
이번 글에서는 저번 회고 때, 고민했던 문제 해결에 대해 작성해보려고 합니다.
이전 글에서 Swagger 적용시 문제점은 크게 2가지가 있었습니다.
1. Swagger UI에서 API자체 테스트시 인증 토큰이 없음에도 테스트가 통과하는 문제
2.views.py에서@swagger_auto_schema의 복잡한 코드로인해 가독성이 떨어지는 문제
1. Swagger UI API 테스트 문제
문제 원인
원인은 간단하게 API 자체 로직에 있었습니다.
이전 로직에서는 인증토큰이 있는지 확인을 해주는 코드 자체가 없던 것으로 확인이 되었고,
아마 로그인되지 않은 상황에서도 사용자의 일부 정보를 확인하기 위해서 그랬던 것 같습니다.
변경 전 views.py 사용자 정보 조회 API
def get(self, request, **kwargs):
if kwargs.get('id') is None:
auth = get_authorization_header(request).split()
if auth and len(auth) == 2:
user = User.objects.filter(pk=token_decode(auth)).first()
return Response(UserSerializer(user).data, status=status.HTTP_200_OK)
raise AuthenticationFailed('Unauthenticated')
else:
user_id = kwargs.get('id')
user_serializer = UserSerializer(User.objects.get(pk=user_id))
response = Response()
user_id = user_serializer.data.get('id')
nickname = user_serializer.data.get('nickname')
profile = user_serializer.data.get('profile')
response.data = {
'id' : user_id,
'nickname' : nickname,
'profile' : profile
}
return responseurl에 사용자의 인덱스 값이 없다면 인증 토큰을 확인하고 사용자의 정보를 반환해주고,
아닌 경우 해당 사용자의 인덱스 값을 통해 인덱스 값인 id와 닉네임, 프로필 이미지를 반환해줘야 한다는 로직이었습니다.
하지만 이번 Swagger의 API테스트 과정에서는 사용자의 정보를 조회할 때, 토큰을 통해 로그인한 사용자인지 확인 과정만 필요했고, 로그인하지 않아도 사용자의 정보를 확인할 필요는 없다고 판단하여 다음과 같이 변경하였습니다.
# views.py
...
# 403 error를 401로 변환
class TokenErrorException(APIException):
status_code = 403
if status_code == 403:
status_code = 401
default_detail = 'unauthenticated'
...
def get(self, request, **kwargs):
auth = get_authorization_header(request).split()
if auth and len(auth) == 2:
user = User.objects.filter(pk=token_decode(auth)).first()
user_serializer = UserSerializer(user).data
user_id = user_serializer['id']
nickname = user_serializer['nickname']
profile = user_serializer['profile']
response = Response()
response.data = {
'id' : user_id,
'nickname' : nickname,
'profile' : profile
}
return response
raise TokenErrorException()
# urls.py
...
urlpatterns = [
...
path('user-info', UserAPIView.as_view()), # 유저 정보 조회/업데이트
...
]로그인된 사용자인지 토큰 여부를 확인하고, 사용자 id 값과 닉네임, 프로필이미지만 반환할 수 있도록 변경했습니다.
또한 APIException 클래스를 활용하여 403에러 코드를 401에러로 변환 시키는 과정도 추가했습니다.
📌 Why?
403 에러는 서버는 해당 요청을 이해했지만 권한이 없어 요청을 거부한 것이기 때문에
권한이 없다는 것은 해당 요청에 대한 자원의 존재 여부를 제공하는 것으로 취약점이 될 가능성이 있습니다.
그래서 '리소스 존재 여부'를 알고 악용하는 공격자에게 이런 힌트를 감추기 위한 목적으로 401에러 코드로 변환시켰습니다.더 이상 사용자의 id로 어떤 사용자인지 구분할 필요가 없고 REST하지 않기 때문에 기존 <int:id>에서 user-info로 엔드포인트도 변경해줬습니다.
