본 포스트는 인프런의 "파이썬 동시성 프로그래밍 : 데이터 수집부터 웹 개발까지 (feat. FastAPI)" 강의를 듣고 회고 목적으로 작성하였습니다.
📌컴퓨터 구조와 운영체제 기본
-
컴퓨터의 구성 요소
-
CPU : 명령어를 해석하여 실행하는 장치
-
메모리
- 주메모리 : 작업에 필요한 프로그램과 데이터를 저장하는 장소(RAM)
- 보조메모리 : 저장장치라고 불리며 데이터를 일시적 또는 영구적으로 저장하는 장소
-
입출력장치
-
시스템버스
-
-
운영체제(OS) : 컴퓨터 시스템을 운영하고 관리하는 소프트웨어
-
운영체제가 없는 컴퓨터는 처음에 설계한 대로만 사용할 수 있는 단순 계산기에 불과하다.
-
운영체제가 있는 컴퓨터를 프로그램이 가능한 기계라고 한다.
-
WindowOS, MacOS, Ubuntu
-
-
프로세스
-
프로그램 : 어떤 문제를 해결하기 위해 컴퓨터에게 주어지는 처리 방법과 순서를 기술한 일련의 명령문(개발자가 작성한 코드)의 집합체
-
프로그램은 HDD, SDD와 같은 저장장치에 보관되어 있다. 사용자는 어떤 이유로 프로그램을 실행하기 위해 프로그램 바로가기 버튼을 눌러서 실행시킨다.
-
프로그램이 실행된다? 해당 프로그램의 작성된 코드들이 주메모리로 올라왓 작업이 진행된다. 프로세스가 생성되면 CPU는 프로세스가 해야할 작업을 수행한다.
- 즉, 프로그램은 저장장치에 저장된 정적인 상태이고
프로세스는 실행을 위해 주메모리에 올라온 동정인 상태이다.
- 즉, 프로그램은 저장장치에 저장된 정적인 상태이고
-
-
스레드
-
프로세스가 생성되면 CPU는 프로세스가 해야할 작업을 수행한다. 이때 CPU가 처리하는 작업의 단위가 바로 스레드이다.
즉, 스레드란 프로세스 내에서 실행되는 여러 작업의 단위 -
스레드가 한 개로 동작하면 싱글 스레드, 여러 개의 스레드가 동작하면 멀티 스레딩
- 멀티 스레딩에서 스레드는 다수의 스레드끼리 메모리 공유와 통신이 가능하다.
자원의 낭비를 막고 효율성을 향상
But, 한 스레드에 문제가 생기면 전체 프로세스에 영향을 미친다.
- 멀티 스레딩에서 스레드는 다수의 스레드끼리 메모리 공유와 통신이 가능하다.
-
종류: 사용자 수준 스레드, 커널 수준 스레드
-
📌동시성 vs 병렬성
- 동시성(Concurrency) : 한 번에 여러 작업을 동시에 다루는 것을 의미.
- 병렬성(Parallelism) : 한 번에 여러 작업을 병렬적으로 처리하는 것을 의미.
뜻만 보면 이해하기가 어렵다.. 둘다 비슷해 보인다
이해를 위해 한 가지 예시를 들어보자
요리하는 AI 로봇 자비스가 있다. 자비스는 라면 주문이 들어오면 물을 끓이고 수프를 넣고 야채를 넣고 면을 넣는다.
그렇다면, 만약 음식 주문이 한 번에 3개가 왔다면? (라면, 파스타, 케익)
- 동시성으로 작업 시작!!
- 라면 물을 끓이는 동안 옆으로 가서 케이크의 밀가루 반죽을 한다. 그리고 물이 아직 안끓었으니 파스타 요리의 재료 손질을 한다.
이제 라면 물이 다 끓었다면, 자비스는 라면에 면과 스푸를 넣어서 라면을 끓인다. 그리고 오븐에 케익 반죽을 넣고 오븐안의 케이크가 만들어 지는 동안 파스타를 요리한다. - 즉, 로봇 자비스는 혼자서 여러 음식을 만들기 위해 스위칭을 하며 요리를 했다.
- 라면 물을 끓이는 동안 옆으로 가서 케이크의 밀가루 반죽을 한다. 그리고 물이 아직 안끓었으니 파스타 요리의 재료 손질을 한다.
- 병렬성으로 작업 시작!!
- 가게 사장은 요리하는 AI 로봇 마이크와 프라이데이를 추가했다!
- 자비스는 라면을, 마이크는 케이크를, 프라이데이는 파스타를 동시에 만들기 시작한다!
