
최근 면접준비로 혼자 끄적여보는.. 복습하며 끄적이는거니 그냥 막 적어본다.
👉 객체지향
객체지향 프로그래밍이란 프로그래밍에서 필요한 데이터를 추상화(Class)시키고 그것을 대상으로 상태(멤버변수), 행위(메서드)를 가지는 객체를 만들어 그 객체들 간에 유기적인 상호작용을 통해 프로그램을 구성하는 프로그래밍 방법이다.
어떠한 문제를 해결하는 프로그램을 작성한다고 가정했을때 그 해당 문제를 추상화하고 여러개의 작업단위로 나누어 프로그램을 작성한다. 여기서 해당 문제를 추상화하는것은 Class가 되고 여러개의 작업단위로 나누는것을 객체(인스턴스)라고 한다.
쉽게 설명해 Class는 설계도, 객체는 설계도를 통해 만들어진 실체라고 보자.
제일 많이 쓰이는 예시를 봐볼까?
나는 강아지, 고양이, 햄스터를 키우는 동물원을 만들고 싶다. 그럴려면 동물을 만들어야 겠지? 이것을 객체지향이 아닌 절차지향으로 본다면..
// 강아지
String dogName = "멍멍이"; // 강아지 이름
int dogAge = 12; // 강아지 나이
String dogSay = "멍멍"; // 강아지는 짖을때 멍멍한다.
// 고양이
String catName = "야옹이"; // 동물 이름
int catAge = 5; // 고양이 나이
String catSay = "멍멍"; // 강아지는 짖을때 야옹한다.
// 햄스터
String hamsterName = "햄딩이"; // 동물 이름
int hamsterAge = 7; // 햄스터 나이
String hamster = "꺅꺅"; // 햄스터는 짖을때 끼웃끼웃한다.뭔가 불편하고 지저분해 보이는데? 심지어 강아지가 2마리이면 어떡하지?
// 강아지
String dogName1 = "멍멍이"; // 강아지 이름
int dogAge1 = 12; // 강아지 나이
String dogSay1 = "멍멍"; // 강아지는 짖을때 멍멍한다.
String dogName2 = "멍멍이2호"; // 강아지 이름
int dogAge2 = 13; // 강아지 나이
String dogSay2 = "멍멍"; // 강아지는 짖을때 멍멍한다.이렇게 해줘야하나..? 겁나 불편하네... 머리를 좀써서 객체지향으로 짜보자.
추상화란 간단하게 중요한 특징을 찾아내어 표현한것을 말한다. 동물을 추상화 해보자. 동물은 나이도 있을거고.. 이름도 있을거야. 또 짖을수도 있을거야. 동물마다 짖는 소리는 다르겠지? 이걸 이용해서 동물 Class를 만들어보자.
class Animal {
private int age;
private String name;
public Animal(int age, String name) {
this.age = age;
this.name = name;
}
public void say() {
System.out.print("저는" + age + "살이고 " + "이름은 " + name + "에요. ");
};
}Animal 클래스는 나이, 이름을 멤버변수로, 생성자함수에서 해당 변수에 값을 저장한다. 또한 나이와 이름을 말하는 say()메서드도 만들었다.
그럼 이제 동물 Class를 만들었으니.. 얘내를 가지고 강아지,고양이,햄스터 클래스를 만들어보자.
class Dog extends Animal {
public Dog(int age, String name) {
super(age, name);
}
public void say() {
super.say();
System.out.println("멍멍");
}
}
class Cat extends Animal {
public Cat(int age, String name) {
super(age, name);
}
public void say() {
super.say();
System.out.println("야옹");
}
}
class Hamster extends Animal {
public Hamster(int age, String name) {
super(age, name);
}
public void say() {
super.say();
System.out.println("꺅꺅");
}
} Dog 클래스를 봐보자. 생성자 함수를 통해 super키워드로 부모클래스의 생성자를 호출하여 age와 name을 저장했다(age와 name은 private 제어자로 직접 접근할수 없다). 또한 상속받은 메서드 say를 오버라이딩하여 재정의했다. super 키워드를 통해 부모의 say 메서드를 호출하고 나서 강아지는 "멍멍"하고 짖는다.
이제 동물 Class를 상속받아 자식 Class Dog, Cat, Hamster를 만들었다. 위에서 설명했는데 Class는 설계도, 객체는 실체라고 하였다. Dog, Cat, Hamster 설계도를 만들었으니.. 이제 실체를 만들어볼 차례이다.
public static void main(String[] args) {
Dog dog = new Dog(12,"멍멍이");
dog.say(); //--> output: 저는12살이고 이름은 멍멍이에요. 멍멍
}메인함수에서 dog 객체를 만들었다. 나이는 12살, 이름은 멍멍이라고 했다. dog.say() 메서드를 이용해서 강아지한테 짖으라고 명령을 내리면 멍멍하고 짖을수 있다.