2. views.py 가독성 문제
문제원인
@swagger_auto_schema의 반복적이고, 긴 코드
변경 전 views.py 로그인 API
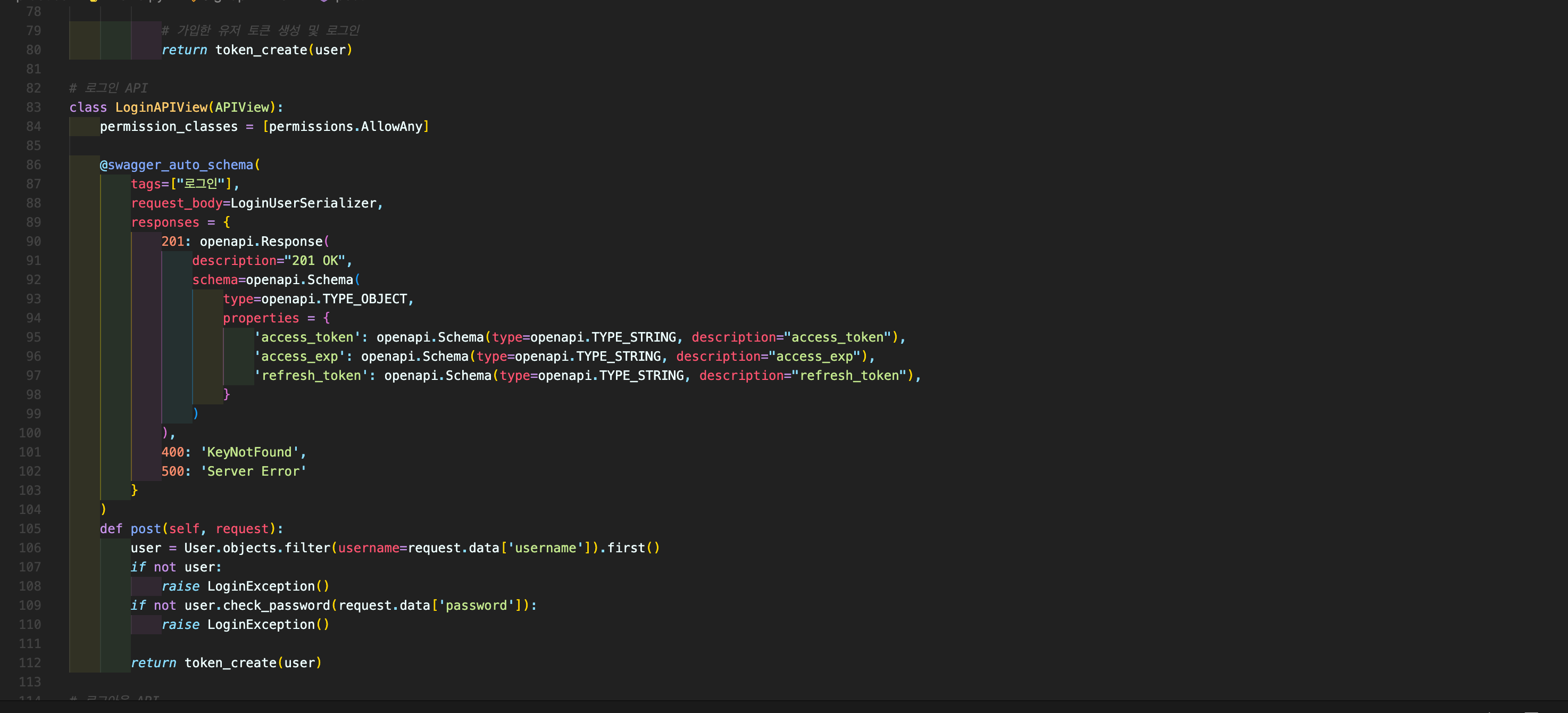 로그인 로직에 비해
로그인 로직에 비해 @swagger_auto_schema 데코레이터의 코드가 더 많은 양의 코드를 가지고 있고, 각 API마다 대부분 반복되는 코드를 가지고 있습니다.
