
원래는 메모리 구조에 대해서 포스팅하려던건 아녔고, 재귀와 반복문의 차이 그리고 왜 재귀에서 적절하게 빠져나오는 구문이 없다면 stackOverFlow가 될까?를 포스팅하려 했다.
보통은 재귀에서 적절하게 빠져 나오지 못하면 콜스택이 터졌다라고 하는데 감으로는 이해했지만 누구에게 설명하라고하면 자신이 없었기에 이번에 확실하게 짚고 넘어가려 한다.
포스팅을 위해 공부를 하다보니 운영체제의 메모리 구조와 관련이 있을거 같고, 도움이 될거 같아서 포스팅한다.
메모리 구조
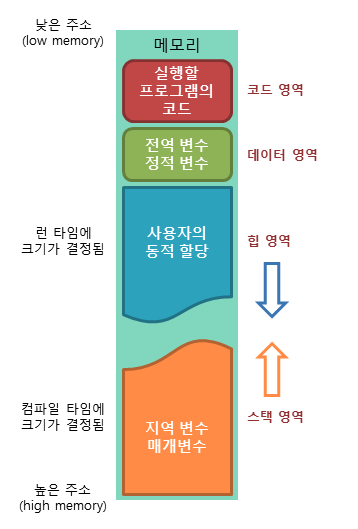
프로그램이 운영체제로부터 할당받는 대표적인 메모리 공간은 다음과 같다.
코드(Code) 영역
실행할 프로그램의 코드가 저장되는 영역이다.
프로그램이 시작하고 끝날 때까지 메모리에 계속 남아 있는다.
컴파일된 기계어가 들어가게 된다.
CPU는 코드 영역에 저장된 명령어를 하나씩 가져가서 처리한다.
데이터(Data) 영역
프로그램의 전역 변수와 정적 변수, 문자열 상수가 저장되는 영역이다.
프로그램이 시작하고 끝날 때까지 메모리에 계속 남아 있는다.
스택(Stack) 영역
함수의 호출과 관계되는 지역 변수와 매개변수가 저장되는 영역이다.
함수의 호출과 함께 할당되며 함수의 호출이 완료되면 소멸한다.
이렇게 스택 영역에 저장되는 함수의 호출 정보를 스택 프레임(stack frame)이라고 한다.
프로그램이 자동으로 사용하는 임시 메모리 영역이다.
컴파일 시에 크기가 결정된다.
힙(Heap) 영역
사용자가 직접 관리할 수 있고 해야만하는 영역이다.
힙 영역은 사용자에 의해 메모리 공간이 동적으로 할당되고 해제된다.
malloc()/new 연산자를 통해 할당하고, free()/delete 연산자를 통해서 해제가 가능하다.
런타임 시에 크기가 결정된다.
(Swift/iOS는 이부분에 대해서 알아둬야할 부분이 있지... Memory Leak에서 한 번 피 봐서 우는거 아님...)
Stack vs Heap
Stack과 Heap은 OS/컴퓨터 구조에서 빈번하게 비교되는 주제이다.
- 메모리 구조상 Stack이 커지면 Heap이 작아지고, Stack이 작아지면 Heap이 커지는 구조이다.
그렇다면 할당 속도는 누가 더 빠를까?
Stack은 이미 할당 되어 있는 공간을 사용하므로 포인터의 위치만 바꿔주는 단순한 CPU Instruction이다.
하지만 Heap에서의 할당은 동적인 메모리 영역으로 고려해야하는 요소가 많아 Stack보다 많은 CPU Instruction을 필요로 한다.
결론은 Stack이 할당 속도가 훨씬 빠르다.
하지만 Stack의 공간이 작아 모든 응용에서 사용할 수는 없다.
Overflow
그렇다면 내가 궁금했던, Overflow에 대해서 알아보자.
우선 Overflow가 생기는 이유에 대해서 생각해본다면 Stack과 Heap에 채워지는 메모리 주소의 방향이 달라서이다.
Stack은 주소값이 위에서부터 채워진다.
