SpringBatch는 언제 사용할까?
- 대용량의 비즈니스 데이터를 복잡한 작업으로 처리해야하는 경우
- 특정한 시점에 스케쥴러를 통해 자동화된 작업이 필요한 경우 (ex. 푸시알림, 월 별 리포트)
- 대용량 데이터 의 포맷을 변경, 유효성 검사 등의 작업을 트랜잭션 안에서 처리 후 기록해야하는 경우
- Spring Batch는 로깅/추적, 트랜잭션 관리, 작업 처리 통계, 작업 재시작, 건너뛰기, 리소스 관리 등 대용량 레코드 처리 에필 수적인 재사용 가능한 기능을 제공한다. 또한 최적화 및 파티셔닝 기술을 통해 대용량 및 고성능 일괄 작업을 가능하게 하는 고급 기술 서비스 및 기능을 제공한다.
배치 애플리케이션은 조건
-
대용량 데이터 : 대량의 데이터를 가져오거나, 전달하거나, 계산하는 등의 처리를 할 수 있어야 한다.
-
자동화 : 심각한 문제 해결을 제외하고는 사용자 개입 없이 실행되어야 한다.
-
견고성 : 잘못된 데이터를 충돌/중단 없이 처리할 수 있어야 한다.
-
신뢰성 : 무엇이 잘못되었는지를 추적할 수 있어야 한다. (로깅, 알림)
-
성능 : 지정한 시간 안에 처리를 완료하거나 동시에 실행되는 다른 애플리케이션을 방해하지 않도록 수행되어야 합니다.
Quartz VS SpringBatch
-
Quartz는 스케줄러의 역할이지, Batch와 같이 대용량 데이터 배치 처리에 대한 기능을 지원하지 않는다.
-
반대로 Batch 역시 Quartz의 다양한 스케줄 기능을 지원하지 않아서 보통은 Quartz + Batch를 조합해서 사용한다.
SpringBatch
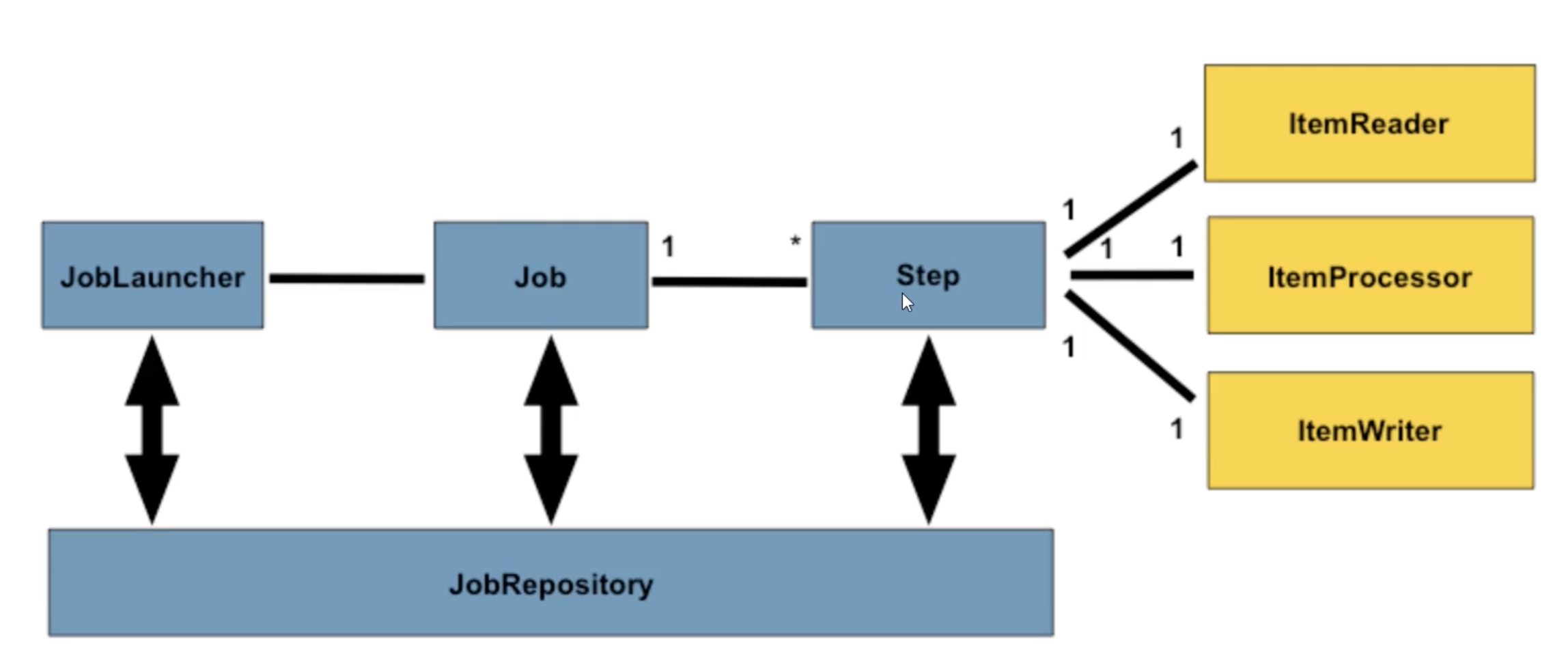
- jobRepository : 배치가 수행될때 수행되는 메타데이터 관리
- Job : 배치단위
- Step :job의 세부적인 내용
- job하나에 여러개의 step이 존재할수 있다.