API마다 해당 데코레이터를 가지고 있어서 만약 더 많고 복잡한 API를 다룬다면 기능 로직과 Swagger 설정을 보기 까다로울 것입니다. 이런 비효율성을 해소하고자 나름의 방법으로 다음과 같이 변경했습니다.
# swaggers.py 생성 : @swagger_auto_schema 데코레이터의 모든 내용을 정리
from rest_framework import serializers
from .serializer import UserSerializer
from drf_yasg import openapi
...
# swagger request body custom serializer
# 로그인 request body parameters
class LoginUserSerializer(serializers.Serializer):
username = serializers.CharField(help_text="아이디")
password = serializers.CharField(help_text="패스워드")
...
# 회원가입/로그인 response
SignupResponse = {
201: openapi.Response(
description="201 OK",
schema=openapi.Schema(
type=openapi.TYPE_OBJECT,
properties = {
'access_token': openapi.Schema(type=openapi.TYPE_STRING, description="access_token"),
'access_exp': openapi.Schema(type=openapi.TYPE_STRING, description="access_exp"),
'refresh_token': openapi.Schema(type=openapi.TYPE_STRING, description="refresh_token"),
}
)),
400: 'KeyNotFound',
500: 'Server Error'
}
...가장 먼저 swaggers.py 파일을 새로 생성하여 swagger의 설정을 views.py에서 분리해줬습니다.
이후 request body, header, response 값들을 차례로 정리했고, 로그인과 회원가입 API의 경우 response 값이 같기 때문에 SignupResponse로 합쳐서 코드 중복성을 최소화 했습니다.
다음은 변경 후 views.py 로그인 API입니다.
