Part3. 프로세스 동기화
시스템은 일반적으로 병렬로 실행되는 수백개 또는 수천개의 스레드로 구성된다. 스레드는 종종 사용자 데이터를 공유한다. 공유 데이터에 대한 액세스가 제어되지 않으면 경쟁 조건이 존재하여 데이터 값이 손상될 수 있다.
프로세스 동기화는 경쟁조건을 피하고자 공유 데이터에 대한 액세스를 제어하는 도구를 사용한다. 이러한 도구를 잘못 사용하면 교착 상태를 포함한 시스템 성능이 저하될 수 있으므로 주의해서 사용해야한다.
Chapter6. 동기화 도구들
협력적 프로세스: 시스템 내에서 실행중인 다른 프로세스의 실행에 영향을 주거나 받는 프로세스
- 협력적 프로세스는 논리 주소 공간(즉, 코드 및 데이터)을 직접 공유하거나 공유 메모리 또는 메세지 전달을 통해서만 데이터를 공유할 수 있다.
- 그러나 공유 데이터에 동시에 접근하면 데이터의 일관성을 망칠 수 있다.
⇒ 이 장에서는 논리 주소 공간을 공유하는 협력적 프로세스의 질서 있는 실행을 보장하여, 이를 통해 데이터의 일관성을 유지하는 다양한 매커니즘을 논의한다.
💡 이 장의 목표 * 임계 구역 문제를 설명하고 경쟁 조건을 설명한다. * 메모리 장벽, compare-and-swap 연산 및 원자적 변수를 사용하여 임계구역 문제에 대한 하드웨어 해결책을 설명한다 * Mutex 락, 세마포, 모니터 및 조건 변수를 사용하여 임계 구역 문제를 해결하는 방법을 보인다. * 적은, 중간, 및 심한 경쟁 시나리오에서 임계구역 문제를 해결하는 도구를 평가한다.6.1 배경
우리는 프로세스가 병행하게 또는 병렬로 실행될 수 있다는 것을 알고 있다. CPU 스케줄러가 프로세스 사이에서 빠르게 오가며 각 프로세스를 실행하여 모든 프로세스를 병행 실행시킨다는 것을 설명하였다. 사실 프로세스는 명령어가 실행될 때 어느 지점에서나 인터럽트 되고, 처리 코어는 다른 프로세스의 명령어를 실행하도록 할당될 수 있다.
⇒ 본 장에서는 프로세스가 병행 또는 병렬로 실행될 때 여러 프로세스가 공유하는 데이터의 무결성에 어떤 문제를 일으키는지에 관해 설명한다.
예) 생산자-소비자 문제
생산자는 count를 count++ 시키고, 소비자는 count—시킨다.
이를 병행적으로 수행시키면 count값이 현재 5라면 count값은 4,5,6 중 하나가 된다! 유일한 올바른 결과는 count ==5이다. 이 결과는 생산자와 소비자의 실행이 분리되었을 때 얻을 수 있는 값이다.
count++과 count—는 다음과 같은 기계어로 구현될 수 있다.
register_1 = count
register_1 = register_1 + 1
count = register_1register_2 = count
register_2 = register_2 - 1
count = register_2register는 한 CPU만 접근할 수 있는 레지스터 중 하나이다.
count++과 count— 문장을 병행하게 실행하는 것은 앞에서 제시한 저수준의 문장들을 임의의 순서로 뒤섞어 순차적으로 실행하는 것과 동등하다. (그러나 각 고수준 문장 내에서의 순서는 유지)
- T0: producer execute register_1 = count {
register_1= 5} - T1: producer execute register_1 = register_1+1 {
register_1= 6} - T2: consumer execute register_2 = count {
register_2= 5} - T3: consumer execute register_2 = register_2 -1 {
register_2= 4} - T4: producer execute count = register_1 {
count= 6} - T5: consumer execute count = register_2 {
count= 4}
이 경우 count==4라는 부정확한 상태에 도달한다. T4와 T5의 순서를 바꾸면 count == 6인 부정확한 상태에 도달한다.
이러한 부정확한 상태에 도달하는 것은 두개의 프로세스가 동시에 변수 count를 조작하도록 허용했기 때문이다.