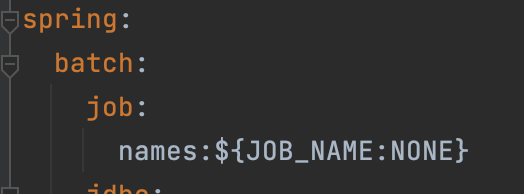
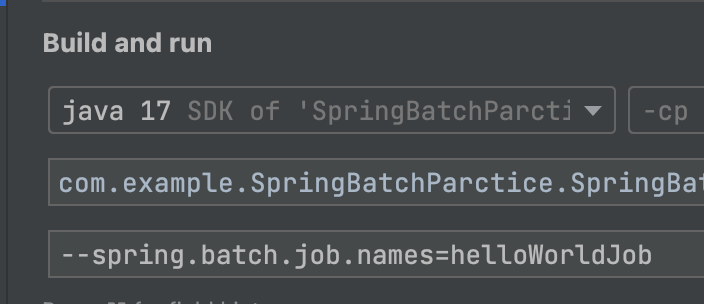
-
YMl 에서 설정한 batch-names 를 파라미터로 넘겨줘야 job이 실행됀다.
-
파라미터로 job이름을 넘겨주면 그 job이 실행 된다.
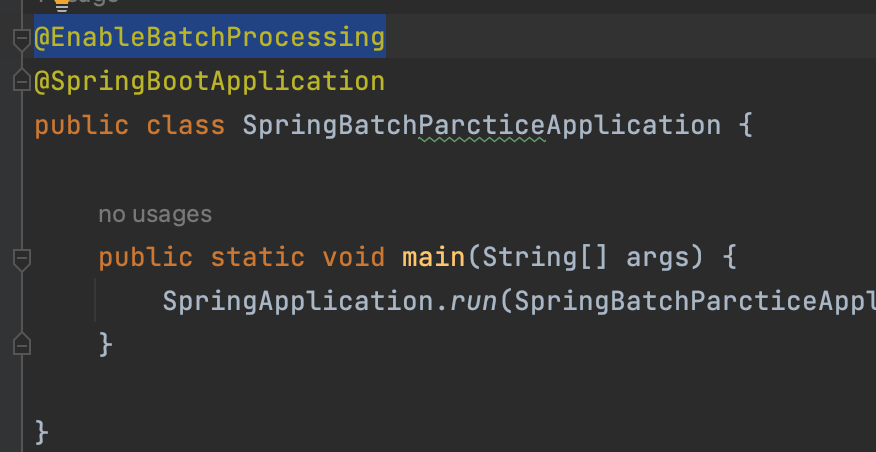
- 배치를 사용하기위해서는 @EnableBatchProcessing 애노테이션 필요함
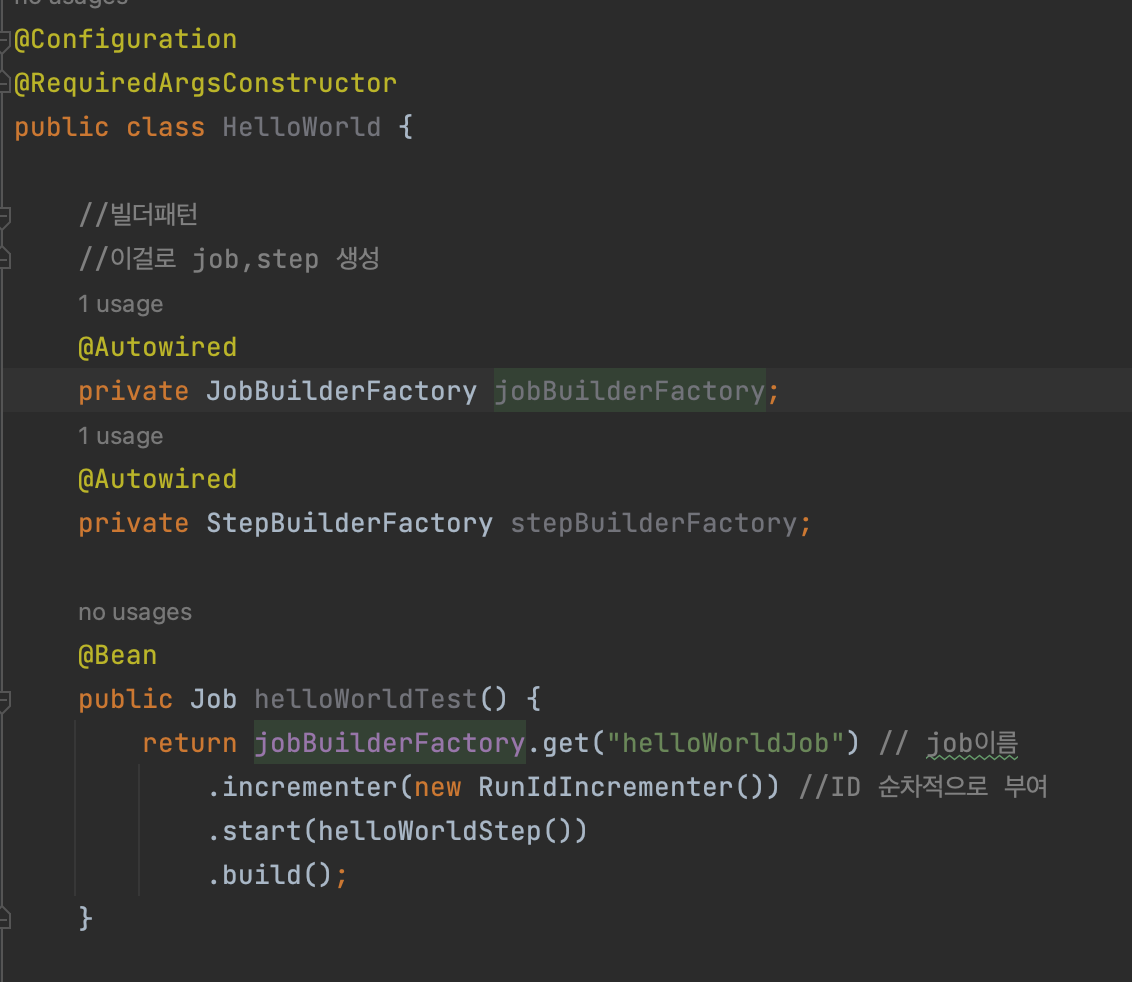
-
JobBuilderFactory, stepBuilderFactory 를 통해 