 한 눈에 보더라도 위 사진과 비교했을 때, 코드의 가독성이 좋아진 것을 확인할 수 있습니다.
한 눈에 보더라도 위 사진과 비교했을 때, 코드의 가독성이 좋아진 것을 확인할 수 있습니다.
swaggers.py에서 호출만 해서 활용만 하면 되기때문에 @swagger_auto_schema의 내용이 한 줄로 요약됩니다.
단점은 swaggers.py를 통해서만 상세한 @swagger_auto_schema 내용을 확인할 수 있다는 점 입니다.
+ 기타 추가 내용
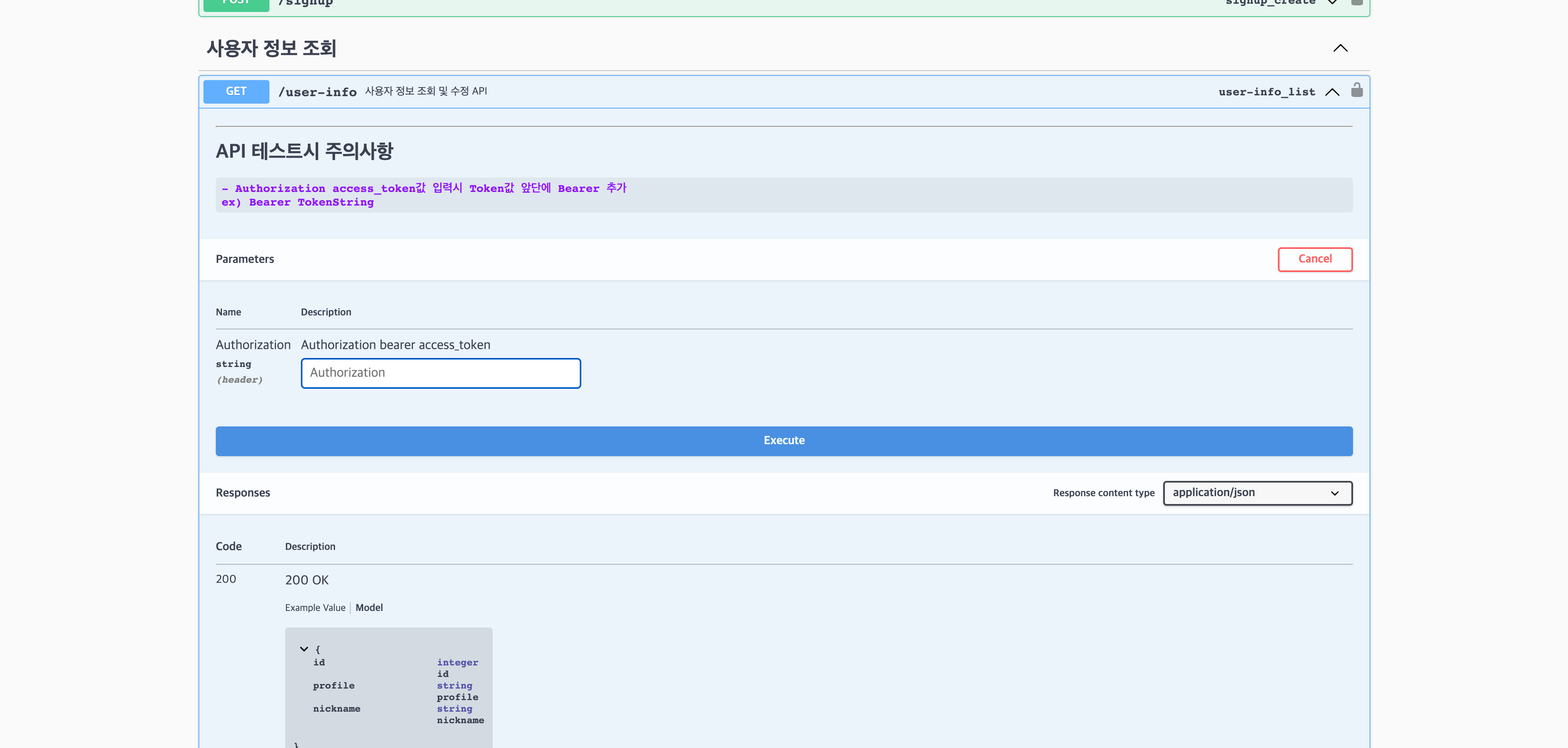
API class와 @swagger_auto_schema 데코레이터 사이에 주석을 추가함으로써 Swagger UI에서 확인할 수 있는 설명을 조금 더 풍부하게 만들어 줄 수 있습니다.
# 유저정보 조회 및 수정 API
class UserAPIView(APIView):
"""
사용자 정보 조회 및 수정 API
---
# API 테스트시 주의사항
- Authorization access_token값 입력시 Token값 앞단에 Bearer 추가
ex) Bearer TokenString
"""
permission_classes = [permissions.AllowAny]
parser_classes=(MultiPartParser,) #이미지 fields 나타나지 않는 에러 해결
# 유저정보 조회
@swagger_auto_schema(tags=["사용자 정보 조회"], manual_parameters=UserinfoHeader, responses = GetUserResponse)이렇게 주석을 작성하게 된다면 Swagger UI에서는 다음과 같이 확인할 수 있습니다.
글을 마치며
전체 코드는 https://github.com/wodnrP/Swagger_practise 에 있습니다.
1번 문제는 실수(?)라고 볼 수 있어서, 좀 더 꼼꼼히 로직을 살펴봐야겠다고 생각했습니다.
2번 문제는 코드 가독성도 어느정도 해결했고, 이후 유지보수적으로도swaggers.py에 따로 분리한 것은 괜찮은 방법이라고 생각해서 앞으로 Swagger를 적용할 때에 잘 응용해야겠다고 생각했습니다.혹여 이렇게 Swagger를 작성했을 때 발생할 수 있는 문제점이 있을 경우 알려주시면 정말 감사하겠습니다.
언제나 의견, 질문, 개선사항 등 전부 환영합니다!