⇒ 이렇게 동시에 여러개의 프로세스가 동일한 자료를 접근하여 조작하고, 그 실행 결과가 접근이 발생한 특정 순서에 의존하는 상황을 경쟁 상황(race condition)이라고 한다.
⇒ 위와 같은 경쟁 상황으로부터 보호하기 위해, 우리는 한 순간에 하나의 프로세스만이 변수 count를 조작하도록 보장해야한다. 이를 위해 우리는 어떤 형태로든 프로세스들이 동기화되도록 할 필요가 있다.
앞선 장들에서 공부했던 것처럼 다중 코어 시스템의 대두와 더불어 다중 스레드 응용의 개발에 관한 관심이 증가하고 있다. 이런 다중 스레드 응용에서는 자원을 공유할 가능성이 매우 높은 여러 스레드가 서로 다른 처리 코어에서 병렬로 실행된다.
⇒ 협력하는 프로세스간의 프로세스 동기화와 조정에 대해 본장에서 많은 부분 다룰 예정이다.
6.2 임계구역 문제_The Critical-Section Problem
프로세스 동기화에 관한 논의는 임계구역 문제라고 불리는 문제로부터 시작한다.
임계구역: 한 프로세스가 자신의 임계구역에서 수행하는 동안에는 다른 프로세스들은 그들의 임계구역에 들어갈 수 없다. 즉, 동시에 두 프로세스가 임계구역 안에서 실행될 수 없다.

그림 6.1 전형적인 프로세스의 일반적인 구조
임계구역 문제에 대한 해결안은 다음의 세가지 요구 조건을 충족해야한다.
- 상호배제(mutual exclusion) : 프로세스 Pi가 자기의 임계구역에서 실행된다면, 다른 프로세스들은 그들 자신의 임계구역에서 실행될 수 없다.
- 진행(progress) : 자신의 임계구역에서 실행되는 프로세스가 없고, 그들 자신의 임계구역으로 진입하고자하는 프로세스들이 있다면, 나머지 구역에서 실행중이지 않은 프로세스만 다음에 누가 그 임계구역으로 진입할 수 있는지를 결정하는데 참여할 수 있으며, 이 선택은 무한정 연기될 수 없다.
- 한정적 대기(bounded waiting) : 프로세스가 자기의 임계구역에 진입하려는 요청을 한 후부터 그 요청이 허용될 때까지 다른 프로세스들이 그들 자신의 임계구역에 진입하도록 허용되는 횟수에 한계가 있어야한다.
임의의 한 순간에 많은 커널 모드 프로세스들이 운영체제 안에서 활성화 될 수 있다. 그 결과 운영체제를 구현하는 코드(커널 코드)는 경쟁 조건이 발생하기 쉽다.
예를 들어 아래 상황에서 P0, P1의 두 프로세스는 fork() 시스템 콜을 사용하여 자식 프로세스를 생성한다. fork()는 새로 생성된 프로세스의 프로세스 식별자를 부모 프로세스로 반환한다는 점을 상기하라. 이 예에서, 커널 변수 next_available_pid에 경쟁조건이 있으며, 이 변수는 다음 사용가능한 프로세스 식별자 값을 나타낸다. 상호 배제가 제공되지 않으면 동일한 프로세스 식별자 번호가 두 개의 다른 프로세스에 배정될 수 있다.