job과 step을 만들어준다. (Builder 패턴 사용)
-
factory.get(name) 에서 Name 부분은 해당 step, job의 이름을 뜻한다. 실행시킬떄 파라미터로 job이름을 보낼때 사용
-
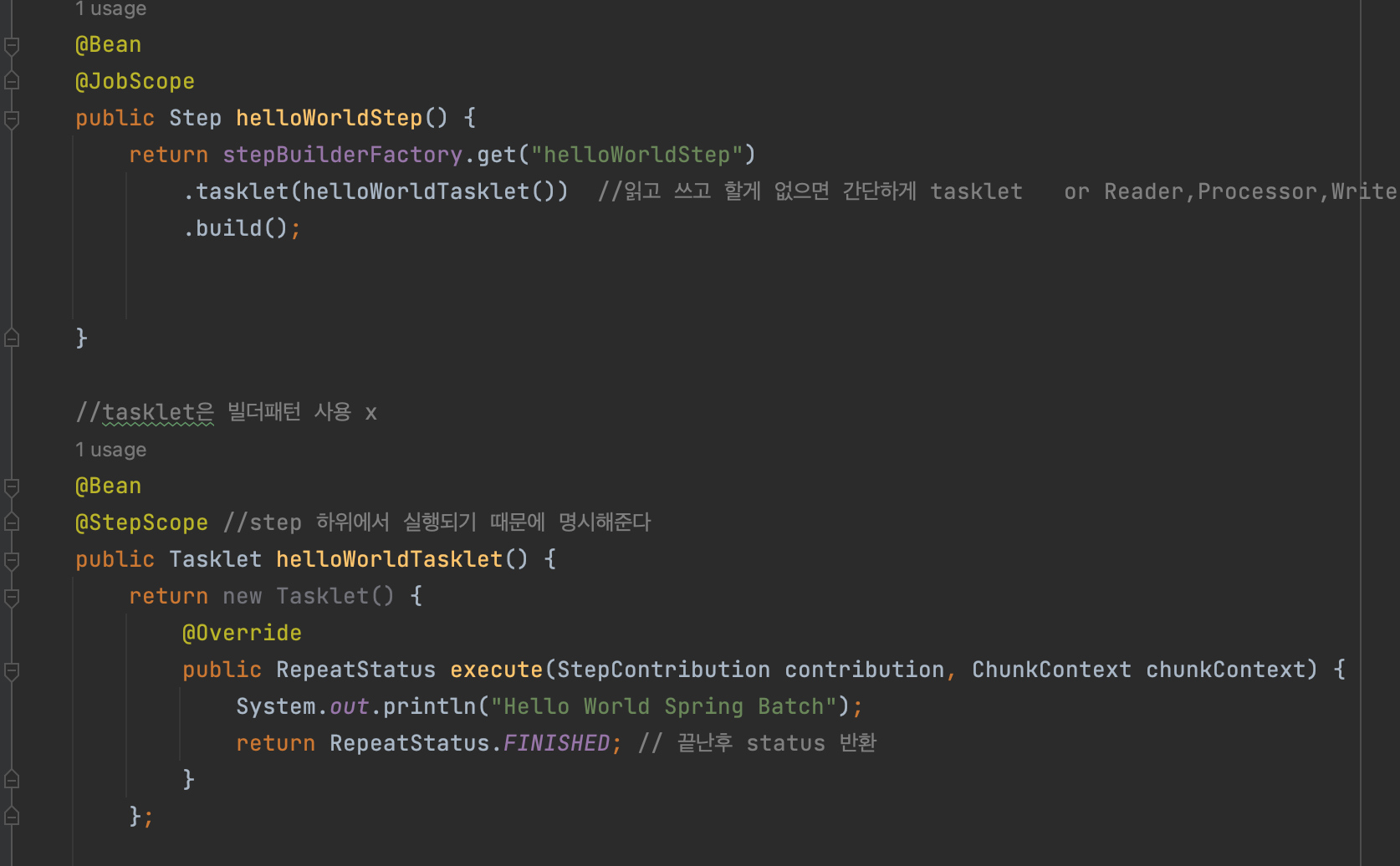
