Paper Review
1.[논문리뷰] Deep Residual Learning for Image Recognition (ResNet)
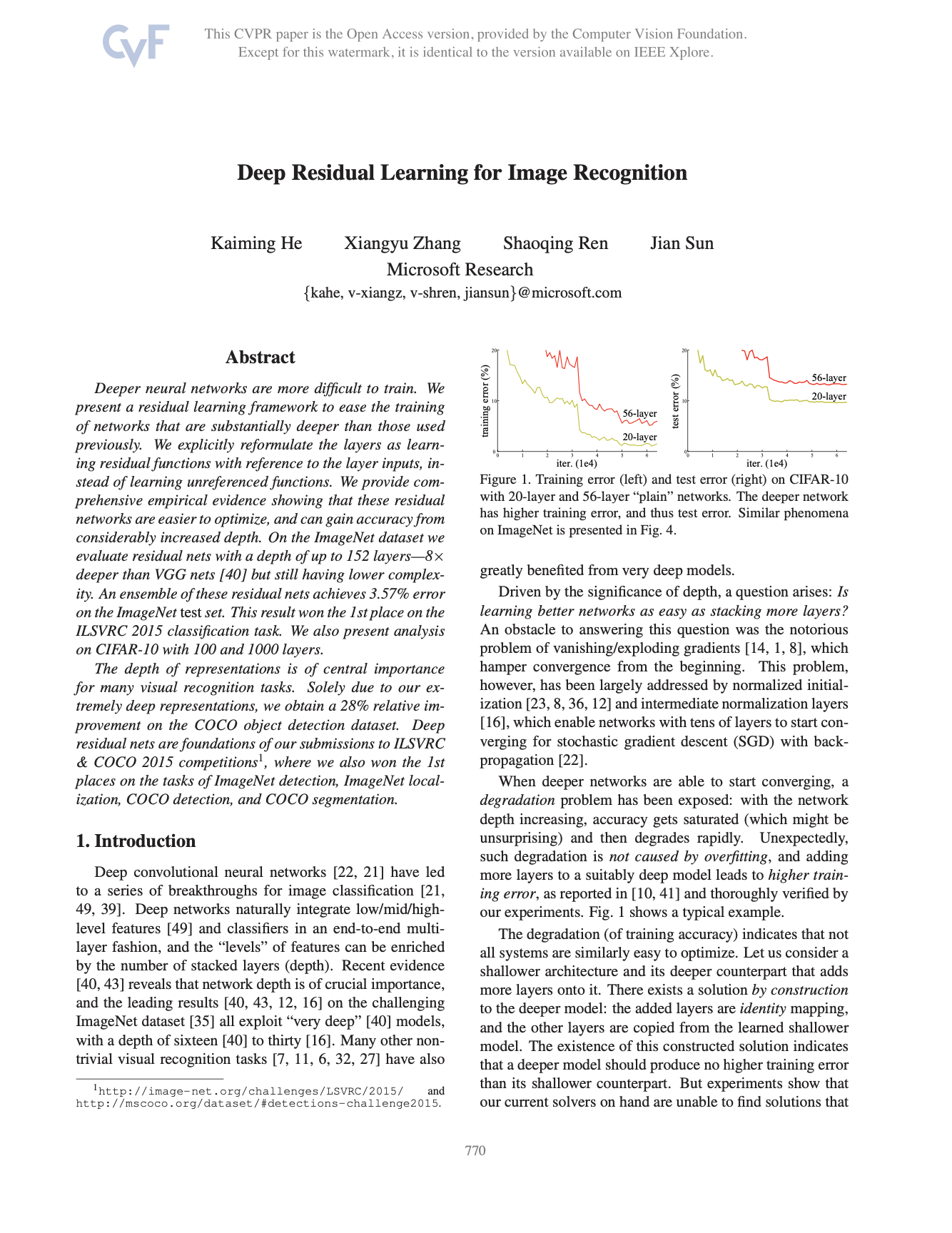
ResNet 논문을 보기 앞서, CNN에 대해 간단히 살펴보겠습니다.cnn은 이미지의 공간 정보 를 유지한 상태로 학습이 가능한 네트워크입니다.CNN에서 가장 중요하게 쓰이는 개념인 Convolution은 Filter를 사용하여 이미지의 공간적 정보를 유지한 채 학습하
2023년 6월 6일
2.[논문리뷰] EfficientNet : Rethinking Model Scaling for Convolutional Neural Networks

저번 논문리뷰에서 Resnet에 대해 이야기했었는데, resnet 이후 한번 더 효율성을 높인 방법론인 EfficientNet에 대해 알아보겠습니다.이 논문에서는 mobilenet, resnet, gpipe를 계속해서 언급하고있습니다. 그래서 이 세가지 모델을 간단히
2023년 9월 7일
3.[논문리뷰] An Image is Worth 16x16 words : Transformers for Image Recognition at Scale

제가 이번에 리뷰할 논문은 구글팀에서 낸 vision transformer에 대해 이야기해보겠습니다.VIT 구조는 self-attention을 사용한 구조로 NLP에서 높은 성능을 거두며 많이 쓰이고 있습니다. CV에서는 VIT논문이 발표되기 전까지는 여전히 CNN기반
2023년 10월 13일