즉, 동시성은 논리적 개념으로 멀티 스레딩에서 사용되기도 하고 싱글 스레드에서 사용되기도 한다. 또한 싱글 코어 뿐만 아니라 멀티 코어에서도 각각의 코어가 동시성을 사용할 수 있다.
지난 포스팅에서 asyncio 패키지를 가지고 했던 프로그래밍이 바로 싱글스레드 동시성 프로그래밍이다.
병렬성은 물리적 개념으로 예시에서 여러 로봇들이 여러 작업을 병렬로 수행한 것처럼, 멀티 코어에서 여러 작업을 병렬적으로 수행한다.
그리고 병렬성에서 동시성이 공존할 수 있다. 예를 들어 요리가 10개가 주문이 들어왔다고 생각해 보자. 그럼 각각의 로봇들은 10개의 요리를 각자 나눠서 요리를 시작할 것이다.(3개 3개 4개 처럼) 그렇다면 각각의 로봇들은 병렬성을 지키면서 동시성을 따르며 요리를 할 수 있다.
📌파이썬 멀티 스레딩
파이썬 멀티 스레딩을 실제로 구현해보자.
지난 포스팅에서 했던 코드를 가져와서 사용할 것이다.
import requests
import time
import os
import threading
def fetcher(session, url):
print(f"{os.getpid()} process | {threading.get_ident()} url : {url}")
with session.get(url) as response:
return response.text
def main():
urls = ["https://google.com", "https://apple.com"] * 50
with requests.Session() as session:
result = [fetcher(session, url) for url in urls]
print(result)
if __name__ == "__main__":
start = time.time()
main()
end = time.time()
print(end - start) # 19코드를 보면 추가된 것이 os.getpid() 와 threading.get_ident() 메소드이다.
os와 threading 패키지는 파이썬 안에 내장되어 있는 패키지 이다. 자세한 내용이 궁금하다면 파이썬 공식 문서를 참고하자.
os.getpid() 메소드는 현재 프로세스의 id를 리턴한다.
threading.get_ident() 메소드는 현재 스레드의 '스레드 ID'를 리턴한다.
위 코드를 실행시키면 다음과 같은 결과가 나오고, 시간은 19초가 걸렸다(시간은 컴퓨터의 사양에 따라 다르게 나온다).
22344 process | 16652 url : https://google.com
22344 process | 16652 url : https://apple.com
22344 process | 16652 url : https://google.com
22344 process | 16652 url : https://apple.com이제 비동기적으로 위 코드를 돌려보자!! 코드는 역시 이전 포스팅에서 썻던 코드를 가져다 약간의 수정만 했다.
import aiohttp
import time
import asyncio
import os
import threading
async def fetcher(session, url):
print(f"{os.getpid()} process | {threading.get_ident()} url : {url}")
async with session.get(url) as response:
return await response.text()
async def main():
urls = ["https://google.com", "https://apple.com"] * 50
async with aiohttp.ClientSession() as session:
result = await asyncio.gather(*[fetcher(session, url) for url in urls])
print(result)
if __name__ == "__main__":
start = time.time()
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy()) # WindowOS는 이것을 추가해야 에러가 안뜬다..
asyncio.run(main())
end = time.time()
print(end - start) # 2.4출력되는 시간을 보면 동기적으로 코드를 돌렸을 때에 비해서 많이 줄어들었다.
동기적 코드에서는 구글에 요청을 보내고 응답을 받을 때 까지 기다리고, 응답을 받았으면 애플에 요청을 보내고 응답을 기다리고 .... 반복을 했다.
그에 비해 비동기적 코드는 구글에 요청을 보내고 await response.text()로 탈출을 한다. 그리고 다른 코루틴인 애플로 들어가서 요청을 보내고 다시 탈출하고를 반복한다. 즉, 요청을 하고 응답이 오는 시간동안 다른 예약된 task를 시작한다.
비동기적 코드에서 사용한 aiohttp 패키지는 비동기적 함수를 지원한다. 하지만 만약 동기적 함수를 지원하는 request 패키지를 무조건 써야 하는 상황에서는 비동기 프로그래밍을 어떻게 해야할까?
파이썬 공식 문서에 들어가서 Executor 를 한 번 읽어보자.
공식 문서에 따르면 "Executor 객체는 비동기적으로 호출을 실행하는 메서드를 제공하는 추상 클래스입니다. 직접 사용해서는 안 되며, 구체적인 하위 클래스를 통해 사용해야 합니다" , "ThreadPoolExecutor는 스레드 풀을 사용하여 호출을 비동기적으로 실행하는 Executor 하위 클래스입니다" 라고 한다. 즉, 이름에서 알 수 있듯이 멀티 쓰레딩을 사용하는 것이다. 사용 예시는 다음과 같다.
