1. Overview
사진에서 일반 쓰레기, 플라스틱, 종이, 유리 등 10 종류의 쓰레기를 Detection하는 모델을 만들어 쓰레기 분리배출에 도움이 되고자 함 🌎
-
Input : 쓰레기 객체가 담긴 이미지와 bbox 정보(좌표, 카테고리)가 모델의 인풋으로 사용. bbox annotation은 COCO format으로 제공
-
Output : 모델은 bbox 좌표, 카테고리, score 값을 리턴
-
Metric: test set의 mAP50
- 활용 장비 및 재료(개발 환경, 협업 tool 등)
- 개발 환경
- 개발 언어 : PYTHON
- IDE : VSCODE, JUPYTER NOTEBOOK
- 서버 : AI STAGES
- GPU : NVIDIA TESLA V100
- 협업 tool : git, notion, wandb, google spreadsheet, slack
- mmdetection 라이브러리, yolo_v5 라이브러리, efficientdet 라이브러리
2. Goals
저는 baseline code 분석을 통해 어떤 구조로 파이프라인이 돌아가는지 파악하는 것을 제일 우선으로 삼았고, 어느정도 구조를 파악하고 나서 제공된 모델인 FasterRCNN 을 사용해보며 출력이 어떻게 나오는지 확인을 했습니다. 이후 Wandb 에 연결하여 train 상황을 그래프로 볼 수 있게 했습니다.
이후 MMDetection을 기반으로 SOTA 논문이 구현돼있는 1-stage 모델인 UniverseNet을 baseline으로 사용하기 위해 여러 가지 조합의 수를 생각해서 모델을 튜닝하고 반복적으로 실험을 해보며 어떤 조합이 가장 성능이 좋고, 우리 팀의 base조합으로 가져가면 될지 파악하고자 했습니다.
또한 저번 대회에 이어서 협업 툴(git)의 사용법에 더 익숙해지고자 했습니다.
3. Dataset
dataset
├── train.json
├── test.json
├── train
└── test-
train: 4883 images
-
test: 4871 images
-
class: General trash, Paper, Paper pack, Metal, Glass, Plastic, Styrofoam, Plastic bag, Battery, Clothing
# images
{
"width": 1024,
"height": 1024,
"file_name": "train/0000.jpg",
"license": 0,
"flickr_url": null,
"coco_url": null,
"date_captured": "2020-12-26 14:44:23",
"id": 0
},
# annotations
{
"image_id": 0,
"category_id": 0,
"area": 257301.66,
"bbox": [
197.6,
193.7,
547.8,
469.7
],
"iscrowd": 0,
"id": 0
