📌모델 불러오기
학습 결과를 공유하고 싶다 학습 결과를 저장할 필요가 있다.
model.save()
-
학습의 결과를 저장하기 위한 함수
-
모델 형태(architecture)와 파라미터를 저장
-
모델 학습 중간 과정의 저장을 통해 최선의 결과 모델을 선택
-
만들어진 모델을 외부 연구자와 공유하여 학습 재연성 향상
-
PyTorch에서는 모델을 저장할 때 .pt 또는 .pth 확장자를 사용하는 것이 일반적인 규칙

코드를 보면서 실습해보자.
간단하게 모델을 만들고, 모델의 state_dict를 출력해 보면 아래 그림과 같다.
( state_dict에 대한 설명. )
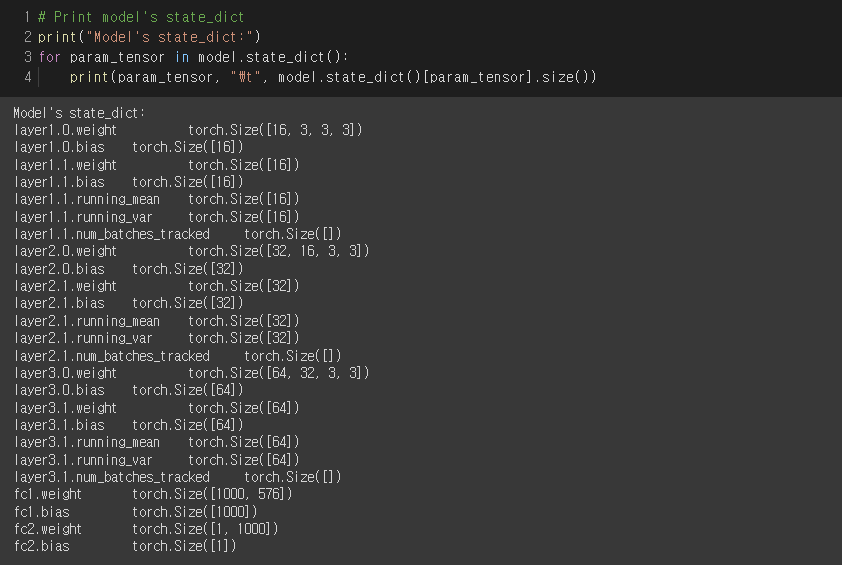
state_dict()의 type을 출력해보면 OrderedDict 타입이 출력된다.
collections 모듈의 OrderedDict 클래스를 사용하면 데이터의 순서를 보장받을 수 있다. 
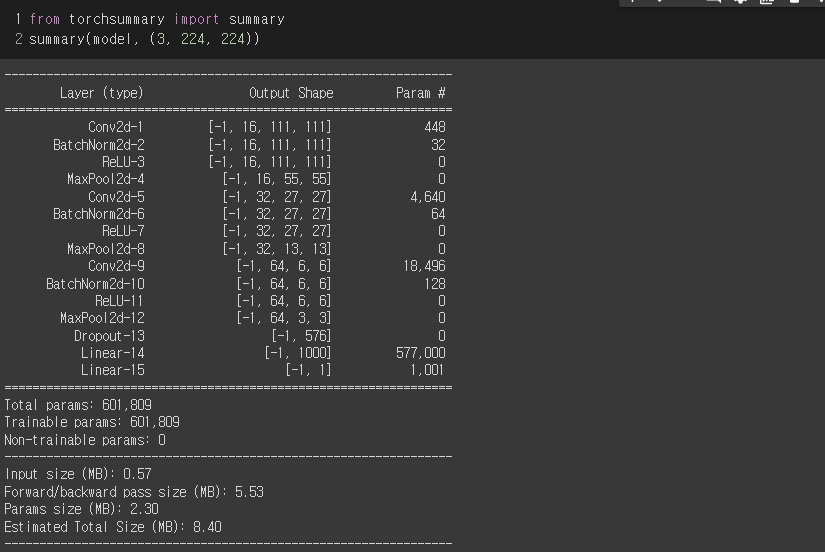
또한 torchsummary 모듈의 summary를 사용하면 다음과 같이 더욱 가시성이 좋게 파라미터를 출력할 수 있다.
summary의 입력 파라미터는 network model, input shape 이다. (torchsummary.summary)
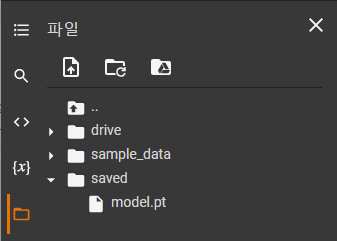
이제 파라미터를 저장해보자. 다음 그림과 같이 "saved"라는 폴더를 생성한 후에 torch.save()를 사용하여 파라미터를 저장할 수 있다.