다른 동물들도 마저 만들어보자.
Cat cat = new Cat(5,"야옹이");
cat.say(); // --> output : 저는5살이고 이름은 야옹이에요. 야옹
Hamster hamster = new Hamster(7,"햄띵이");
hamster.say(); // --> output : 저는7살이고 이름은 햄띵이에요. 꺅꺅다른 동물들도 똑같은 결과가 나오는것을 알수 있다!
그럼 이제 강아지를 3마리로 늘려보자.
Dog[] dog = new Dog[3];
dog[0] = new Dog(12,"멍멍이");
dog[1] = new Dog(13,"멍멍이2호");
dog[2] = new Dog(14,"멍멍이3호");
for(Dog dogs : dog) {
dogs.say();
}
// --> output:
/* 저는12살이고 이름은 멍멍이에요. 멍멍
저는13살이고 이름은 멍멍이2호에요. 멍멍
저는14살이고 이름은 멍멍이3호에요. 멍멍 */겁나 기깔나고 간단하고 멋지다. 객체지향을 이용하지 않았다면 아마 아래와 같은 코드일것이다.
String dogName1 = "멍멍이"; // 강아지 이름
int dogAge1 = 12; // 강아지 나이
String dogSay1 = "멍멍"; // 강아지는 짖을때 멍멍한다.
String dogName2 = "멍멍이2호"; // 강아지 이름
int dogAge2 = 13; // 강아지 나이
String dogSay2 = "멍멍"; // 강아지는 짖을때 멍멍한다.
String dogName3 = "멍멍이3호"; // 강아지 이름
int dogAge3 = 13; // 강아지 나이
String dogSay3 = "멍멍"; // 강아지는 짖을때 멍멍한다.
System.out.println("저는" + dogAge1 + "살이고 " + "이름은 " + dogName1 + "에요. " + dogSay1);
System.out.println("저는" + dogAge2 + "살이고 " + "이름은 " + dogName2 + "에요. " + dogSay2);
System.out.println("저는" + dogAge3 + "살이고 " + "이름은 " + dogName3 + "에요. " + dogSay3);멋지지가 않고 가장 중요한건.. 코드가 중복되고 효율성이 떨어지는것 같다.
이것처럼 프로그램의 모든 동작단위를 클래스와 객체로 나누어 프로그램을 구성하여 코드의 재사용성을 높이는 방식을 객체지향 프로그래밍이라고 한다.
✔ 클래스가 뭔가요?
- 연관되어 있는 변수와 메서드들의 집합
- 구현할 대상을 추상화 해놓은 것
- 객체를 만들어 내기위한 설계도
✔ 객체란 뭔가요?
- 추상화된 구현할 대상으로부터 실체로 구현된 것
- 클래스로부터 만들어진 실체
✔ 객체지향 프로그래밍의 장점은 뭔가요?
- 코드의 재사용성
- 유지보수 용이
- 대형 프로젝트에 적합
👉 멀티스레드
기본적으로 프로그램은 단일스레드를 제공한다. 예를 들어 운전을 할때 운전자가 운전말고 다른 행동을 할수있는가? 아니다. 운전자는 운전만 해야지.. 다른 행동을 했다간 큰 사고로 이어지겠지. 프로그램도 똑같다. 시작과 종료까지 하나의 일밖에 하지 못한다. 하지만 멀티스레드를 사용하게 되면 여러가지의 일을 동시에 수행할 수 있다. 예로 TCP/IP로 구현한 채팅프로그램이 있다고 가정하자. 기본적으로 TCP/IP는 하나의 소켓으로 통신하는 일대일 통신방식이다. 때문에 서버는 하나이지만 클라이언트, 즉 접속자가 여러명일 경우 다중 응답을 동시에 해주어야 할 때 멀티스레드를 사용하여 채팅프로그램을 구현할 수 있다.
👉 제네릭
제네릭이란 객체, 인스턴스가 생성될 때 클래스 내부에서 사용할 데이터 타입을 파라미터로 전달하여 결정하는것을 말한다. 제네릭을 선언하는 방법은 다음과 같다.
public class GnrTest<T> {
T num;
public GnrTest(T num) {
this.num = num;
}
public T getNum() {
return num;
}
}public static void main(String[] args) {
GnrTest<Integer> gt1 = new GnrTest<Integer>(3);
System.out.println(gt1.getNum());
GnrTest<Double> gt2 = new GnrTest<Double>(3.5);
System.out.println(gt2.getNum());
}클래스 명 옆에 <> 기호로 안에 별명을 만들어준다. 보통 T라는 것으로 약속하여 사용한다. 객체 선언부에서 결정할 타입을 <>안에 전달한다. 여기서 주의할 점은 제네릭의 파라미터로는 참조 타입만 올수 있다. 즉 primitive type인 int, double char와 같은 테입을 불가하다. 대신 Wrapper 타입인 Integer, Double와 같은 타입으로 대체한다.