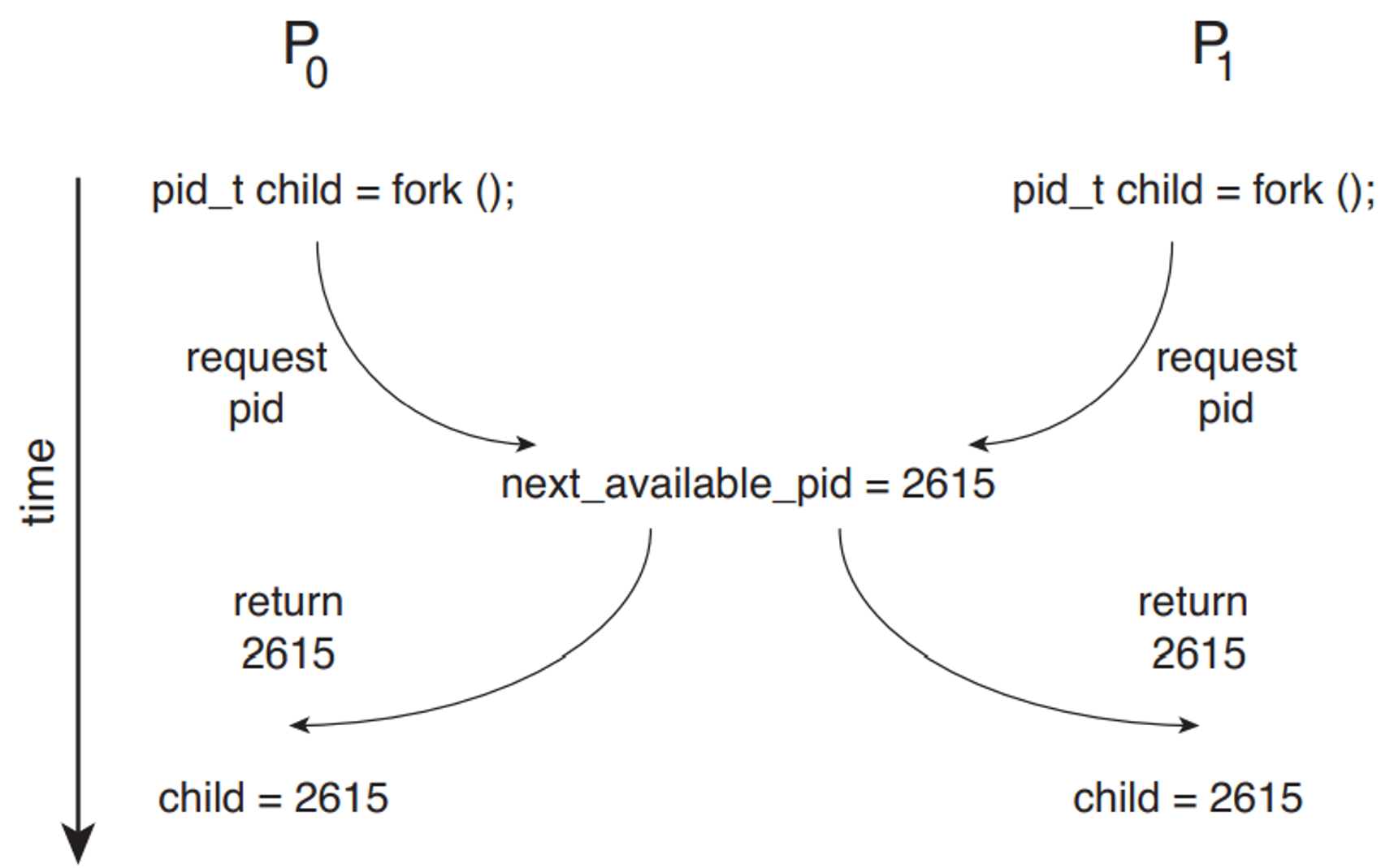
그림 6.2 pid를 배정할 때의 경쟁 조건
단일코어 환경에서는 공유 변수를 수정하는 동안, 인터럽트가 발생하는 것을 막을 수 있다면 임계구역 문제는 간단히 해결될 수 있다. 불행히도, 이 해결책은 다중 처리기 환경에서 실현할 수 있지 않다. 메세지가 모든 프로세서에 전달이 되므로, 다중 처리기에서 인터럽트를 비활성화하면 시간이 많이 걸릴 수 있다. 이러한 메세지 전달은 각 임계구역으로의 진입을 지연시키고, 시스템 효율성을 떨어뜨린다.
운영체제 내에서 임계구역을 다루기 위해서 선점형 커널과 비선점형 커널의 두가지 일반적인 접근법이 사용된다.
- 선점형 커널은 프로세스가 커널 모드에서 수행되는 동안 선점되는 것을 허용한다.
- 비선점형 커널은 커널 모드에서 수행되는 프로세스의 선점을 허용하지 않고 커널 모드 프로세스는 커널을 빠져나갈 때까지 또는 봉쇄할때까지 또는 자발적으로 CPU의 제어를 양보할때까지 계속 수행된다.
