회사에서 Business Logic 을 위해 Event 를 정의하고 publish, subscribe 하는 pattern 을 사용하여 서버를 개발하고 있다. 그래서 나는 우리 회사가 Event Sourcing Pattern 을 사용하고 있다고 생각했다. 하지만 우리는 Event Sourcing 을 사용하는 것이 아닌 Event Driven Architecture 를 사용하고 있다는 것임을 이번에 Event Sourcing 에 대해 제대로 공부하면서 알게 되었다. 사람들이 흔히 착각하는 Event Sourcing 에 대해서 면밀히 살펴보았다.
이번에 Event Sourcing 에 대해 공부하면서 주로 참고한 문서는 다음과 같다
Martin Fowler - Event Sourcing
Chris Richardson - Pattern: Event sourcing
Greg Young 의 Event Store - A Beginner's Guide to Event Sourcing
Gigi Sayfan - Introduction to event-based programming
대부분 OOP, MSA, Event Sourcing, CQRS 관련 선구자이자 권위자들의 글들을 찾아보았다. 사실 마틴파울러와 리차드슨의 글을 읽고 우리회사가 쓰고 있던 패턴을 생각하면서 대강 완전히 따라할 필요는 없고, 상황에 맞게 적당히 섞어서 사용하면 되지 않을까? 라고 생각하고 글을 쓰려고 했다. 하지만 그러던 중에
Nat Pryce - Mistakes we made adopting event sourcing (and how we recovered)
글을 읽게 되었고, 내가 생각하던 것들이 이 분들이 실수한 것과 상당히 비슷하구나 느끼고, 다시 공부하고, 찾아보게 되었다. 마틴파울러의 글을 읽으면서 사실 완벽하게 정리가 되지 않았는데, CQRS 제안자인 Greg Young 이 개발한 EventStoreDB 회사에서 정리한 글이 다른 권위자들의 설명이 거의 다 녹아져 들어가 있으며, 깔끔하게 잘 정리되었다고 생각했다. (역시 상업용은 다르다) 그래서 이 글은 그 Article 의 번역이 주를 이룰 것이다.
Event Sourcing?
Event Sourcing 의 원리와 각 Component 들에 대해 알아보기 전에 간략하게 이게 뭔지에 대한 설명을 보자면, 데이터를 이벤트로서 append-only log로 저장하는 패턴이다. 여기서 이벤트는 business 안에서 발생하는 사실들을 의미하며, 모든 state 의 change 다.
예를 들어 한 주문이 생성되고, 그 주문에 상품이 추가되고, 주문이 완료된다 했을때, 한 주문 entity 에 상품에 대한 state 를 update 하고, 주문이 완료된 state 를 update 하여 저장하는 것이 아닌, 각각이 한 event 로서 저장이 되는 것이다.
즉, 주문 Entity 에 상품 entity, 주문 완료 flag 의 값을 저장하는 것이 아니라
1) 주문 생성 Event
2) 상품 추가 Event
3) 주문 완료 Event
들이 순서대로 저장된다고 생각하면 될 것 같다
따라서 이 패턴 속에서는 어떠한 entity 의 현재 상태를 따로 저장하는 것이 아니라, 저장된 event 들을 순서대로 재실행하면서 만들어나간다. 이는 단순히 history log 를 위해, auditing 을 위함이 아니다. 그 외에 여러가지 장점이 존재한다.
