성능테스트
- 보통 처리량(Throughput)과 지연시간(Latency)을 엮어서 같이 측정한다
- 왜냐하면 처리량이 낮을때는 지연시간이 낮다가, 처리량을 높아지면 지연시간이 높아지는 경향이 있기 때문
서버자원
-
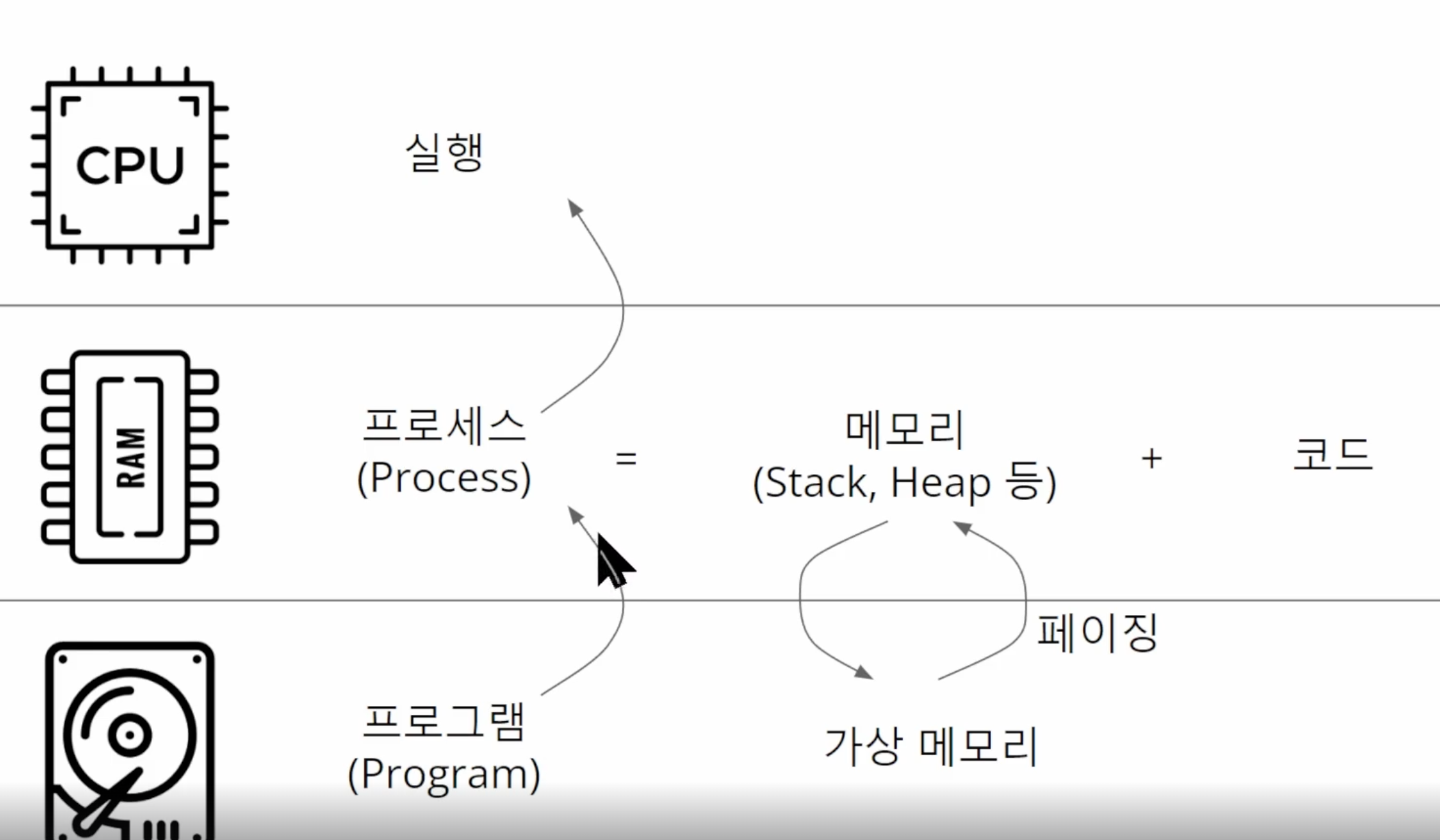
실행파일 exe, jar..etc 프로그램이 실행되면 그게 메모리 위로 올라가서 실행된다. 우린 이거 프로세스라 부른다
-
프로세스 = 메모리(Stack,Heap등) + 코드 , 여기서 메모리는 코드에 영향을 받는다
네트워크
- Latency 의 대부분을 차지하는 부분은 네트워크 이다.(ex: 데이터베이스 호출, 또 다른 API 호출)
- 네트워크는 물리적인 거리에 제약을 굉장히 많이 받는다.
- 대역폭을 넘어서는 작업은 Latency를 증가시킴
- 대역폭은 경로상(라우터) 가장 낮은 대역폭으로 맞춰짐 (ex : 100 -> 200 -> 300이면 100으로 맞춰진다)
데이터베이스
- 데이터 베이스도 일종의 애플리케이션이다.
- 많은 데이터들 중 조회를 특정 데이터를 조회할때, 한번에 많은 데이터를 넘겨줄떄, 여러건을 동시에 처리할때, 락이 너무 자주걸릴때 Latency가 증가함
성능 테스트 순서
- 한건씩 요청을 보내 지연시간이 어느정도 나오는지 체크
- 처리량(ThroughPut)을 늘려가며 지연시간이 치솟는 지점 찾기, 그 지점부터 성능개선 시작
- 어떤 부분이 병목이 되는건지 가설을 세워보고 서버자원 모니터링, 로그등을 통해 병목 지점을 찾는다.