위 예제와 같이 비슷한 기능을 구현하는 하나의 클래스로 여러개의 데이터타입을 이용함으로써 재사용성이 증가한다.
// ArrayList str = new ArrayList(); 좋지않은 방법이다.
ArrayList<String> str = new ArrayList<String>();
str.add("hello");
System.out.println(str.get(0)); // --> output: hello
ArrayList<Double> num = new ArrayList<Double>();
num.add(3.5);
System.out.println(num.get(0)); // --> output: 3.5예로 Java의 Collection중에 하나인 ArrayList는 객체 선언시 타입을 제네릭으로 선언하지 않으면 데이터 타입에 상관없이 모든 자료형을 저장 할수 있다. 어떻게 보면 정말 편하구나라고 생각할 수 있지만 이것은 좋지않은 선택이다. 만약 제네릭을 선언않고 ArrayList를 사용할 경우 해당 Index에 값을 저장하고 불러올때 마다 형변환이 일어나게 된다. int형 값을 저장할 경우 int 타입에서 Object 타입으로 변환하여 저장되고, 불러 올 경우 다시 Object 타입을 int 타입으로 변환하게 된다. 이는 성능 저하를 불러올 뿐만 아니라 데이터 타입에 대한 검증을 매우 엄격하게 하는 Java에서 어울리지 않는다. 때문에 ArrayList 선언시 제네릭으로 타입을 명시해주어 사용하는것이 성능 향상에 도움을 줄것이다.
👉 다형성
다형성이란 사전적으로 다양한 형태의 성질을 가진다라는 의미이며, **부모타입의 참조변수로 자식 타입의 객체를 가질수 있는것이다. 반대로 생각해본다면? 하나의 객체가 여러개의 데이터타입을 가질수 있게 된다.
class Fruit {}
class Apple extends Fruit {}
class Banana extends Fruit {}
public class MainClass {
// 매개변수의 Fruit은 부모 타입임으로 자식타입(Apple,Banana)을 가질수도 있다.
public static void whatKindFruits(Fruit fruit) {
if(fruit instanceof Apple) {
System.out.println("Apple");
} else if (fruit instanceof Banana) {
System.out.println("Banana");
}
// instanceof는 특정 객체가 특정클래스의 인스턴스인지를 묻는 키워드이다.
}
public static void main(String[] args) {
Apple apple = new Apple(); // 자기 자신을 참조변수으로 Apple 객체
Banana banana = new Banana(); // 자기 자신을 참조변수으로 Banana 객체
Fruit parentTypeApple = new Apple(); // 부모 타입을 참조변수로 가지는 Apple 인스턴스
Fruit parentTypeBanana = new Banana(); // 부모 타입을 참조변수로 가지는 Banana 인스턴스
whatKindFruits(parentTypeApple); // --> output: Apple
whatKindFruits(parentTypeBanana); // --> output: Banana
}
}위 코드를 보면 Fruit 클래스를 상속받는 자식클래스 Apple과 Banana가 있는데 Main 함수에서 Fruit 부모클래스의 데이터 타입을 참조변수로 하여 자식타입의 객체를 생성한다. Apple, Banana 클래스는 자기 자신을 데이터타입으로 사용할수도 있고 부모인 Fruit를 데이터타입으로 사용할 수도 있다. 그냥 이해가 어려울경우.. 가장 이해가 쉽게 아래 코드를 보자.
public static void main(String[] args) {
Object obj1 = 1;
Object obj2 = "String";
Object obj3 = 23.5;
System.out.println(obj1 instanceof Integer); // --> output: true
System.out.println(obj2 instanceof String); // --> output: true
System.out.println(obj3 instanceof Double); // --> output: true
}자바의 최상위 클래스는 Object이다. 자바의 모든 객체는 Object 타입을 부모로 가질수 있다. 아래 출력문에서 instanceof 키워드를 이용해 obj1,obj2,obj3이 특정 클래스의 인스턴스인지 비교했다. 모두가 true로 출력된다. 이렇게 보니 간.단.하.네?ㅡ.ㅡ
👉 추상클래스와 인터페이스 차이
추상클래스와 인터페이스는 선언만 있고 구현이 없는 클래스이다. 해서 자기 자신이 스스로 객체를 생성할 수 없고 자식클래스에서 추상클래스와 인터페이스를 상속받아야만 사용이 가능하다.
추상클래스는 일반 멤버변수와 메서드를 포함할 수 있지만 인터페이스는 모든 변수는 상수이고 모든 메서드는 반드시 추상메서드여야 한다. 추상클래스는 단일상속만 가능하며 인터페이스는 다중구현이 가능하다. 공통점은 추상클래스와 인터페이스를 상속받는 자식클래스는 추상메서드를 모두 오버라이딩하여 정의하여야 한다는점이다.