step 부분에서 읽고 쓰고 할게 없으면 간단하게 taskLet으로 가능
-
taskLet은 빌더패턴 사용 x
파일이름 파라미터로 전달 및 검증

- springBatch에서는 검증시 taskLet까지 가지않고 job에서 검증가능(validate)
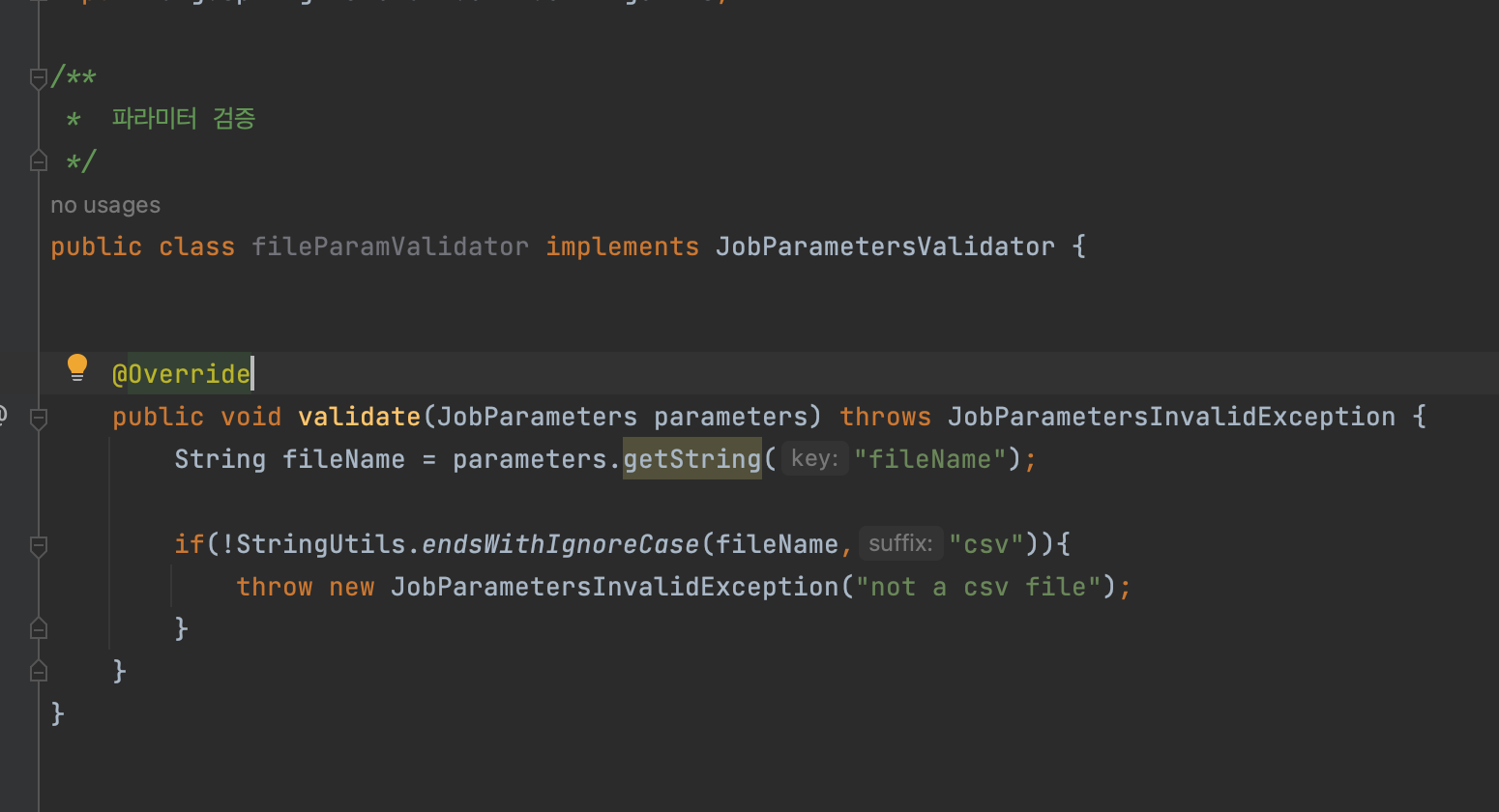
