📌AutoGrad & Optimizer
torch.nn.Module
-
딥러닝을 구성하는 Layer의 base class
-
Input, Output, Forward, Backward 정의
-
학습의 대상이 되는 parameter(tensor) 정의
nn.Parameter
-
Tensor 객체의 상속 객체
-
nn.Module 내에 arrtibute가 될 때는 required_grad = True로 지정되어 학습 대상이 되는 Tensor
-
우리가 직접 지정할 일은 잘 없음
:대부분의 layer에는 weights 값들이 지정되어 있음

Backward
-
Layer에 있는 Parameter들의 미분을 수행
-
Forward의 결과값 (model의 output = 예측치)과 실제값간의 차이(loss)에 대해 미분을 수행
-
해당 값으로 Parameter 업데이트

optimizer.zero_grad(), loss.backward(), optimizer.step()
-
optimizer.zero_grad(): 이전 step에서 각 layer 별로 계산된 gradient 값을 모두 0으로 초기화 시키는 작업입니다. 0으로 초기화 하지 않으면 이전 step의 결과에 현재 step의 gradient가 누적으로 합해져서 계산 -
loss.backward(): 각 layer의 파라미터에 대하여 back-propagation을 통해 gradient를 계산 -
optimizer.step(): 각 layer의 파라미터와 같이 저장된 gradient 값을 이용하여 파라미터를 업데이트. 이 명령어를 통해 파라미터가 업데이트되어 모델의 성능이 개선.
optimizer.step()을 통한 파라미터 업데이트와 loss.backward()와의 관계
-
weight를 업데이트 하는 시점은
optimizer.step()이 실행되는 시점 -
가중치 갱신 순서 : 뉴럴네트워크의 출력값과 라벨 값을 loss 함수를 이용하여 계산을 하고 그 loss 함수의
backward()연산을 한 뒤에optimizer.step()을 통해 weight를 업데이트
criterion = nn.CrossEntropyLoss() out = model(input) loss = criterion(out, target) loss.backward() optimizer = optim.Adam(model.parameters(), lr=lr) optimizer.step()
<순서>
1. loss 계산
2. loss.backward()로 gradient 계산
3. optimizer.step()으로 wight 갱신
✍그렇다면 loss와 optimizer는 어떤 관계로 연결되어 있어서 loss를 통해 계산한 gradient를 optimizer로 가중치 갱신을 할 수 있을까?
👉 위의 코드를 보면 loss와 optimizer의 연결 포인트는 딥러닝 네크워크가 선언된 객체인 model의 각각이 가지고 있는 weight의 gradient 값. 입니다.
model의 layer 중 하나의 이름이 layer1 이라 하면, gradient가 저장되는 시점은 loss.backward()가 실행되는 시점이고, gradient는 model.layer1.weight.grad에 저장됩니다.
optimizer 객체는 model.parameter()를 통해 생성되었기 때문에 loss.backward()를 통해 model.layer1.weight.grad에 저장된 gradient는 optimizer에서 바로 접근하여 사용 가능합니다.
따라서!! optimizer와 loss.backward()는 같은 model 객체를 사용하고 loss.backward()의 출력값이 각 model 객체 layer들의 grad 멤버 변수에 저장되고 이 값을 optimizer의 입력값으로 다시 사용함으로써 두 연산이 연결하게 됩니다.
gradient를 직접 zero로 셋팅하는 이유와 활용 방법
-
weight에 계산된 gradient를 0으로 셋팅하는 함수가 있습니다. 이 함수를 사용하는 이유는 기본적으로 어떤 weight의 gradient를 계산하였을 때, 그 값이 기존 gradient를 계산한 값에 누적 되기 때문입니다.
-
대표적으로
optimizer.zero_grad()를 이용하여 optimizer에 연결된 weight들의 gradient를 모두 0으로 만드는 방법이 있습니다.
Further Question
-
epoch에서 이뤄지는 모델 학습 과정을 정리해보고 성능을 올리기 위해서 어떤 부분을 먼저 고려하면 좋을지 같이 논의해보세요.
모델의 구조 및 성능, loss function을 우선 고려. 이후 옵티마이저 및 하이퍼파라미터 조정을 통해 성능을 향상시킨다.
-
optimizer.zero_grad()를 안하면 어떤 일이 일어날지 그리고 매 batch step마다 항상 필요한지 같이 논의해보세요.
기울기가 누적이 되어 올바른 역전파가 되지 않는다.
📌Dataset & Dataloader
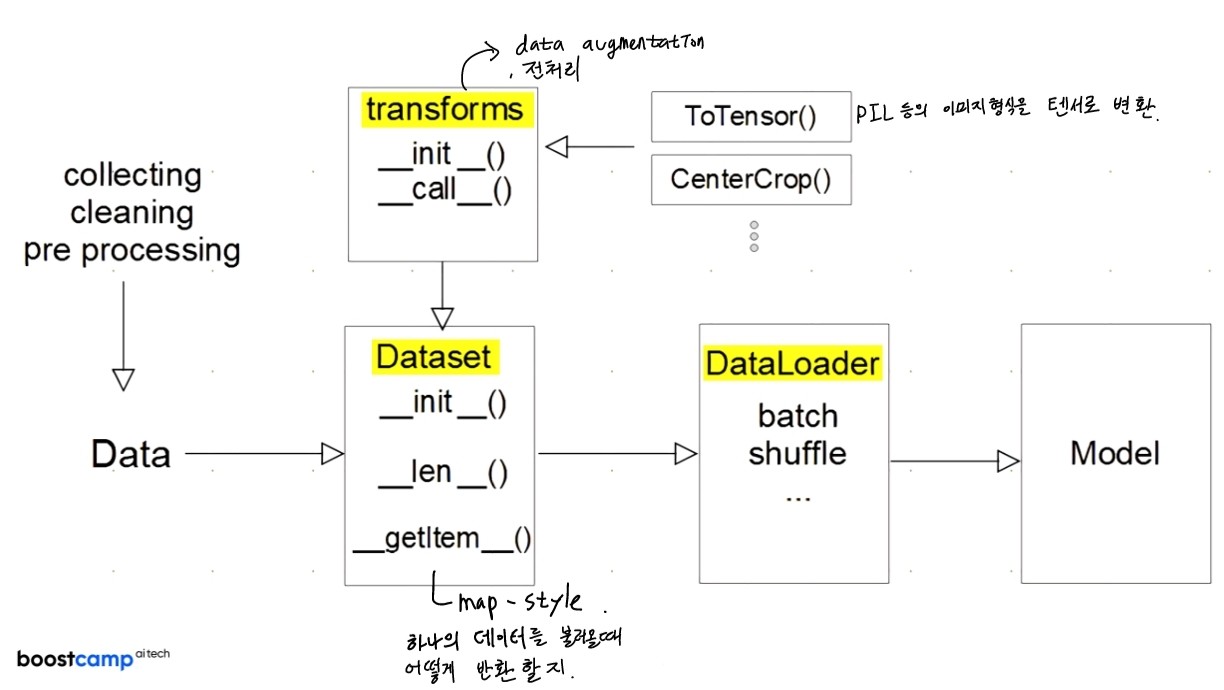
Dataset 클래스
-
데이터 입력 형태를 정의하는 클래스
-
데이터를 입력하는 방식의 표준화
-
Image, Text, Audio 등에 따른 다른 입력정의
-
torch의 Dataset을 상속받는 CustomDataset class는 init, len, getitem으로 구성된다.

