문제 출처 : https://www.acmicpc.net/problem/1012
미로 탐색과 같은 탐색 문제. 미로 탐색과는 다른 점이 있다면 DFS와 BFS 중 무엇이 더 효율적인지 생각이 나지 않았다는 것.
사고과정
배추!의 개수는 한정적이기 때문에 새로운 맵을 만들고 배추를 저장하는 것보다 배추 list 내부에서 index를 이용하여 조사하면 좀 더 효율적이지 않을까 싶어서 처음에는 이렇게 접근했다.
- 배추에서 한 개를 뽑고 남은 배추 list에서 뽑은 배추의 주변에 있는 배추가 있다면 deque를 이용하여 탐색한 배추 (deque)에 추가해주고 배추 list에서 찾은 배추는 제거한다.
[ 배추 주변에 있는지 판단하는 방식 : 방향을 이용하지 않고 좌표로 접근. (x',y'의 합)-(x,y의 합)의 절댓갑이 1 이면서, x나 y 중 같은 게 한개라도 있다. ]
중첩 반복문을 이용하면서 시간복잡도가 커질거라 생각을 했지만...
import sys
from collections import deque
T = int(sys.stdin.readline().rstrip("\n"))
# 필드 없이 짤라고 했는데, 그러면 시간복잡도가 너무 커질듯
# 이게 포함되는지 모르니까 K의 요소 하나하나 참조를 해봐야한다.
# 일단 필드 없이 짜보고 필드 있는 걸로도 짜보고 비교하자.
for _ in range(T) :
M, N, K = list(map(int,sys.stdin.readline().rstrip("\n").split()))
cabbage = [list(map(int,sys.stdin.readline().rstrip("\n").split())) for k in range(K)]
warm=0
while cabbage :
state = deque([cabbage.pop()])
while state :
now = state.popleft()
for n in cabbage :
if abs(n[0]+n[1]-now[0]-now[1])==1 and (n[0]==now[0] or n[1]==now[1]) :
state.append(n)
del cabbage[cabbage.index(n)]
#이럴 때 연결리스트를 사용하면 효율적
warm+=1
print(warm)
- 추가로 for 문 내부에서 for문의 변수를 건드리는 실수를 하지 말자. 요소가 삭제되면서 for문이 채 다 돌지 못하고 무시된다.
- index 함수는 시간복잡도가 O(1)이다 잘 이용하자
- DFS, BFS로 해결하자.
결과적으로 DFS와 BFS의 시간 차는 크지 않다.
import sys
T = int(sys.stdin.readline().rstrip("\n"))
dic=[[-1,0],[0,1],[1,0],[0,-1]]
def dfs(state) :
next_s=[state]
f[state[0]][state[1]]=0
while next_s :
s=next_s.pop() #여기만 pop(0)으로 바꿔주면 bfs
for n in range(4) :
ny,nx = s[0]+dic[n][0],s[1]+dic[n][1]
if ny>=0 and ny<=(N-1) and nx>=0 and nx<=(M-1) and f[ny][nx] == 1 :
f[ny][nx]=0
del cabbage[cabbage.index([ny,nx])]
next_s.append([ny,nx])
for _ in range(T) :
N, M, K = list(map(int,sys.stdin.readline().rstrip("\n").split()))
f = [[0 for m in range(M)] for n in range(N)]
cabbage=[]
warm=0
for k in range(K) :
y,x = list(map(int,sys.stdin.readline().rstrip("\n").split()))
cabbage.append([y,x])
f[y][x]=1
while cabbage :
dfs(cabbage.pop())
warm+=1
print(warm)DFS를 재귀가 아닌 STACK을 이용하여 해결!
다른 사람들은 더 효율적으로 풀었기에 참고해보자
그냥 map의 요소들 하나하나 탐색... 이게 제일 빠르네...?
import sys
sys.setrecursionlimit(10000)
T = int(sys.stdin.readline().rstrip("\n"))
dic=[[-1,0],[0,1],[1,0],[0,-1]]
def dfs(s) :
for n in range(4) :
ny,nx = s[0]+dic[n][0],s[1]+dic[n][1]
if ny>=0 and ny<=(N-1) and nx>=0 and nx<=(M-1) and f[ny][nx] == 1 :
f[ny][nx]=0
dfs([ny,nx])
for _ in range(T) :
N, M, K = list(map(int,sys.stdin.readline().rstrip("\n").split()))
f = [[0 for m in range(M)] for n in range(N)]
warm=0
for k in range(K) :
y,x = list(map(int,sys.stdin.readline().rstrip("\n").split()))
f[y][x]=1
for i in range(N) :
for j in range(M) :
if f[i][j]==1 :
f[i][j]=0
dfs([i,j])
warm+=1
print(warm)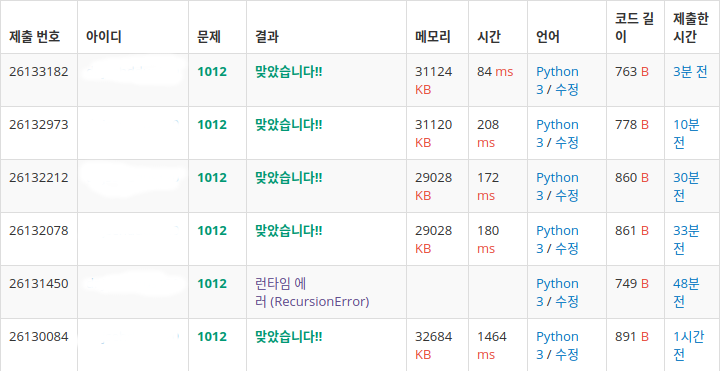
->중간에 208ms는 무시
사실 제일 간단한 방식인데 효율적으로 할려고 cabbage라는 걸 이용해서 할려했는데 되려 더 커져버렸다. 이 코드들을 비교하면서 연산횟수를 파악하고 어떤 방식을 택하면 시간복잡도가 더 커질지 생각할 수 있는 능력을 길러야겠다
1. while문 중첩. 연산량이 매우 큼.
2. del 함수 때문에 시간이 더 걸린 듯. del 함수는 시간 복잡도가 O(n)

세상은 너무나도 커