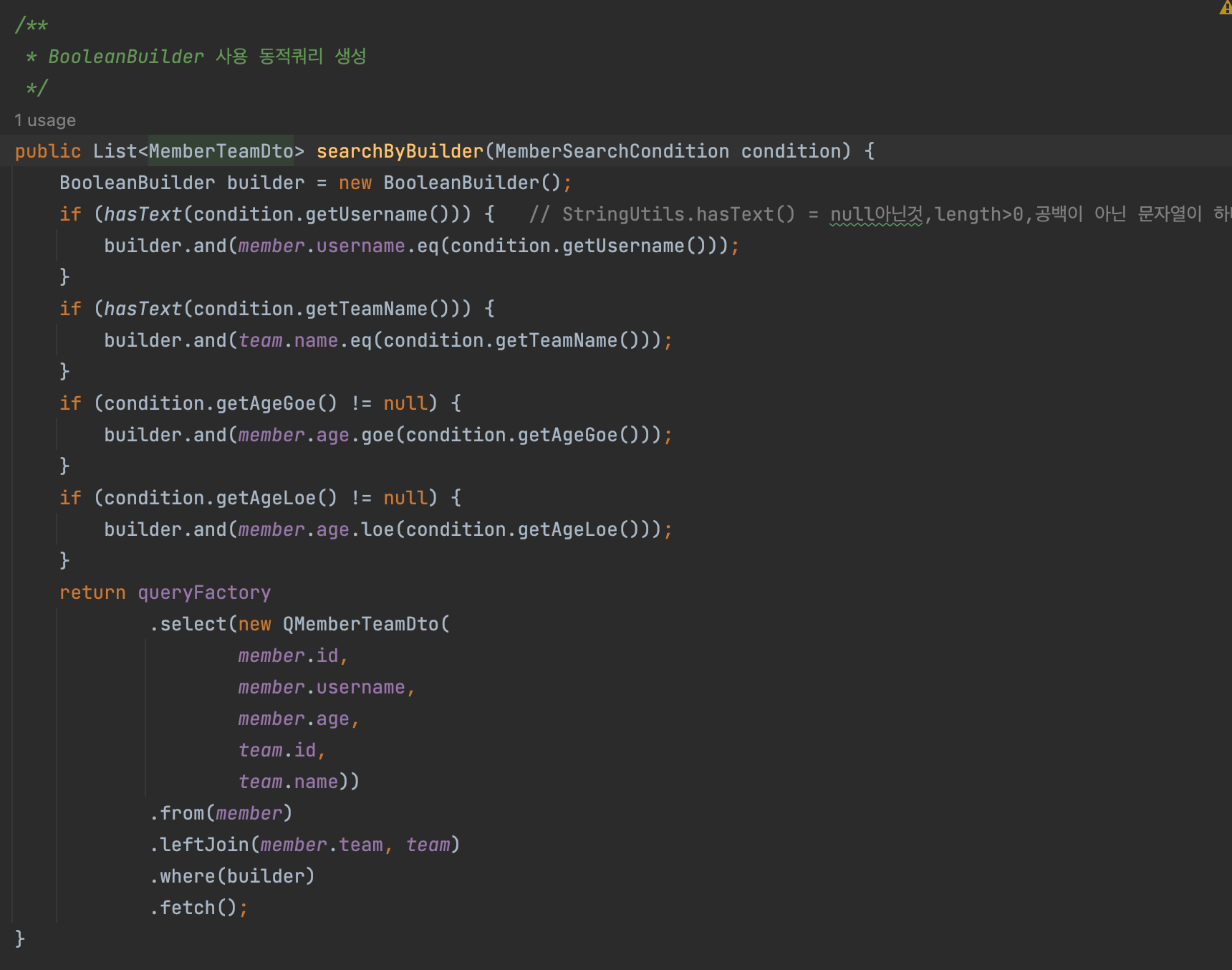
- Booleanbuilder를 사용해 상황에따라 다른 동작을 하는 동적 쿼리 생성
-
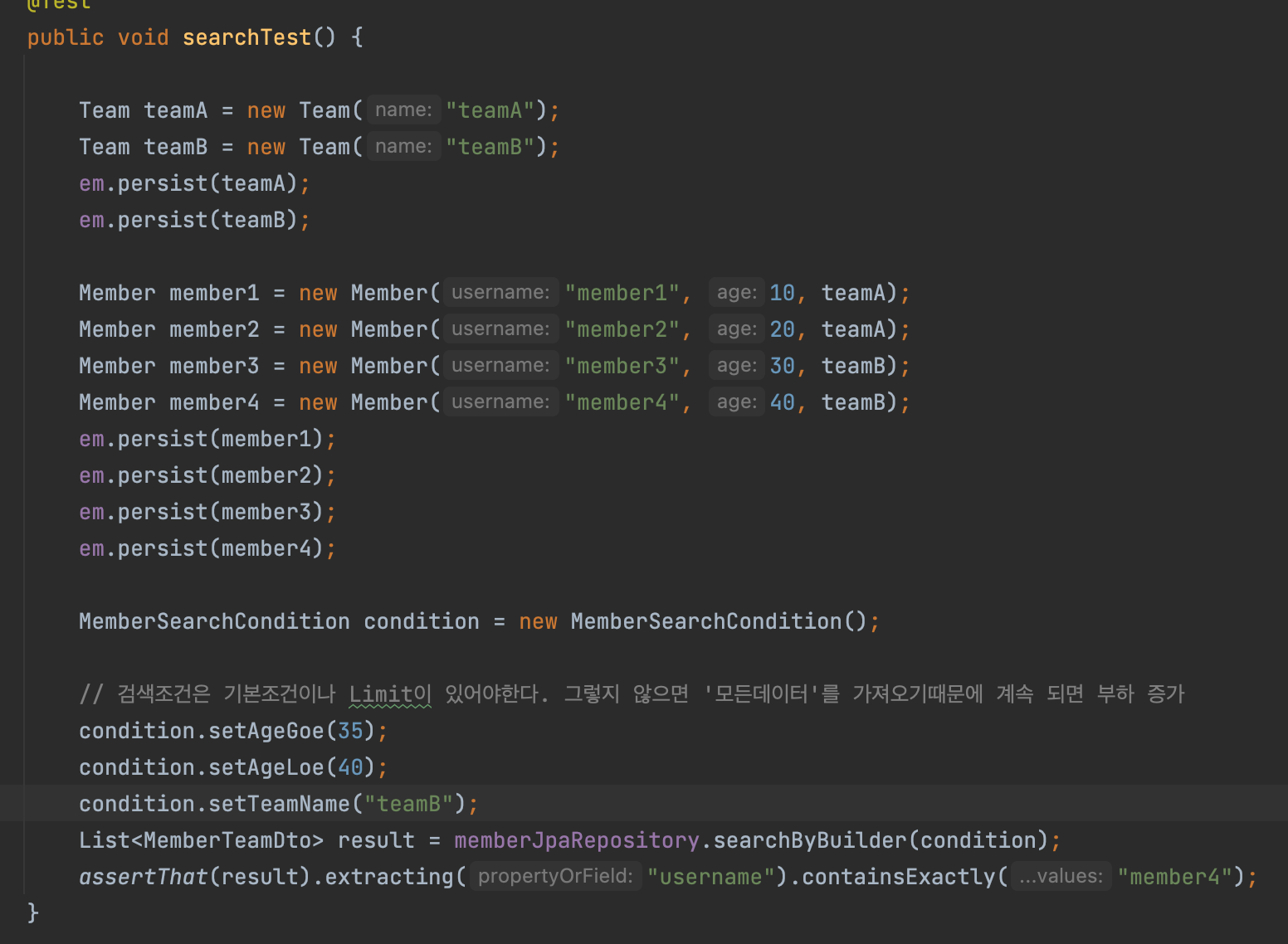
pureJPA + querydsl testcode
-