},- Bbox annotation : .json / coco dataset
- images에는 데이터셋 전체 이미지 목록과 이미지 각각의 width, height, 파일명이 포함돼있음
- annotations에는 해당 image에 대한 자세한 라벨 정보들이 포함돼있음
4. EDA
EDA는 크게 이미지당 bbox 개수, bbox label, bbox 형태를 중점적으로 진행함.(김대근 캠퍼님께서 해주셨다)
-
이미지당 bbox 개수 분포 분석
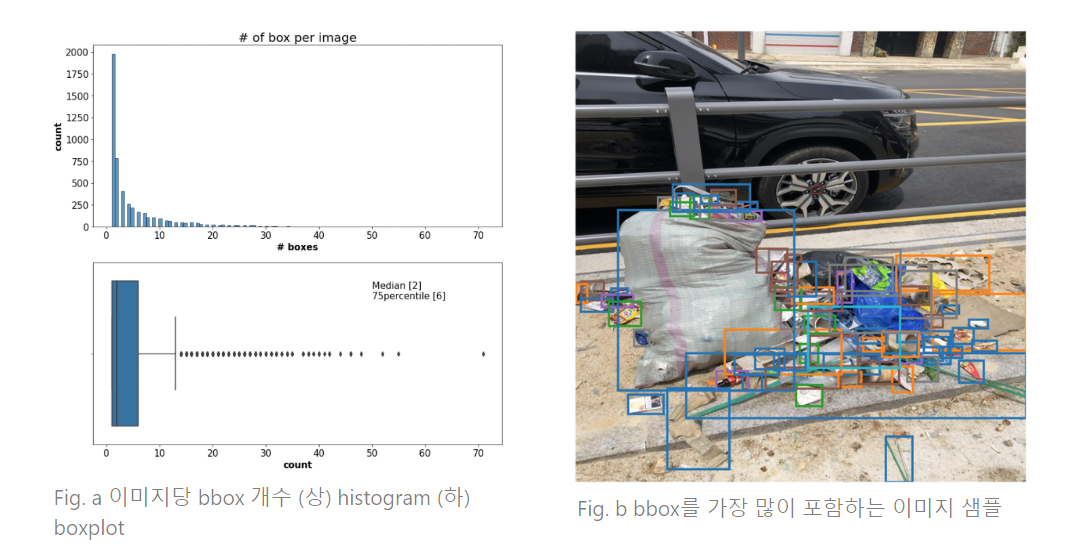
- 이미지당 bbox 개수의 경우 극단적으로 많은 수를 가진 이미지가 존재하는 것을 확인할 수 있었으며, 중앙값은 2, 75분위수는 6, 전통적인 방식으로 찾은 outlier 기준은 11개로 확인됨
- Fig. b 예시에서 볼 수 있듯 육안으로 관찰했을 때 bbox가 많은 이미지의 경우 bbox가 겹치는 부분이 많았고 작은 개체가 많은 것을 확인할 수 있었음
-
Bbox target label 분포 분석
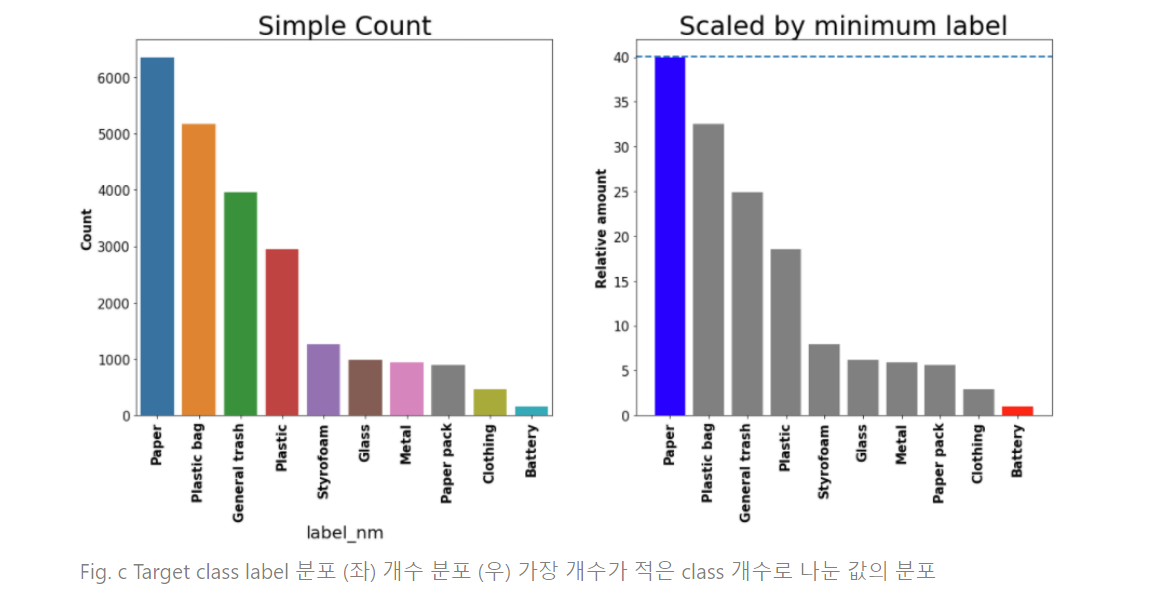
- 개수 상위 4개 class의 경우 하위 6개에 비해 수가 많은 것을 확인할 수 있었으며 가장 많은 paper class는 가장 적은 battery class에 약 40배에 육박함
- 높은 class imbalance가 있다고 판단할 수 있음
-
Bbox의 크기와 형태에 대한 분석
- 모든 class에서 극단적으로 작은 bbox가 관찰되었으며, 빈도 상위 4개 의 경우 극단적으로 큰 크기의 bbox도 많이 관찰됨
- Bbox 높이, 너비 모두 굉장히 크거나 작은 bbox가 관찰되었으며 전반적으로 작은 bbox가 더 많이 분포하는 것을 관찰할 수 있었음
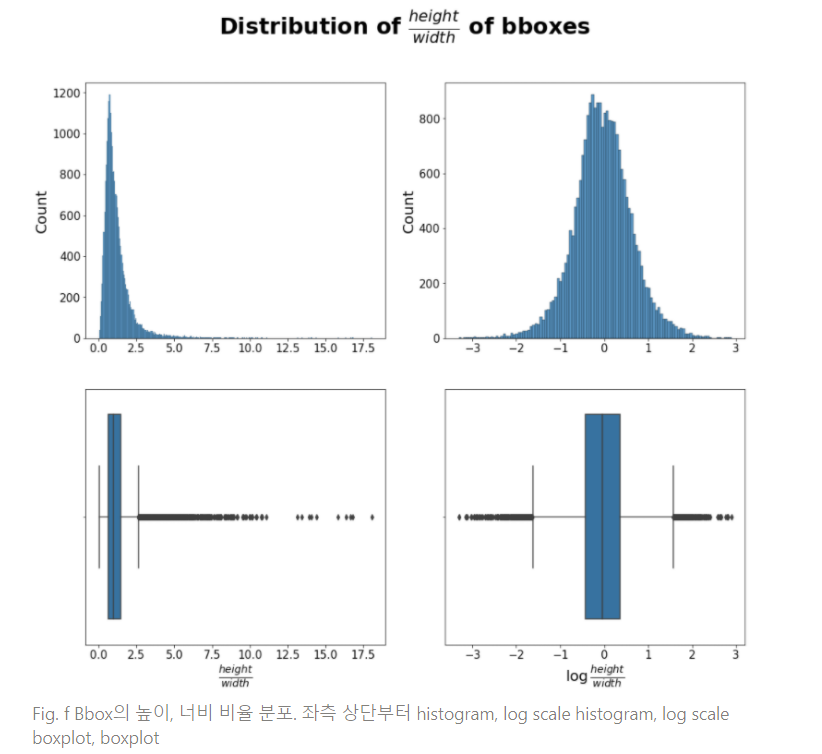
- Bbox의 높이, 너비 비율의 경우 log scale을 적용했을 때 정규분포에 근접한 형태를 보였음
- Log scale 값을 boxplot 형태를 취해본 결과 약 -1.5 ~ 1.5 범위를 넘어서는 경우 outlier로 판정할 수 있었으며 이는 환산했을 때 높이-너비의 비율이 약 5배 이상 차이나는 경우임
-
Data level modification 전략
- Dataset set version
- v1 : StratifiedGroupedKFold (from sklearn)
- https://stages.ai/competitions/178/discussion/talk/post/1205
- .json이 아닌 내부 코드 기반 변경 형식으로 인한 사용 불편함으로 많이 사용되지 않음
- v2 : Multilabel KFold https://stages.ai/competitions/178/discussion/talk/post/1203
- 높은 pearson correlation score를 보임
