
[Reference] : 위 글은 다음 내용을 제가 공부한 후, 인용∙참고∙정리하여 만들어진 게시글입니다.
- 연결 리스트(List)
- STL list
- Q&A
- 마치며
1. 연결 리스트(List)
- 연결 리스트(List)
: 원소들을 저장할 때, 그 다음 원소가 있는 위치를 포함시키는 방식으로 저장한 자료구조
1) 연결 리스트의 성질
(1) k번째 원소를 확인 / 변경하기 위해 O(k)가 필요
예를 들어, 3 -> 13 -> 72 -> 5의 연결 리스트에서 72를 찾기 위해서는, 3을 거쳐 13을, 13을 거쳐 72로 가야함.
이는, 배열과 다르게 원소들이 연속적으로 위치하지 않기 때문.
(2) 임의의 위치에 원소를 추가 / 제거는 O(1)
(3) Cache hit rate가 낮음. 대신 메모리 할당은 쉬움
메모리 상에서 데이터가 연속적으로 위치하지 않음.
Cache hit rate는, 캐시된 데이터를 요청할 때 해당 키 값이 메모리에 존재하여 얼마만큼의 비율로 잘 찾았는지에 대한 비율.
2) 연결 리스트의 종류
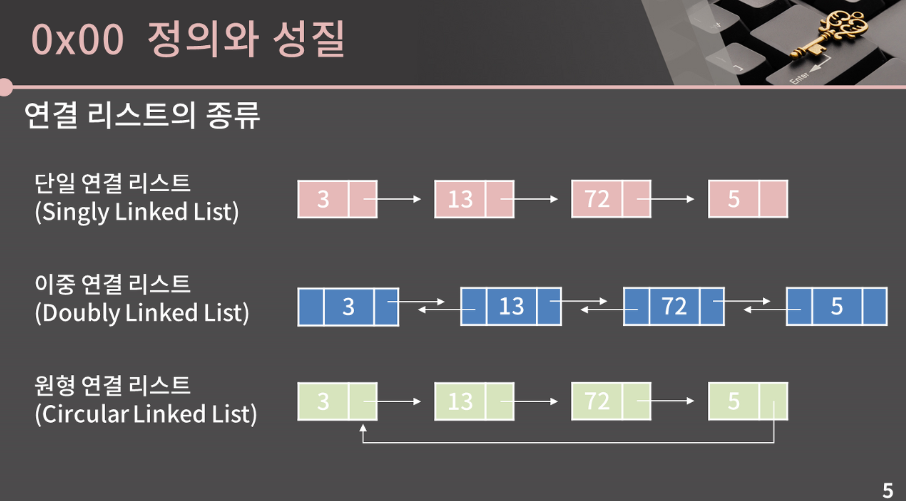
(출처 : '바킹독'님의 블로그 중 '[실전 알고리즘] 0x04강 - 연결 리스트')
(1) 단일 연결 리스트(Singly Linked List)
각 원소가 자신의 다음 원소의 주소를 들고 있는 연결 리스트
(2) 이중 연결 리스트(Doubly Linked List)
각 원소가 자신의 다음과 이전의 원소의 주소를 들고 있는 연결 리스트.
STIL의 연결 리스트에서, 컨테이너의 이름은 list이고, 구조는 이중 연결 리스트입니다.
(3) 원형 연결 리스트(Circular Linked List)
처음과 끝이 연결된 연결 리스트.
이 때 연결 리스트는 단일 / 이중 연결 리스트이다.
3) 배열과 연결 리스트
배열과 연결 리스트는,
메모리 상에서 데이터를 놓는 방식은 다르더라도, 원소들 사이에 선후 관계가 일대일로 정의됨
그래서 이 둘 자료형은, '선형 자료구조'라고 불림.
트리, 그래프, 해쉬 등은 '비선형 자료구조'라고 불림.
둘 다 선형 자료구조이므로, 면접에서 둘을 비교하라는 내용이 나오기도 하니 알고있어야 함!
(1) k번째 원소의 접근
- 배열 : O(1)
- 연결 리스트 : O(k)
(2) 임의의 위치에 원소 추가 / 제거
- 배열 : O(N)
- 연결 리스트 : O(1)
사실 엄밀히 말하면, 연결 리스트에 원소를 추가 / 제거 하는 경우,
임의 위치까지 찾아간 후에 O(1) 연산을 하는 것이므로 주의!