검색 조건을 설정하지 않으면 데이터를 다 가져오기 때문에 검색할 데이터가 많으면 limit을 설정해 주는게 좋다.
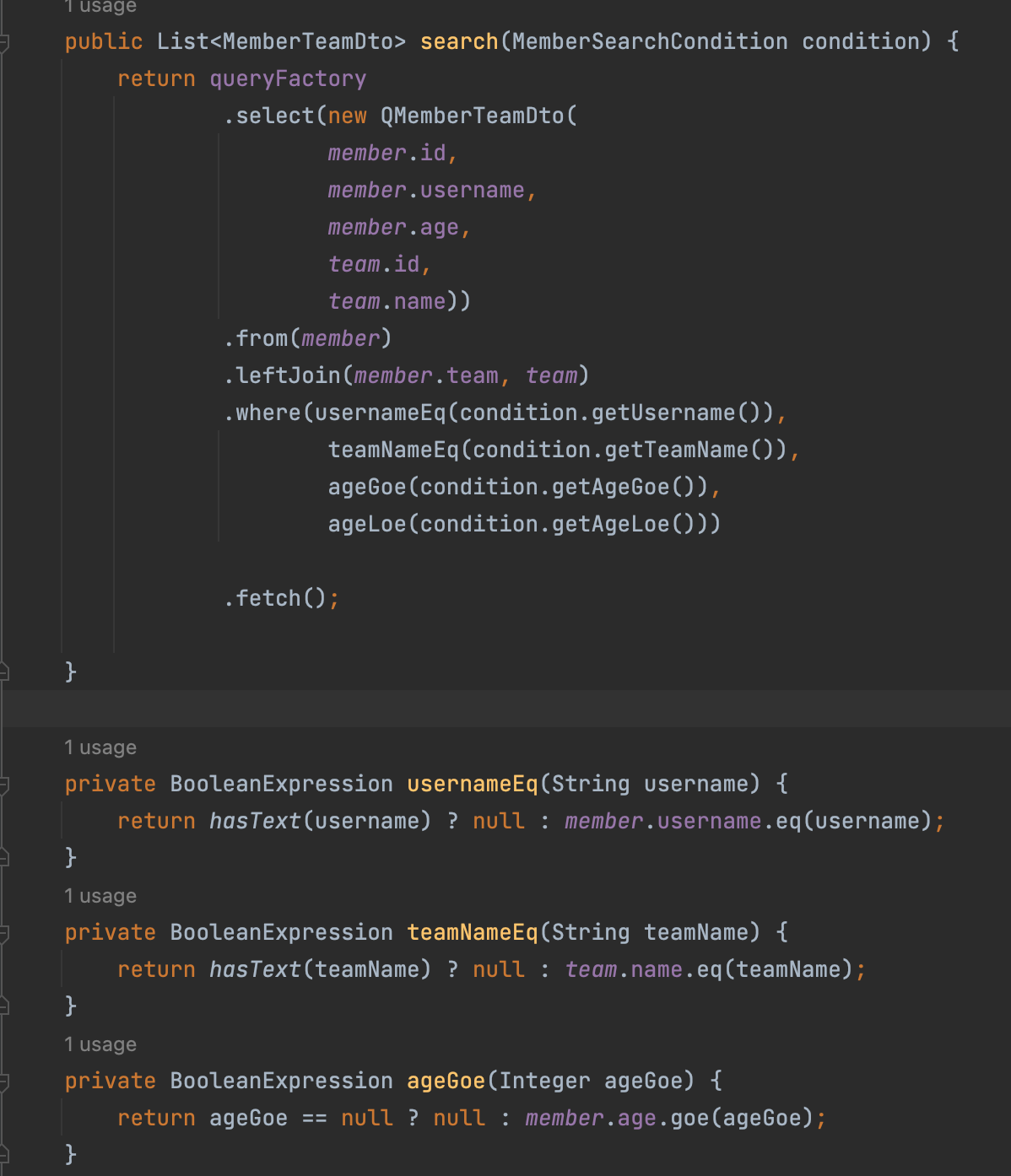
동적쿼리 BooleanBuilder 최적화 (where절 사용)
-
코드도 깔금해지고 가독성도 훨씬 좋아졌다.