성능테스트
TPS
- 초당 처리 가능한 트랜잭션의 수
- TPS 수치가 높을 수록 짧은 시간에 많은 작업을 처리할 수 있다.
- 여기서 트랜잭션이란 http 요청에 대한 응답, 한묶음을 의미함
Vuser
- 가상 사용
Mean test Time
- 평균 테스트 시간 ( 하나의 작업을 완료하는 시간)
-> TPS가 높고 Mean test time이 낮을수록 좋은결과
Artillery
-
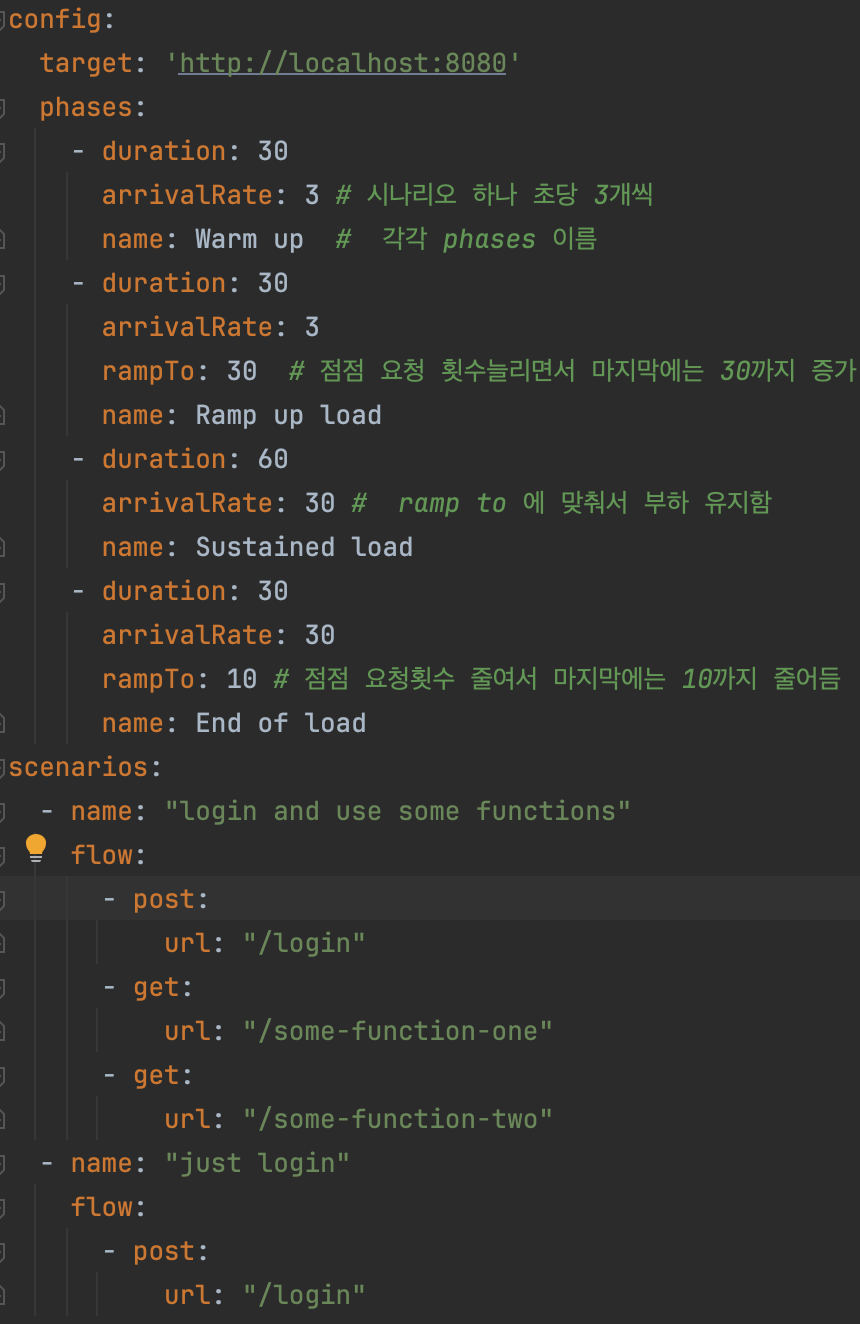
Artillery는 yml 파일로 테스트 컨트룰을 한다.
