[ECCV 2022] DeciWatch: A Simple Baseline for 10× Efficient 2D and 3D Pose Estimation
Paper Reading
https://arxiv.org/abs/2203.08713v1
1.Introduction
efficiency를 높이기 위한 더 compact한 model을 design하는 것이다
(a) Compact Network Design for Pose Estimation
(b) Keyframe-Based Efficient Pose Estimation
keyframe 마다 feature extraction을 해야하기 때문에 computational complexity를 낮추기 어렵다
(c) Our Sample-Denoise-Recover Framework (DeciWatch)
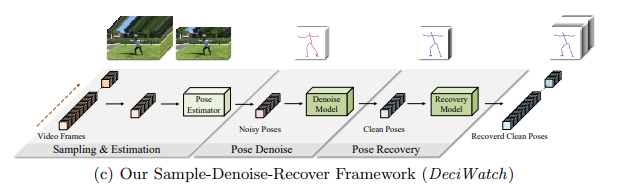
sample-denoise-recover(RecoverNet) framework: DeciWatch
Objective
-
highly efficient video-based pose estimation을 구현하여, pose estimation할 수 없는 frame을 pose recovery 하여 light weight model을 사용할 수 있다.
-
computational cost에 여유가 생겨 occlused pose나 rare action에 대한 pose estimation을 할 수 있다.
-
continuity of human motion을 고려하기 때문에 기존의 기법보다 더 smooth 하다.
-
기존의 Simple Baselines for Human Pose Estimation and Tracking (ECCV 2018)에서 성능 저하 없이 effiency를 10배 향상시켰다.
10%의 video frame을 균일하게 샘플링하고, efficient Transformer architecture를 이용해 측정된 2D/3D pose를 denosing 한다.
2.Related Work
2.1 Efficient Human Pose Estimation
Image-based pose estimator: frame-by-frame으로 pose estimation하지 않아 accuracy가 떨어진다.
Video-based pose estimator: temporal co-dependency among consecutive frames 고려하여 다른 frame 간에 adaptive operation을 취한다. 이에 따른 calculation cost가 크다.
2.2 Motion Completion
specific keyframe constraint로 인해 발생한 absent pose를 complete 한다.
3.Method
3.1 Problem Definition
human motion은 continuous 하기 때문에 인접한 frame 간에 redundant information이 존재한다. 이것을 고려하면 efficient human pose estimation을 구현할 수 있다.
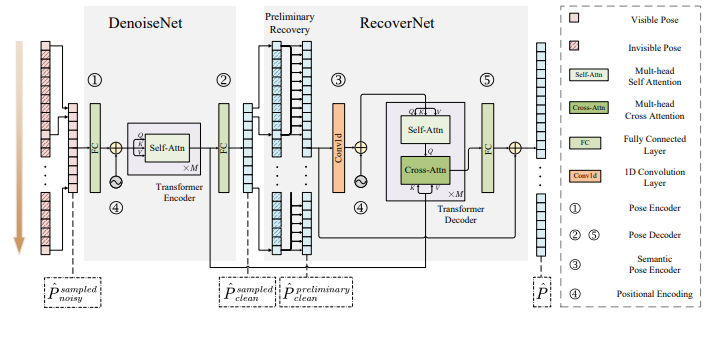
3.2 Getting Sampled Poses
3.3 Denoising the Sampled Poses
3.4 Recovering the Sampled Poses
3.5 Loss Function
4.Experiments
4.1 Experimental Settings
Sub-JHMDB(video-based dataset for 2D human pose estimation)
2D pose estimation -> Percentage of the Correct Keypoints (PCK)
3D pose estimation -> Mean Per Joint Position Error (MPJPE), mean Acceleration error (Accel), localization precision and smoothnes
PCK@20: estimated pose와 ground-truth pose간의 좌표 차이가 bounding box 크기의 20%(0.2) 이내 이면, correct keypoint로 간주한다. 이때 0.2는 PCK threshold 라고 한다
mean FLOPs (G) per frame: efficiency metrics
Number of parameters, Inference time: tested on a single TITAN Xp GPU
input, output window size: NQ+1
Q=1: 2D dataset
M=5, C=128: DenoiseNet
temporal kernel size of the semantic pose encoder: 5
single TITAN Xp GPU
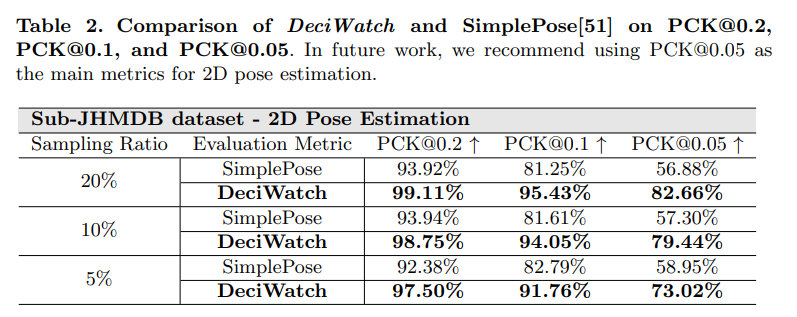
4.2 Comparison with Efficient Video-based Methods
Head
shoulder (Sho.)
elbows (Elb.)
wrist (Wri.)
inner joints (e.g., Hips)
Knee
ankles (Ank.)
average PCK (Avg.)
sampling ratio
4.3 Boosting Single-frame Methods
3D pose estimation
4.4 Comparison with Motion Completion Techniques
motion compensation/interpolation
CVAE-R+star: 3D pose의 ground-truth
CVAE-R: estimated 3D poses
CVAE-U: uniform sampling
5 Conclusion and Future Work
Adaptive sampling + dynamic recovery
ex. multi-modality information(WIFI, sensor)
Appendix