발단
메인 프로젝트의 서버가 자꾸 뻗어버린다고 한다...
메인 프로젝트 때 나는 서버 쪽을 담당하지 않았기에 그 때는 몰랐지만,,,
지금의 나는 그래도 조오오오금 전에 비해 아주 조금 성장했기에 서버의 안정성에 대해 매우 큰 관심이 생겼다.
서버 담당하신 백엔드 개발자분께 물어보니 서버가 뻗는 이유는 'out of memory'라고 하셨다.
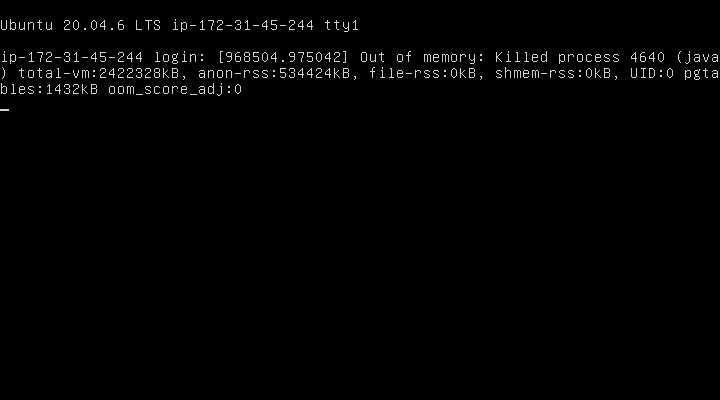
서버에서 OOM이 일어난 것인데, 리눅스 기반은 우분투에서 OOM Killer가 일어난 것이다.
OOM Killer는 메모리가 부족한 상황에서 동작하고, 사용자에게 통보 없이 메모리를 많이 사용하는 프로세스 중 하나를 선택하여 종료 시킨다.
그렇담 OOM Killer를 비활성화 시키는 것은?
가능은 하다. 하지만 내가 모든 메모리 상황을 알고 프로세스를 종료시키는 것이 효율적일까?
당연히 No! 사용자가 모든 메모리 상황을 알고 해당 프로세스를 일일이 종료시키는 번거로움을 해결하기 위해 리눅스 시스템에서 OOM Killer 만든 것이니, 내가 이 부분을 비활성화 시키는 것은 나중에 예상치 못한 문제들을 발생할 여건을 만드는 것이라고 생각했다. 그래서 비활성화 시키는 것은 안하려고 했다.
" 어떤 일이든 가장 기초적인 사실들로 쪼개서 생각하고, 거기서부터 추론해나가기"
일론 머스크가 한 말이다. 일론 머스크는 일을 바라볼 때 물리학적인 관점으로 바라본다고 한다.
나도 일론 머스크가 한 말처럼 따라서 생각해봤다.
Out of memory가 발생한 이유는?
-> 메모리가 가득차서 OOM killer가 실행되었고 메모리를 가장 많이 사용하는 프로세스인 스프링부트 앱을 종료시킨 것이다.
스프링부트 앱의 메모리가 가득 찼다는 얘기이다.
그러면 자바로 만든 스프링부트 앱의 메모리에 어떤 데이터가 가득차 것일까?
메모리의 어떤 부분?? static ? stack ? heap?
static 영역은
GC가 작동을 하지 않았던 것인가?
뭘까?? 일단 위에서 말한대로 기초적인 사실에 집중해보는걸로!! 뭣이 그렇게나 메모리를 쓰는가?? 메모리 어떻게 할당되고 있는지부터 살펴보자
free -h

자 일단, 용어들 한번 싹 정리하고 가면
- total : 총 사용 가능한 물리적 메모리와 스왑 공간
- used : 현재 사용 중인 메모리양
- free : 사용 가능한 메모리 양인데, 점유되지 않은 메모리의 양
- shared : 프로세스 간에 공유되는 메모리 양
- buff/cache : 파일 시스템 캐싱이나 I/O 버퍼링을 위해 사용하는 메모리
- available : free와 달리 점유된 메모리의 양인데, 현재 사용 중이지 않아서 동적으로 메모리를 받을 수 있는 양
- swap : 물리적 메모리 부족 시 사용되는 가상 메모리 공간
간단한 추가 설명을 하자면 스왑에 가상 메모리 공간이라고 하는데 이건 뭐냐면 물리적 메모리가 효율적으로 메모리를 사용하기 위해 쓰는 가상 메모리라고 생각하면 된다.
파일시스템 캐싱은 무엇인가?
파일시스템 부터 알아야한다.
OS는 직접 저장 장치에 접근하지 않고 편의를 위해 파일시스템을 통해 접근한다.
왜 파일시스템이 필요한가? OS가 직접 파일을 저장하였다면, 파일이 저장 장치의 어떤 주소에 저장되었는지 알 수 있을까? 컴퓨터는 그냥 저장만 했을뿐이다. 이렇게 되면 파일이 저장은 되었을지언정 저장한 파일에 다시 접근하는 것은 매우 어렵게 될것이다.
파일 시스템은 이러한 문제를 해결하기 위해 데이터를 저장 장치 어디다 보관 했으며, 저장 장치 빈 영역은 얼마나 있는지 등을 관리할 수 있게 만들어주는 아주 훌륭한 시스템이다.
캐싱은 무엇인가?
이것을 알려면 메모리 장치의 계층 구조를 알아야한다
레지스터 -> 캐시메모리 -> 메모리 -> 저장 장치
오른쪽으로 갈수록 접근 속도가 느려진다.
오른쪽으로 갈수록 가격이 싸진다.
오른쪽으로 갈수록 사이즈가 커진다.