-
artillery run --output report.json scenario-test-config.yaml 이런식으로 어떤 yml을 사용할지 설정 가능함
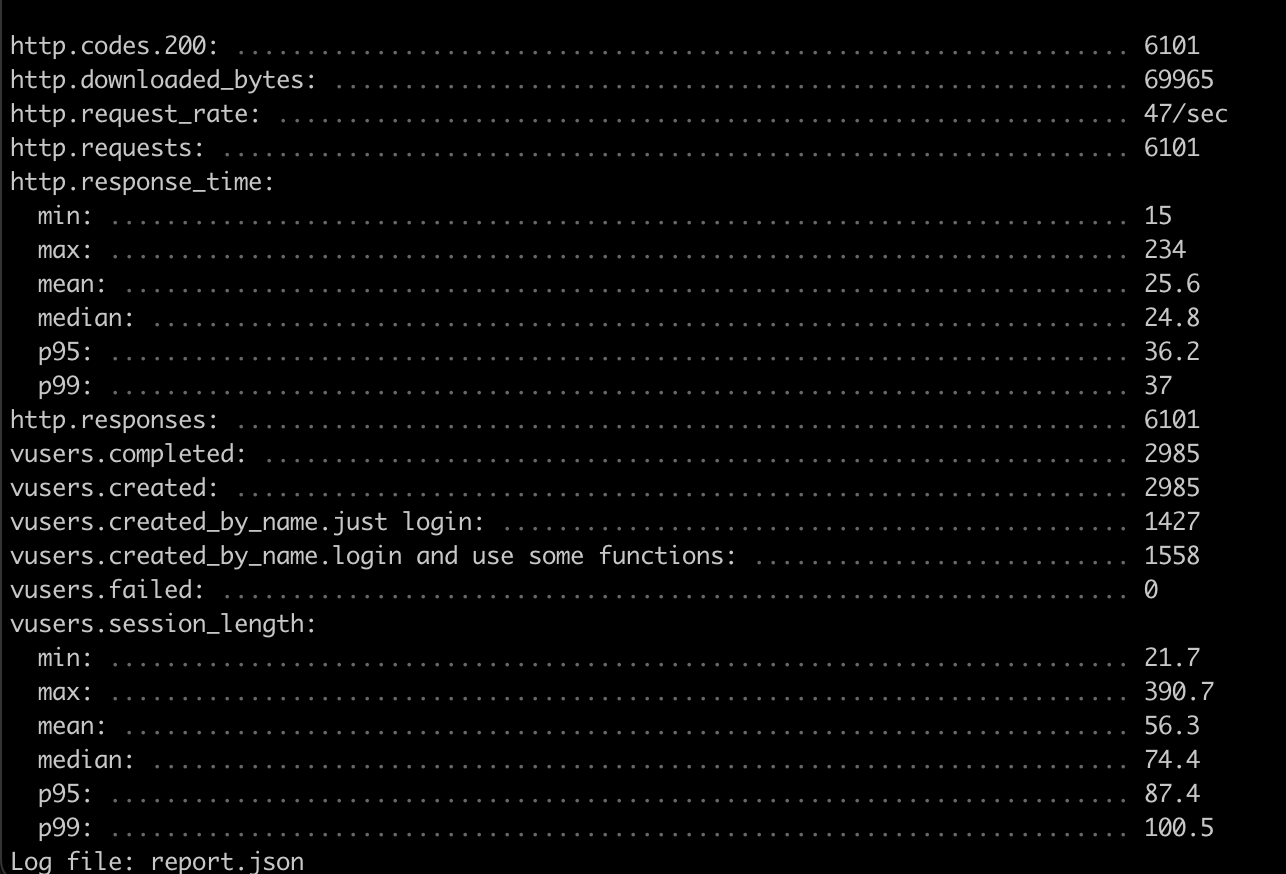
- p95 = 95%의 유저가 이정도로 느낀다, -> p95 와 p99의 차이가 많이 나지 않아야 좋음
- http.codes.200: 상태 코드가 200(OK)인 HTTP 응답 수
- http.request_rate: 초당 HTTP 요청 수
- http.requests: 총 HTTP 요청 수
- http.response_time: 최소, 최대, 중앙값, 95번째 백분위수 및 99번째 백분위수 응답 시간을 포함한 HTTP 요청의 응답 시간에 대한 통계
- http.responses: 수신된 총 HTTP 응답 수
- vusers.completed: 테스트를 완료한 총 가상 사용자 수
- vusers.created: 테스트 중에 생성된 총 가상 사용자 수
- vusers.created_by_name: test.yaml 파일에 정의된 각 시나리오에 대해 생성된 가상 사용자 수
- vusers.failed: 테스트 중 실패한 총 가상 사용자 수
- vusers.session_length: 최소, 최대, 중앙값, 95번째 백분위수 및 99번째 백분위수 세션 길이를 포함하여 가상 사용자의 세션 길이에 대한 통계