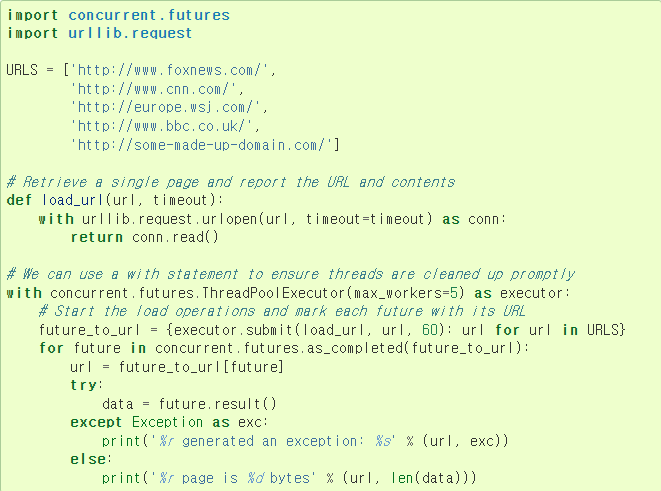
다음 코드를 보자.
import requests
import time
import os
import threading
from concurrent.futures import ThreadPoolExecutor
def fetcher(params):
session = params[0]
url = params[1]
print(f"{os.getpid()} process | {threading.get_ident()} url : {url}")
with session.get(url) as response:
return response.text
def main():
urls = ["https://google.com", "https://apple.com"] * 50
executor = ThreadPoolExecutor(max_workers=1)
with requests.Session() as session:
# result = [fetcher(session, url) for url in urls]
# print(result)
params = [(session, url) for url in urls]
results = list(executor.map(fetcher, params))
print(results)
if __name__ == "__main__":
start = time.time()
main()
end = time.time()
print(end - start) # 4.1코드를 하나하나 분석해보자. 가장 먼저 ThreadPoolExecutor 메소드를 사용하기 위해 concurrent.futures에서 import 하자.
그리고 ThreadPoolExecutor()를 사용하여 executor를 선언하는데, 인자로 max_workers가 들어간다. 이는 최대 스레드를 실행할 개수를 의미한다.
이후 with문으로 세션을 열고 exacutor의 map()메소드를 사용하는데, 이 map() 메소드는 우리가 알고 있는 파이썬 내장함수와 거의 유사하다.
executor.map(fetcher, urls)를 하면 urls에 들어있는 주소가 하나씩 fetcher() 함수에 들어가게 된다. 하지만 원래의 fetcher 함수의 인자는 아래와 같이 session과 url이 있다.
def fetcher(session, url):
pass즉, map을 이용해서 fetcher에 session과 url을 넣어야 하므로 새로운 변수를 선언할 필요가 있었고, 그게 바로 params다. list comprehension을 사용하여 (session, url) 튜플을 원소로 가지는 리스트인 params를 만들고 이를 map()에 넣는다. 하지만 한 가지 문제가 더 발생한다. 이렇게 params의 각 인덱스에 해당하는 값들이 fetcher에 들어갈때는 튜플형태인 (session, url) 형태로 들어가기 때문에 fetcher의 인자를 params로 바꿔주고 fetcher 함수 안에서 튜플을 언패킹 한다.
걸린 시간을 보면 약 4.1초가 걸렸는데 19초에 비해서 확실히 빨라진 모습이다.
주의할 점은 파이썬에서는 멀티 스레딩이 병렬적으로 실행되지 않는다..
📌파이썬 멀티 프로세싱, GIL
위에서 언급했던 것 처럼 프로세스가 생성되면 CPU는 프로세스가 해야할 작업을 수행하고, 이때 CPU가 처리하는 작업의 단위가 바로 스레드이다. 멀티스레딩은 결국 스레드를 여러 개 사용하여 실행하므로 실행속도도 빨라지겠다 생각하겠지만, 전혀 그렇지가 않다. 왜 이러한 현상이 발생하는지 자세히 살펴보자.
-
멀티 스레딩의 단점
-
멀티 스레딩은 스레드끼리 자원을 공유한다. 그런데 하나의 자원을 동시에 여러 스레드가 가져가려는 상황이 발생할 수 있는데 이 경우 충돌이 발생할 수 있다. 이 경우에 하나의 스레드가 다른 스레드에 의해 차단될 수 있다.