Dataset 클래스 생성시 유의점
-
데이터 형태에 따라 각 함수를 다르게 정의함
-
모든 것을 데이터 생성 시점에 처리할 필요는 없음
: image의 Tensor 변화는 학습에 필요한 시점에 변환 -
데이터 셋에 대한 표준화된 처리방법 제공 필요
후속 연구자 또는 동료에게는 빛과 같은 존재 -
최근에는 HuggingFace등 표준화된 라이브러리 사용
DataLoader 클래스
-
Data의 Batch를 생성해주는 클래스
-
학습직전(GPU feed전) 데이터의 변환을 책임
-
Tensor로 변환 + Batch 처리가 메인 업무
-
병렬적인 데이터 전처리 코드의 고민 필요


- dataset :
torch.utils.data.Dataset의 객체를 사용- Map-style dataset : index가 존재하여 data[index]로 데이터를 참조할 수 있다.
__getitem__과__len__선언 필요 - Iterable-style dataset : random으로 읽기에 어렵거나, data에 따라 batch size가 달라지는 데이터(dynamic batch size)에 적합.
__iter__선언 필요
- Map-style dataset : index가 존재하여 data[index]로 데이터를 참조할 수 있다.
-
batch_size : int, optional, default=1
- 배치(batch)의 크기, dataset에서 return하는 데이터는 tensor이므로 만약 tensor로 변환이 안되는 데이터는 에러가 난다.
-
shuffle : bool, optional, default=False
- 데이터를 DataLoader에서 섞어서 사용하겠는지를 설정
-
sampler : Sampler, Iterable, optional
- 데이터의 index를 원하는 방식대로 조정. map-style에서 컨트롤하기 위해 사용된다.
-
batch_sampler : Sampler, Iterable, optional
- 샘플러와 비슷하지만 한 번에 인덱스 배치를 반환
-
num_workers : int, optional, default=0
- 데이터 로딩에 사용하는 subprocess개수 (멀티프로세싱)
- 기본값이 0인데 이는 data가 main process로 불러오는 것을 의미한다.
-
collate_fn : callable, optional
- map-style 데이터셋에서 sample list를 batch 단위로 바꾸기 위해 필요한 기능. zero-padding이나 Variable Size 데이터 등 데이터 사이즈를 맞추기 위해 많이 사용한다.
-
pin_memory : bool, optional
- True 일 때 데이터로더는 Tensor를 CUDA 고정 메모리에 올린다.
-
drop_last : bool, optional
- batch 단위로 데이터를 불러올 때 마지막에 남는 batch의 길이가 설정한 batch보다 작을 경우 사용. 특히 batch의 길이가 다른 경우에 따라 loss를 구하기 귀찮은 경우, batch의 크기에 따른 의존도 높은 함수를 사용할 경우
-
time_out : numeric, optional, default=0
- 양수로 주어지는 경우, DataLoader가 data를 불러오는데 제한시간
-
worker_init_fn : callable, optional, default=’None’
- num_worker가 개수라면, 이 파라미터는 어떤 worker를 불러올 것인가를 리스트로 전달
- num_worker가 개수라면, 이 파라미터는 어떤 worker를 불러올 것인가를 리스트로 전달
Further Question
-
DataLoader에서 사용할 수 있는 각 sampler들을 언제 사용하면 좋을지 같이 논의해보세요!
sampler는 데이터의 index를 원하는 방식대로 조정한다. 즉, index를 컨트롤할 수 있기 때문에 시계열 데이터를 사용할 때 활용할 수 있지 않을까...?
-
데이터의 크기가 너무 커서 메모리에 한번에 올릴 수가 없을 때 Dataset에서 어떻게 데이터를 불러오는게 좋을지 같이 논의해보세요!
배치사이즈 조정, multi GPU 사용
📌피어세션
-
further question 논의
-
알고리즘 : Bellman-ford 알고리즘
- 푼 사람이 없어서 시간을 가지고 풀기로..
📌Day7 회고
- 과제1,2 빨리 해야한다...