-
where 절에 null 이 나오면 무시함
contorller 생성
-
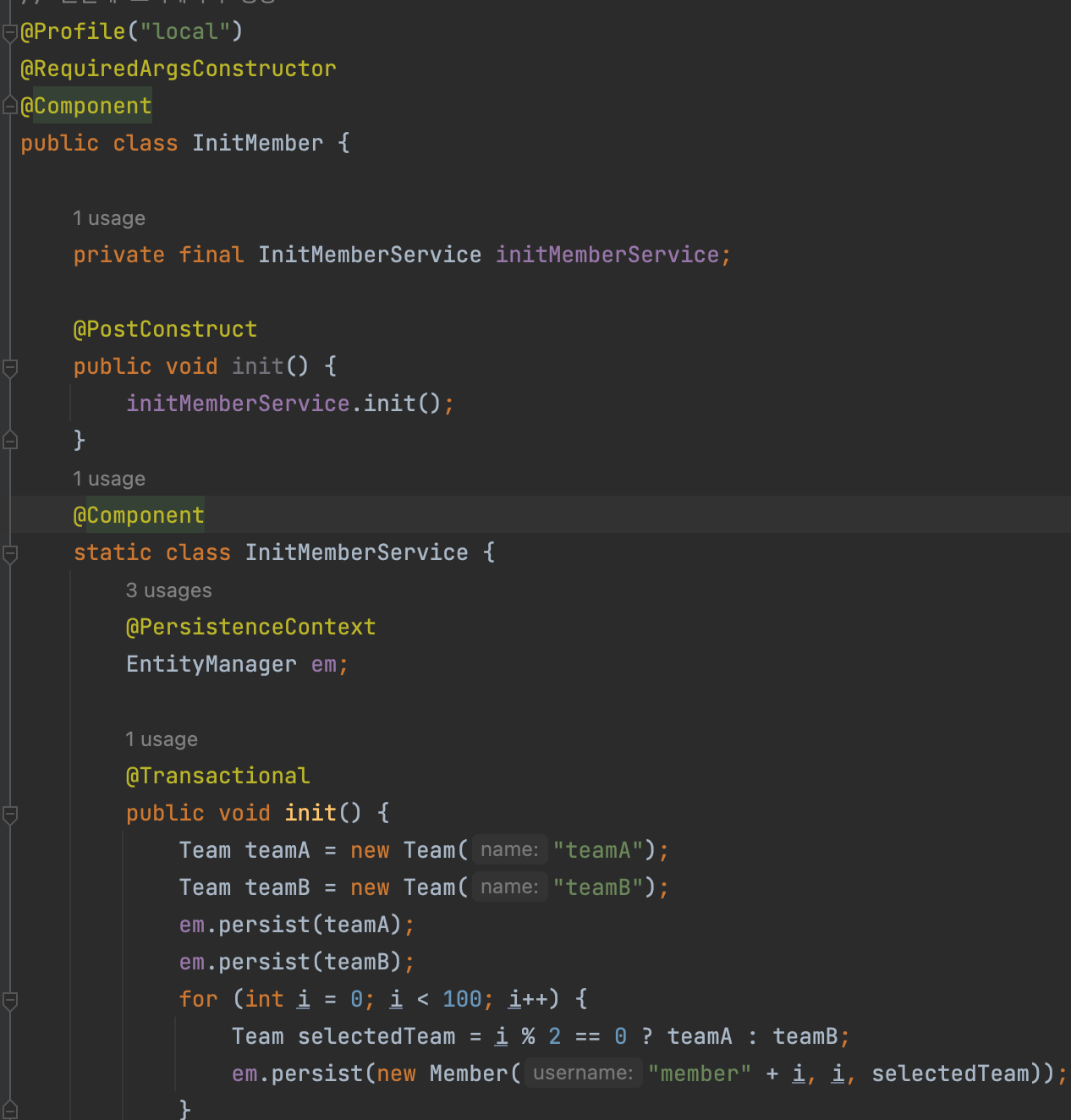
초기화 데이터 설정
-
@Profile을 사용해 main소스코드와 test소스코드를 나눴다.
