Volatile
volatile boolean suspended= false;
volatile boolean stopped= false;
-
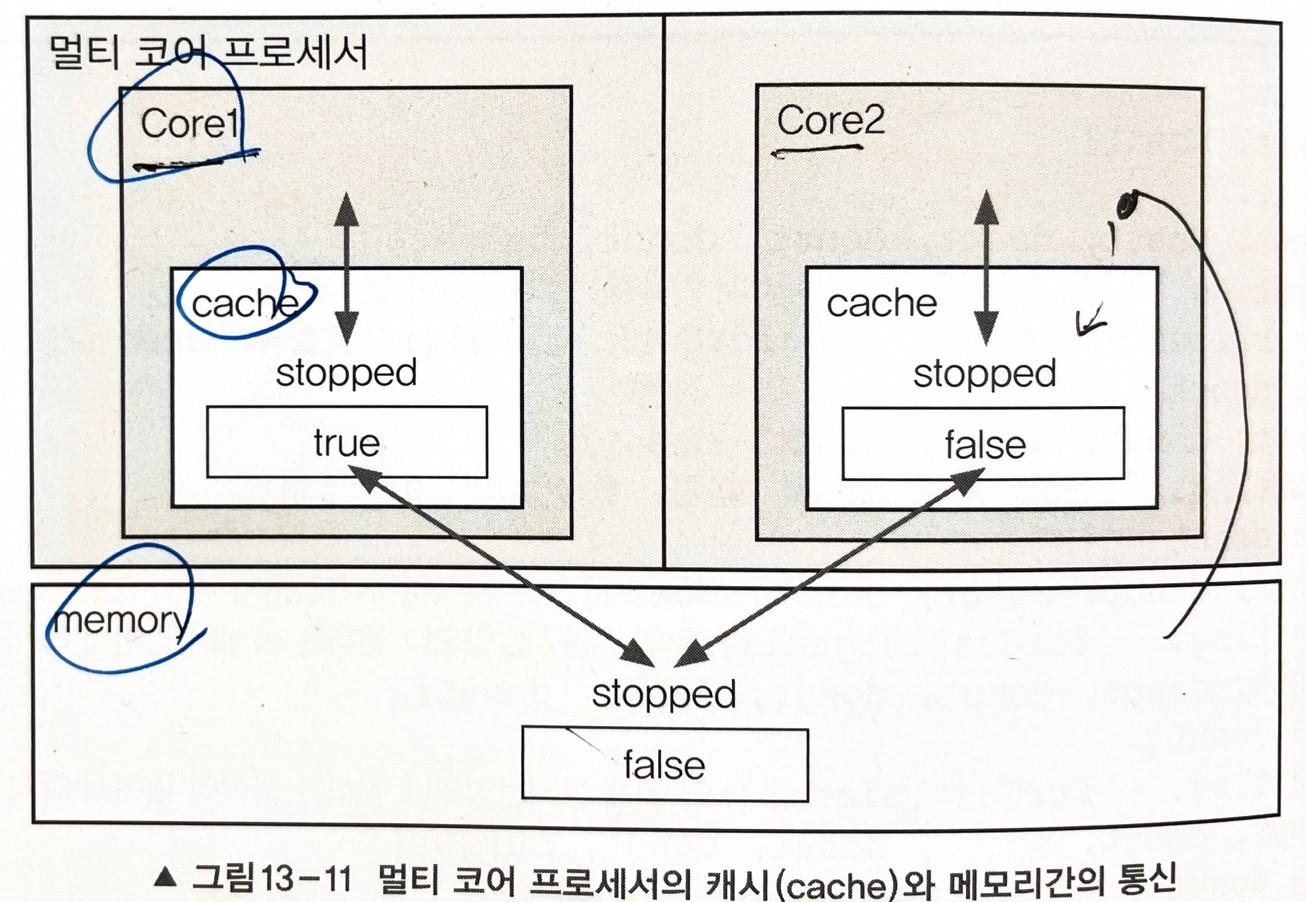
멀티 코어 프로세서에서는 코어마다 별도의 캐시를 가지고 있다.
-
코어는 메모리에서 읽어온 값을 캐시에 저장하고 캐시에서 값을 읽어 작업을 한다. 다시 같은 값을 읽어올때도 먼저 캐시부터 확인하고 없으면 메모리로 간다.
