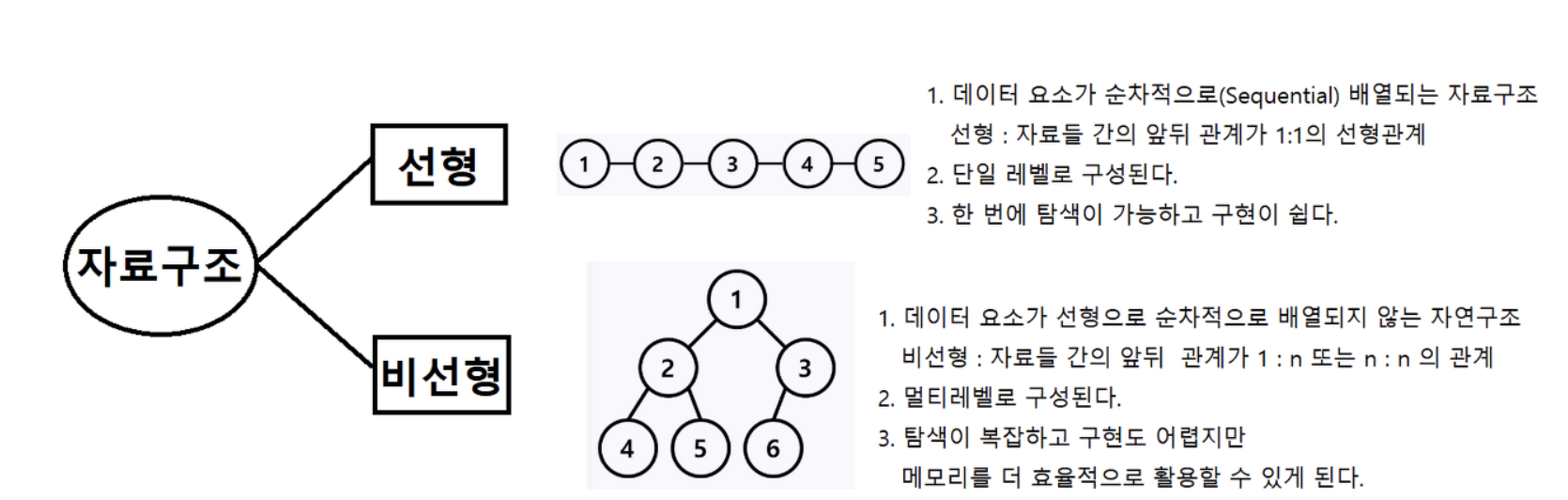
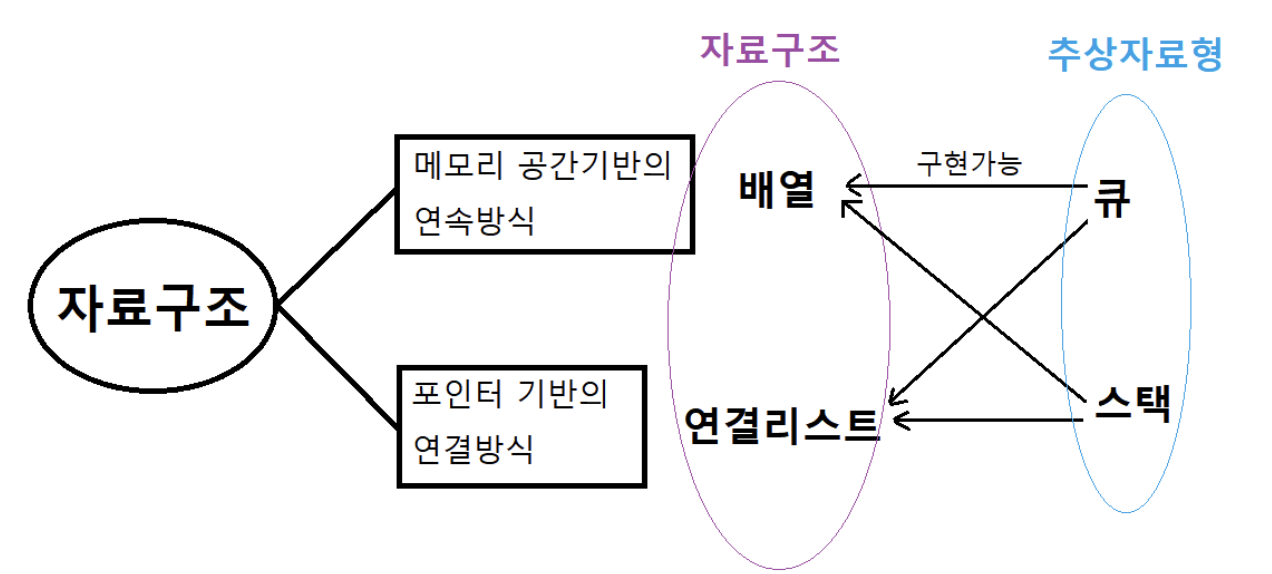
스택과 큐는 자료형의 연산, 그 행동만 정의되어 있고
구현 방법은 정의되어 있지 않은추상 자료형이다.