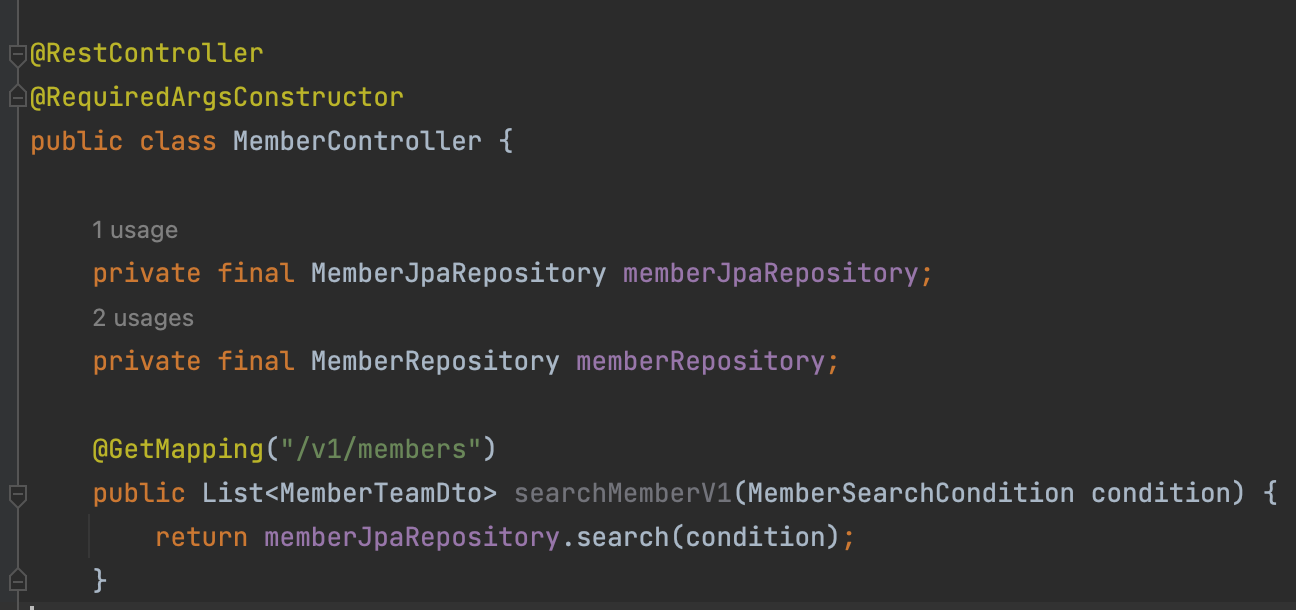
SpringDataJpa +querydsl
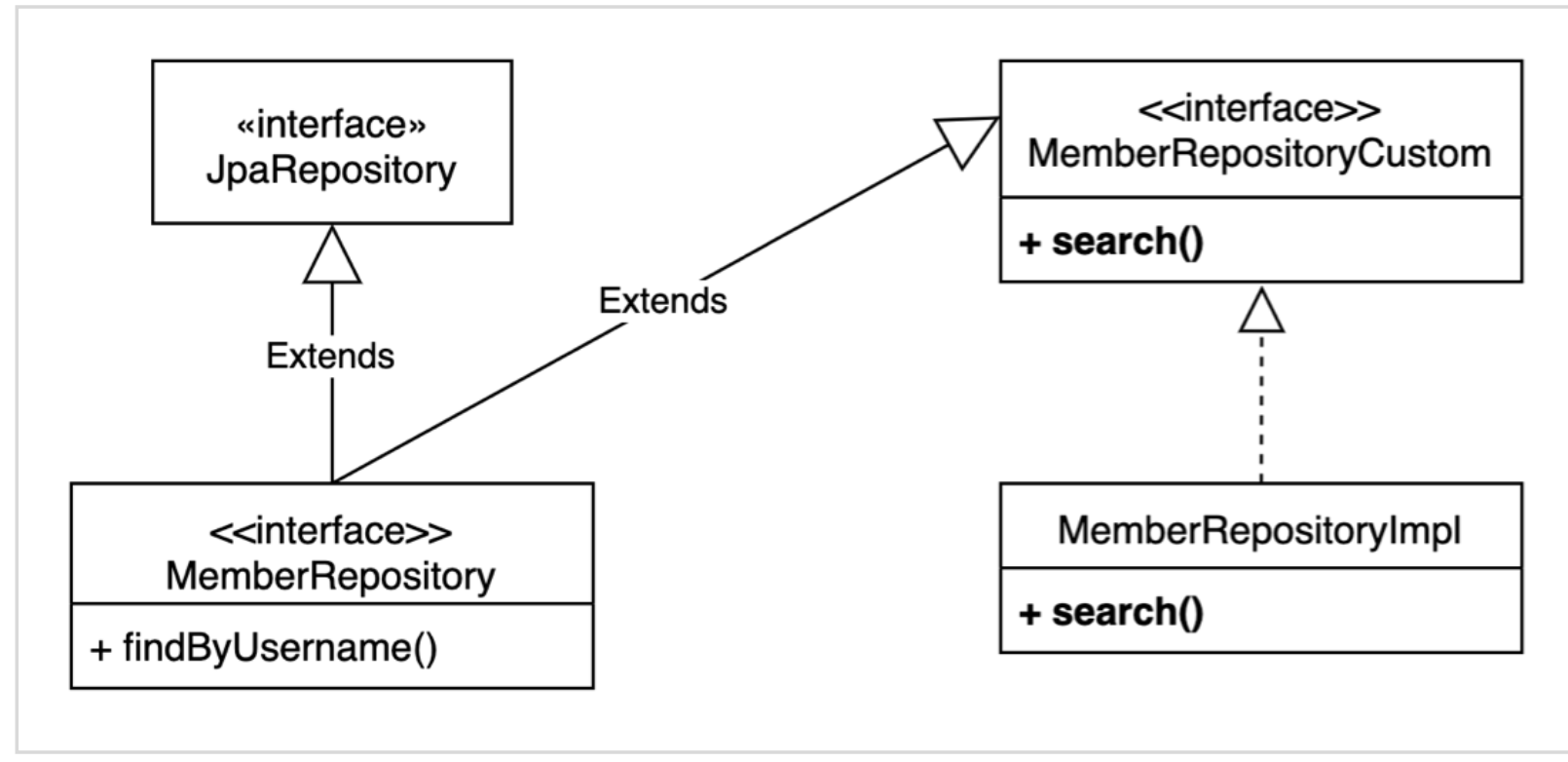
- 사용자 정의 repository 생성
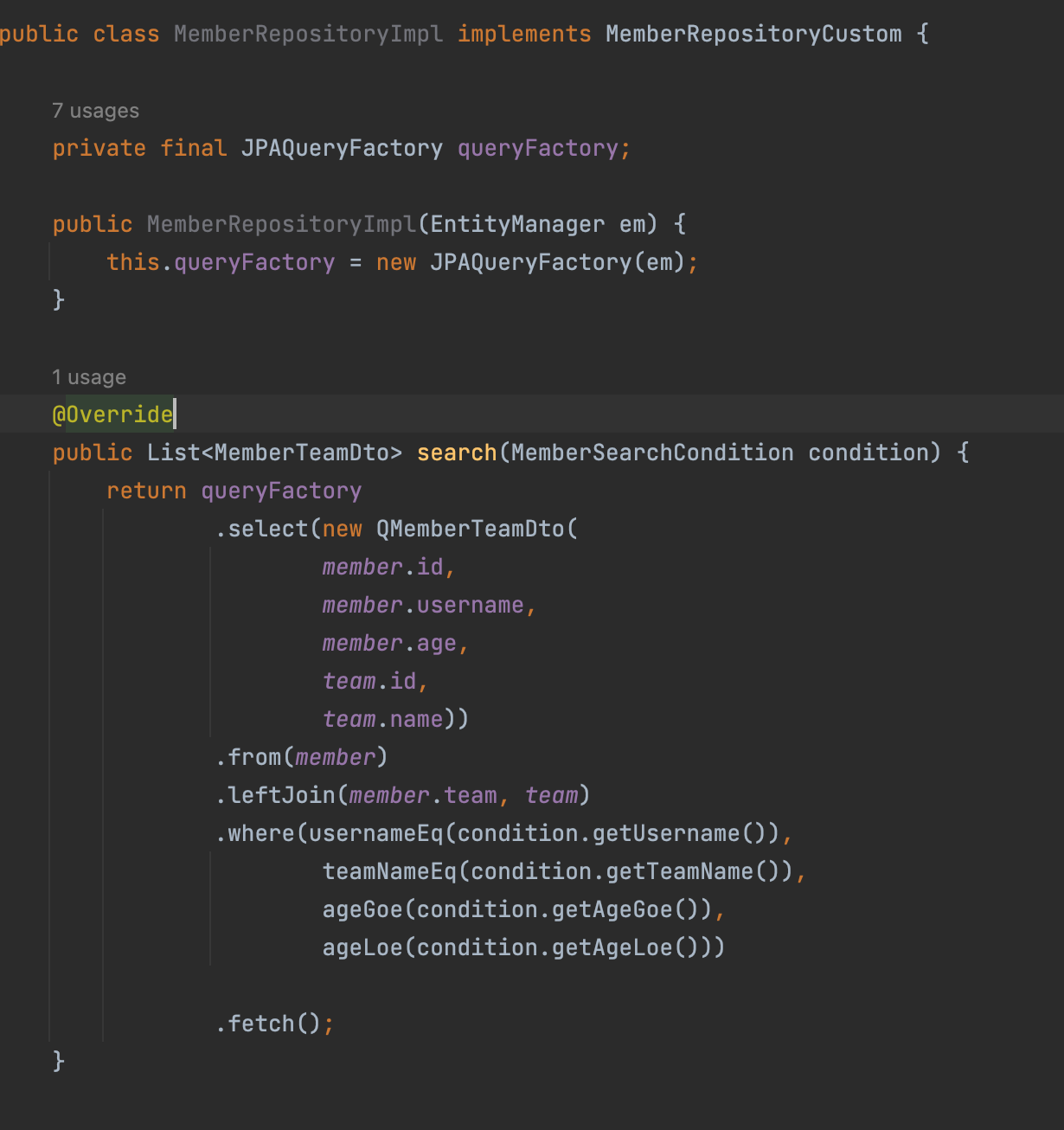
-
하나의 커스텀 repo - impl 구성뒤 그 repo를 기존 JPA인터페이스와 함께 상속받는다 (인터페이스는 여러개 상속가능)
-