-
그러다보니 메모리에 저장된 값이 변경 되었음에도 불구하고 캐시에 저장된 값이 갱신이 되지않아 문제가 발생한다.
-> Volatile =캐시가 아닌 메모리에서 값을 읽어온다.
-> 변수에 volatile을 붙이는 대신에 synchronized 블럭을 사용해도 같은 효과를 얻을 수 있다.
Volatile 원자화
-
JVM 은 4byte단위로 데이터를 처리하기 떄문에 int와 int보다 작은 타입들은 한번에 읽거나 쓰기 가능하다. 즉 단 하나의 명령어로 일거나 쓰기가 가능 하다는것이다. 하나의 명령어는 더 이상 나눌수 없는 최소한의 작업단위이므로 중간에 다른 쓰레드가 끼어들수 없다.
-
크기가 8byte long, double 타입은 하나의 명령어로 값을 읽거나 쓸수 없기 때문에 중간에 다른 쓰레드가 끼어들 여지가 있다.
-> synchronized 로 감쌀수는 있지만 더 간단한 방법은 위에 예시처럼 변수를 선언할떄 Volatile를 붙이는 것이다.
Volatile vs synchronized
- Volatile는 해당 변수에 대해 읽기나 쓰기를 원자화 시킨다.
-
원자화는 작업을 더이상 나눌 수 없게 한다는 의미인데 synchronized블럭도 일종의 원자화라 할수 있다.
-
Volatile는 읽기나 쓰기를 원자화 할뿐, 동기화 하는 것은 아니다
-
그래서 동기화가 필요할때 synchronized 대신 Volatile 쓸수 없다.
Fork / Join 프레임웍
- 하나의 작업을 작은 단위로 나눠서 여러 쓰레드가 동시에 처리하는 것을 쉽게 만들어 준다.
RecursiveAciton = 반환값이 없는 작업을 구현할때 사용
RecursiveTask = 반환값이 있는 작업을 구현할때 사용
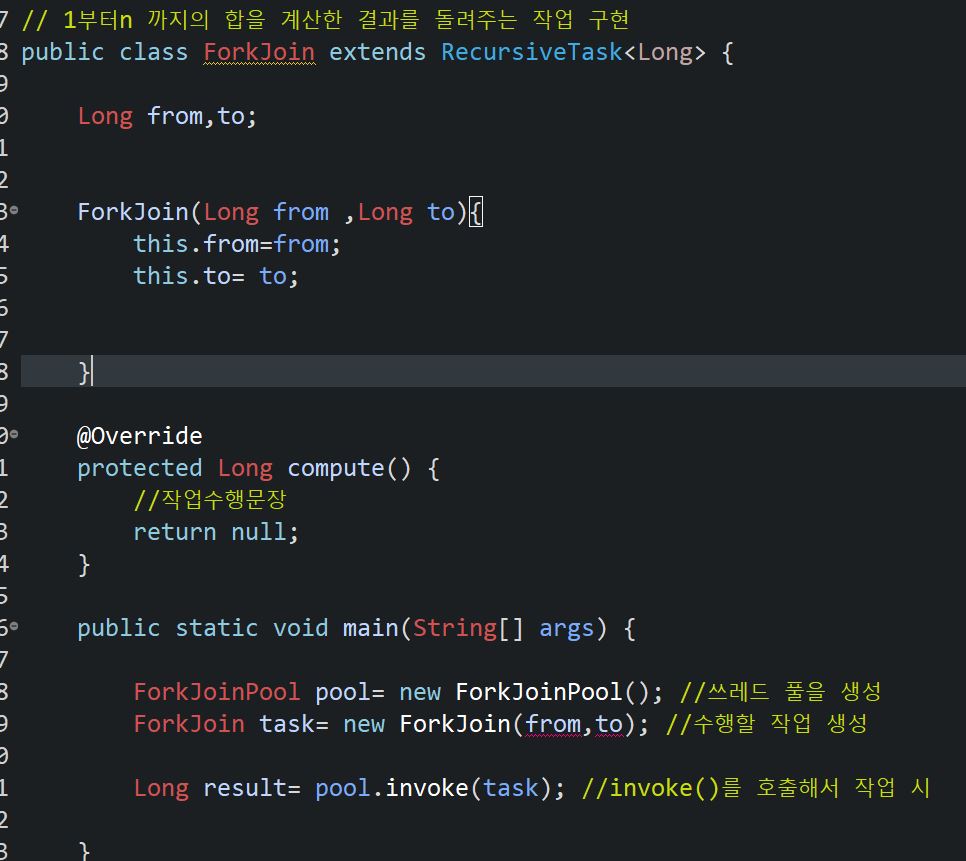
- 두 클래스중에 하나를 상속받아 compute()라는 추상메서들 구현 해야한다.