파일 시스템과 연관지어 생각해보면
파일 시스템은 데이터 관리소인데, 처음에는 한번 관리소를 다녀오고 그 후에는 캐시라는 중간 관리소를 만들어서 관리소까지 가는게 아니라 중간 관리소에서 빠르게 데이터 접근하는 것이다.
처음에 데이터 쓰기
OS -> 파일 시스템(데이터 관리소) -> 저장 장치
그 후에 데이터 접근(읽기 및 쓰기)
OS -> 캐시 메모리(중간 관리소) -> 파일 시스템(데이터 관리소)
파일 시스템에 페이지 캐시 기능이 있음
프로세스가 파일의 데이터를 읽어 들이면 커널은 프로세스의 메모리에 파일의 데이터를직접 복사하는 것이 아니라 일단 커널의 메모리 내에 있는 페이지 캐시라는 영역에 복사한 뒤 이 데이터를 프로세스 메모리에 복사.
커널은 자신의 메모리 안에 페이지 캐시에 캐싱한 파일과 그 범위 등의 정보를 보관하는 관리 영역을 가지고 있음
페이지 캐시에 존재하는 데이터를 다시 읽으면 커널은 페이지 캐시의 데이터를 돌려줌
이렇게 해서 저장 장치에 접근하는 경우에 비해 훨씬 빠르게 처리ㅎ됨
buff/cache : 1.1G인데 실제 캐시가 얼마나 점유하나 확인해보면
cat /proc/meminfo
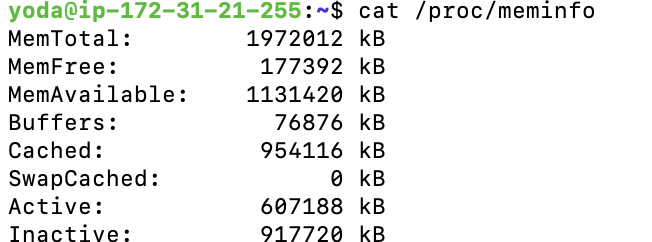
버퍼에 비해 캐시가 훨~~씬 많이 점유하고 있음을 확인할 수 있다.
즉, 문제는 파일 시스템 캐시가 너무 많다는 것이다.
내가 생각했던 것은 EC2에서 실행된 스프링부트 애플리케이션이 메모리 용량을 많이 차지하고 있을 줄 알았는데, 지금 보니 메모리에서 캐시 메모리가 꽤 큰 용량을 차지하고 있다.
그러면 나의 스프링부트 애플리케이션은 메모리를 얼마나 쓰고 있는지부터 확인해보자
ps -eo pid,cmd,%mem,%cpu --sort=-%mem | head
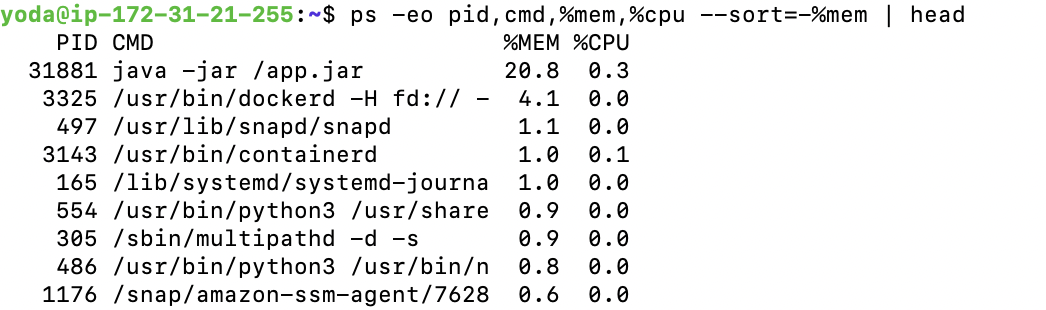
확인해보니 전체 메모리의 20% 밖에 차지하고 있지 않다.
즉, 전체 메모리 중의 60% 이상은 캐시 메모리이고
남은 메모리 중 20% 밖에 차지하지 않는 애플리케이션 때문에 OOM killer가 실행됐다는 것이다.
참고로 OOM Killer는 메모리 부족시에 실행되고 있는 프로세스 중 가장 많은 메모리를 차지하는 프로세를 종료시키기만 한다. OOM killer가 캐시 메모리를 삭제하는 역할을 하지 않는다.
그러면 어떤 부분에서 메모리 용량을 확보하는게 합리적일까?
캐시 메모리 용량을 확보하는게 합리적이다. 왜냐하면 모든 캐시데이터의 빈도수가 높지 않을 것이기 때문이다.
이것을 어떻게 해결하는게 좋을까?
캐시 메모리를 주기적으로 비워준다 -> 특정 부분 성능 하락이 이어질 수 있음
메모리를 늘려준다 -> 비용 추가, 돈이 많다면야 좋겠지만, 지금의 환경에서 최적화하는 방법을 찾고 싶다
그러면?? 캐시 메모리를 주기적으로 비워주는게 좋은 선택일것이다.
여기서 한번 더 생각해봐야할 것은
모든 캐시데이터가 중요한가? 즉, 캐시데이터에 있는 모든 캐시의 빈도가 높으냐는 말이다. 추측하건데 당연히 아닐것이다.
근거는? 파레토의 법칙 + 직접 봐보면 로그 찍어보기
여기서 파레토의 법칙이란? 2:8 법칙인데, 실제 2에 해당하는게 나머지 8에 해당하는 부분보다 중요하다는 것이다. 왜냐하면 실제 2에 해당하는 부분이 실질적으로 더 많이 쓰인다는 것이다. 물론 반박하는 롱테일 법칙도 존재한다.
일단 해보자! 내가 선택한 해결 방법은 주기적으로 파일 시스템을 모니터링하고 빈도수 낮은 캐시를 삭제하도록 만드는 것이다.
-> 계속