- v3 : Class 별 bbox 개수를 이용한 배타적 이분 전략
- Fig. c를 기반으로 하여 Bbox 빈도 상위 4개, 하위 6개를 배타적으로 분리함
- 일반적인 class imbalance problem과는 다르게 개수가 적은 class가 높은 탐지 성능을, 많은 class가 낮은 탐지 성능을 보여 추가적 분석 하지 않음
- v4 ~ 5 : 탐지가 어려운 class와 쉬운 class의 배타적 이분 전략
- 하위 카테고리
- v4: 팀 내 가장 탐지 성능이 낮았던 일반쓰래기 (#0)와 나머지로 데이터 분리
- v5: 팀 내 가장 탐지 성능이 낮았던 일반쓰래기 (#0), 플라스틱 (#5) 와 나머지로 데이터 분리
- 목표 여러 문제를 최적화하는 것에 모델의 복잡도가 충분하지 않다면 모델을 복수로 사용하여 복잡도를 증대시키고 일부 문제에 집중할 수 있도록 하기 위함
- 관찰
- v2 사용에 비해 v4, v5 사용에 validation mAP50 기준 약 13, 17% 증가하는 결과를 확인
- Hard task, Easy task가 각각 초반 epoch, 후반 epoch에서 best validation score를 보임
- 해석 과적합을 피하기 위한 best epoch이 차이나는 것을 볼 때, hard task는 상대적으로 쉽게 과적합이 일어나는 것으로 보임. 따라서 두 모델이 서로다른 epoch으로 최적화 타이밍을 같도록 유동성을 준 것이 일반화 성능 증대의 원인일 가능성이 있다고 판단됨
- 한계 모델, Augmentation, train-validation split의 랜덤성에 대한 강건함을 보장할 수 없음
- 하위 카테고리
- v6 ~ 7 : Outlier 제거 전략
- 하위 카테고리
- v6: Fig. a에 기반하여 이미지 내 bbox가 11개를 초과하는 이미지를 제거
- v7: Fig. f에 기반하여 Bbox의 인 bbox를 제거한 뒤, Fig. a에 기반하여 이미지 내 bbox가 11개를 초과하는 이미지를 제거
- 목표 데이터 내 outlier 제거를 통해 과적합을 피하고 noise를 학습할 가능성을 낮추도록 함
- 관찰 v2 validation set 기준하에서, 가설과는 반대로 v2(제거 없음), v6(보통 정도 제거), v7 (가장 많은 제거) 순으로 높은 성능을 보임
- 해석
- 공통된 validation으로 사용한 v2 set의 경우 이런 outlier가 존재 때문에 성능 차이가 난 것으로 추측됨
- v7의 경우 v2에 비해 반절 수준의 bbox를 가지게 되는데, 이런 데이터의 양적 감소가 모델 학습에 충분하지 않았을 가능성이 존재
- 한계
- 모델, Augmentation, train-validation split의 랜덤성에 대한 강건함을 보장할 수 없음
- 공통 평가 방식인 v2 validation set이 LB score를 충분히 잘 반영한다는 가정하에 의미가 있는 결과임
- 하위 카테고리