반면 Heap의 주소값은 아래에서부터 채워져 내려온다.
이때, 두 메모리 영역의 주소가 겹치게 되면 Overflow가 발생한다.
Heap Overflow
Heap이 아래에서부터 주소값을 채워져 올라가다 Stack영역을 침범한 경우이다.
Stack Overflow
Stack 영역이 Heap을 침범한 경우이다.
재귀 vs 반복문
이 주제에 대해 얘기하기 전에 메모리 Stack에 대해서 알아둬야하는 것은
- 함수의 호출과 관계되는 지역 변수와 매개변수가 저장되는 영역이다.
- 함수의 호출과 함께 할당되며 함수의 호출이 완료되면 소멸한다.
이것들이다.
위의 내용을 기억한 채로 내용을 진행해본다.
콜 스택(Call Stack)이란 무엇일까?
이름에서 알 수 있듯이 stack의 구조를 따르고 있다.
프로그램이 함수 호출(Function Call)을 추적할 때 사용하는 것이다.
콜 스택은 각 function call당 하나씩의 스택 블록으로 이루어져 있다.
예시를 통해 좀 더 자세하게 알아보자
func roll_die() -> Int {
return Int.random(in: 1...6)
}
func rollTwoAndSum() {
var total = 0
total = total + roll_die()
total = total + roll_die()
print(total)
}
rollTwoAndSum()- 프로그램은 rollTwoAndSum()을 호출하고, rollTwoAndSum()은 콜 스택으로 이동한다.
rollTwoAndSum()
- rollTwoAndSum()은 roll_die()를 호출한다.
roll_die()
rollTwoAndSum()
- roll_die() 내에서 Int.random(in:)을 호출한다.
Int.random()
roll_die()
rollTwoAndSum()
- Int.random(in:)의 실행이 끝나면, 스택에서 제거되고, 값은 roll_die()에게 반환된다.
roll_die()
rollTwoAndSum()
- roll_die()가 return된다.
rollTwoAndSum()
.... 이런식으로 함수가 호출될때마다 콜 스택에 쌓이게 된다.
그렇다면 나는 왜 재귀와 반복문에 대해서 얘기하려 했을까?
나는 PS를 풀때 아니면 의도적으로 재귀를 피하려고 한다.
그 이유는 재귀는 적절한 때에 탈출 조건이 있어야만 안 터지고 잘 굴러가기 때문이다.
이게 PS를 풀때에는 조건이 제한되어 있다보니 재귀를 적절하게 탈출할 수 있는데 실제 서비스에서는 내맘대로 안된다ㅋㅋㅋ
진짜 안된닼ㅋㅋㅋㅋㅋㅋ
한번도 되는걸 못 봤닼ㅋㅋㅋㅋㅋ(늘 내 예상을 뛰어넘는 사용자들이다.)
그렇다면 재귀를 사용하면 어떤 문제가 있을까?
프로그램에 재귀를 짜게되면 우선, 하나의 함수가 끝나지 않았는데 또 다시 함수를 호출해 콜 스택이 쌓인다.
우리는 위에서 메모리의 Stack 영역은 크기가 정해져 있다고 했고, 크기를 넘어서면 overflow가 된다고 했다.
물론 우리가 여기서는 무조건 재귀가 2번일꺼야라고 단정지을 수 있는 상황이라면 재귀를 사용해도 아무 문제 없을것이다.
하지만 늘 사용자는 내 예상을 벗어나기에 재귀를 몇 번 돌지는 아무도 모른다.
그렇기에 누군가는 overflow로 시스템이 터질 것이고, 누군가는 정상작동되겠지..
이것이 내가 재귀를 의도적으로 피하는 이유고, 그렇다면 반복문과 재귀가 다른점은 무엇일까?
재귀는 재귀를 도는만큼 함수를 호출하기 떄문에 콜스택이 계속 쌓인다고 했다.
그렇다면 반복문은?
반복문은 콜스택에 1개 쌓인다.
(물론 반복문도 탈출 못하면 문제긴 하지만..ㅋㅋ)