순서
-
쓰레드 풀과 수행할 작업 생성하고 invoke() 로 작업 시작
-
쓰레드를 시작할떄 run() 이 아니라 start() 호출 하는 것처럼 fork&join 프레임웍으로 수행할 작업도 compute()가 아닌 invoke() 로 시작한다.
쓰레드풀
-
ForkJoinPool 쓰레드 풀로 지정된 수의 쓰레드를 생성해서 미리 만들어 놓고 반복해서 재사용할 수 있게 한다.
-
쓰레드 풀은 쓰레드가 수행해야하는 작업이 담긴 큐를 제공한다.
compute() 의 구현
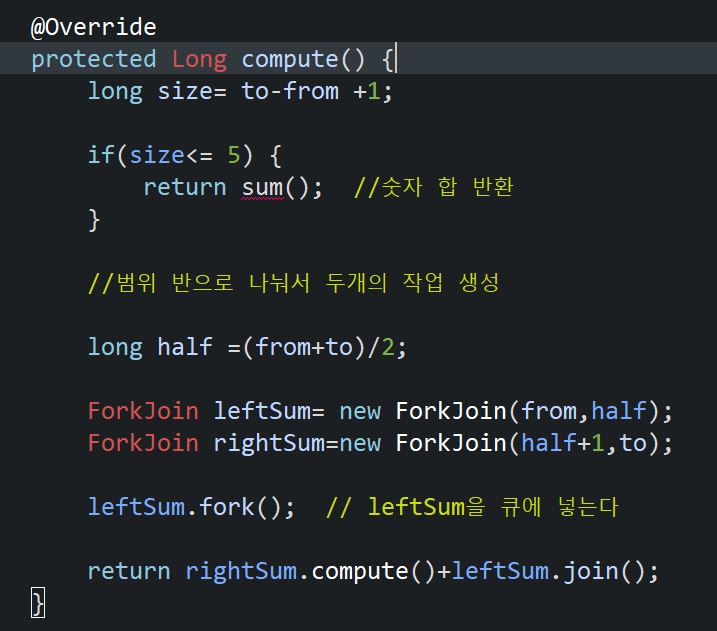
- 수행할 작업 외에도 작업을 어떻게 나눌 것인가에 대해서도 구현해야한다.
-
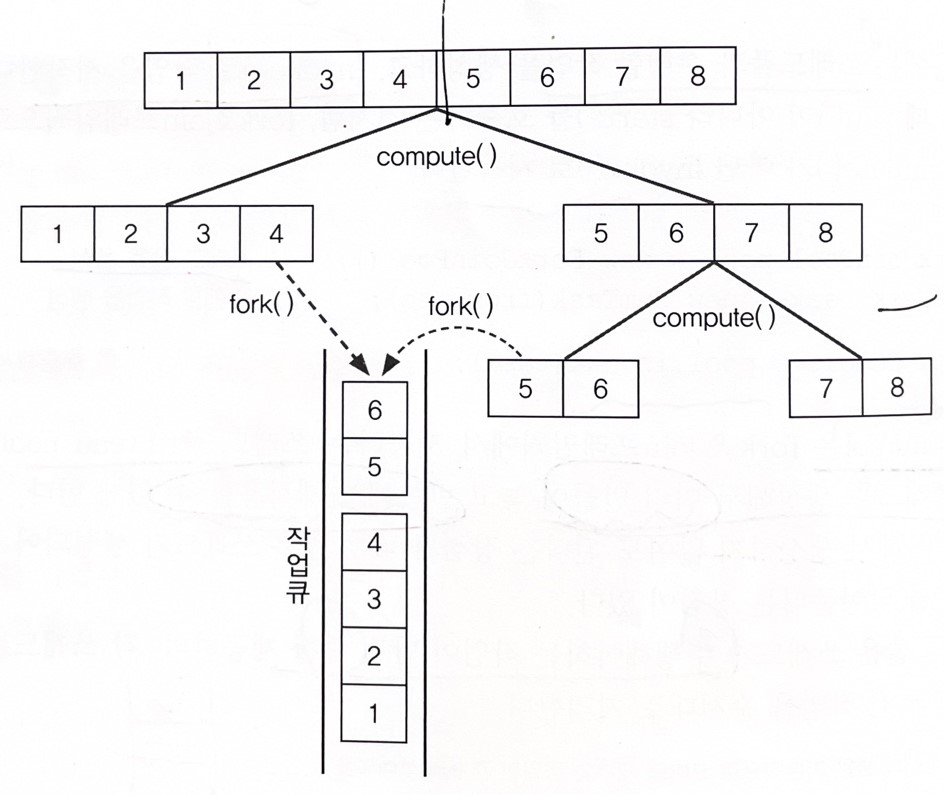
작업의 size가 2가 될떄까지 나눈다. compute()가 호출되면 더할 숫자의; 범위를 반으로 나눠서 한 쪽에는 fork()를 호출해서 작업 큐에 저장한다.
-
하나의 쓰레드는 재귀호출하면서 작업을 계속해서 반으로 나누고 다른 쓰레드는 fork()에의해 큐에 추가된 작업을 수행한다.
-
자신의 작업 큐가 비어있는 쓰레드는 다른 쓰레드이 작업 큐에서 작업을 가져와서 수행한다. 이것을 작업 훔쳐오기 라고 하며 이 과정은 모두 쓰레드풀에 의해 자동적으로 처리된다.