반면,
배열은 연속적으로 저장되어 있어야 하고
연결리스트는 다음 데이터의 위치를 저장하는 방식이어야 하는 자료구조다.
1. ⚡️ Stack
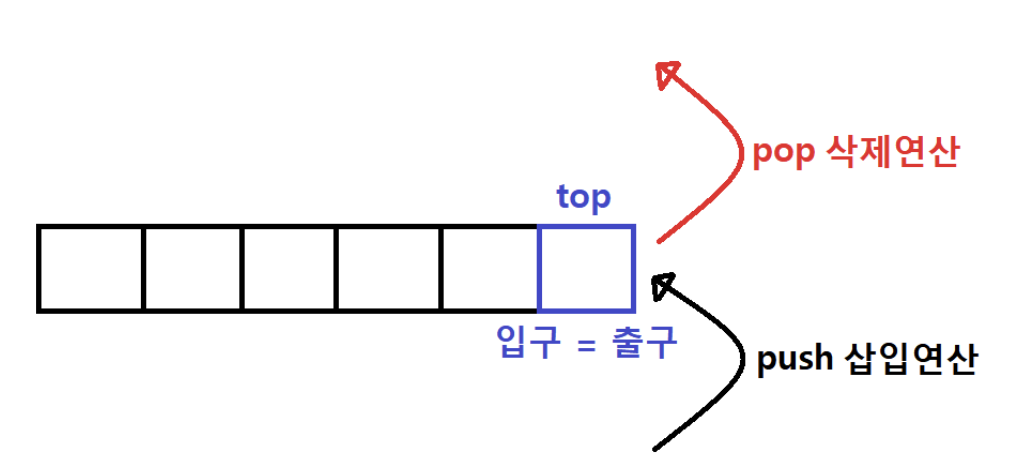
1-1. 정의
스택은 후입선출(LIFO : Last in First Out)의 개념으로 만들어진 자료구조로, 마지막으로 넣었던 값이 가장 먼저 뽑히는 구조라고 할 수 있습니다.
1-2. 활용 예
- 스택은 데이터를 짚어넣는 선형 구조인 후입선출 구조로 예를 들어 빨래통에 비유할수 있습니다.
세탁물들은 아래에서부터 차곡차곡 쌓이고 , 빨래물을 꺼낼때는 위에 있는 세탁물부터 꺼내게 되는 원리와 같다. - undo : 실행취소
1-3. 스택(Stack)의 선언
스택을 선언하는 방법은 아래와 같습니다.
Stack<Integer> myStack=new Stack<Integer>();
System.out.println(myStack.toString()); //[]이전에 다루었던 ArrayList나 Queue를 선언하는 방법과 비슷합니다. 꺾쇠< >안에는 스택 안에 저장 할 값의 형태를 넣게 됩니다. 생성 직후 출력을 해 보면 아무것도 들어있지 않아 []형태로 출력되는 것을 볼 수 있습니다.
