딥러닝 문제를 해결하기 위한 초기 단계에서는 풀어야 할 문제를 이해하고 데이터를 잘 파악할 수 있어야 한다. 데이터를 잘 파악하기 위해 탐색적 데이터 분석(EDA)을 수행하는데 주어진 데이터의 구조를 훑어보는 것을 말한다. 데이터 파일이 여러개 있으면 각 파일별 용도를 파악하거나, 전체적인 데이터의 양, 피처를 이해하는 과정을 포함한다. 여기서 도출해야하는 예측값(타깃)이 무엇인지도 확인해야 한다. 데이터 시각화를 통해 좀더 가시적으로 데이터를 파악할 수도 있다. 데이터에는 크게 정형, 반정형, 비정형 데이터가 있지만 여기서는 정형데이터만 다루겠다.
정형데이터에는 크게 수치형 데이터와 범주형 데이터로 나뉜다.
수치형 데이터는 사칙연산이 가능한 데이터로 일정한 범위 내에서 데이터의 분포를 파악하는 것이 중요하다. 이 분포를 알아야 데이터를 어떻게 가공하고 해석할지 판단할 수 있다. seaborn에서 제공하는 분포도 함수에는 histplot(), kdeplot(), displot(), rugplot()이 있다.
아래는 이산형 데이터는 histplot()으로, 연속형 데이터는 kdeplot()으로 그린 것이다. hue파라미터를 통해 타깃값에 따른 분포가 어떻게 나타나는지까지 볼 수 있다. subplot()은 여러 그래프를 한번에 그릴때 유용한 함수로 plt.subplots((행 ,열, 그래프의 크기(가로, 세로))의 형태를 띤다.
# 수치형 데이터 - 이산
df_수치이산 = [
'no_of_adults', 'no_of_children', 'no_of_weekend_nights', 'no_of_week_nights',
'no_of_previous_cancellations', 'no_of_previous_bookings_not_canceled', 'no_of_special_requests']
len_수치이산 = len(df_수치이산)
f, ax = plt.subplots(1, len_수치이산, figsize=(100,7))
for i in df_수치이산:
df[i].unique()