⇒ 비선점형 커널은 한순간에 커널 안에서 실행 중인 프로세스는 하나밖에 없으므로 커널 자료구조에 대한 경쟁조건을 염려할 필요는 없다.
⇒ 선점형 커널에 대해서는 동일한 주장을 할 수 없다. 공유되는 커널 자료구조에서 경쟁조건이 발생하지 않는다는 것을 보장하도록 신중하게 설계되어야한다. SMP 구조에서 선점형 커널을 설계하는 것은 특히 어렵다. 이 환경에서는 서로 다른 처기기의 두 프로세스가 동시에 커널 모드에 있을 수 있기 때문이다.
- 그렇다면 사람들은 왜 비선점형 커널보다 선점형 커널을 선호할까?
- 커널 모드 프로세스가 대기중인 프로세스에 처리기를 양도하지 전에 오랫동안 실행할 위험이 적기 때문에 선점형 커널은 응답이 더 민첩할 수 있다.
- 선점형 커널은 실시간 프로세스가 현재 커널에서 실행 중인 프로세스를 선점할 수 있기 때문에 실시간 프로그래밍에 더 적당하다.
6.3 Peterson’s Solution
임계구역에 대한 고전적인 소프트웨어 기반 해결책이다. 현대 컴퓨터 구조가 load와 store같은 기본적인 기계어를 수행하는 방식 떄문에 Peterson의 해결안이 이러한 구조에서 올바르게 실행된다고 보장할 수는 없다.
⇒ 그러나 임계구역 문제를 해결하기 위한 좋은 알고리즘적인 설명을 제공하고 상호배제, 진행, 한정된 대기의 요구조건을 중점으로 다루는 소프트웨어를 설계하는 데 필요한 복잡성을 잘 설명하기 떄문에 이 해결책을 제시한다.
Peterson의 해결안은 두 프로세스가 두개의 데이터 항목을 공유하도록 하여 해결한다.
int turn;
boolean flag[2];- turn은 임계구역으로 진입하라 순번을 나타낸다.
- turn == i이면 프로세스 Pi가 임계구역에서 실행가능하다.
- flag 배열은 프로세스가 임계구역으로 진입할 준비가 되었다는 것을 나타낸다.
- 예를 들어 flag[i]가 참이라면 Pi가 임계구역으로 진입할 준비가 되었다는 것이다.
알고리즘을 설명해보겠다.

임계구역으로 진입하기 위해서
- Pi는 먼저 flag[i]를 참으로 만들고, turn을 j로 지정한다.
- 이렇게 함으로써 프로세스 j가 임계구역으로 진입하기를 원한다면 진입가능하다는 것을 보장한다.
- 만일 두 프로세스가 동시에 진입하기를 원한다면 turn은 거의 동시에 i와 j로 지정될 것이다. (그러나 둘 중 오직 한 배정만이 지속된다. 겹쳐쓰여지기 때문에)
- turn의 궁극적인 값이 둘 중 누가 먼저 임계구역으로 진입할 것인가를 결정한다.
이제 해결책이 올바르게 동작한다는 것을 증명한다. 우리는 다음과 같은 사실을 보여야한다.
- 상호배제가 제대로 지켜진다는 사실
- 진행에 대한 요구조건을 만족한다는 사실(progress)
- 대기 시간이 한없이 길어지지 않는다는 사실(bounded waiting)
-
1에 대한 증명
- 이를 증명하려면 각 Pi가 임계구역에 들어가기 위해서는 반드시 flag[j] == false이든지 아니면 turn == i이여야함을 주목해야한다. 두 프로세스가 모두 자기 임계 구역을 수행중이라면 flag[0] ==flag[1] ==true로 지정하여야한다. 위 두가지 분석을 살펴보면 P0과 P1이 동시에 WHILE문을 성공적으로 지나지는 못한다. 왜냐하면 turn변수의 값은 0이든지 1이든지 둘중 하나여야하지 동시에 두 값을 가질 수 없다.
- 따라서 둘 중 하나만이, 예를 들어 Pj만이 while을 성공적으로 지나갈 수 있었을 것이고, 나머지 Pi는 (”turn==j”)문을 한번 이상 더 실행했어야 할것이다. 그렇지만 그 순간에 flag[j]==true && turn ==j인 상태는 Pj가 임계구역안에 있을 때는 변하지 않는다.