Event Sourcing 의 장점
Audit
모든 상태 변화에 대해 immutabe 한 event 로 저장하기 때문에, audit log 로서의 기능도 수행한다
Time travel
모든 상태 변화가 순서대로 저장되기 때문에, 디버깅, 오류 등의 이유로 state 를 과거로 돌려야 하는 상황에서 빛을 발한다
Root cause Analysis
이슈가 발생했을 때 각각의 Event 를 추적하면서 이슈 발생원인을 쉽게 분석할 수 있다
Event Driven Architecture
어떠한 event 가 다른 동작을 triger 하는 event driven architecture 와 구조적으로 잘 맞다
Asynchronous first
Event sourced system 은 각각의 이벤트가 반응형이고, 확장가능성이 크기 때문에 절차적인 transaction script 로 짜여진 business logic 보다 비동기로의 전환이 간단하다.
Replay and Retry
Event 가 전부 기록되어 있기 때문에, 어떤 이벤트가 올바르지 않았을 때 쉽게 되돌리고 replay 할 수 있으며 어떠한 event 가 발생하고 그에 따른 동작이 실패했을 때 쉽게 그 event 를 re-run 할 수 있다.
Loosely-coupled workflow
event 와 관련된 data flow 가 분리되어 있으므로 단일책임을 가지고, 따라서 느슨하게 연결된다. 이에 따라 확장가능성이 증대되고, 유지보수하기 편한 구조를 가지게 된다.
Event Sourcing 핵심 요소 및 원리
Events
이벤트는 도메인 내에서 발생한 사실을 표현한다. 현재 상태는 그 이벤트들로 도출될 수 있다. 이벤트는 변경불가능하다. 이벤트는 일반적으로 unique 한 메타데이터를 갖는다. 이는 timestamp 나 unique id 값이 될 수 있다. 이벤트 내의 데이터는 state 나 read model 이 존재할 수 있게(populate)하는 write 모델에서 사용이 된다.
Event database (event store)
이 article 에서는 자세히 다루었지만, 사실 위에서 다룬 전반적인 내용이 포함된, event store 를 위해서 event store db 를 사용한다는 내용이다. Event Store 을 위해서는 꼭 EventStoreDB를 사용해야 하진 않지만, 이벤트 저장에 특화된 DB 라고 한다.
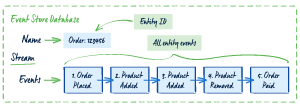
Streams
이벤트 스트림은 domain object 의 변화에 대해서 전체적인 history 를 갖고 있다. 즉, 한 entity 에 대한 event 의 집합이라 할 수 있다. stream 은 object 에 대한 unique 한 id 값을 지니고, 그 object 의 상태변화에 따른 event 가 그 stream 안의 unique 한 position 을 가진채로 저장된다. position 은 주로 incremental numeric value 로 설정된다. 이 position 으로 순서가 정의되고, 동시성 issue 를 파악할 때도 사용된다. stream 은 많은 event 를 가진 short-lived 일 수 있고, 적은 event 를 가진 long-lived 일 수 있다. short-lived 가 유지보수와 versioning 을 더 쉽게 할 수 있다고 한다.