sns.histplot(data=df, x=i, hue="booking_status", multiple="stack", ax=ax[df_수치이산.index(i)])
plt.show()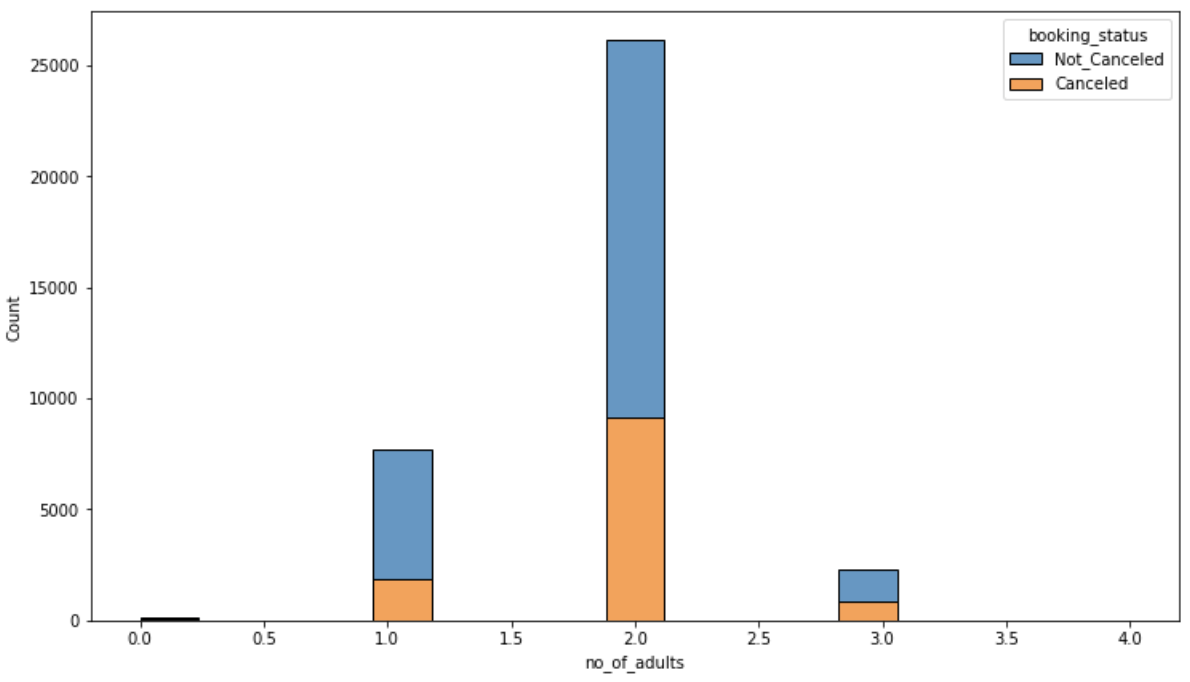
# 수치형 데이터 - 연속
df_수치연속 = ['lead_time', 'avg_price_per_room']
len_수치연속 = len(df_수치연속)
f, ax = plt.subplots(1, len_수치연속, figsize=(100,7))
for i in df_수치연속:
df[i].unique()
sns.kdeplot(data=df, x=i, hue="booking_status", multiple="stack", ax=ax[df_수치연속.index(i)])
plt.show()
반면, 범주형 데이터는 범주를 나눌 수 있는 데이터로 사칙연산이 불가능하다. 범주형 데이터도 순위를 매길수 있는 순서형 데이터와 순위가 따로 없는 명목형 데이터로 나눌 수 있다.
범주형 데이터를 시각화하는 방법에는 막대그래프(barplot), 포인트플롯(pointplot), 박스플롯(boxplot), 바이올린 플롯(violinplot), 카운트플롯(countplot)이 있다. 또한 범주형 데이터별 비율을 알아볼 때 파이그래프(pie())를 사용할 수 있다
아래는 취소 여부를 나타내는 명목형 데이터의 카운트 플롯과 파이그래프를 그린것이다.
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1, 2, figsize=(15,7))
df["booking_status"].value_counts().plot.pie(autopct='%.2f', ax=ax[0])
sns.countplot(x = 'booking_status', data = df, ax=ax[1])
plt.show()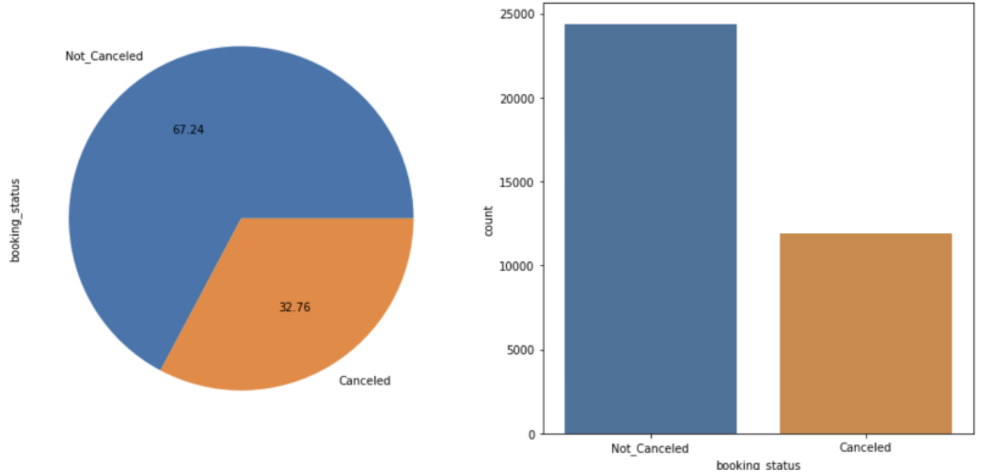
범주형 데이터에서는 타깃 값에 따른 비율 비교를 crosstab()함수로 할 수 있다.