- 따라서 상호배제는 지켜진다.
-
2와 3의 증명
- 이를 증명하려면 우리는 프로세스 Pi가 임계구역에 진입 못하도록 막는 방법은 그것을 while문에서 flag[j]==true && turn ==j 조건으로 묶어두고 계속 공회전 하도록 만드는 방법이라는 점에 주목해야한다.
- Pj가 임계구역에 들어갈 준비가 안되었을때는 flag[j]==false이고, Pi는 임계구역에 진입할 수 있다.
- Pj가 flag[j]를 true로 지정하고 역시 자신의 while문을 수행하게 되면 이때 turn ==i이든지 turn==j일것이다. turn ==i이라면 Pi가 임계구역에 진입하게 되고, turn==j이라면 Pj가 임계구역에 진입하게 된다. 그러나 추후 Pj가 임계구역을 빠져나올 때는 pj가 flag[j]를 false로 재지정하여 Pi로 하여금 진입하게 만들어준다.
- Pj가 flag[j]값을 true로 재지정하고 나면 반드시 turn값도 i로 지정해주어야한다. Pi는 while문을 수행하는 동안 turn값을 바꾸지 않기 때문에 Pi는 Pj가 지난번에 진입했다면 이번에는 자기도 한번은(따라서 대기시간이 한없이 길어지지않음) 들어갈 수 있게 (progress 보장) 된다.
Peterson의 해결안은 최신 컴퓨터 아키텍처에서 작동한다고 보장되지 않는다.
데이터 종속성이 없는 읽기 및 쓰기 작업을 재정렬 할 수 있다.
단일스레드 응용프로그램의 경우 상관없으나, 데이터를 공유하는 다중 스레드 응용프로그램의 경우 명령 순서가 바뀌게 되면 데이터의 일관성이 꺠지거나 예기치 못한 결과를 낳을 수 있다.
⇒ 이러한 사실이 Peterson의 해결안에 어떤 영향을 미칠까?
- 그림 6.3의 Peterson의 해결안의 진입구역에 나타는 첫 두 문장의 순서를 바꾸면 그림 6.4와 같이 두 스레드가 동시에 임계구역에서 활성화될 수 있다.
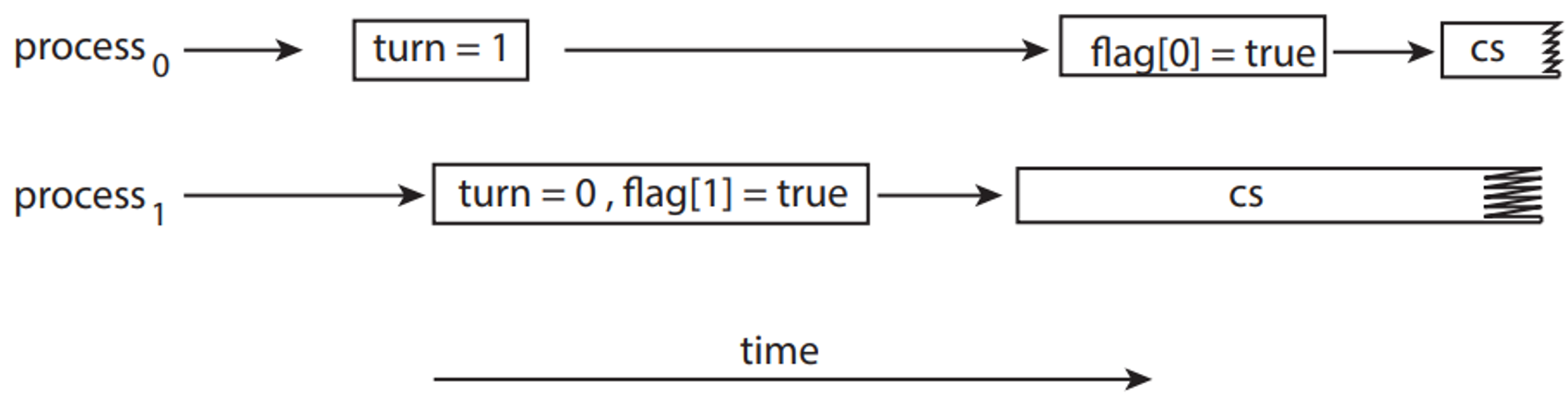
그림 6.4 Peterson의 해결안에서 명령 순서 변경의 영향
다음 절에서 볼 수 있듯이 상호배제를 유지하는 유일한 방법은 적절한 동기화 도구를 사용하는 것이다. 이러한 도구에 대한 논의는 하드웨어 프리미티브 지원에서 시작하여 커널 개발자와 응용 프로그램 프로그래머 모두가 사용할 수 있는 추상적인 고수준 소프트웨어 기반 API 순서로 진행된다.
