Redis는 key - value 구조이며 value에는 다양한 data type을 지원
data type은 저마다 각자의 특성을 가지고 목적에 부합한 기능을 제공
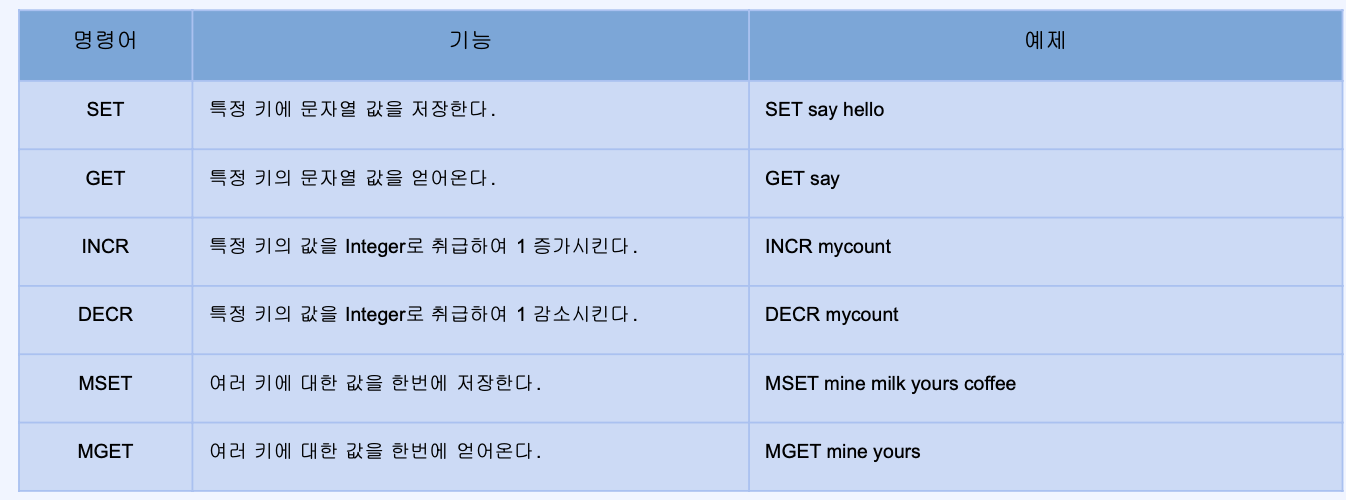
- Strings
- 가장 기본적인 데이터 타입
- 바이트 배열을 저장
- 바이너리로 변환할 수 있는 모든 데이터 저장 가능(JPG와 같은 파일 등)
- 한 key 넣을 수 있는 최대 크기는 512MB
- Lists
- value 값에 하나의 값이 아닌 여러개의 값이 들어간 것
- Linked-list형태의 자료구조(인덱스 접근은 느리지만 데이터 추가/삭제가 빠름)