- artillery report report.json --output report.html 이 명령어를 사용하면 테스트결과를 html로 만들어줌
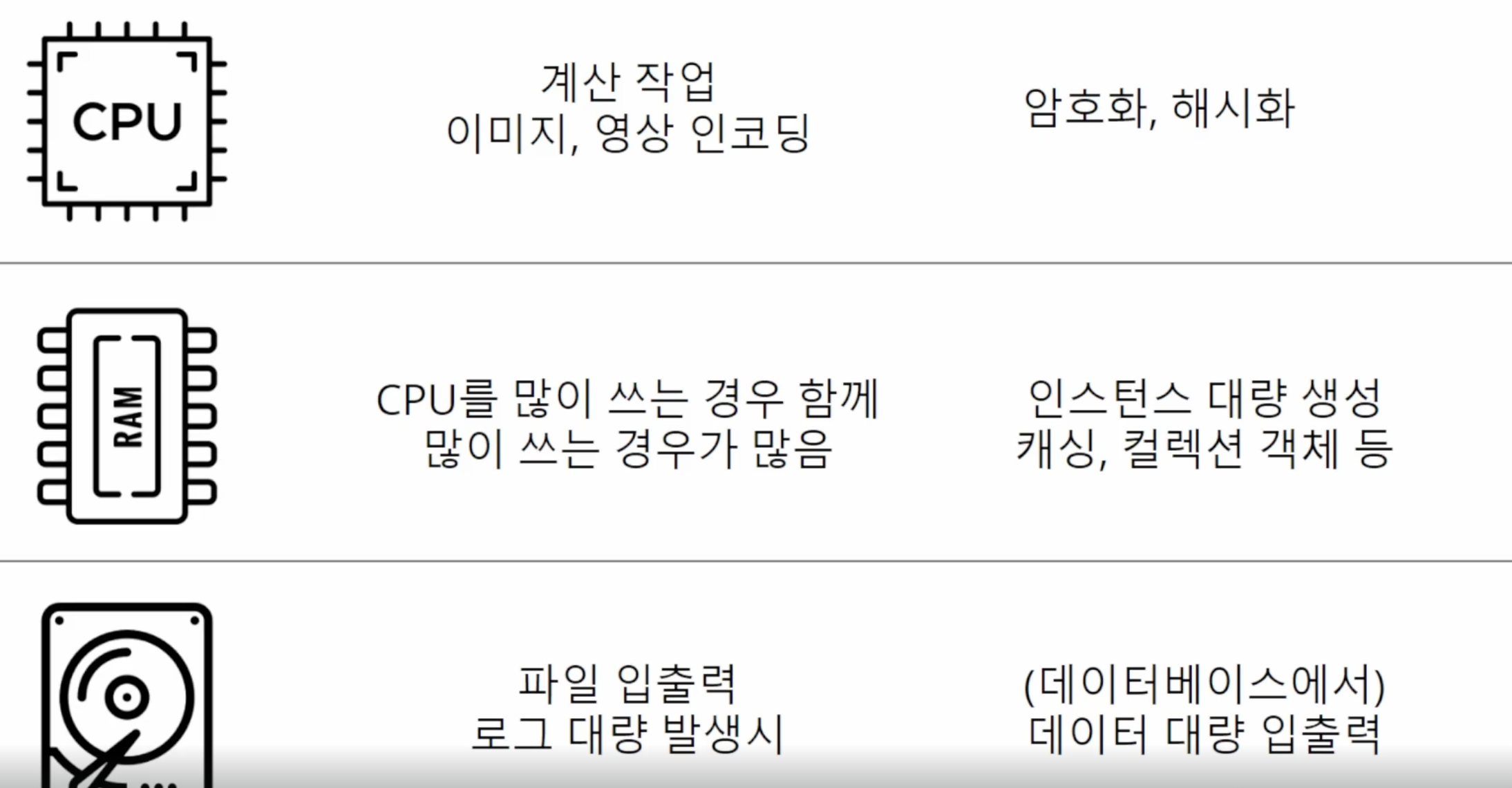
- memeory 부하 테스트시 cpu도 올라가는 이는 GC가 메모리 정리할때 이 인스턴스가 필요한지 안한지 판단할떄 cpu가 사용되기 때문
ngrinder
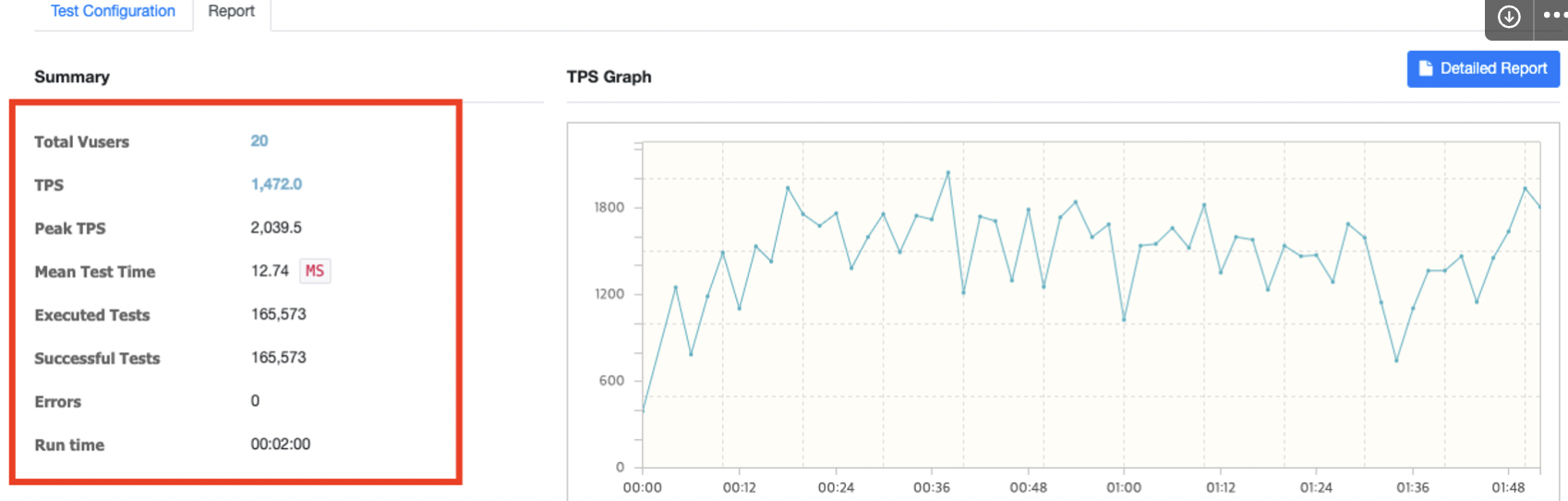
- TPS: 평균 TPS
- Peak TPS: 최고 TPS
- Mean Test Time: 평균 테스트시간
- Executed Tests: 테스트 실행 횟수
- Successful Tests: 테스트 성공 횟수
- Errors: 에러 횟수
- Run time: 테스트 실행시간
성능개선
캐쉬
local cahce
- 로컬 캐시는 애플리케이션 내부에서만 유효하며, 동일한 애플리케이션 내의 여러 모듈이나 서비스 간에는 공유되지 않습니다.
- 또한, 메모리 내에 데이터를 저장하므로 매우 빠른 읽기 및 쓰기 성능을 제공합니다.
- 로컬 캐시는 애플리케이션의 JVM 내부 또는 로컬 서버에 저장되며, 외부에서 접근할 수 없습니다.
GloballCache
- 글로벌 캐시는 여러 서버 또는 애플리케이션 간에 데이터를 공유할 수 있습니다.
- 글로벌 캐시는 주로 네트워크를 통해 데이터에 접근하므로 로컬 캐시에 비해 상대적으로 느린 읽기 및 쓰기 성능을 가질 수 있습니다.