pd.crosstab(df["market_segment_type"], df["booking_status"], normalize='index')*100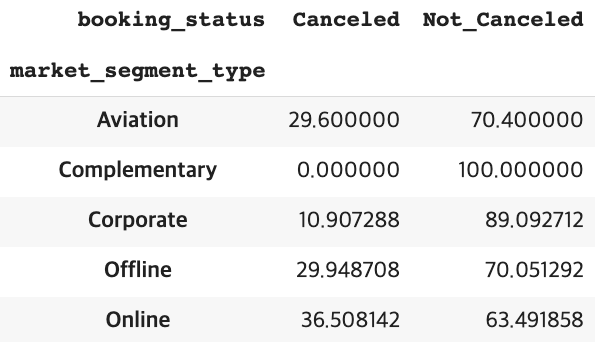
각 피처 데이터의 분포를 확인했다면 데이터 사이의 관계를 파악해보자! 히트맵, 라인플롯, 산점도, 회귀선 정도가 있을 것 같다.
대표적으로 히트맵을 만들어보자
corrMat = df[["no_of_adults", "no_of_children", "no_of_weekend_nights",
"no_of_week_nights", "lead_time","no_of_previous_cancellations",
"no_of_previous_bookings_not_canceled", "avg_price_per_room",
"no_of_special_requests"]].corr()
fig, ax = plt.subplots()
fig.set_size_inches(10, 10)
sns.heatmap(corrMat, annot=True)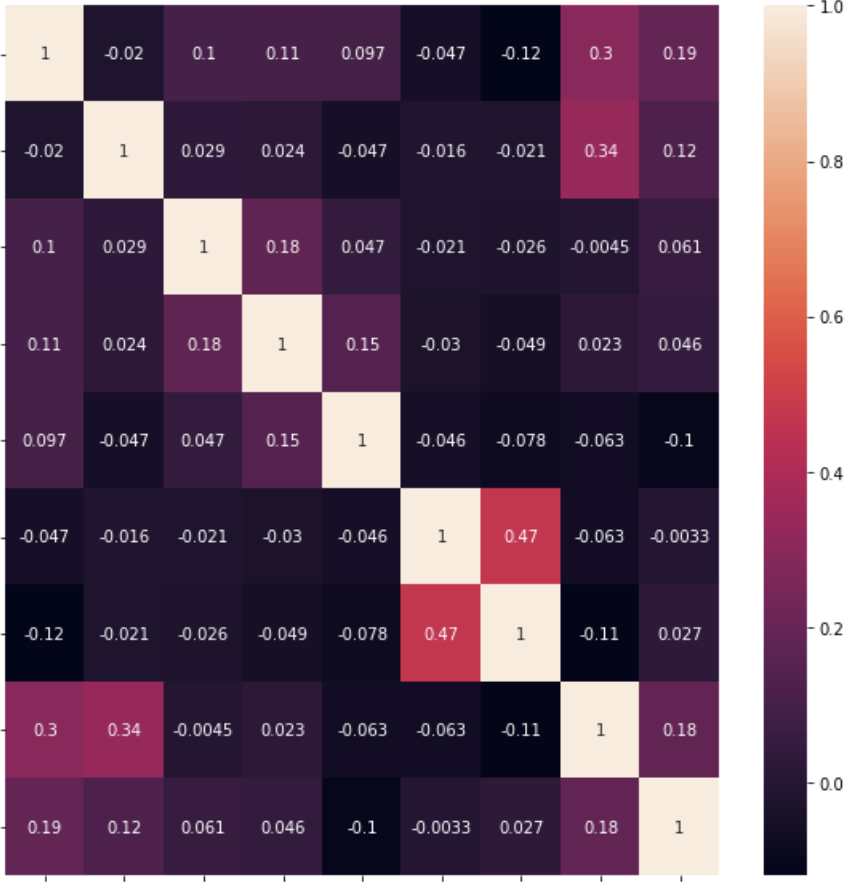
(다듬어야함)
