
이번에는 제어문과 자료구조(배열이나 컬렉션, set, Hash(있나..?)) 를 공부했고 정리하도록 하겠다.
그리고... 여러번 반복하지만 제어문 까지는 비슷하니까 살짝만..
시작!
조건문
조건문이란?
특정 조건에 따라 다른 연산을 수행하거나 동일한 연산을 반복할 때 사용한다.
조건문의 종류
- if
- switch case
If문
특정 조건에 따라 연산을 시행하고 싶을 때 사용하는 제어문이다.
if(조건) {
연산
}위의 형태로 사용되며 조건이 true일 때 연산을 진행한다.
만약 조건이 false라면 if-else 나, if-else if 를 사용하여 여러가지 조건에 맞는 연산을 수행할 수 있다.
if(조건) { if(조건){
연산 연산
} else { } else if (조건) {
연산 연산
} } else {
연산
}또한 if문은 중첩하여 복잡한 조건을 처리할 수 있다.
Switch문
switch문은 switch와 case로 존재한다.
각각 switch(피연산자) case (조건)이며 사용 방식은 아래와 같다.
int x = 0;
switch (x // 조건의 피연산자) {
case 0(조건):
연산;
break;
case 1:
연산;
break;
default:
연산;switch에 피연산자가 들어오면 case의 조건과 일치하는 case의 연산이 실행된다.
switch-case에서 중요한 점은 break인데 break가 존재하지 않으면 switch-case가 끝나지 않는다.
또한 default역시 생략되서는 안되는 구문이다. default가 없으면 case에 맞는 조건이 없을 경우에 빠져나가는 길이 없는 것이기 때문에 처리할 수 없게된다.
조건문의 차이
- 피연산자의 갯수 차이
- 코드의 복잡성
피연산자의 갯수 차이
-
if문의 경우 if (조건)에 여러 개의 피 연산자 존재할 수 있다.
if(x==1)이라는 간단한 조건부터 if(x==1 && y==1) 처럼 논리 연산자를 통한 조건처럼 여러가지의 조건이 올 수 있다. -
switch-case는 switch(피연산자) 자리에 하나의 값 밖에 올 수 없다.
따라서 복잡한 조건을 구현해야 할 때는 if문의 활용도가 더 높다.
코드의 복잡성
-
if문은 첫 if문의 조건이 만족하지 않는다면 else if로 맞는 조건을 찾거나 else로 전체를 아니게는 처리할 수 있다.
그렇지만 각각 조건에 맞는 else if를 구현한다면 if후에 else if로 조건문이 도배가 되는데 이러한 부분에서 코드의 복잡성이 높아져 가시성이 떨어지게 된다. -
switch-case는 case를 통해 조건을 맞추기 때문에 case를 늘려 많은 양의 코드를 작성해도 가시성이 높아 복잡성이 떨어진다.
반복문
특정 조건에 따라 같은 연산을 반복적으로 하고 싶을 때 사용한다.
반복문의 종류
- for문
- 향상된 for문
- while문
- do~while문
for문
for(초기값; 조건문; 증감연산) { 반복할 연산 }초기값이 조건문을 만족할 때 까지 증감연산을 반복하여 반복할 연산을 계속 수행한다.
향상된 for문
int[] array = new int[]{1, 2, 3, 4, 5};
for(int arrayValue : array) {
System.out.println(arrayValue);
}의 형태로 반복문이 구현된다.
arrayValue에는 array의 요소가 들어간다.
(잠깐 잡담을 조금 섞자면 향상된 for문은 정말 기억이 안났는데 python에서 똑같이 쓴게 있어서 다행이랄까...??)
while, do ~ while
while (조건) {
연산
}do {
연산
} while (조건)while문은 위의 형태로 구현된다.
둘 다 조건문을 만족하는 경우에만 반복이 실행되며 한번 반복할 때 마다 조건문이 만족하지 않을 때 반복을 중단한다.
둘의 차이
- while은 조건이 만족하지 않으면 시작하지 않는다.