* 추상클래스의 용도
추상클래스는 상속관계에 있는 클래스중 반드시 구현해야 하는 메서드의 형식을 미리 구현해놓은 것이다. 즉 추상클래스는 상속관계에 의미를 둔다. 일반적인 상속관계에서 자식클래스들 마다 달라져야 할 속성이 있을때 추상클래스로 선언하여 자식클래스에서 추상메서드를 정의하는 것이다. 즉 동물에 비교 했을때 개, 고양이가 있다고 가정하고 서로 동물이라는점은 일치하지만 짖을때 개는 '멍멍', 고양이는 '야옹', 까마귀는 '꺅꺅'이라는 다른점을 생각하면 될것이다.
* 인터페이스의 용도
인터페이스의 목적은 위 처럼 동물에 비교 했을때 상속관계처럼 공통된 부분(모든 동물은 짖는다)을 상속받는것이 아닌 필요에따라 기능들을 결합하는것이다. 예를 들어 개와 고양이는 달릴수있고 까마귀는 하늘을 날수 있다. 그렇다면 개와 고양이는 달리는 인터페이스를 구현하고 까마귀는 하늘을 나는 인터페이스를 구현할수 있을것이다.
추상클래스는 상속받고자 하는 자식클래스에서 상속관계에 해당되는 메서드를 강제로 구현하게끔 하고 인터페이스는 상속관계가 아닌 클래스가 요구하는 특성에 따라 메서드의 정의를 강제하게끔 한다. 즉 추상클래스는 물려받는것, 인터페이스는 장착하는것으로 이해하자.
위의 얘기한 동물을 예시로 코드를 만들어보자.
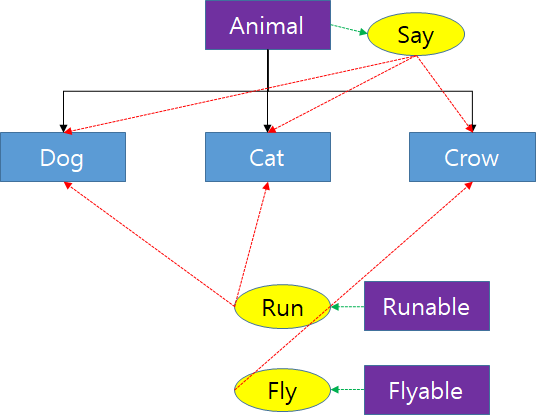
추상클래스
abstract class Animal {
abstract void say();
}동물은 모두 짖는다는 요소를 가지고 있다.
인터페이스
interface Runnable {
void run();
}
interface Flyable {
void fly();
}개와 고양이는 달릴수 있고 까마귀는 하늘을 날수있다.
자식 클래스
class Dog extends Animal implements Runnable {
@Override
void say() {
System.out.println("개는 멍멍하고 짖어요");
}
@Override
public void run() {
System.out.println("나는 10초에 50미터를 달려요");
}
}
class Cat extends Animal implements Runnable {
@Override
void say() {
System.out.println("고양이는 야옹하고 짖어요");
}
@Override
public void run() {
System.out.println("나는 10초에 70미터를 달려요");
}
}
class Crow extends Animal implements Flyable {
@Override
void say() {
System.out.println("까마귀는 깍깍하고 짖어요");
}
@Override
public void fly() {
System.out.println("나는 10초에 50미터를 날아요");
}
}추상 클래스를 상속받아 Dog와 Cat, Crow의 자식클래스를 생성했고 각 자식클래스들은 say 추상메서드를 구현하고 있다. 또한 Dog와 Cat은 Runable이라는 인터페이스를 구현하고 있고, Crow는 Flyable이라는 인터페이스를 구현하고 있다.
👉 메모리 영역의 구조

👉 스택영역과 힙영역
C, C++이 아닌 Java와 C#과 같은 객체지향언어는 메모리를 가비지컬렉터가 스스로 관리 해주는데 그렇기 때문에 이 스택영역과 힙영역에 대한 부분을 다루는것이 중요치않게 여겨지는 경우가 꽤 있는것 같다. 스택영역과 힙영역에 대해 정리해보자.
기본적으로 Java는 Primitive type인 int, char, double과 같은 기본 자료형외에 모든 자료형은 객체이며 참조형이다. 기본 자료형은 Stack 영역에 저장되고, 참조형은 Heap영역에 저장된다라는것을 알고가자.
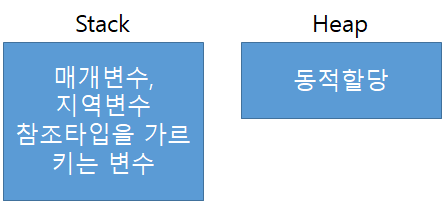
Stack
- 기본적으로 Stack영역은 매개변수와 지역변수, 그리고 참조타입의 위치(주소)를 가르킬 변수로 할당된다.
- 또한 Stack영역은 스레드마다 각자의 영역을 제공한다.
Heap
- Heap영역은 동적할당의 영역, 참조타입(객체)이 저장된다.