Projection
Event Sourcing 에서 가장 중요한 개념중에 하나가 projection 이다. 이 패턴에서는 현재 상태를 따로 저장하지 않고 event 들만 저장을 하는데, 그럼 현재 상태는 어떻게 가져올 것인가? 에 대한 답이다. projection 은 view model 혹은 query 모델로도 불리는데, 이는 event-based data model 의 view 를 제공한다. projection 은 source 인 write model 을 read model 로 변환하는 로직을 나타내기도 하며, read model과 write model 에서 쓰인다.

Read Model 에서의 Projection
일반적인 시나리오는 write model 에서 만들어진 event 를 취하고 read model view 를 계산한다. 이러한 object(read model view) 는 각각 다른 db 에 저장되고 query 에 사용된다.
이벤트 집합 (stream) 은 다른 이벤트 집합의 시작지점이 되기도 한다. 예를 들어 order event 에서 가격에 대한 요약을 계산하고 다른 event set 을 만들 때 (새로운 event를 추가할 때) 이 요약을 그 이벤트 집합(stream) 의 시작점으로 둘 수 있다. 이러한 projection 을 transformation 이라고 부른다.

Write Model 에서의 Projection
projection 의 또 다른 형태는 stream aggregation 이라고 불린다. stream aggregation 은 stream 으로부터 write model 의 현재상태를 만드는 과정이다. 이것의 목적은 command 를 (event 를 추가) 검증하기 위해 현재 상태를 조회하는 것이다. (현재 상태를 알아야 validation 할 수 있기 때문이다.)

projection들은 현재 상태로 간주되는 것이 아닌 일시적이고 일회용으로 다루어져야 한다. read model 과 projection 간에 혼동이 있으 수 있는데, read model 은 여러 projection 들로 만들어 진다고 볼 수 있고, projection 은 read model 을 만들어내기 위한, 즉 read model 의 이산적인 부분이라고 볼 수 있다.
Subscription
Event Sourcing 에서 각각의 action 은 event 를 작동시키고, 그 이벤트는 action 의 결과로 business information 을 모은다. 이것은 간단하지만 강력하며 복잡한 business workflow 를 구축하며, 더 작은 단위로 분리할 수 있게 해준다.
Event Driven Architecture 에서는, Service 의 책임이 역전된다. pub-sub 접근에 따라 Service 들은 서로 decoupled 된다. 예를 들어, 예약 서비스는 접수 서비스를 직접적으로 호출하지 않는다. 예약 이벤트를 발행하고, 접수 서비스는 그 이벤트를 구독하는 형태의 flow 가 된다. Event Store 는 그러한 구독 기능을 제공할 수 있지만, 저장에 초점이 맞추어져 있기 때문에, 전문화된 streaming solution 인 kafka 등을 이용하는 것이 좋다.
관련 용어
Event Sourcing 과 관련된 용어들을 간략하게 정리한다. 이 각각에 대해서는 따로 더 공부하고 정리해야 되겠다는 내용도 있어서 간단하게만 기술한다.
Eventual Consistency (궁극적 일관성)
Eventual Consistency 는 분산시스템에서 각각의 다른 부분들이 새로 업데이트 되지않는다는 가정 하에 가장 마지막 value 를 return 한다는 개념이다. weak consistency 라고 불리는데, 이는 두 다른 부분에서 한 쪽의 update 가 반영이 안되었을 때는 같은 value 를 return 하지 않지만, 결국에 동기화되는 순간에는 일관성이 보장되기 때문이다. 이것이 Event Sourcing 의 단점이라 하지만, 사실 어느 분산시스템에서도 발생할 수 있는 문제이고 이를 잘 풀어낼 수 있는 것은 모든 시스템의 과제이다. (억울함이 보인다)
Write Model
write model 은 business logic 을 handle 하는 책임이 있다. CQRS 패턴을 사용중이라면 command 가 handle 되는 곳이다. write model 은 physical 과 logical 측면을 가진다. physical 측면은 어디에, 어떻게 데이터가 저장되는지와 관련이 있다. logical 측면은 코드 구조에서 business domain 을 반영한다. 그래서 이는 domain model 로도 불린다. 주로 wrtie model 은 aggregate model 를 사용하여 구현한다. 이는 Domain Driven Design 에 나오는 개념이고, DDD 파트에서 따로 다룰 것임으로 넘어간다.

Read Model
read model 은 특정한 정보를 가지고 있다. read model 은 write model 로 부터 도출될 수 도 있고, 아닐 수도 있다. 이것은 business operation 의 결과가 읽을 수 있는 형태로 변형 된 것이다. read model 은 projection 으로 생성 될 수 있고, 새로 추가된 event 들은 read model 을 업데이트 하거나 만드는 projection 로직을 동작시킬 수 있다. read model 은 영구적이지 않고, 새로운 read model 이 기존 것의 영향을 끼치지 않는다. 또한 기존 business 로직이나 정보에 영향을 주지 않고 삭제 또는 재창조 될 수 있다.
CQRS
command query responsibility segregation 의 약어로 시스템의 행동을 command 와 query 로 격리시킨다. command handler 에서는 상태를 변경시키고 다른 효과를 일으키는 command 들을 handle 하고, query handler 는 요청된 쿼리 데이터를 반환하는 query 를 handle 한다. 더 자세한 내용은 다른 포스트에서 언급할 예정이다.

몇일 동안 Event Sourcing 관련 글만 10개를 넘게 보고 공부했는데, 직접 이를 구현해보아야 더 와닿고 정확하게 이해 할 수 있을 것 같다. 이 패턴에서 가장 의문이 들고, 어려운 부분이라 생각하는게, 동시성 문제와 쿼리를 위한 로직과 성능, 또한 Database 의 load 부분이다. Axon Framework 라고 CQRS와 ES 를 위한 프레임워크가 존재하던데, 이 또한 사용해보고 정리해보아야 겠다.