- 글로벌 캐시는 주로 네트워크를 통해 외부 서버에 데이터를 저장하므로 여러 애플리케이션이 공유할 수 있습니다.
-> 캐시가 빠르다고 다 캐시로 사용하면 안됀다. 오히려 히트율이 떨어지는 데이터 조회시 캐시에서 한번찾고 DB에서 한번 더찾는 '이중작업'이 나올 가능성이 크기 때문
인덱스
SELECT * FROM notice
WHERE createDate BETWEEN {startDate} AND {endDate}
;-- 인덱스 생성
CREATE INDEX idx_notice_createDate ON notice ( createDate );
-- 인덱스 확인
show index from notice;- 데이터 베이스는 인덱스가 없으면 조회시 전체 스캔을 한다.
- 인덱스 생성시 특정컬럼 을 기준으로 만든다.
SELECT
CONCAT(ROUND(COUNT(DISTINCT id) / COUNT(*) * 100, 2), '%') AS id_cardinality,
CONCAT(ROUND(COUNT(DISTINCT title) / COUNT(*) * 100, 2), '%') AS title_cardinality,
CONCAT(ROUND(COUNT(DISTINCT content) / COUNT(*) * 100, 2), '%') AS content_cardinality,
CONCAT(ROUND(COUNT(DISTINCT who) / COUNT(*) * 100, 2), '%') AS who_cardinality,
CONCAT(ROUND(COUNT(DISTINCT createDate) / COUNT(*) * 100, 2), '%') AS createDate_cardinality,
CONCAT(ROUND(COUNT(DISTINCT updateDate) / COUNT(*) * 100, 2), '%') AS updateDate_cardinality
FROM notice;
- 인덱스를 정할때는 이렇게 카디널리티 수치를 기준으로 한다.(고유한 값을 가지는 정도)
explain
SELECT * FROM notice
WHERE createDate BETWEEN '2023-01-15 00:00:00' AND '2023-01-15 23:59:59'
;
- 인덱스를 정하고 explain 으로 확인 할 수 있다.
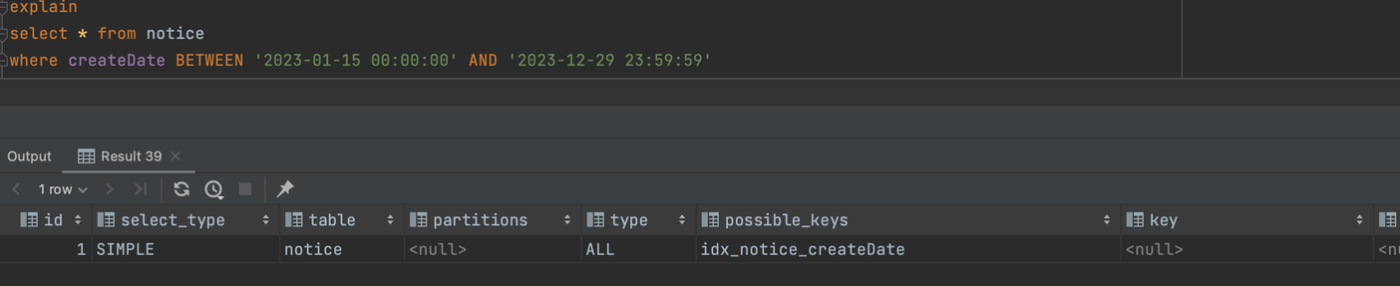
- 인덱스를 걸었지만 풀 테이블 스캔이 더 나은 선택이라고 데이터베이스 엔진이 판단하면 인덱스를 제외하고 조회함
CREATE INDEX idx_notice_who ON notice ( who );
show index from notice;
explain
SELECT * FROM notice
WHERE who = 'incu19'
and
createDate BETWEEN '2023-01-15 00:00:00' AND '2023-01-15 23:59:59'
;
// 힌트 기능을 사용해서 강제로 idx_notice_who 인덱스를 타도록 하기.
explain
SELECT * FROM notice use index(idx_notice_who)
WHERE who = 'incu19'
and
createDate BETWEEN '2023-01-15 00:00:00' AND '2023-01-15 23:59:59'
;- hint기능을 사용해 인덱스를 강제로 타게 할 수 도있음
인덱스를 타지 않는경우
- 함수나 연산자를 사용하는 경우
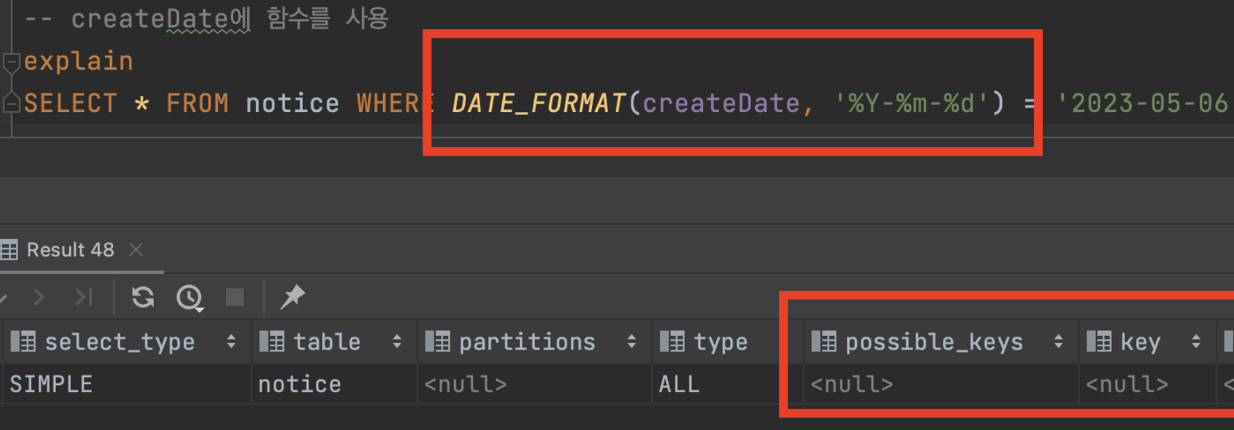
- 쿼리에서 컬럼 값에 함수나 연산을 적용하면 인덱스가 효과적으로 사용되지 않을 수 있다.