fork()와 join()
-
fork()는 작업을 쓰레드의 작업 큐에 넣는 것이고 , 작업 큐에 들어간 작업은 더이상 나눌수 없을때까지 나뉜다. compute로 나누고 fork로 작업 큐에 넣는 작업이 계속해서 반복된다
-
작업의 결과는 join()을 호출해서 얻는다
fork() vs join()
fork() =해당 작업을 쓰레드 풀의 작업 큐에 넣는다/ 비동기메서드
join() =해당 작업의 수행이 끝날 때까지 기다렸다가 수행이 끝나면 그결과 반환/ 동기메서드
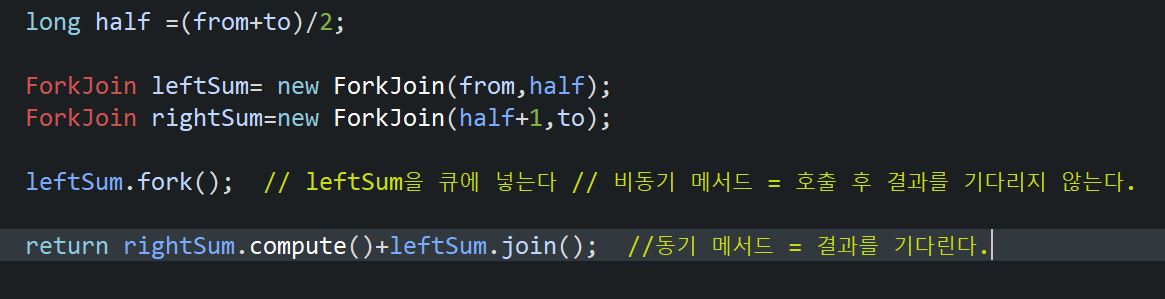
-
비동기 메서드는 일반적인 메서드와 달리 메서드를 호출만 할뿐, 그 결과를 기다리지 않는다. -> fork()를 호출하고 바로 returun 문으로 넘어간다.
-
retrun 문에서 compute()가 재귀호출 될때 join()은 호출되지 않는다. 그러다가 작업을 더이상 나눌 수 없게 되었을때 compute() 의 재귀호출은 끝나고 join()의 결과를 기다렸다가 더해서 결과를 반환한다.
-
compute()가 모두 종료 될때 최종 결과를 얻는다.