- job에서 사용할 검증기를 따로 만들어준다.
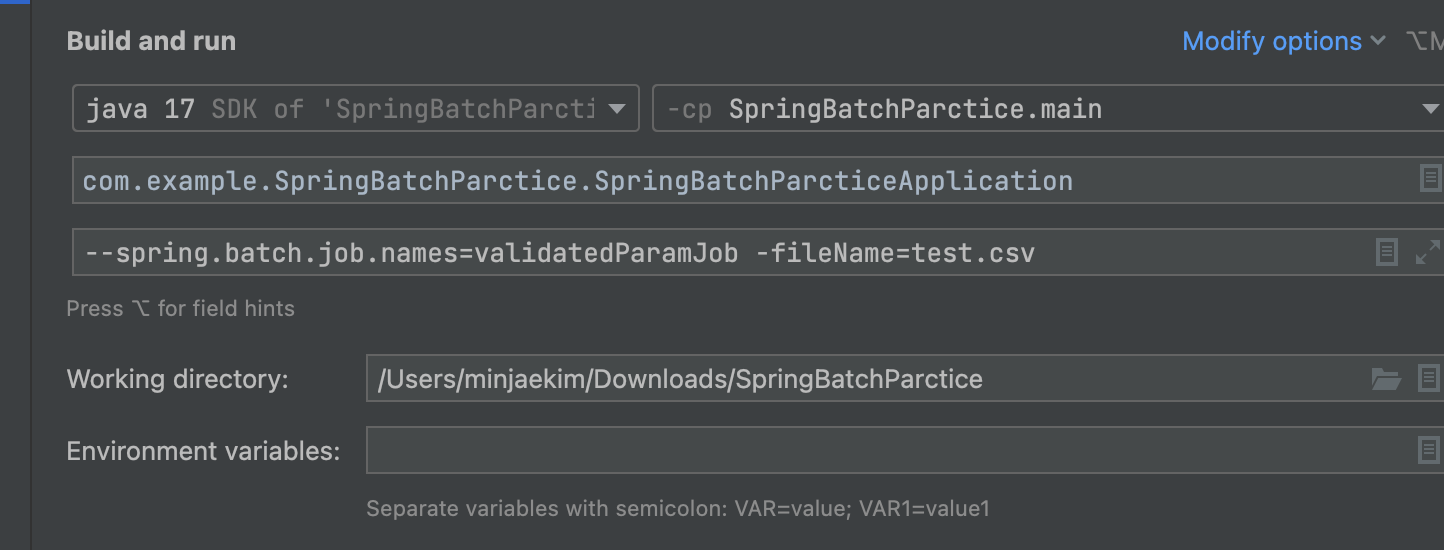
- 파라미터로 파일이름:test.csv 를 넣어주면서 검증job을 시작해준다.
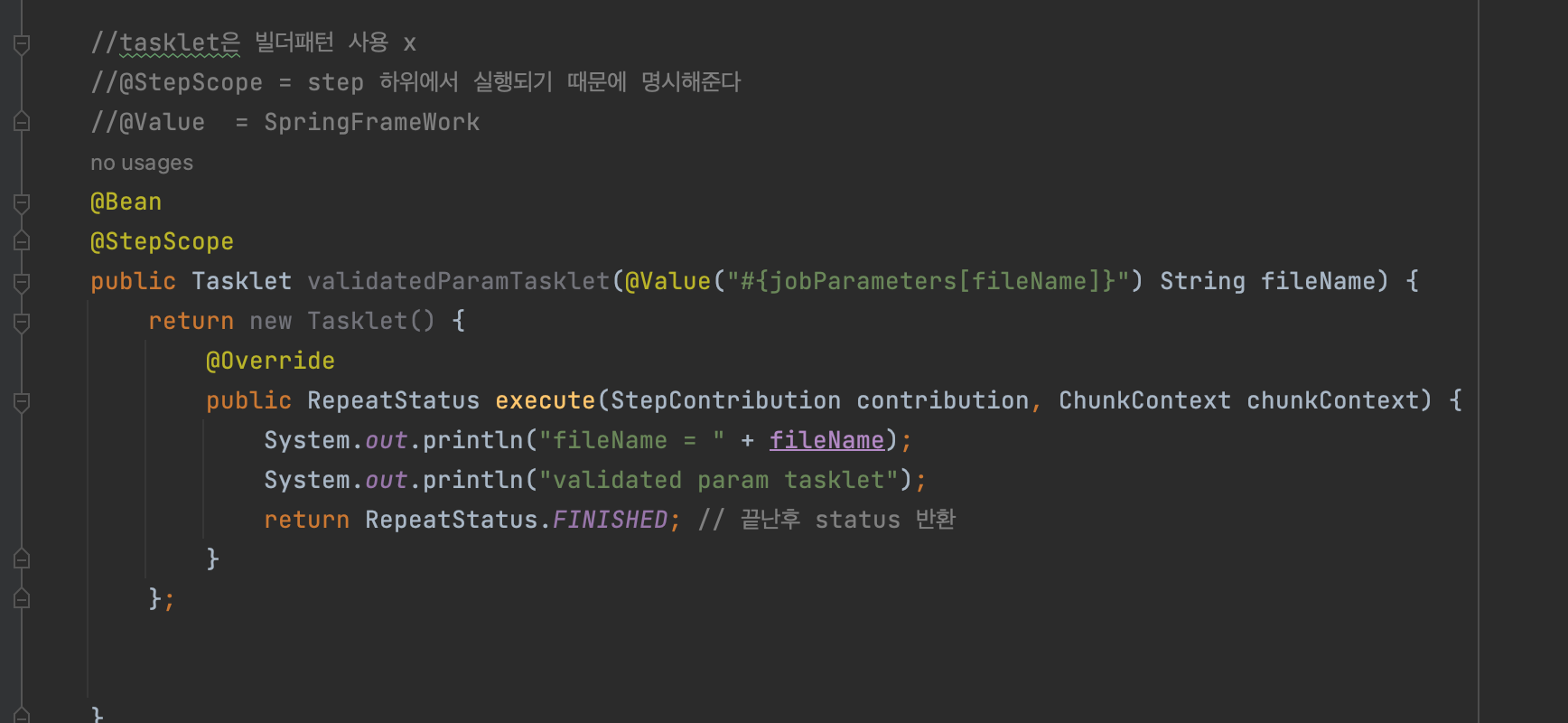
- @Value로 taskLet에서 받는다.