BooleanBuilder -where 절 사용으로 구현
-
즉 결과적으로 SpringDataJPA 의 기본쿼리 crud 자동 구현 기능과 커스텀 repo(querydsl)을 통해 복잡한 쿼리를 동시에 가져가는 방법!
페이징처리 V1
- 커스텀 repo에 페이징처리 추가
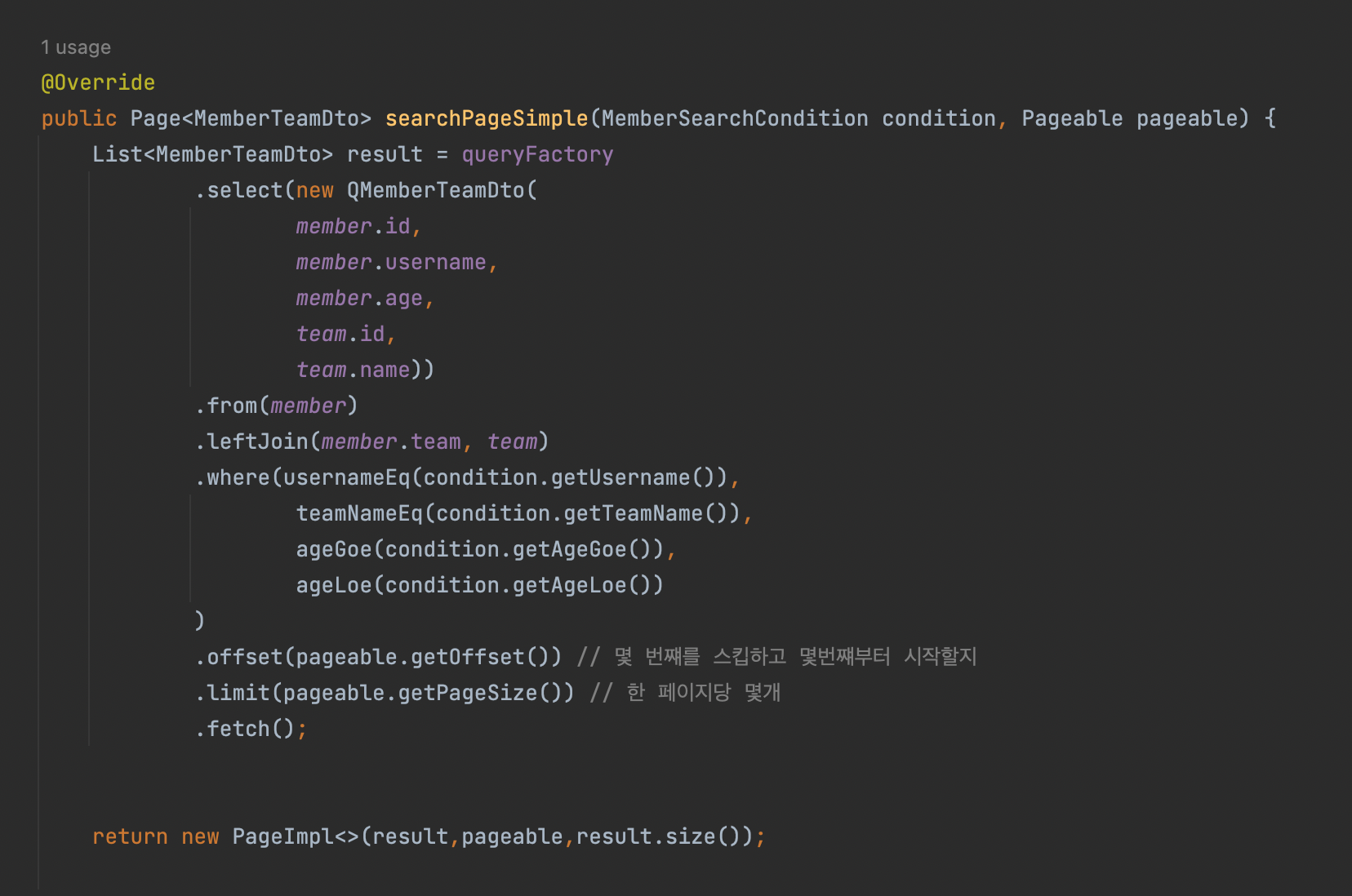
- new PageImpl() 사용, - 간단한 limit - offset을 이용한 페이징 처리이다.