6.4 동기화를 위한 하드웨어 지원_Hardware Support for Synchronization
이 절에서는 임계구역 문제를 해결하기 위한 지원을 제공하는 세가지 하드웨어 명령어를 제시한다.
6.4.1 메모리 장벽
메모리 모델: 컴퓨터 아키텍처가 응용프로그램에게 제공하는 메모리 접근 시 보장되는 사항을 결정한 방식
⇒ 일반적으로 두가지 범주 중 하나에 속한다.
- 강한 순서: 한 프로세서의 메모리 변경 결과가 다른 모든 프로세서에 즉시 보임
- 약한 순서: 한 프로세서의 메모리 변경 결과가 다른 프로세서에 즉시 보이지 않음
메모리 모델은 프로세서의 유형에 따라 다르므로 커널 개발자는 공유 메모리 다중 처리기에서 메모리 변경의 가시성에 대한 어떠한 가정도 할 수 없다.
- 이 문제를 해결하기 위해 컴퓨터 아키텍처는 메모리의 모든 변경사항을 다른 모든 프로세서로 전파하는 명령어를 제공하여 다른 프로세서에서 실행 중인 스레드에 메모리 변경사항이 보이는 것을 보장한다. ⇒ 이를 메모리 장벽, 메모리 펜스라고 한다.
스레드 1에 메모리 배리어 추가
while (!flag) {
memory_barrier();
}
print x;스레드 2에 메모리 배리어 추가
x = 100;
memory_barrier();
flag = true;⇒ flag값이 x값보다 먼저 적재되도록 보장한다. 이렇게 작업의 재정렬을 피할 수 있다.
- 메모리 장벽은 매우 낮은 수준의 연산으로 간주하며 일반적으로 상호 배제를 보장하는 특수 코드를 작성할 때 커널 개발자만 사용한다.
6.4.2 하드웨어 명령어_Hardware Instructions
많은 현대 기계들은 인터럽트 되지 않는 하나의 단위로서, 특별한 하드웨어 명령어들을 제공한다. 우리는 이들 특별한 명령어들을 사용하여 임계구역 문제를 상대적으로 간단한 방식으로 해결할 수 있다.
test_and_set()과 compare_and_swap() 명령어를 설명함으로써, 이러한 유형의 명령어들 이면에 있는 주요개념들을 추상화하여 설명한다.
- 원자적 test_and_set() 명령어의 정의
boolean test_and_set(boolean* target)
{
boolean rv = *target;
*target = true;
return rv;
}중요한 특정으로는 이 명령어는 원자적으로 실행된다. 그러므로 만일 두개의 test_and_set()명령어가 각각 다른 코어에서 동시에 실행된다면, 이들은 임의의 순서로 순차적으로 실행될 것이다.
- test_and_set() 명령어를 사용한 상호배제 구현
do {
while (test_and_set(&lock)) {
; /* do notiong */
}
/* critical section */
lock = false;
/* remainder section */
} while (true);이 명령어를 사용하여 false로 초기화되는 lock이라는 불린 변수를 선언하여 상호배제를 구현할 수 있다. 이를 사용하는 프로세스 Pi의 구조이다.