- Like문 검색에서 와일드카드 위치
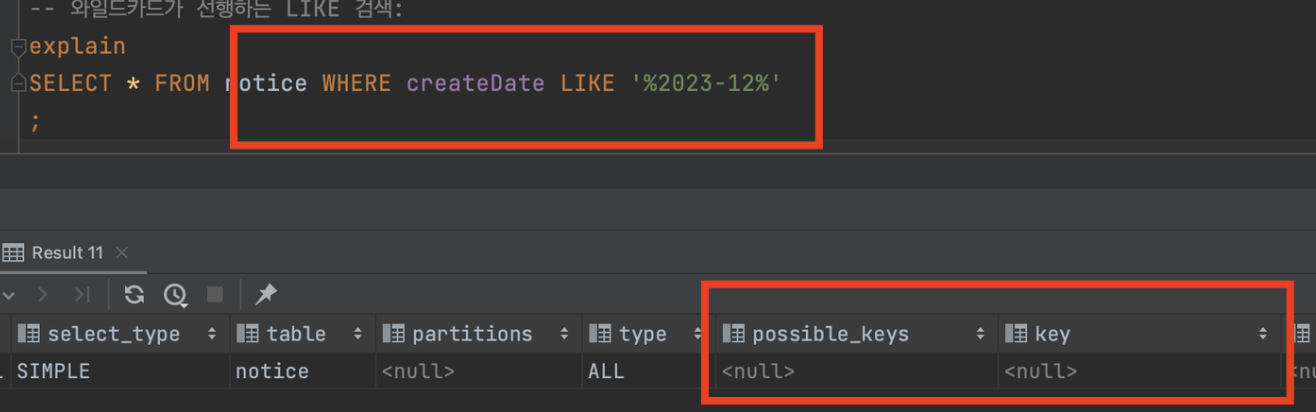
- 와일드카드(%, _)가 문자열의 시작 부분에 위치하면 인덱스가 효과적으로 사용되지 않을 수 있다.
- OR절을 사용하는경우
- 개별 조건이 인덱스를 사용할 수 있더라도, or절은 최적화를 어렵게 만들 수 있다.
4.Null값을 비교하는 경우
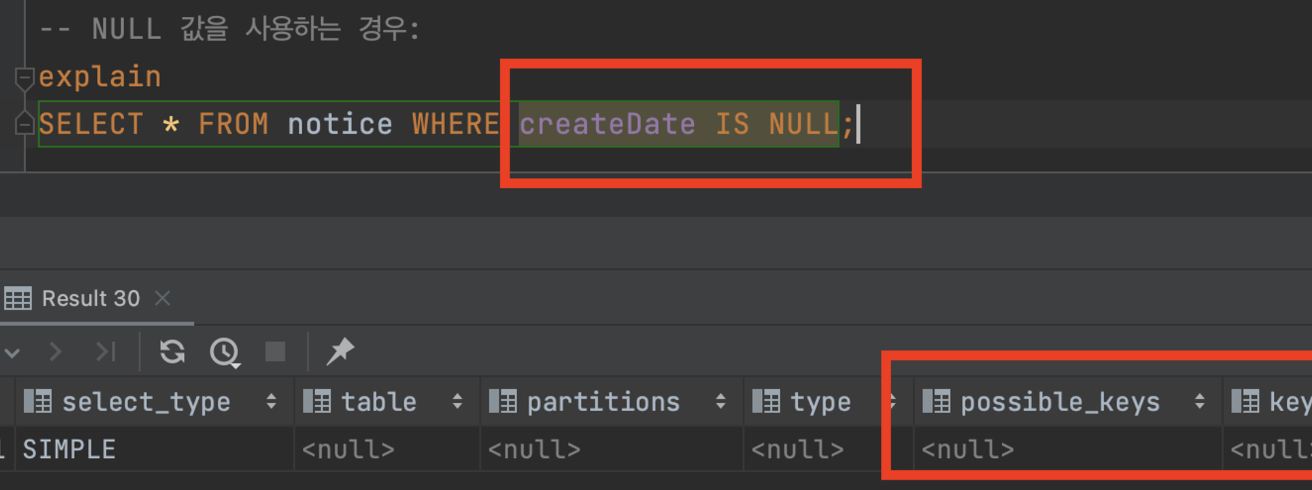
- 특정컬럼 null 검색하는 경우
- 컬럼의 자료형이 다른 검색을 하는경우
- 자료형이 다르면 인덱스의 키와 비교할 값의 자료형이 일치하지 않아 인덱스를 사용할 수 없게 된다.