- v1 : StratifiedGroupedKFold (from sklearn)
- Validation set 평가 방법
- Pearson Correlation (validation mAP50 - public leader board mAP50) Validation set v2에서 0.9582의 높은 수치를 보임
- Spearman Correlation (validation mAP50 - public leader board mAP50) 모든 validation set 전략의 pearson correlation이 낮을 경우 대체 평가방식으로 고려하였으나, validation set v2의 pearson correlation이 충분히 높아 사용하진 않음
- Pearson Correlation (validation mAP50 - public leader board mAP50) Validation set v2에서 0.9582의 높은 수치를 보임
- Dataset set version
5. What I did
Baseline model
-
Library : MMdetection
-
아키텍쳐 : Universenet101
-
LB(mAP50) : 0.5962
-
dataset
- Dataset version 2
-
Augmentation
-
Train
- HorizontalFlip
- VerticalFlip
- RandomRotate90
- HueSaturationValue
- Blur
- RandomBrightness
- RandomFog
- Multiscale
-
Valid
- Normalize()
-
-
LR scheduler : StepLR
-
Loss
- loss_cls : QualityFocalLoss
- loss_dfl : DistributionFocalLoss
- loss_bbos : GIoULoss
-
Optimizer : SGD
-
TTA(Test Time Augmentation)
- multiscale : [(2048,2048), (1536, 1536), (1536, 1024), (1024, 1536), (1024, 1024), (1536, 768), (768, 1536), (768, 768), (1024, 768), (768, 1024)]
- HorizontalFlip , VerticalFlip
-
아키텍쳐는 MMDetection을 기반으로 SOTA 논문이 구현돼있는 UniverseNet을 사용
dataset은 CV를 위한 Multilabel K-Fold를 적용하여 LB와 상관관계가 있는 fold를 사용. 이를 검증하기 위하여 스프레드시트를 만들어서 팀원들과 각자 모델의 val map와 public map 점수를 기록하여 적합한 CV인지 검증함.
optimizer는 adam과 adamW를 사용해봤지만, SGD보다 성능이 좋지 않았음. 또한 가장 최적의 Learning rate를 찾기 위해 실험을 가장 많이함.