- compare_and_swap() 명령어의 정의
int compare_and_swap(int* value, int expected, int new_value)
{
int temp = *value;
if (*value == expected) {
*value = new_value;
}
return temp;
}CAS는 test_and_set() 명령어와 마찬가지로 두 개의 워드에 대해 원자적인 연산을 하지만 두 워드의 내용 교환에 기반을 둔 다른 기법을 사용한다. CAS는 3개의 피연산자를 대상으로 연산을 하며, 피연산자 value는 오직 (*value==expected) 수식이 참일 때만 new_value로 지정된다.
어떠한 경우에든 CAS 명령어는 언제나 value의 원래값을 반환한다. 이 명령어의 중요한 특징 또한 명령이 원자적으로 실행된다는 것이다.
- compare_and_swap() 명령어를 사용한 상호배제 구현
while (true) {
while (compare_and_swap(&lock. 0, 1) != 0) {
; /* do notiong */
}
/* critical section */
lock = 0;
/* remainder section */
}전역변수 lock이 선언되고 0으로 초기화된다. cas를 호출한 첫번째 프로세스는 lock을 1로 지정할 것이다. lock의 원래값이 expected값과 같으므로 프로세스는 임계구역으로 들어간다.
이후의 cas 호출은 현재 lock값이 기댓값 0과 같이 않기 때문에 성공하지 못한다. 프로세스가 임계구역을 빠져나올 때 0으로 변경하고, 다른 프로세스가 임계구역을 들어갈 수 있게 허용한다.
⇒ 위 알고리즘은 상호배제 조건은 만족시키지만 한정된 대기 조건을 만족 시키지는 못한다. 임계 구역 요구 조건을 모두 만족 시키는 cas 명령어를 이용한 다른 알고리즘은 다음과 같다.
- compare_and_swap()을 사용한 한정된 대기조건을 만족시키제
while (true) {
waiting[i] = true;
key = 1;
while (waiting[i] && key == 1) {
key = compare_and_swap(&lock, 0, 1);
}
waiting[i] = false;
/* critical section */
j = (i + 1) % n;
while ((j != i) && !waiting[j]) {
j = (j + 1) % n;
}
if (j == i) {
lock = 0;
} else {
waiting[j] = false;
}
/* remainder section */
}공통 데이터는 다음과 같다.
boolean waiting[n];
int lock;waiting 배열의 원소는 false로 초기화되고, lock은 0으로 초기화된다.
- 상호배제 조건
- Progress 조건
- 한정된 대기조건을 다 만족시킨다.
(증명은 책에 나와있다. p. 295~296 참조)
6.4.3 원자적 변수
일반적으로 compare_and_swap() 명령어는 상호 배제를 제공하기 위해 직접 사용되지 않는다. 오히려 임계구역 문제를 해결하는 다른 도구를 구축하기 위한 기본 구성요소로 사용된다.
그러한 도구 중 하나는 원자적 변수(atomic variable)로, 정수 및 부울과 같은 기본 데이터 유형에 대한 원자적 연산을 제공한다. 원자적 변수는 카운터가 증가할 떄와 같이 갱신되는 동안 단일 변수에 대한 데이터 경쟁이 있을 수 있는 상황에서 상호 배제를 보장하는 데 사용될 수 있다.
6.5 Mutex Locks
6.4절에서 제시한 임계구역 문제에 대한 하드웨어 기반 해결책은 복잡할 뿐 아니라 응용 프로그래머는 사용할 수 없다. 대신 운영체제 설계자들은 임계 구역 문제를 해결하기 위한 상위 수준 소프트웨어 도구들을 개발한다. ⇒ 가장 간단한 도구가 바로 mutex 락이다.
mutex는 mutual exclusion의 축약형태이다. 임계구역으 보호하고, 따라서 경쟁 조건을 방지하기 위해 mutex 락을 사용한다.
- 즉, 프로세스는 임계구역에 들어가기 전에 반드시 락을 획득해야하고 임계구역을 빠져나올때 락을 반환해야한다.
- acquire()함수가 락을 획득하고 release()함수가 락을 반환한다.
- mutex락은 available이라는 불린 변수를 가지는 데, 이 변수값이 락의 가용 여부를 표시한다.