- 모든 객체는 사용하기 전에 new 키워드를 사용해 인스턴스를 메모리 동적할당(Heap 영역)을 해주어야한다.
다음 코드를 보자.
public static void addAryList(ArrayList<String> arrlist) {
int value2 = 3;
arylist.add(" world");
}
public static void main(String[] args) {
ArrayList<String> str = new ArrayList<String>();
int value1 = 1;
str.add("hello");
for(String _str : str) {
System.out.println(_str);
} --> output: hello
addAryList(str);
for(String _str : str) {
System.out.print(_str);
} --> output: hello world
}동작 과정은 다음과 같다.

1. 먼저 처음으로 Stack 영역에 str이라는 참조타입의 위치(주소)를 가르킬 변수가 할당된다.
2. Heap영역에는 참조 객체인 ArrayList가 할당된다.
3. Stack영역에 str는 Heap영역의 ArrayList를 가르킨다.

4. 이제 Main함수에 value1 변수가 stack영역에 할당된다. int형이므로 값 그 자체가 영역에 할당된다.
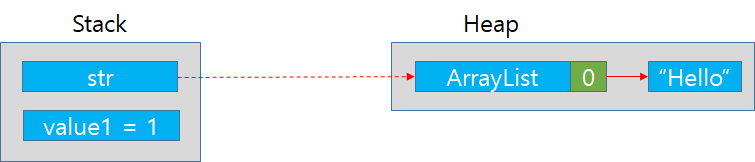
5. Stack 영역의 str에 "hello"라는 문자열을 add한다. 내부적으로 str이 가르키는 Heap영역의 ArrayList에 "hello"라는 문자열이 추가된다.
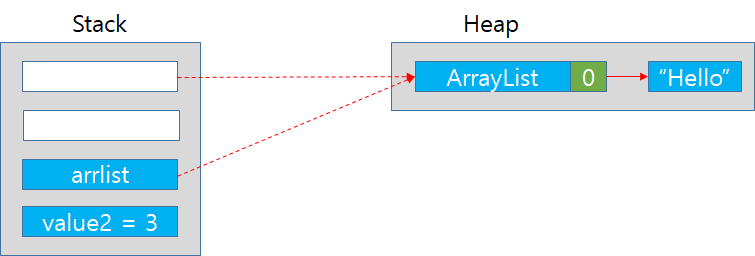
6. for loop를 돌며 ArrayList str을 출력하여 hello이 출력되었다.
7. addAryList 함수를 호출함으로써 기존 Stack영역에 있던 str과 value1은 scope에서 벗어나 사용할 수 없다.
8. addAryList 함수의 매개변수 arrlist가 Stack영역에 할당되고 Main함수의 str을 인자로 전달받았음으로 Heap영역에 ArrayList를 가르킨다.
9. addAryList 함수의 value2 변수가 stack영역에 할당된다. int형이므로 값 그자체가 영역에 할당된다.
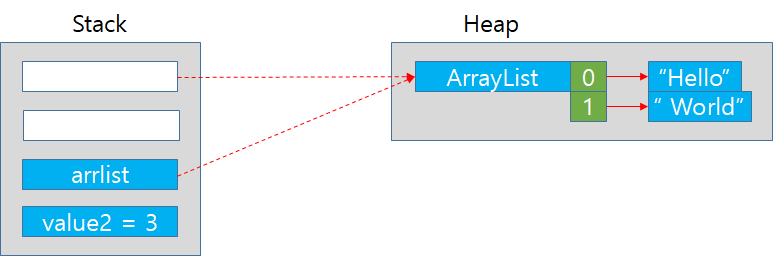
10. Stack 영역의 arrlist에 " world"라는 문자열을 add한다. 내부적으로 arrlist이 가르키는 Heap영역의 ArryList에 " world"라는 문자열이 추가된다.
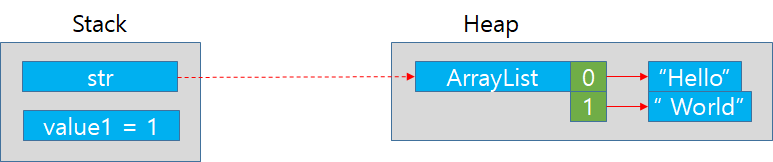
11. addAryList의 함수가 종료되었음으로 이전에 존재하던 Stack 영역의 arrlist와 value2는 pop되어 삭제된다.
12. 다시 Main함수의 scope로 돌아왔기 때문에 str와 value1이 사용 가능상태로 돌아왔다.
13. for loop를 돌며 ArrsyList str을 출력해보니 hello world가 출력된다. 앞서 addAryList 함수에서 arrlist변수로 Main함수 스코프의 str과 같은 Heap영역의 ArrayList를 참조했기 때문이다.