- In연산자를 사용할때
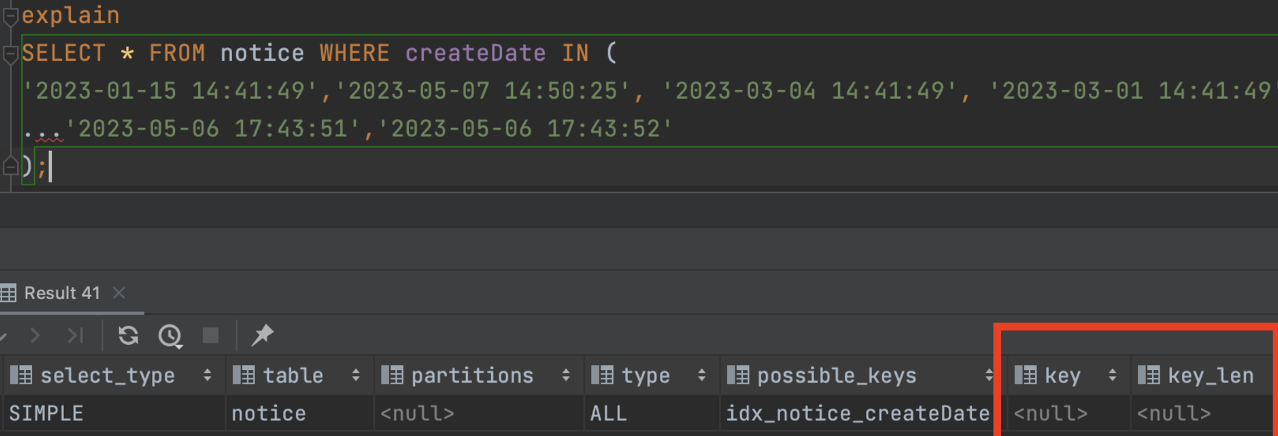
- In연산자를 사용할때 검색 범위가 넓은 경우
Mysql-Profiling
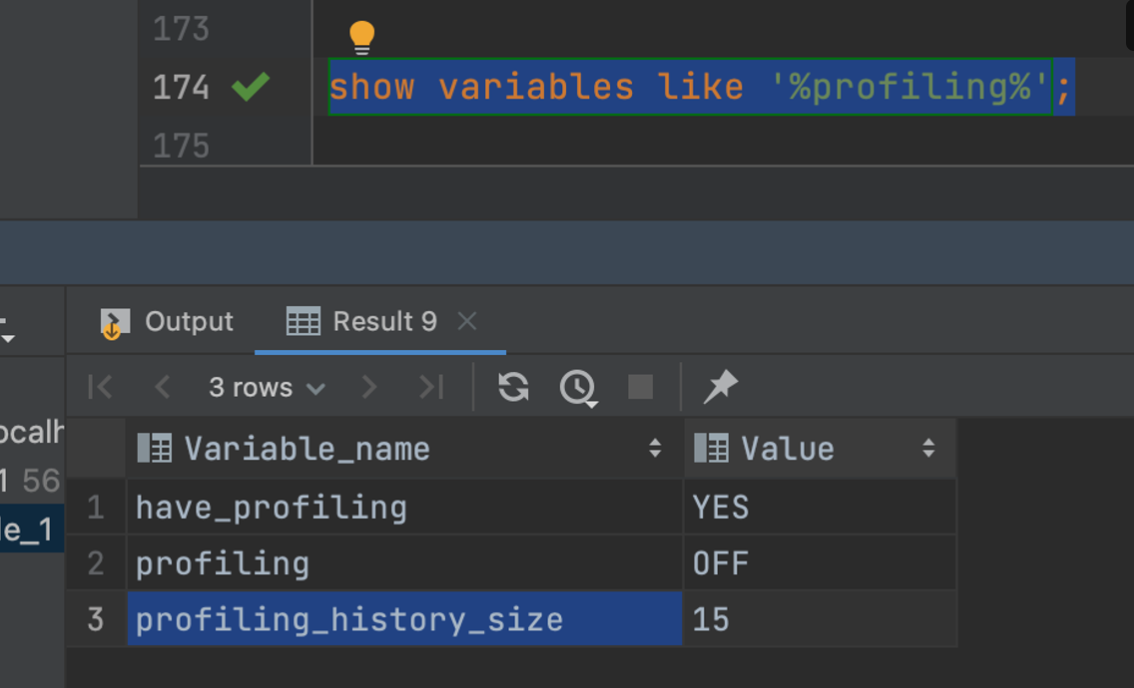
show variables like '%profiling%';- 프로파일링 확인
// profiling 기능 활성화하기
set profiling=1;
set profiling_history_size=100;- 프로파일링 활성화
SELECT * FROM study_db.notice
WHERE createDate BETWEEN '2023-01-15 00:00:00' AND '2023-02-14 23:59:59'
;
show profiles ;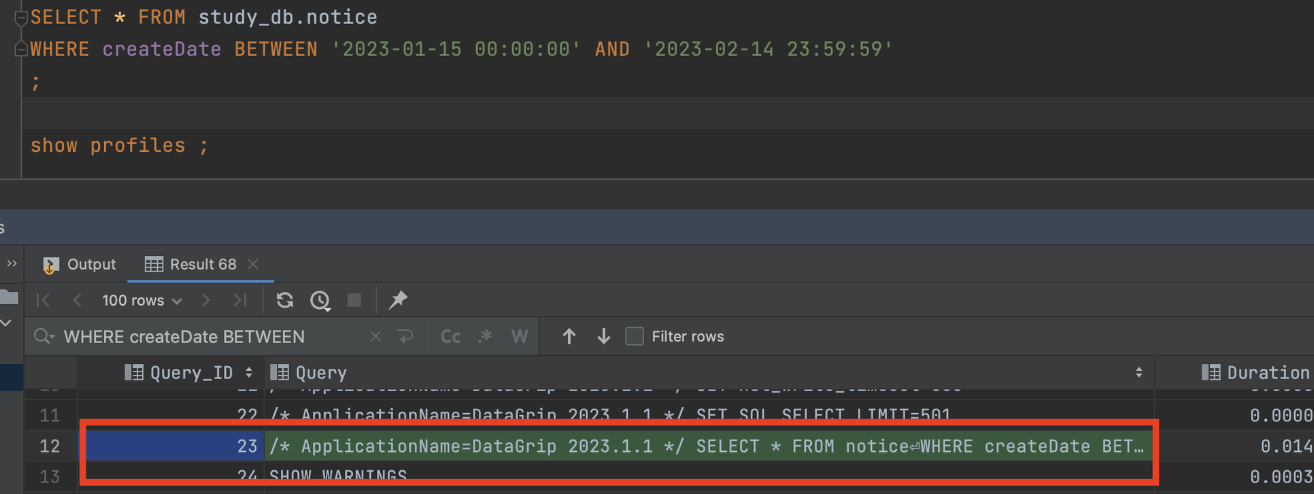
- 프로파일링 활성화후 쿼리 Id 찾기