-
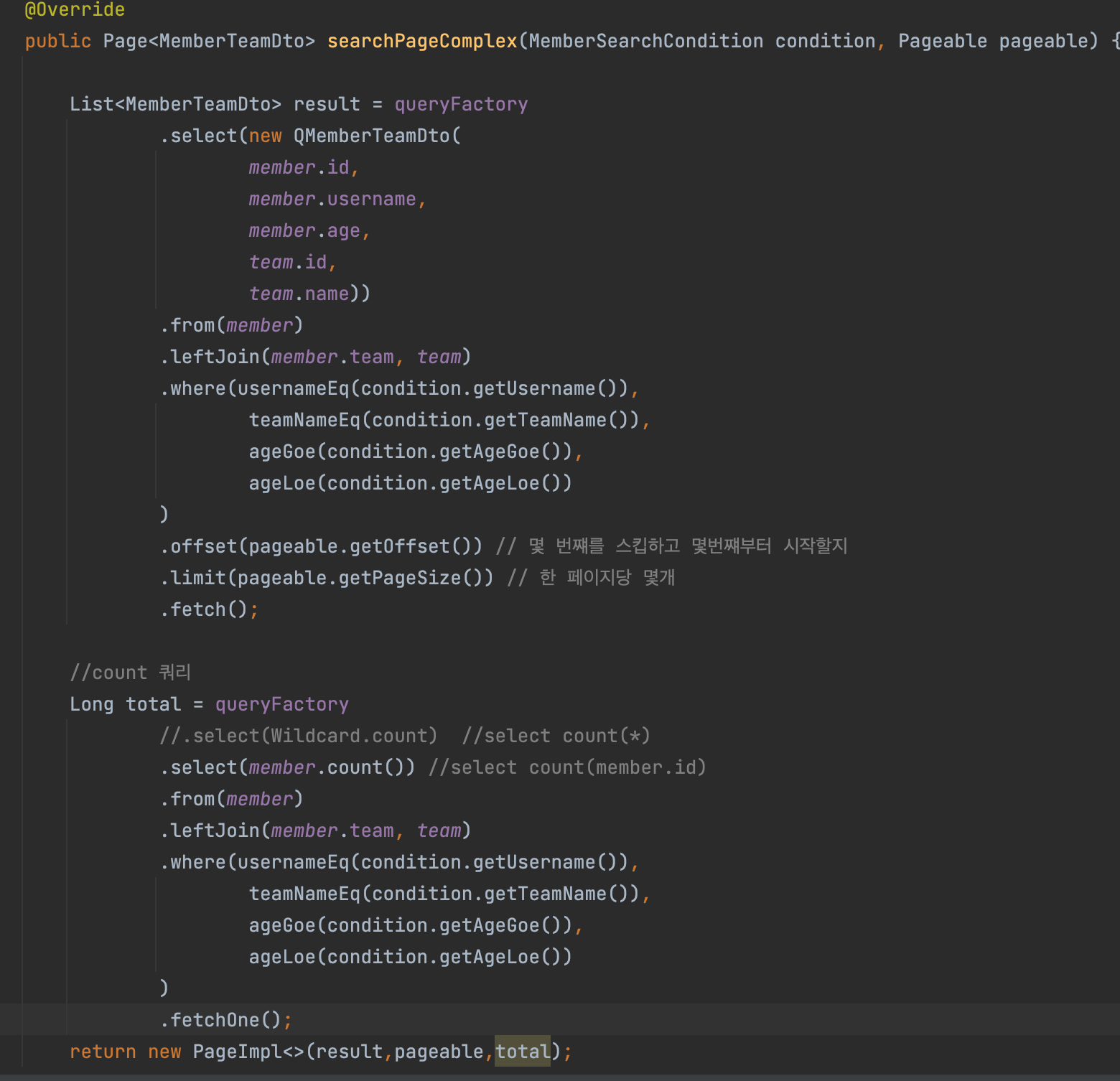
동적쿼리를 count쿼리와 나눴다.