(3) 메모리 상의 배치
- 배열 : 연속적
- 연결 리스트 : 비연속적
(4) 추가적으로 필요한 공간(Overhead)
- 배열 : 필요 없음
- 연결 리스트 : O(N)
배열의 경우 데이터만 저장하면 되니 추가 공간 필요 없음
(굳이 따지자면, 길이 정보를 저장할 int 1개가 필요할 수 있지만 미미하므로 신경 쓸 필요 없음)
연결 리스트의 경우, 데이터 뿐만 아니라, 다음 / 이전 원소의 주소값을 가지고 있어야 하므로,
32비트 체제의 경우 4N(32비트)바이트,
64비트 체제의 경우 8N(64비트)바이트가 추가적으로 필요.
즉, N에 비례하는 만큼 메모리를 추가로 쓰게 됨.
즉, 임의의 위치에 원소를 추가하거나 제거하는 연산을 많이 해야하는 경우, 연결 리스트의 사용을 고려할 수 있음.
3) 연결 리스트의 직접 구현
(1) 정석적인 구현
struct NODE{
struct NODE *prev, *next;
int data;
};코테에서는 STL list를 사용하기.
만약 STL이 사용불가하면 2번 방법을 활용하기.
위의 코드 경우 면접에서 손코딩을 시키거나 질문을 하는 경우가 있기 때문에 알고는 있어야 함.
(2) 코테에서 STL 사용이 불가할 때
#include <bits/stdc++.h>
#define fastio cin.tie(0)->sync_with_stdio(0)
using namespace std;
const int MX = 1000005;
int dat[MX], pre[MX], nxt[MX];
int unused = 1;
void traverse(){
int cur = nxt[0];
while(cur != -1){
cout << dat[cur] << ' ';
cur = nxt[cur];
}
cout << '\n\n';
}
void insert(int addr, int num) {
// 1. Write new element
dat[unused] = num;
pre[unused] = addr;
nxt[unused] = nxt[addr];
// 2. Fix pre & nxt element's information
if(nxt[addr] != -1) pre[nxt[addr]] = unused;
nxt[addr] = unused;
// 3. Fix unused
unused++;
}
void erase(int addr){
// 1. Fix pre & nxt element's information
nxt[pre[addr]] = nxt[addr];
if(nxt[addr] != -1) pre[nxt[addr]] = pre[addr];
// 2. Fix unused
unused--;
}
int main (){
fastio;
fill(pre, pre + MX, -1);
fill(nxt, nxt + MX, -1);
}원소를 배열로 관리하고, pre와 nxt에 이전 / 다음 원소의 포인터 대신, 배열 상의 인덱스를 저장하는 방시긍로 구현한 연결 리스트.
메모리 누수 때문에 실무에서는 사용할 수 없지만,
구현 난이도가 낮고 시간복잡도도 동일해 코테에서는 활용 가능.
코드 상에서,
dat[i]는 i번지 원소의 값,
pre[i]는 i번지 원소에 대해 이전 원소의 인덱스,
nxt[i]는 i번지 원소에 대해 다음 원소의 인덱스.
만약 pre와 nxt의 값이 -1인 경우 이전 / 다음 원소는 존재하지 않는 경우임.
unused는 현재 사용되지 않는 인덱스, 즉 새로운 원소가 들어갈 수 있는 인덱스이고 원소가 추가된 이후에는 1씩 증가시킴.
특별히 0번지는 연결 리스트의 시작 원소로 고정되어 있음. 따라서 값이 들어가지 않고 시작점을 나타내기 위한 dummy node.
0번지의 dat값은 -1, pre는 -1, nxt는 다음 원소의 번지 인덱스를 적으면 됨.
(dummy node를 만들어야 예외 처리가 쉬워짐. 만약 원소가 없는 경우, 원소 추가 / 삭제를 생각할 때 dummy node가 있는게 쉬움)
만약 길이 정보가 필요하면 len변수를 선언하고 추가 / 제거 될때 1씩 증가 / 감소시키면 됨.
2. STL list
st::list는 Doubly Linked List로 구현되어 있습니다.
임의의 위치에 원소를 삽입 / 삭제(O(1) : 해당 원소의 위치를 알 고 있을 때만... 모르면 해당 위치로 일일이 찾아가야 함...)할 수 있지만,
[]연산자를 이용해 접근할 수 없으며, 처음부터 하나씩 접근해야만 합니다.
따라서, list는 1) 중간 위치에서 삽입, 삭제가 빈번하게 일어나고,
2) 데이터에 랜덤하게 접근하지 않는 경우가 많을 때 사용됩니다.
1) 생성자
1. list<int> L;
2. list<int> L(n); 또는 list<int> L(n, val);
3. list<int> L{1, 2, 3}; 또는 list<int> L = {1, 2, 3};- 비어있는 리스트를 생성합니다.