👉 HTTP
HTTP란 HyperText transfer Protocol의 약자로 클라이언트와 서버간에 상호작용을 위한 통신 프로토콜이다. 프로토콜은 규약이며 약속이다. 상호작용 한다는것은 클라이언트와 서버간에 통신을 한다는 것을 의미한다. 때문에 웹에서 운영되는 모든 프로그램은 이 HTTP 규약을 따라야한다. 클라이언트가 서버로 정보를 요청하는것을 Request라고 하며 서버가 클라이언트로부터 요청받은 정보를 응답하는것을 Response라고 한다.

👉 RESI API
REST API란 클라이언트에서 서버로 정보를 요청하는데에 있어서 널리 쓰이는 형식이다. 이 형식을 지키게 되면 클라이언트에서 서버로 요청하는 정보를 URL만 보고도 추론이 가능하다. 다음과 같은 4가지 요청을 서버로 보낼때를 예로 들어보자.
- 학원반 정보를 요청
- 학원 학생들의 정보를 요청
- 학원 선생님의 정보를 요청
위와 같은 조건들이 존재할 때 RESTful하지 못한 경우는 다음과 같다.
- http://학원/1 : 학원 반 정보를 요청
- http://학원/hello : 학원 학생들의 정보를 요청
- http://학원/bye : 학원 선생님들의 정보를 요청
URL만 봐서는 도저히 이게 무엇을 요청하는거지? 이 URL로 요청했을때 어떠한 응답이 서버로부터 올까? 감이 잡히질 않는다.
물론 이렇게 애플리케이션을 만들어도 문제될것은 없다. 프로그램에 문제가 없으니. 단 자신이 혼자 개발하고 혼자 유지보수하며 다른 앱으로 API 정보를 제공하지 않을거라면 말이다.
그렇다면 REST API의 규칙을 잘 갖춘 요청을 보자.
- http://학원/class/3 : 학원 반 정보를 요청
- http://학원/student : 학원 학생들의 정보를 요청
- http://학원/teacher : 학원 선생님들의 정보를 요청
딱봐도 이 URL이 무엇을 요청하는지 알수있다. 첫번째는 class의 3반을 요청하는것이고 두번째는 student 학생의 정보, 세번째는 teacher 선생들의 정보를 요청하는것이다.
개발자들 사이에서는 이러한 규칙들을 잘 지켜진것을 보고 RESTful하다고 한다.
물론 이런 URL의 자원을 예측 가능하도록 만드는것도 중요하지만 서버로에게 보내는 요청에 따라 HTTP 메서드 역시 잘 맞춰 사용해야 할것이다. HTTP 메서드의 종류는 다양하지만 대표적으로 가장 많이 쓰이는 종류는 다음과 같다.
- GET: URL에서 가진 정보를 조회하기 위한 요청 주로 페이지를 읽어오고 검색 요청을 수행
- POST: 새로운 정보를 추가 하기 위한 요청
- PUT & PATCH : 정보를 수정하기 위한 요청, 정보 전체를 변경 할때는 PUT 메서드를 사용하고 일부를 변경 할때는 PATCH 메서드를 사용한다.
- DELETE : 정보를 삭제하는 요청
최종적으로 정리하자면 REST API란? HTTP 요청을 보낼때 어떠한 URL 자원과 어떠한 메소드 요청을 사용할지 개발자들의 사이에서 널리 지켜지는 약속이다.
👉 델리게이트
기본적인 개념과 선언방식
델리게이트는 C#에서 사용되는 개념이다. 데이터 반환형과 파라메터를 포함한 델리게이트 자료형을 선언하고 델리게이트에 등록하려는 메서드 역시 델리게이트 자료형과 동일한 형태를 가지게끔 선언한다.
class Program
{
delegate void MyDeleGate(); // 델리게이트 자료형 선언 반환형은 void이며 parameter는 없다.
static void printTest() // 델리게이트에 등록할 메서드 선언. 반환형은 void이며 parameter는 없다.
{
Console.WriteLine("Hello World");
}
static void Main(string[] args)
{
MyDeleGate del = new MyDeleGate(printTest); // 델리게이트에 printTest 메서드를 등록한다.
del(); // --> output: Hello World
}간단하게 설명하자면 델리게이트는 메서드를 대신해서 담는 변수이다. 의미적으로는 대리인이라고도 한다. 위 코드에서는 반환형이 없고 parameter가 없는 델리게이트를 MyDeleGate라는 이름으로 생성했다. printTest함수 역시 델리게이트 자료형과 동일한 형태로 선언했다. Main 함수에서 MyDeleGate 자료형으로 del이라는 델리게이트(대리자) 변수를 만들었으며 del변수에 printTest 메서드를 등록했다. del함수를 호출하면 printTest를 호출한것과 같은 출력결과를 확인할 수 있다.
델리게이트의 사용예시
또한 델리게이트는 메서드의 매개변수로도 사용할 수 있다(메서드를 담는 변수이기 때문). 이러한 것을 콜백함수라고 하는데 델리게이트와 메서드의 Prototype이 일치하면 모든 메서드를 등록할 수 있다는것을 이용해 코드의 재사용성을 높일 수 있다.