-
나눈이유에 대해 간략히 설명하면
->count 쿼리를 join 없이 더 쉽게 불러올수 있는데 자동으로 나가는거라 성능 떨어짐
->count쿼리는 조인문이 필요하지 않는 경우에도 자동으로 나가는 방식이라 최적화를 하려면 따로 분리해줘야함 = 성능 최적화
페이징V2 -count쿼리 최적화
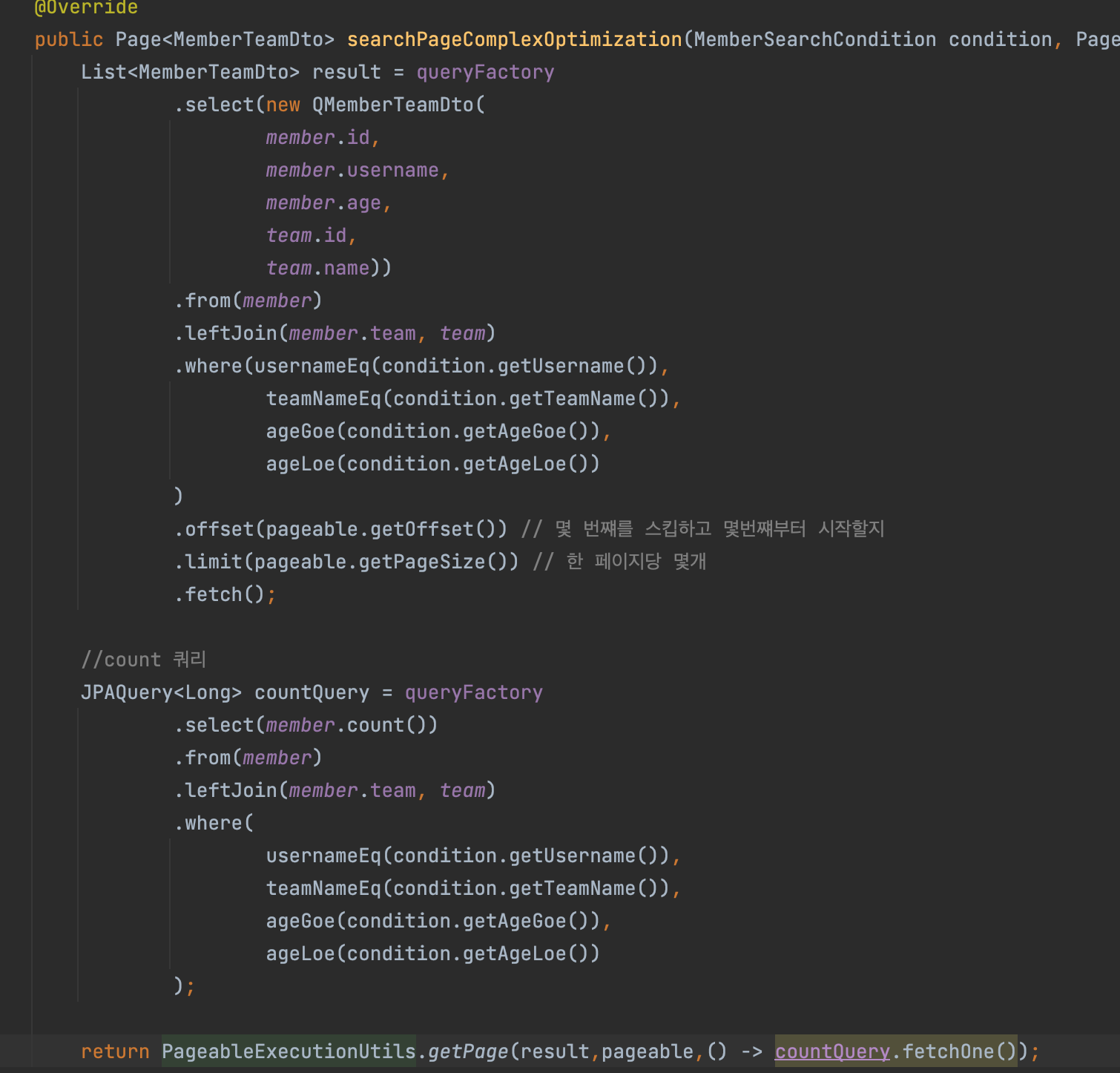
- PageableExecutionUtils.getPage
->알아서 count쿼리가 필요 없으면 만들지 않음
->페이지 시작이면서 컨텐츠 사이즈가 페이지 사이즈보다 작을 때
->마지막 페이지 일 때 (offset + 컨텐츠 사이즈를 더해서 전체 사이즈 구함)
현재 조회된 페이지의 contents 개수가 pageable.getPageSize()보다 작은 경우
-> 현재 페이지 이전 페이지 수 * 페이지 최대 사이즈 + 현재 페이지의 contents 개수 의 연산 결과가 곧 전체 contents의 개수이기 때문에 굳이 count쿼리를 조회하지 않아도 전체 count를 알 수 있다.
이러한 방법을 이용한 페이징은 count 쿼리에 불필요한 join을 제거할 수 있어 성능을 최적화 할 수 있다.
querydsl Repository support
- 원래 QuerydslRepositorySupport 이란게 있지만 Querydsl 4.x에 나온 JPAQueryFactory로 시작할 수 없음, select로 시작할 수 없음 (from으로 시작해야함) QueryFactory 를 제공하지 않음, 스프링 데이터 Sort 기능이 정상 동작하지 않음, 등등 단점이 많다.