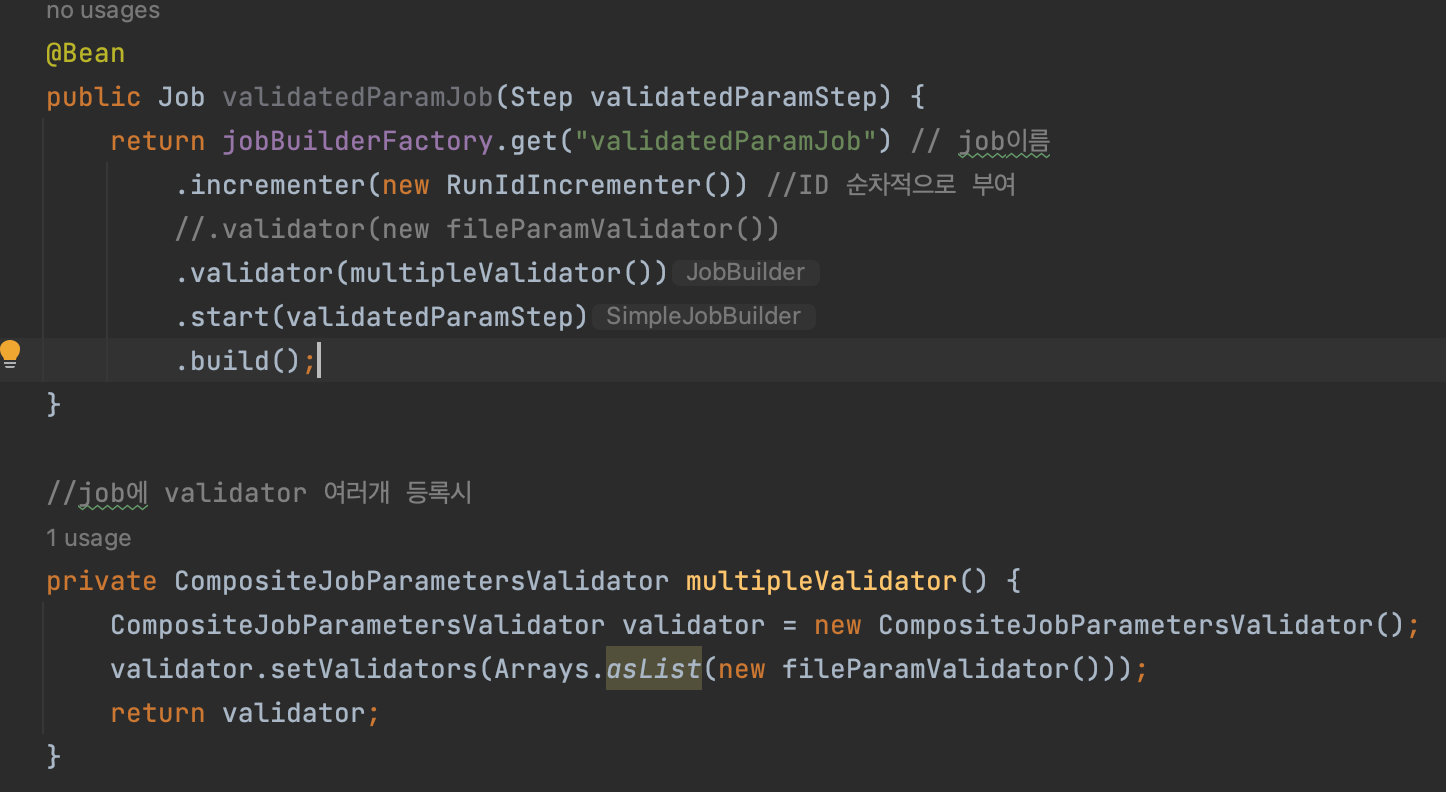
- 검증기를 여러개 추가할수도 있다!