-
파이썬의 전역 인터프리터 잠금(GIL, Global Interprrter Lock)은 이러한 문제점을 막는다
-
-
GIL
-
한 번에 1개의 스레드만 유지하는 락
-
GIL은 본질적으로 한 스레드가 다른 스레드를 차단해서 제어를 얻는 것을 막아준다. 멀티 스레딩의 위험으로부터 보호를 하는 것이다.
-
이 때문에 파이썬에서는 스레드로 병렬성 연산을 수항하지 못한다.
- 파이썬 멀티 스레딩은 동시성을 사용하여 io bound 코드에서 유용하게 사용할 수 있지만, cpu bound 코드에서는 GIL에 의해 원하는 결과를 얻을 수 없다.
-
- 멀티 프로세싱
- 멀티프로세싱이란 스레딩 모듈과 유사한 API를 사용하여 프로세스 생성을 지원하는 패키지이다. 멀티프로세싱은 멀티스레딩과 다르게 GIL의 제약을 피할 수 있기 때문에 복수의 프로세서를 활용할 수 있다.
멀티 스레딩은 하나의 프로세스 안에서 여러 스레드가 동시에 작업을 하고, 멀티프로세싱은 CPU가 추가된다. 하지만 멀티 스레딩은 프로세스에 비해 단위가 작기 때문에 생성이 쉽지만, 멀티 프로세싱은 프로세스 생성에 시간이 걸린다.
이제 코드를 보며 이해를 해보는 시간을 가져보자.
import time
import os
import threading
# nums = [50, 63, 32]
nums = [30] * 100
def cpu_bound_func(num):
print(f"{os.getpid()} process | {threading.get_ident()} thread")
numbers = range(1, num)
total = 1
for i in numbers:
for j in numbers:
for k in numbers:
total *= i * j * k
return total
def main():
results = [cpu_bound_func(num) for num in nums]
print(results)
if __name__ == "__main__":
start = time.time()
main()
end = time.time()
print(end - start) # 21.1코드를 보면 cpu_bound_func()은 동기적으로 단순히 계산만 하는, 즉 cpu계산만 하는 함수이다. 이를 실행하면 약 21초가 나온다.
이제 이 코드를 멀티스레딩을 사용하여 돌려보자!!
import time
import os
import threading
from concurrent.futures import ThreadPoolExecutor
nums = [30] * 100
# nums = [50, 63, 32]
def cpu_bound_func(num):
print(f"{os.getpid()} process | {threading.get_ident()} thread, {num}")
numbers = range(1, num)
total = 1
for i in numbers:
for j in numbers:
for k in numbers:
total *= i * j * k
return total
def main():
executor = ThreadPoolExecutor(max_workers=10)
results = list(executor.map(cpu_bound_func, nums))
print(results)
if __name__ == "__main__":
start = time.time()
main()
end = time.time()
print(end - start) # 21.29시간을 보면 21.29초가 나왔다??? 시간이 줄어든것도 아니고 오히려 아주 조금이지만 늘었다.
os.getpid() 와 threading.get_ident() 메소드로 출력되는 프로세스 id와 스레드 id를 확인해보자. 멀티 스레딩을 하기 때문에 이전 코드와 비교해봤을때 스레드 id가 동일하지않은 것을 확인할 수 있다.
자 이 상태에서 코드의 성능을 높일려면? 멀티 프로세싱을 사용하여 병렬로 계산하면 된다!
다음 코드를 보자.
import time
import os
import threading
from concurrent.futures import ProcessPoolExecutor
nums = [30] * 100
def cpu_bound_func(num):
print(f"{os.getpid()} process | {threading.get_ident()} thread, {num}")
numbers = range(1, num)
total = 1
for i in numbers:
for j in numbers:
for k in numbers:
total *= i * j * k
return total
def main():
executor = ProcessPoolExecutor(max_workers=10)
results = list(executor.map(cpu_bound_func, nums))
print(results)
if __name__ == "__main__":
start = time.time()
main()
end = time.time()
print(end - start) # 13멀티 스레딩에서의 코드와 달라진 점은 단지 ThreadPoolExecutor() 메소드가 ProcessPoolExecutor() 메소드로 달라진 점이다. 이 코드는 병렬적으로 돌아가고, 수행 시간도 약 13초로 매우 줄어든 것을 확인할 수 있다.
또한 os.getpid() 메소드로 출력되는 프로세스 id가 다 다른것도 확인 할 수 있다.
참고 : 파이썬 동시성 프로그래밍

대단해요!