- n개의 원소를 갖는 리스트를 생성합니다.
후자는 n개의 원소를 val값으로 초기화합니다. - initializer_list를 인자로 받는 생성자
2) 멤버 함수
// L = { 1, 2, 3 }
list<int> L = { 1, 2, 3 };
auto it1 = next(L.begin()); // *it1 == 2
// L = { 1, 10, 2, 3 }, *it1 == 2, *it2 == 10
auto it2 = L.insert(it1, 10);
// L = { 1, 2, 3 }, *it2 == 2
it2 = L.erase(it2);(1) push_back / push_front
마지막 / 시작 위치에 원소를 삽입. O(1)
emplace_back, emplace_front로 대체 가능.
(2) pop_back / pop_front
마지막 / 시작 위치의 원소를 삽입. O(1)
반환값은 void.
(3) insert / erase
매개변수로 받은 itertor의 위치의 앞에 원소를 삽입. O(1)
insert는 emplace로 대체 가능.
매개변수로 받은 iterator 위치의 원소를 삭제 후, 원래 위치의 다음 원소의 itertator 반환. O(1)
이 때, erase의 인자로 전달한 iterator는 무효화(invalidated)되기 때문에 *it, it++ 등으로 사용하면 UB를 발생시킴.
그래서 일반적으로, it = erase(it)으로 사용하여 이를 방지함.
// L = { 1, 2, 3 }
list<int> L = { 1, 2, 3 };
// *** Result : 3 ***
cout << L.size();
// *** Result : 1 2 ***
L.resize(2);
for(auto i : L) cout << i ;
// *** Result : False ***
cout << L.empty();
// *** Result : True ***
L.clear();
cout << L.empty();(4) size / resize
list의 크기를 size_t 자료형으로 반환.
list의 크기를 변경.
list의 크기를 변경
변경될 크기가 원래의 크기보다 작은 경우, 뒤의 원소부터 차례로 지워지고,
원래의 크기보다 큰 경우, 두 번째 인자가 없는 경우 초기값, 있는 경우는 해당 값으로 남은 칸이 채워짐.
(5) empty / clear
list가 비어있는지 여부를 bool 자료형으로 반환.
list의 모든 원소를 삭제
// L = { 1, 2, 3 }
list<int> L = { 1, 2, 3 };
// *** Result : 1 3 ***
cout << *L.begin() << ' ' << *L.end();
// *** Result : 3 1 ***
cout << *L.begin() << ' ' << *L.rend();
// *** Result : 1 3 ***
cout << L.front() << ' ' << L.back();
// *** Result : 1 2 3 4 5 ***
L = { 3, 1, 2, 4, 5 };
L.sort();
for(auto i : L) cout << i << ' ';(6) begin / end
list의 첫번째 원소를 가리키는 iterator 반환
list의 마지막 원소의 다음 칸을 가리키는 iterator 반환
(7) rbegin / rend
begin의 reserve_iterator 버전
end의 reserve_iterator 버전
(8) front / back
list의 첫번째 원소를 reference로 반환. O(1)
list의 마지막 원소를 reference로 반환. O(1)
빈 vector에서 둘을 호출하는 것은 'UB(Undefined Behavior)'
(9) sort
list 내의 원소를 정렬. O(nlogn)
sort는 merge sort로 구현.
첫 번째 인자로 cmp를 넣어줄 수 있으며,
생략한 경우 less<>{}가 default parameter로 들어감.
list의 원소를 정렬할 경우, std::sort 대신 L.sort()를 사용해야 함.
(random access iterator가 없기 때문)
(10) 참고
list의 iterator는 random access iterator가 아니라, bidirectional iterator임
따라서, L.begin() + 3과 같은 + 연산을 지원하지 않음.
따라서, iterator를 이동시키기 위해서는, it++, it--와 같은 증감연산자를 사용해야함.
이 떄 증감연산자 대신,
std::prev, std::next함수를 이용할 수 있음.
만약 여러 칸을 이동해야 하면, std::advance를 사용할 수도 있음.
단, std::advance의 시간복잡도는 O(n)임에 주의.
또한, list의 iterator는 iterator 간의 -연산을 지원하지 않아서, it - v.begin() 등으로 인덱스를 구할 수 없음.
이 떄는, O(n)의 시간복잡도를 가지는 std::distance를 사용
(보통 이러한 연산은 피하는게 나음)
3. Q&A
1) iterator(반복자)
http://www.tcpschool.com/cpp/cpp_iterator_category
4. 마치며
-
[Reference] : 위 글은 다음 내용을 제가 공부한 후, 인용∙참고∙정리하여 만들어진 게시글입니다.