- do ~ while은 조건이 만족하지 않아도 최초 1회 연산을 실행한 뒤 조건을 판별한다.
continue, break
break: 호출된다면 가장 가까운 반복문을 중단한다. switch-case 의 경우 switch문을 종료한다.
continue: 반복문에서 사용되며 반복중 continue문을 만나게 되면 해당 반복 순서는 패스되어 continue 다음부터 다음 반복 시작 전 까지의 연산이 생략된다.
for(...) {
...
조건() { // 해당 조건을 만족했을 때
continue; // continue문을 지나치게 되면
}
연산1; // 연산 1과 2는 이번 루프에서 생략된다.
연산2;
}자료구조
배열
배열이란 같은 타입의 변수를 하나의 변수에 저장하고 싶을 때 사용하는 자료구조다.
배열은 한 번에 많은 양의 데이터를 저장하거나 연산할 때 사용된다.
Java에서의 배열 선언
int[] array;
int array[];Java에서의 배열 생성
배열의 생성은 new 키워드를 통해 생성하며 new는 참조형 변수들을 생성하는 키워드이기 때문에 생성된 배열들은 주소값을 저장한다.
int[] array = new int[]{1, 2, 3, 4, 5};
int[] array2;
array2 = new int[]{10, 20, 30, 40, 50};
int array3[] = new int[5];
for(int i = 0; i < array3.length; i++) {
array3[i] = i+5;
System.out.println(array3[i]);
}일반적으로 자바에서 배열의 선언과 초기화하는 과정은 한 줄에서 작성하는것을 권장하지만 위의 케이스처럼 선언과 초기화를 분리하는 방법도 있다.
주소값 (Heap과 Stack 복습)
new 키워드는 참조형 변수를 생성하는 키워드다.
참조형 변수는 Heap영역에 생성된 주소 값을 가지게 된다.
학부시절에 자바를 배웠을 때에도 new연산자 개념이 조금 어려웠는데 다시 정리하자면 다음과 같다.
int[] array = new int[]{1, 2, 3, 4, 5}; // 이렇게 변수를 선언했다 array 는 Stack영역에 생성되며, new int[]{1, 2, 3, 4, 5}; 는 Heap영역에 생성된다. array는 여기서 Heap영역에 생성된 배열의 주소를 가르킨다. 요약하자면 array는 Stack에 생성되어 저장하지만 참조하는 실제 데이터는 Heap 영역에 저장된다.
Java에서의 배열 순회
배열에 있는 변수 하나씩 꺼내 사용하는 것을 순회라 한다.
int array3[] = new int[5];
for(int i = 0; i < array3.length; i++) {
array3[i] = i+5;
System.out.println(array3[i]);
}처럼 for문을 사용하여 배열을 순회하는 것이 일반적이며,
변수명[index]를 통해 하나씩 접근도 가능하다.
Java에서의 배열 초기화
배열을 초기화 할 때는
int[] array = new int[]{1, 2, 3, 4, 5};
{}를 통하여 초기화 하거나 for문을 통해 인덱스 하나씩 접근하여 값을 초기화 할 수 있다.
또한 Arrays.fill이라는 메서드를 사용하여 초기화 할 수 있다.
(Arrays 클래스는 Java에서 기본적으로 제공하는 메소드가 담긴 클래스다.)
Java에서의 배열 복사
얕은 복사
int[] array = new int[]{1, 2, 3, 4, 5}; int[] array2; array2 = array
와 같은 방식으로 복사하려고 하면 나중에 array2의 값을 변경할 때 array의 값도 변경된다.
그 이유는 아까 주소값에 대한 얘기로 array는 new 키워드를 통해 생성되었을 때 Heap영역에 있는 주소값을 데이터로 가지는 것이기 때문에
array2 = array
같은 과정을 통해 복사하게 되면 array2도 array가 가지고 있는 주소값을 데이터로 가지게 되므로 두 배열이 가지고있는 데이터는 같은 주소값을 가지고 있는것과 같다.
이렇게 복사되는 과정을 얕은 복사라고 한다.
깊은 복사
깊은 복사는 배열의 주소값을 가져가는 것이 아닌 인덱스에 직접 접근하여 실제 값을 복사하는 과정이다.