- Queue와 Stack으로 사용할 수 있음
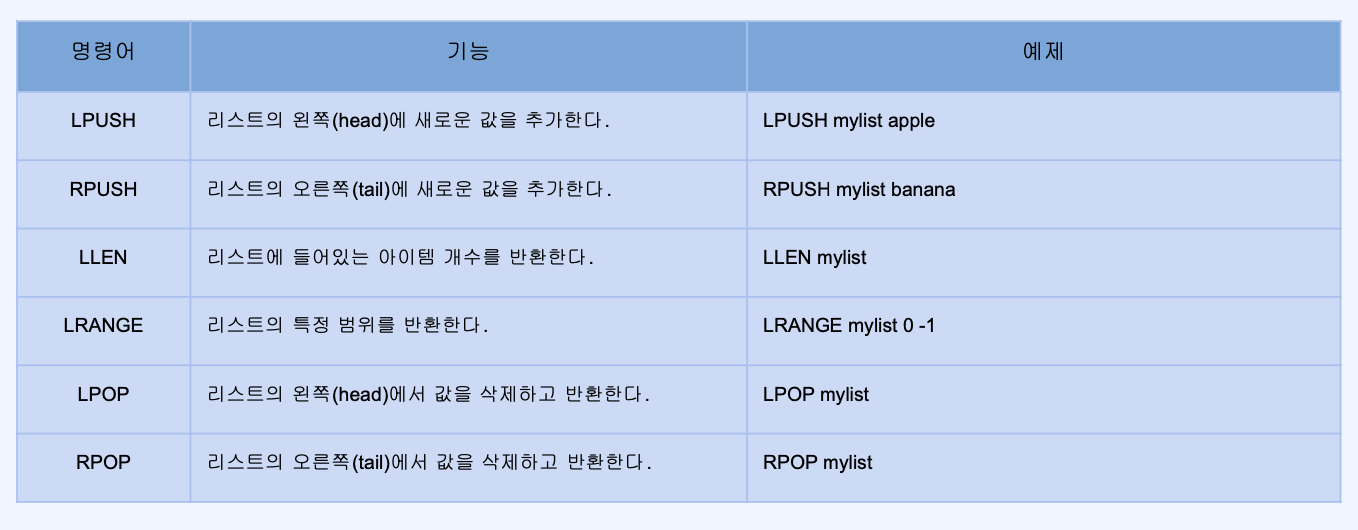
LPUSH -> LPOP 은 나중에 들어온 값을 먼저 삭제하므로 Stack과 유사
LPUSH -> RPOP 은 먼저 들어온 값을 먼저 삭제하므로 Queue와 유사
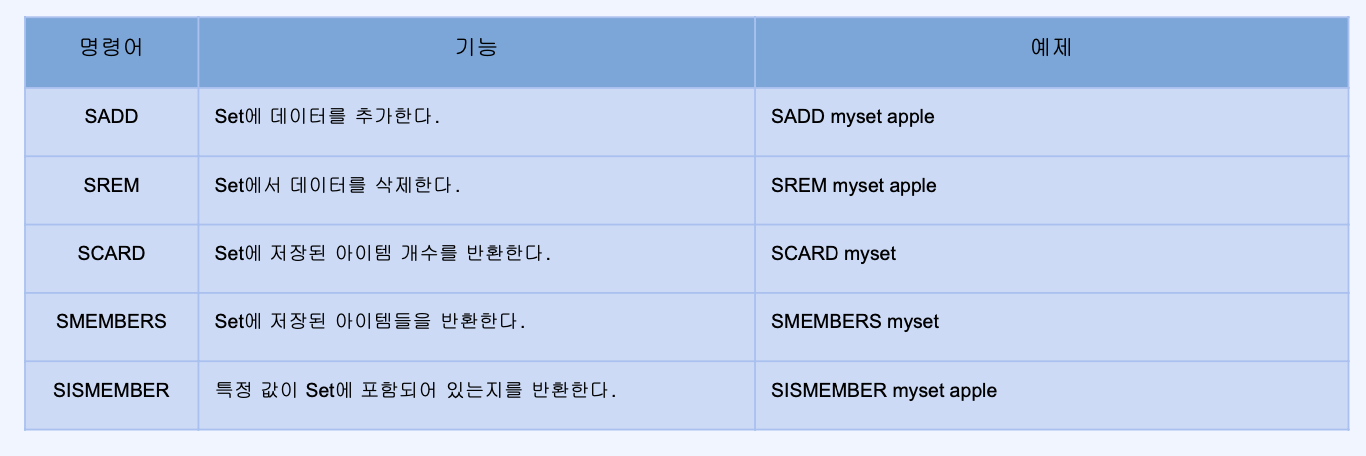
- Sets
- 순서가 없는 유니크한 값의 집합 -> 데이터 존재 여부로 빠름 즉 검색이 빠름
- 개별 접근을 위한 인덱스가 존재하지 않고, 집합 연산이 가능(교집합, 합집합 등)
- 예를 들어 쿠폰 발행시 어떤 유저가 쿠폰을 발급 받았는지의 여부를 빠르게 체크할 수 있도록 만들 수 있음!