스택(Stack)의 주요 메서드
스택의 주요 활용 메서드를 살펴보겠습니다.
//1. add, push
myStack.add(15);
myStack.push(12);
myStack.add(43);
myStack.add(11);
System.out.println(myStack.toString()); //[15, 12, 43, 11]
//2. peek
System.out.println(myStack.peek()); //11
System.out.println(myStack.toString()); //[15, 12, 43, 11]
//3. pop
System.out.println(myStack.pop()); //11
System.out.println(myStack.toString()); //[15, 12, 43]
//4. size
System.out.println(myStack.size()); //3
//5. clear
myStack.clear();
//6. isEmpty
System.out.println(myStack.isEmpty()); //true2. ⚡️ Queue
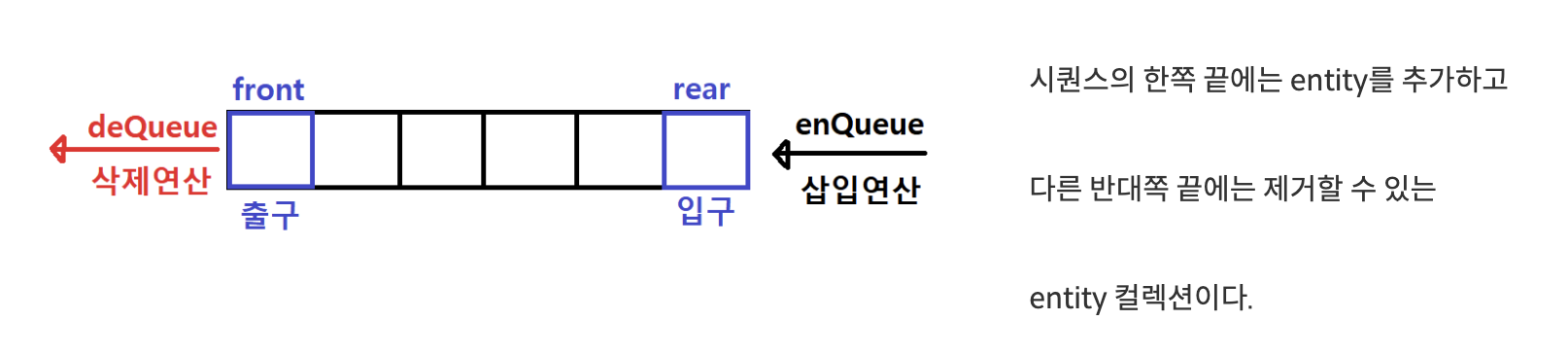
2-1. 정의
큐는 데이터를 집어넣는 선형구조로 선입선출(FIFO : First In First Out) 구조입니다.
JAVA에서의 큐는 LinkedList의 인터페이스 형태로 구현이 되어있습니다. 따라서 그 크기가 가변성이 뛰어나며, 자료를 넣고 빼는데에 있어 속도가 무척 빠른 특징을 가집니다.
2-2. 큐 사용 사례
- 프로세스 관리
- 너비 우선 탐색(BFS, Breadth-First Search) 구현
- 캐시(Cache) 구현
2-3. 큐(Queue)의 선언
큐를 선언하여 생성하는 방법은 다음과 같습니다.
Queue<Integer> myQ=new LinkedList<Integer>();
System.out.println(myQ); //[]2-4. enQueue DeQueue
- 이때 삭제연산만 수행되는 곳을 프론트(front), 삽입연산만 이루어지는 곳을 리어(rear)라 부른다.
- 큐의 리어에서 이루어지는 삽입연산을 인큐(enQueue) 프론트에서 이루어지는 삭제연산을 디큐(dnQueue)라고 부른다.