-> Custom querydsl Repository Support 를 만들어보자
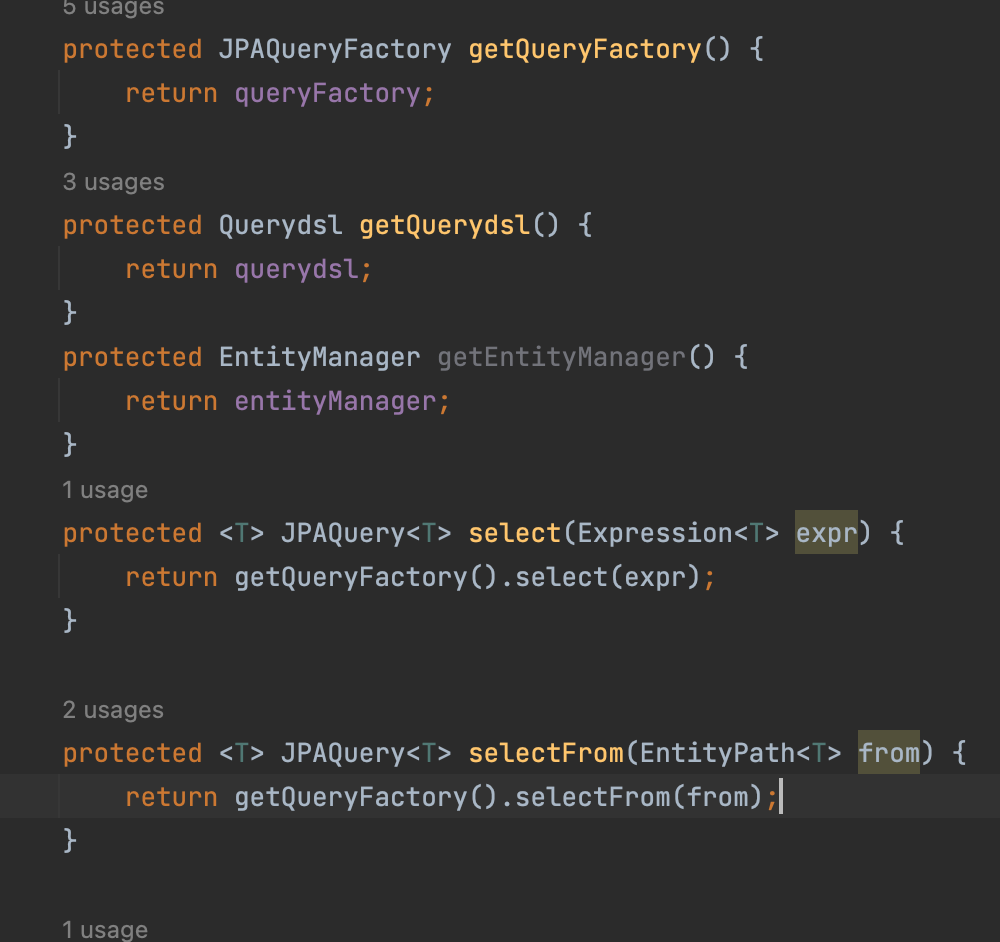
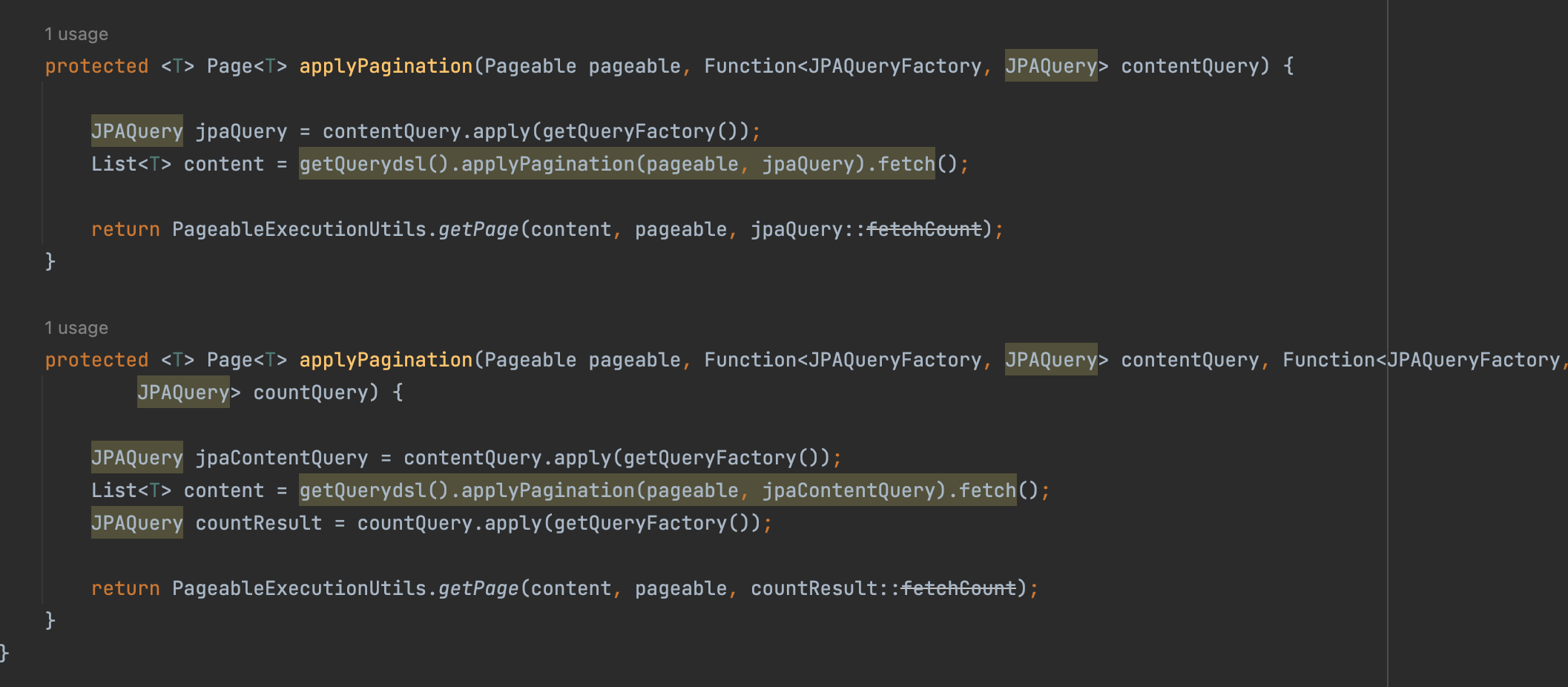
-> 종합해서 말하자면 모든 querydsl 커스텀 repo 에서 공통으로 사용한 부분을 모아놨다고 봐도 좋다.
-> 이렇게 함으로써 querydsl custom repo에서 쿼리를 짤떄 훨씬 깔끔하게 만들수 있다.