Learning rate Scheduler는 CosineAnnealingWarmRestarts, CosineAnnealingLR, Cyclic, Step 이 네가지를 비교하며 실험하여 사용. 이 중 Step의 성능이 가장 좋았음.
augmentation은 HorizontalFlip, VerticalFlip, RandomRotate90을 base로 RandomBrightness만 사용. 이후 kaggle의 object detection solution을 보면서 상위 팀들이 대부분 hard augmentation을 사용한 것을 보고 여러 augmentation을 추가하며 실험해봄.
6. Result
Augmentation
-
RandomBrightness
-
A.OneOf(RandomBrightness, RandomFog, HueSaturationValue, Blur)
-
A.OneOf(RandomBrightness, RandomFog, HueSaturationValue), Blur
val/bbox_mAP가 3번, 1번, 2번 순으로 높았음.
Validation
MMDetection에서 제공하는 class별 AP와 Public leaderboard를 사용
CV 전략 : dataset v2를 사용하여 어느정도 public과의 상관관계를 찾았기 때문에 v2를 사용
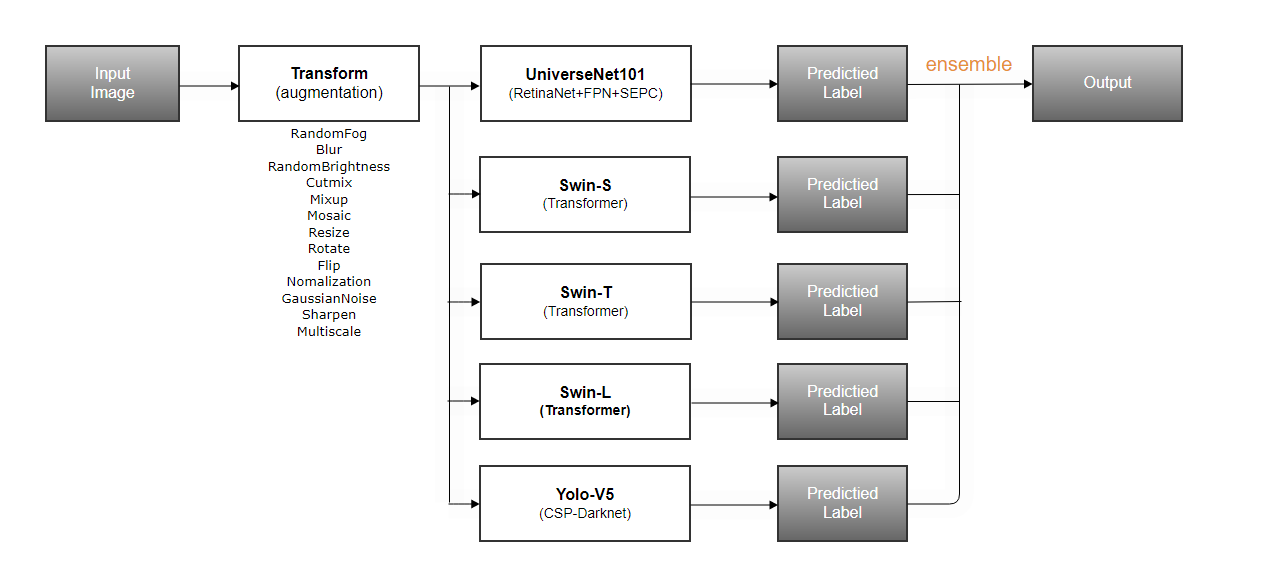
Ensemble
앙상블 목록 : UniverseNet, Yolov5 , swin(small,tiny,large)