- SISMEMBER의 경우 set 들어 있는 개수와 상관없이 동일한 수행속도를 보장함
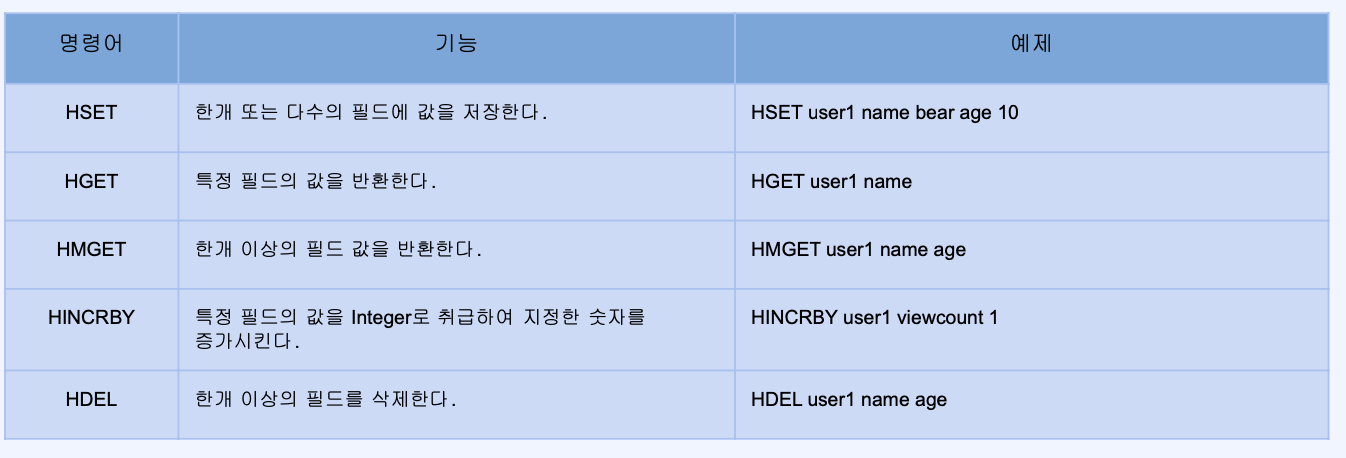
- Hashes
- 하나의 key 하위에 여러개의 field-value 쌍을 저장
- 여러 필드를 가진 객체를 저장하는 것으로 생각할 수 있음
- 특정 필드 지정해서 값을 가져올 수 있음
- 해쉬는 각각의 필드를 따로 사용할 때 유용성이 커짐 예를 들어 유저1의 좋아요 숫자 증가 시키거나 감소시키는 경우
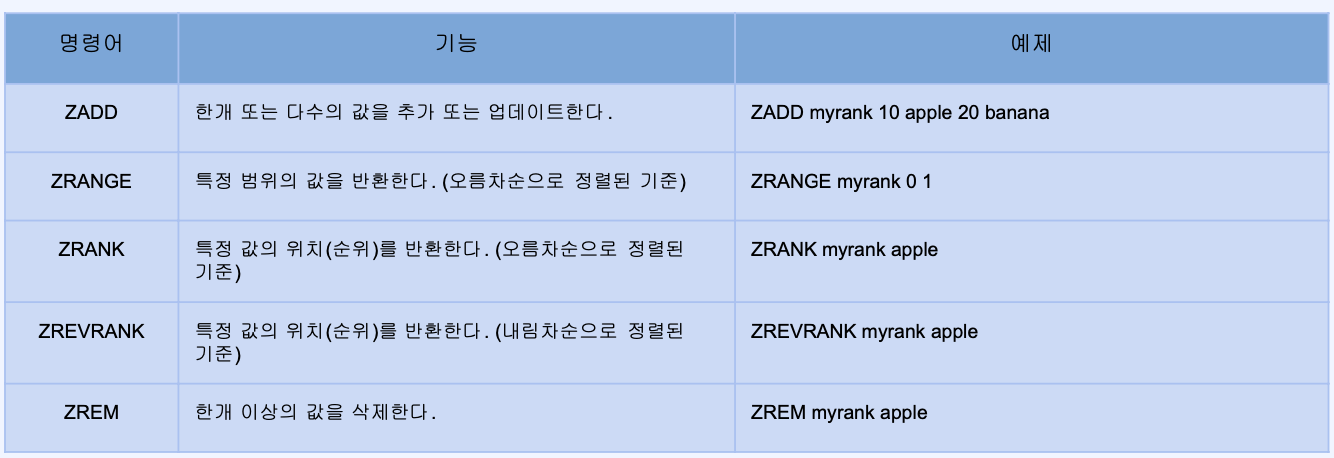
- Sorted Sets
- Set이랑 유사함 순서가 없는 유니크한 값들의 집합
- Set이랑은 달리 각 값은 연관된 score를 가지고 정렬되어 있음
- 정렬된 상태이기에 빠르게 최소/최대값을 구할 수 있음
- 순위 계산 , 리더보드 구현 등에 활용
- 기본적으로 오름차순으로 조회됨
- Bitmaps
- 비트 벡터를 사용해 N개의 Set을 공간 효율적으로 저장

- HyperLogLog
- 값들을 넣은 다음 그 값들의 유니크한 값들의 개수를 효율적으로 얻을 수 있음
- 확률적 자료구조로서 오차가 있으며, 매우 큰 데이터를 다룰 때 사용
- 2^64 개의 유니크 값을 계산 가능
- 12KB 까지 메모리를 사용하며 0.81%의 오차율을 허용
- 여러가지 데이터 타입을 사용할 수 있어서 자유도 높음
- 단, 입력된 값들을 저장하는 것은 아님
- 중복된 값을 넣으려면 중복을 허용하지 않음
- 데이터가 굉장히 많아졌을 떄, 빛을 발함!


오늘의 노력이 내일의 성장으로 이어지고 있음을