Listener

- listener또한 검증기처럼 job에 추가할수 있다.
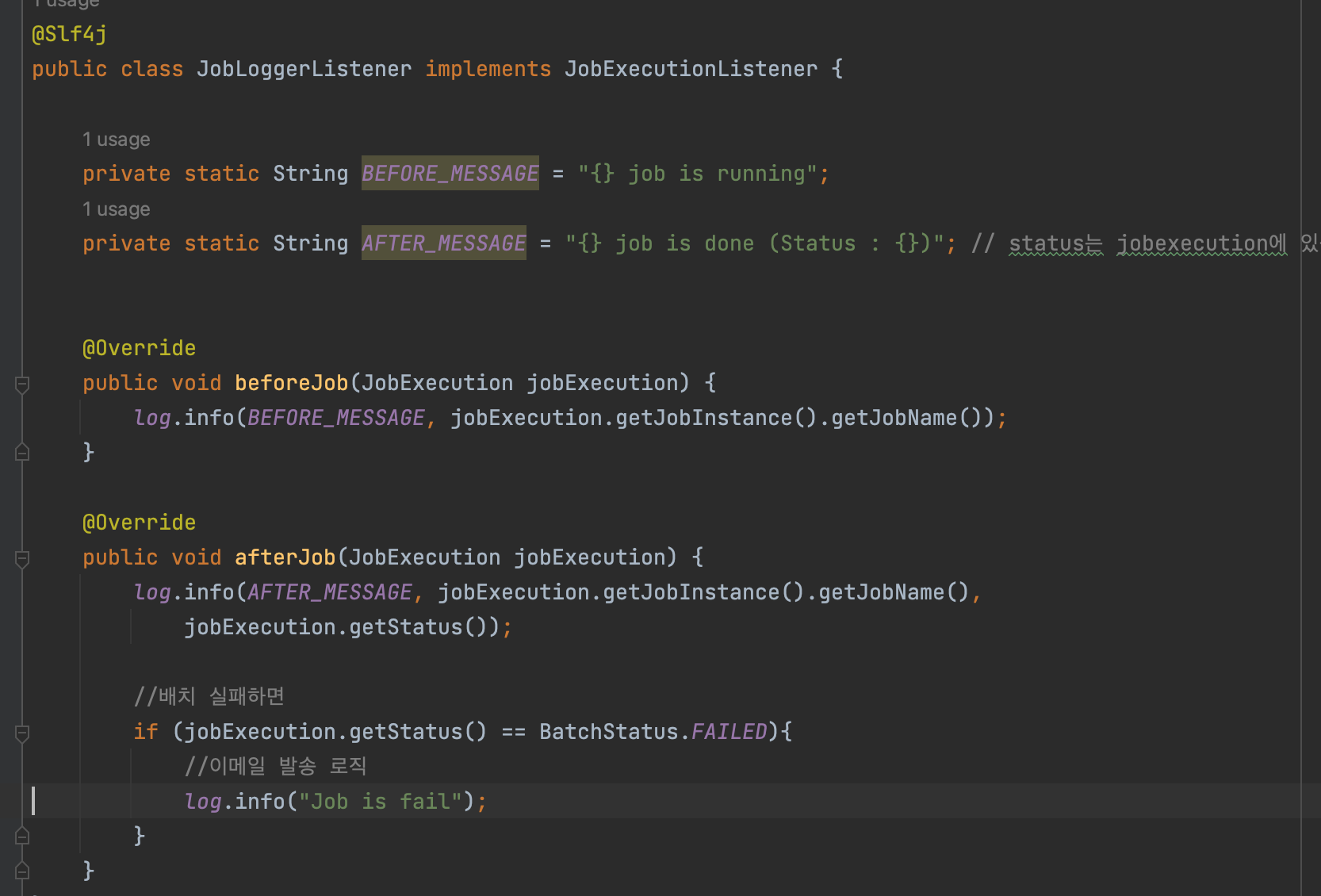
- AOP와 비슷하게 job이 시작하거나 끝난뒤에 동작하도록 만든 listener이다. 지금은 간단하게 로그만 찍도록 만들었다.

호주쉐프에서 개발자까지..
잘 읽었습니다. 좋은 정보 감사드립니다.