- 사용불가 상태의 락을 획득하려고 시도하는 프로세스는 락이 반환될 때까지 봉쇄된다.
acquire()
{
while (!available) {
; /* busy wait */
}
available = false;
}release()
{
available = true;
}이 구현방식의 단점은 바쁜 대기(busy waiting)를 해야한다는 것이다. 이러한 계속된 루프의 실행은 하나의 CPU 코어가 여러 프로세스에서 공유되는 실제 다중 프로그래밍 시스템에서 분명히 문제가 된다. 바쁜 대기는 다른 프로세스가 생산적으로 사용할 수 있는 CPU 주기를 낭비한다. (6.6절에서는 대기 프로세스를 일시적으로 휴면상태로 전환한 후 락을 사용할 수 있게되면 깨워서 바쁜대기를 피하는 전략을 검토한다.)
우리가 설명한 mutex 락 유형을 스핀락이라고도 한다. 락을 사용할 수 있을 때까지 프로세스가 “회전”하기 때문이다. 그러나 스핀락은 프로세스가 락을 기다려야하고 문맥교환에 상당한 시간이 소요될 대 문맥교환이 필요하지 않다는 장점이 있다.
⇒ 7장에서는 고전적인 동기화 문제를 해결하기 위하여 mutex락과 스핀락을 사용하는 방법에 대해 검토한다.
6.6 Semaphores
mutex는 일반적으로 동기화 도구의 가장 간단한 형태로 생각된다. 본 절에서는 mutex와 유사하게 동작하지만 프로세스들이 자신들의 행동을 더 정교하게 동기화할 수 있는 강력한 도구를 설명한다.
- 세마포 S는 정수 변수로서, 초기화를 제외하고는 단지 두 개의 표준 원자적 연산 wait()와 signal()로만 접근할 수 있다.
wait(S)
{
while (S <= 0) {
; /* busy wait */
}
S--;
}signal(S)
{
S++;
}6.6.1 세마포 사용법
카운팅 세마포와 이진 세마포가 있다. 카운팅 세마포의 값은 제한 없는 영역을 갖는다. 이진 세마포는 0과 1사이의 값만 가능하다.
- 이진 세마포는 mutex 락과 유사하게 동작한다.
- 세마포는 가용한 자원의 개수로 초기화된다.
- 각 자원을 세마포는 가용한 자원의 개수로 초기화된다.
- 각 자원을 사용하려는 프로세스는 세마포에 wait()연산을 수행하며, 이때 세마포의 값은 감소한다.
- 프로세스가 자원을 방출할 때는 signal()연산을 수행하고 세마포는 증가하게 된다.
- 세마포 값이 0이되면 모든 자원이 사용 중임을 나타낸다.
- 이후 자원을 사용하려는 프로세스는 세마포 값이 0보다 커질때까지 봉쇄된다.
6.6.2 세마포 구현
mutex락이 바쁜 대기를 해야했다. 지금 설명한 세마포 연산 wait()과 signal()의 정의 역시 같은 문제를 가지고 있다.
typedef struct
{
int value;
struct process* list;
} semaphore;wait(semaphore* S)
{
S->value--;
if (S->value < 0) {
이 프로세스를 S->list에 추가;
sleep();
}
}signal(semphore* S)
{
S->value++;
if (S->value <= 0) {
프로세스 P를 S->list에서 제거;
wakeup(P);
}
}바쁜 대기를 하는 세마포의 고전적 정의에서는 세마포의 값은 음수를 가질 수 없으나, 이처럼 구현하면 음수 값을 가질 수 있다. 세마포 값이 음수일 때, 그 절댓값은 세마포를 대기하고 있는 프로세스들의 수이다.
6.7 모니터
모니터는 프로세스 동기화의 높은 수준의 형태를 제공하는 추상 데이터의 유형이다. 모니터는 프로세스가 특정 조건이 true가 될 때까지 대기할수 있게 하고 조건이 true가 되면 서로에게 신호를 보낼 수 있게 허용하는 조건변수를 사용한다.
6.8 라이브니스
임계 구역 문제에 대한 해결책은 교착상태를 포함한 라이브니스 문제를 겪을 수 있다.
6.9 평가
임계 구역 문제를 해결하고 프로세스 활동을 동기화하는 데 사용 될 수 있는 여러 도구는 다양한 경합 정도에 따라 평가할 수 있다. 일부 도구는 특정 경합 상황에서 다른 도구들 보다 더 잘 작동한다.