// 해당 쿼리문의 수행 시간을 더 상세한 단위로 확인
show profile for query 23;
// 해당 쿼리의 CPU 사용량을 분석
show profile cpu for query 23;- BLOCK IO
- MEMORY
- CPU
- CONTEXT SWITCHES
- IPC
- PAGE FAULTS
- SOURCE
- SWAPS
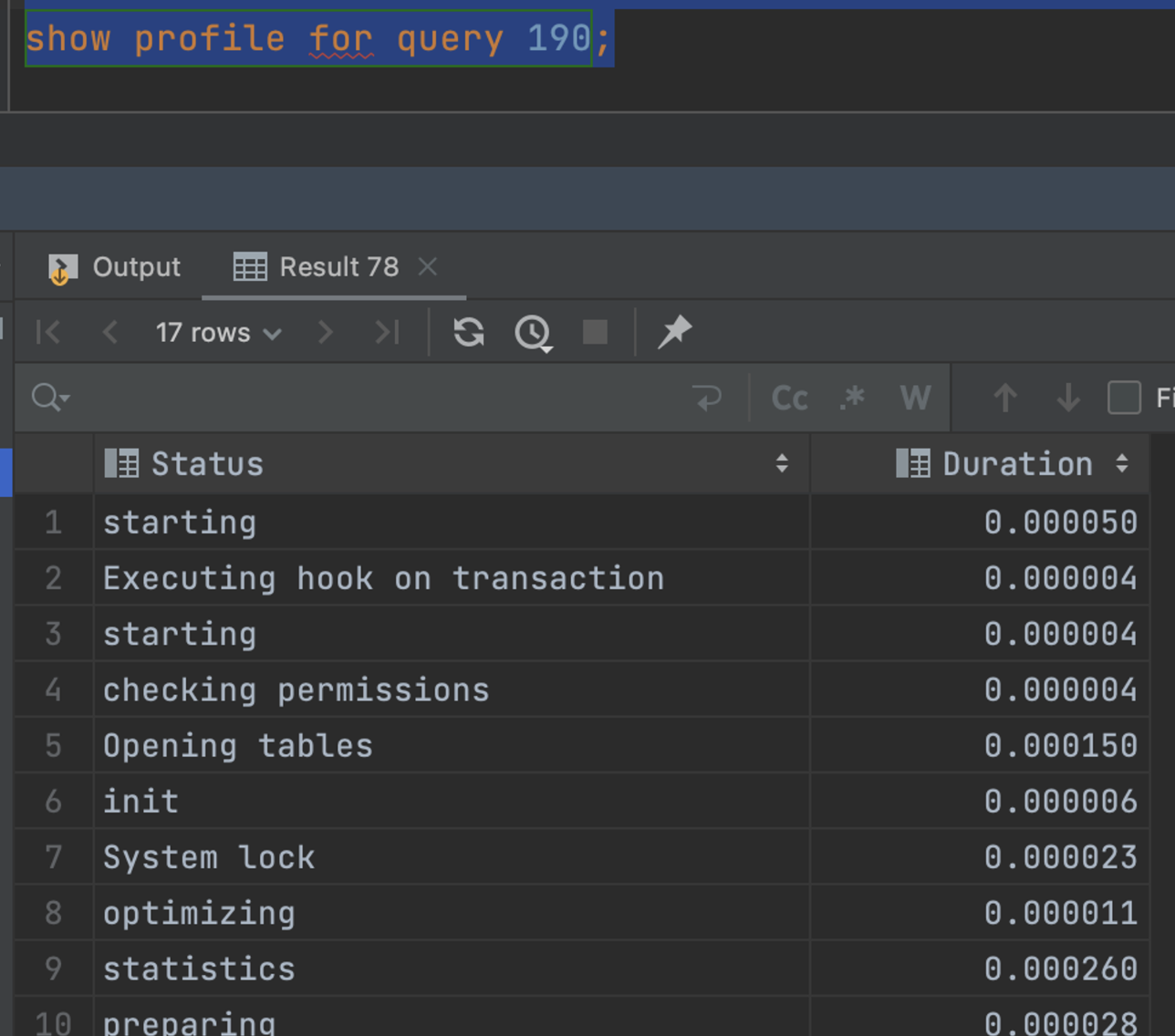
- mySql 에서 Profiling기능을 사용해서 각 쿼리의 작업시간을 알 수 있다.
Mysql index 자료구조
- mySql에서 InnoDB엔진을 사용하고있으며 인덱스의 자료구조는 b-Tree구조이다.
- hash 자료구조의 경우 데이터를 해시 함수를 사용하여 무작위로 배치하므로 정렬된 결과를 얻는것이 어려움
-> b-tree 구조 사용

호주쉐프에서 개발자까지..