반복문을 통해 순회하며 주소에 접근해 주소가 지닌 실제 값을 넘겨주는 방법이 있고,
또한 메서드를 이용하여 깊은 복사를 할 수 있다.
- clone()
int[] array = {1,2,3,4}; int[] array2 = array.clone()
- Arrays.copyOf()
int[] array = {1,2,3,4}; int[] array2 = Array.copyOf(array, array.length); //배열과 배열의 길이도 같이 넣어줘야 한다.
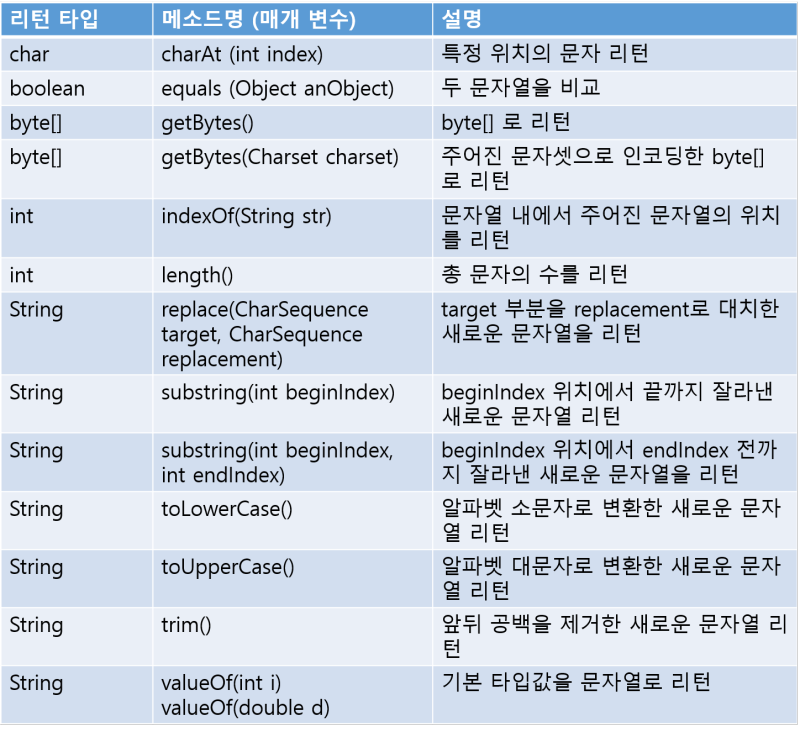
String 배열
String 배열은 위에서 정리한 배열과 기본적인 부분은 같으며 다른 부분만 다루겠다.
char 배열은 문자열(Sting)과 같은 맥락으로 기능하는데 String 배열은 참조형 변수로 사용할 수 있는 여러가지 메서드가 존재한다.
다차원 배열
다차원 배열은 배열 안에 또 다른 배열이 존재하는 것을 말한다.
선언
다차원 배열의 선언은 1차원 배열에 대괄호를 추가하는 것으로 선언된다.
int[][] array; int array[][];
생성
따라서 다차원 배열을 생성할 때 역시 대괄호를 선언할 때의 갯수만큼 추가해야한다.
int[][] array = new int[][];
초기화
따라서 다차원 배열을 생성할 때 역시 대괄호를 선언할 때의 갯수만큼 추가해야한다.
int[][] array = new int[2][3] { {1,2,3},{4,5,6} };
가변 배열
행 마다 다른 길이의 배열을 요소로 저장할 수 있다.
int[][] array = new int[2][]; array[0] = new int[2]; array[1] = new int[8]; { {1,2},{3,4,5,6,7,8,9,0} };
끝!
공부하면서 자바개인과제 level1을 같이 병행하여 작업했다.
https://github.com/WonGi-Kim/sparta_calculator_level1.git
후기1.
생각보다 정리할 내용이 많아져서 컬렉션의 내용은 다음으로 미뤄야겠다..
한 번에 공부하고 정리한다 해도 어차피 머리에 안들어올거 같으니까...
컬렉션은 내용도 많을거 같기도 하고....
후기2.
level1은 병행하면서 할 만 했는데 level2는 정리 꼼곰히 하면서 해야할듯!