그렇다면 다음과 같이 "saved"폴더가 생성되고, 그 안에 "model.pt" 파일이 생성된다.
모델을 다시 부르고 싶다면, 동일한 코드로 동일한 모델을 아래 그림과 같이 만들고
model.load_stat_dict()를 하면 된다.
주의할 점은 load_state_dict() 함수에는 저장된 객체의 경로가 아닌, 사전 객체를 전달해야 한다. 따라서 저장된 state_dict 를 load_state_dict() 함수에 전달하기 전에 반드시 역직렬화 를 해야 한다. 예를 들어, model.load_state_dict(PATH) 과 같은 식으로는 사용하면 안된다!!!

다른 방법으로는 모델 전체를 저장하는 방법이 있다. 이 방법과 위의 방법의 차이점은 모델 전체를 저장하느냐, 모델의 state_dict만 저장하느냐 이다. (모델 저장 방법)

checkpoints
-
학습의 중간 결과를 저장하여 최선의 결과를 선택
-
earlystopping 기법 사용시 이전 학습의 결과물을 저장
-
loss와 metric 값을 지속적으로 확인 저장
-
일반적으로 epoch, loss, metric을 함께 저장하여 확인
-
모델이 학습을 하며 갱신되는 버퍼와 매개변수가 포함된 옵티마이저의 state_dict 도 함께 저장하는 것이 중요
-
마지막 에폭(epoch), 최근에 기록된 학습 손실, 외부 torch.nn.Embedding 계층 등도 함께 저장
-
이와 같이 여러가지 매개변수들을 함께 저장하려면, 사전(dictionary) 자료형으로 만든 후 torch.save() 를 사용하여 직렬화 한다.
-
항목들을 불러올 때에는 먼저 모델과 옵티마이저를 초기화한 후, torch.load() 를 사용하여 사전을 불러온다.. 이후로는 저장된 항목들을 사전에 원하는대로 사전에 질의하여 쉽게 접근할 수 있다.

( 더 자세한 내용은 PyTorch Tutorial 을 참고하자. )
( EarlyStopping, Pytorch lightning 튜토리얼 도 읽어보자 )
Pretrained model & Transfer learning
Transfer learning
- 다른 데이터셋으로 만든 모델을 현재 데이터에 적용
-
일반적으로 대용량 데이터셋으로 만들어진 모델의 성능
-
현재의 DL에서는 가장 일반적인 학습 기법
-
backbone architecture가 잘 학습된 모델에서 일부분만 변경하여 학습을 수행함

📌📌Monitoring tools for PyTorch
Tensorboard
-
TensorFlow의 프로젝트로 만들어진 시각화 도구
-
학습 그래프, metric, 학습 결과의 시각화 지원
-
PyTorch도 연결 가능 DL 시각화 핵심 도구
-
scalar : metric 등 상수 값의 연속(epoch)을 표시
-
graph : 모델의 computational graph 표시
-
histogram : weight 등 값의 분포를 표현
-
Image : 예측 값과 실제 값을 비교 표시
-
mesh : 3d 형태의 데이터를 표현하는 도구

- Tensorboard 기록을 위한 directory 생성. logs라는 디렉토리가 생성된다.
- 기록 생성 객체 SummaryWriter 생성
2.1 SummaryWriter에 기록할 위치 지정writer = SummaryWriter(logs_base_dir) writer.add_type()으로 기록
3.1 add_scaler 함수 : scalar 값을 기록
3.2 Loss/train : loss category에 train 값
3.3 n_inter : x축의 값- 모든 보류중인(pending) 이벤트가 디스크에 기록되었는지 확인하려면
writer.flush()메소드를 호출. Summary writer가 더 이상 필요하지 않으면writer.close()메소드를 호출 %load_ext tensorboard: jupyter 상에서 텐서보드 extension 로드를 위한 magic command
%tensorboard --logdir {logs_base_dir}: 위에서 사용한 루트 로그 디렉터리를 지정하여 TensorBoard를 시작
weight & biases
-
머신러닝 실험을 원활히 지원하기 위한 상용도구
-
협업, code versioning, 실험 결과 기록 등 제공
-
MLOps의 대표적인 툴로 저변 확대 중
📌피어세션
-
과제 리뷰
-
과제가 너무 힘들었다...
-
몸 건강히 챙기자 다들...
📌Day9 회고
-
과제 하다가 밤새서 첫 지각...
-
오피스아워에서 과제 리뷰를 해줬는데, 한 번씩 싹다 정리해야 겠다....
-
설날 다가오니까.. 좀만 더 빡세게 굴리자!!