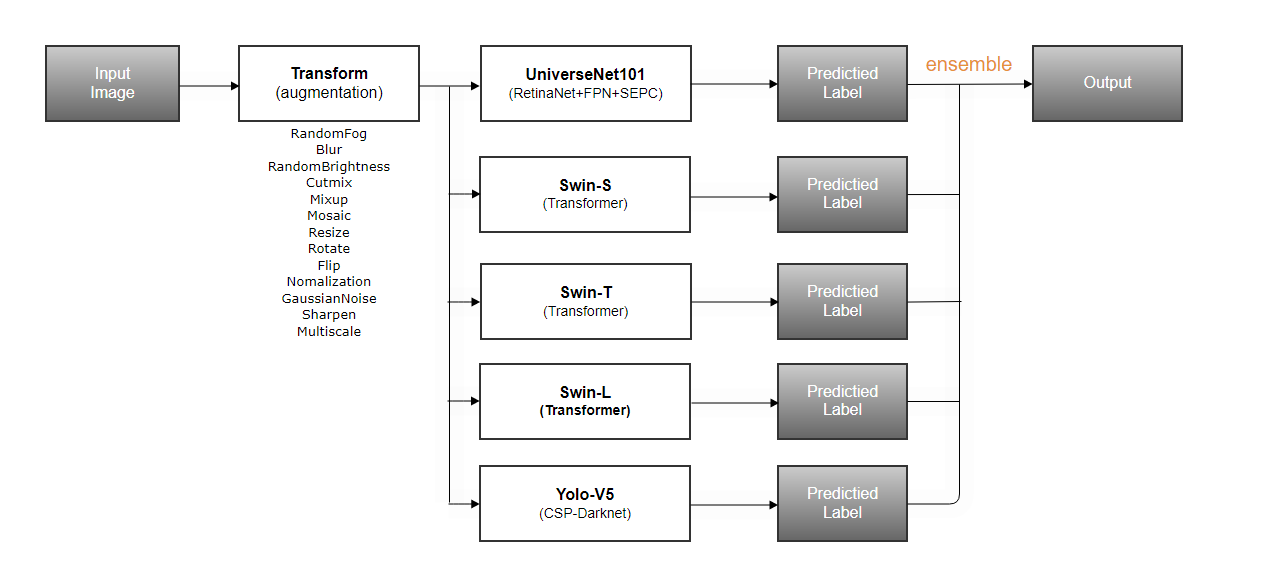
7. Review
SOTA 모델을 가져와서 많은 튜닝을 하며 성능을 끌어올리고자 했습니다. 그 과정에서 파라미터 간의 상관관계(eg. learning rate와 batch_size)가 있다는 사실을 새롭게 알 수 있었지만, 단순히 파라미터 값만 바꿔가며 실험을 한 것이 아쉬웠습니다. 왜냐하면 시간이 너무 많이 걸렸고, 실험이 끝난 이후 유의미한 결과를 얻었을 때 이 결과가 왜 유의미한지 정확한 이유를 알 수 없었기 때문이었습니다. EDA 및 아키텍처에 대한 논문을 통해 충분한 조사를 기반으로 실험을 해야한다는 것을 느끼게 된 계기가 되었습니다.
대회 진행 간 정보를 팀원들과 공유하고자 여러 협업툴(eg. Slack, Git, Notion, Wandb, Google Spreadsheet)을 사용했습니다. 하지만 협업툴에서 공유하고자 하는 바가 명확하지 않아서 각자 다른 목적으로 사용하게 되었고, 이로인해 팀 내 업무파악이 힘들었습니다. 다음 번에는 확실한 그라운드 룰을 정하여 최소한의 협업 툴만 사용해 팀 내부 업무를 파악하고 싶다 느꼈습니다.
가장 큰 아쉬움을 느낀 점은 팀 단위로 체계적인 계획을 세우지 못했다는 점이었습니다. 팀원들 모두 좋은 성적을 위해 열심히 대회에 참여했지만, 체계적인 플랜을 세우지 않아 효율적인 시간 관리가 되지 않았습니다. 또한 각자 다른 속도로 대회를 진행하다 보니 정보 공유를 해도 바로 적용 및 실험을 못했습니다.