다음은 내림차순과, 오름차순을 하는 예시이다.
class Program
{
delegate Boolean SortCompare(int num1, int num2); // 델리게이트 자료형 선언
static void sortFunc(int[] nums, SortCompare sort) // 정렬 기능 처리 메서드
{
for (int i= 0; i < nums.Length; i++)
{
for(int j=i+1; j<nums.Length; j++)
{
if (sort(nums[i],nums[j]) == true)
{
int temp = nums[j]; // 순서 바꾸기
nums[j] = nums[i];
nums[i] = temp;
}
}
}
foreach(int i in nums) Console.Write(i + " "); // 정렬된 배열 출력
}
static Boolean downSortCompare(int num1, int num2) // 내림차순 비교
{
return (num1 - num2) > 0 ? false : true;
}
static Boolean upSortCompare(int num1, int num2) // 오름차순 비교
{
return (num1 - num2) > 0 ? true : false;
}
static void Main(string[] args)
{
int[] nums = new int[5] { 3,2,5,1,4 }; // 정렬되지 않은 배열
SortCompare sortCompare = new SortCompare(upSortCompare); // 델리게이트에 오름차순 비교 메서드 등록
sortFunc(nums, sortCompare); // 정렬 기능 처리 메서드에 정렬되지 않은 배열과 델리게이트 메서드를 인자로 호출
Console.WriteLine();
sortCompare = new SortCompare(downSortCompare); // 델리게이트에 내림차순 비교 메서드 등록
sortFunc(nums, sortCompare); // 정렬 기능 처리 메서드에 정렬되지 않은 배열과 델리게이트 메서드를 인자로 호출
}
}sortFunc은 정렬 기능을 처리하는 메서드로, 오름차순으로 정렬할 것인지, 내림차순으로 정렬할 것인지는 메서드를 호출하는 시점에서 결정된다. 즉 메서드 호출시 내림차순이냐 오름차순이냐에 따라 다른 메서드를 델리게이트에 등록하여 호출한다.
👉 SPA(Single Page Application)
SPA란 Single Page Application의 약자로 서버로 부터 완전한 페이지를 불러오는것이 아닌 현재의 페이지를 동적으로 다시 작성하는 기법이다. 즉 View부분을 담당하는 HTML, CSS, JavaScript는 모두 애플리케이션에 위치하고 서버는 클라이언트가 요청하는 정보만 응답함으로써 애플리케이션 측에서 응답받은 정보만 동적으로 교체하는 방식이다. 대표적인 프레임워크로는 React, Vue, Anguler가 있다.
👉 가비지컬렉션
가비지컬렉션이란 프로그램이 런타임중 동적할당한 메모리영역에 대해 사용하지 않는 메모리영역을 찾아 자원을 해제 시킨다.
C,C++에서는 이러한 메모리의 할당부터 해제까지 개발자가 해주어야 하지만 Java와 C#에서는 가비지컬렉션이 스스로 처리한다.
👉 INDEX
인덱스란 추가적인 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조이다.
👉 DML DCL DDL TCL
DML(Data Manipulation Language)
- SELECT: 데이터 검색
- INSERT: 데이터 삽입
- UPDATE: 데이터 수정
- DELETE: 데이터 삭제
DDL(Data Definition Language)
- CREATE: 테이블 생성
- ALTER: 테이블 수정
- DROP: 테이블 삭제
- TRUNCATE: 테이블 초기화
DCL(Data Control Language)
- GRANT: 권한 부여
- REVOKE: 권한 회수
TCL(Transaction Control Language)
- COMMIT: 트랜잭션의 성공
- ROLLBACK: 트랜잭션 실패로 이전 작업으로 되돌림
- SAVEPOINT: 트랜잭션 실패시 이전 작업으로 되돌리기 위한 Point 지점
👉 JOIN
- INNER JOIN: 공통적인 부분만 SELECT(교집합)
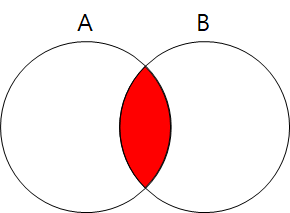
- LEFT OUTER JOIN: A테이블이 기준이된, A테이블의 정보는 모두 출력하되 B테이블은 조건이 만족하는 정보만 출력
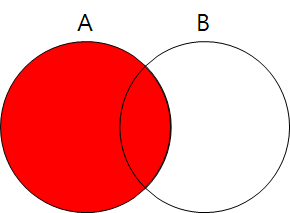
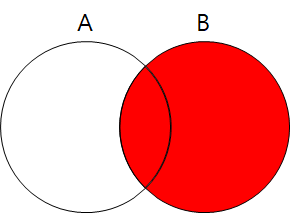
- RIGHT OUTER JOIN: B테이블이 기준이된, B테이블의 정보는 모두 출력하되 A테이블은 조건이 만족하는 정보만 출력
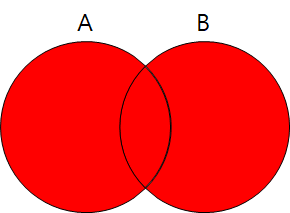
- FULL OUTER JOIN : A테이블, B테이블 모두 출력(합집합)
👉 링크드리스트, 스택, 트리, 큐, 정렬, 힙, 해쉬테이블
- 링크드리스트: 각각의 데이터가 노드로 연결되어 구성된 자료구조. 배열과 유사하나 삽입,삭제에서 유리하다. 배열은 삽입,삭제시 전,후로 있는 인덱스들을 모두 밀거나 당겨줘야 하지만 링크드리스트는 삽입,삭제시 앞,뒤로 가르키는 노드의 위치만 변경해주면 된다.
- 스택: 후입선출 구조로 나중에 들어온것이 가장 먼저 처리된다.
- 큐: 선입선출 구조로 가장 먼저 들어온것이 가장 먼저 처리된다.
- 트리: 그래프의 한 종류로 계층구조의 노드로 이루어진 자료구조이며 트리의 형태를 가지게끔 탐색한다.
- 정렬:
- 힙:
- 해쉬테이블: Key와 Value를 가지며 Key의 중복을 허용하지 않고 순서를 보장하지 않는다. hash함수라는 함수로 부터 내부적인 로직을 거쳐 Key값이 index로 변경되며 이 index를 통하여 Value가 저장된다. hash함수와 Key만 있으면 index를 바로 알아낼 수 있으므로 탐색속도가 매우 빠르다.
👉 C#의 컬렉션(제네릭)
C#의 컬렉션으로 ArrayList, Queue, Stack, HashTable등이 있지만 이 자료형은 Object 타입을 사용하여 데이터를 관리하기 때문에 박싱/언박싱의 이슈가 있어 현재는 사용하지 않는 추세이고 제네릭 타입으로 사용할 수 있는 컬렉션을 사용한다.
- List<>: 배열의 크기를 정적으로 변경가능한 자료형, 순서를 보장한다.
- Dictionary<,>: Key과 Value를 가지는 자료형, Key는 유일해야 한다.
- HashSet<>: 자료의 순서를 보장하지 않으며 중복을 허용하지 않는다. Hash 알고리즘을 사용함으로 탐색속도가 매우 빠르다.
- Queue<>: 선입선출(FIFO) 구조의 자료형
- Stack<>: 후입선출(LIFO) 구조의 자료형
👉 Java의 컬렉션
Set Interface
요소의 저장 순서를 유지하지 않고 같은 요소의 중복 저장을 허용하지 않음.
- HashSet: Set 인터페이스에서 가장 많이 사용됨. Hash 알고리즘을 사용하여 탐색속도가 매우 빠름. 내부적으로 HashMap
인스턴스를 이용하여 요소를 저장함. - TreeSet: 데이터가 정렬된 상태로 저장되는 이진 검색 트리의 형태로 요소를 저장함. 데이터를 추가하거나 제거하는 등의 동작 시간이 매우 빠름.
List Interface
배열과 유사한 구조이며 크기를 정적으로 변경가능함.
- LinkedList: 다음노드의 주소를 기억하고 있는 List로 삽입, 삭제시에 장점이 있지만 인덱스를 찾을때 첫번째 노드부터 차례로 탐색해야 함으로 탐색이 느림.
- ArrayList: 배열과 동일한 구조를 가지고 있으며 인덱스를 기준으로 하기 때문에 삽입, 삭제시 LinkedList에 비해 불리하지만 인덱스를 기반으로 검색하므로 탐색이 빠르다. 동기화 기능 옵션이 존재한다.
- Vector: ArrayList와 동일하지만 Vector는 동기화된 메서드로 구성되어 있어 멀티 스레드가 동시에 이 메소드를 실행할 수 없음. 현재는 사용하지 않는 추세이며 ArrayList를 주로 사용함.
- Queue: 선입선출(FIFO) 구조의 자료형
- Stack: 후입선출(LIFO) 구조의 자료형
Map Interface
Key와 Value를 가지는 자료형임. 요소의 저장순서를 유지하지 않고 키는 중복을 허용하지 않지만 값의 중복은 허용함.
- HashTable: 사용하지 않는 추세이며 HashMap과 대부분의 기능이 동일함. HashMap을 사용하자.
- HashMap: HashMap 인터페이스에서 가장 많이 사용되는 클래스중 하나. Hash 알고리즘을 사용하여 탐색속도가 매우 빠름.
- TreeMap: 데이터가 정렬된 상태로 저장되는 이진 검색 트리의 형태로 요소를 저장함. 데이터를 추가하거나 제거하는 등의 동작 시간이 매우 빠름.