2-5. 큐의 종류
2-5-1. 큐를 일반화한 데크/덱(Deque)
데이터를 양쪽에서 넣고 뺄 수 있는 구조로 스택과 큐가 합쳐진 구조라고 생각하면 됩니다.
https://hbase.tistory.com/128
2-5-2. 원형큐
선형 큐는 front 와 rear가 가장 멀리 떨어져 있는 선형 모양의 큐지만, 원형 큐는 front와 rear가 배열의
상태에 따라 이동하며, 둥근 배열에서 offer을 하면 front가 뒤로 이동하고, poll을 하면 rear가 뒤로 이동하며
만날 수 있는 형태가 된다.
2-5-3. 우선순위큐(Priority Queue)
2-5-3-1. 정의
우선순위 큐(Priority Queue)는 먼저 들어오는 데이터가 아니라, 우선순위가 높은 데이터가 먼저 나가는 형태의 자료구조로 바로 자동으로 정렬입니다.
2-5-3-2. 우선순위 큐는 정렬이 된다고 했는데 출력결과는 정렬이 되지 않은 형태로 출력이 됩니다. 그 이유는?
우선순위 큐는 힙을 사용하여 구성되며 내부구조는 이진트리 형태로 구성되어있습니다.
값을 큐와 마찬가지로 삽입할 때 add를 이용해 가장 마지막에 넣은 후 , 자신보다 작은 부모노드를 찾을 때 까지 이동시키는 과정을 통해 값의 위치가 정해집니다. 이진트리 형태로 저장되기 때문에 출력 당시에는 오름차순이 아닌 형태로 보여지지만 값을 꺼낼때는 가장 작은 값부터 오름차순으로 값이 꺼내짐으로 정렬이 되어지는것을 확인 할 수 있습니다.
2-5-3-3. 내림차순으로 사용하는 방법
우선순위 큐는 오름차순을 기준으로 정렬이 되어버립니다. 혹시 내림차순으로 사용하고 싶으면 어떻게 해야할까요. 우선순위 큐는 있지만 우선순위스택이라는 자료구조는 없습니다. 대신 이런 방법을 사용하게 됩니다.
PriorityQueue<Integer> reversePQ=new PriorityQueue<Integer>(Collections.reverseOrder());늘 비어있던 오른쪽 소괄호 안에
Collections.reverseOrder()넣음으로 , 기존의 비교를 위한 과정을 반대로 적용하라는 뜻입니다.
위의 형태로 우선순위 큐를 생성하게 되면 값을 꺼낼 때 가장 큰 값부터 순차적으로 peek과 poll하게 됩니다.2-5-3-4. 우선순위 큐(Priority Queue)의 선언
우선순위 큐는 기본적으로 큐(Queue) 의 사용방법과 동일합니다. 우선순위 큐를 선언하는 방법은 아래와 같습니다.
PriorityQueue<Integer> myPq=new PriorityQueue<Integer>();
System.out.println(myStack.toString()); //[]2-5-3-5. 우선순위큐(Priority Queue)의 주요 메서드
//1. add
myPQ.add(3);
myPQ.add(7);
myPQ.add(1);
myPQ.add(4);
System.out.println(myPQ); //[1, 4, 3, 7]
//2. peek
int temp=myPQ.peek();
System.out.println(temp); //1
System.out.println(myPQ); //[1, 3, 4, 7]
//3. poll
temp=myPQ.poll();
System.out.println(temp); //1
System.out.println(myPQ); //[3, 4, 7]
while(!myPQ.isEmpty()) {
System.out.println(myPQ.poll()); //3, 4, 7
}https://suyeon96.tistory.com/31
3. ⚡️ Array
3-1. 정의
배열은 정적 자료구조로서 미리 크기를 정해두게 되는데 , 그렇게 되면 해당크기 만큼의 연속적인 메모리를 할당 받게 됩니다. 메모리 상에서 연속적으로 저장되어 있는 특징을 갖기 때문에 index 를 통한 접근이 용이한 장점이 있습니다. 하지만 삽입/삭제가 오래 걸리고, 안쓰는 공간까지 전부 예약해두고 있어야 하므로 공간 낭비 뿐 아니라 해당 크기 이상의 데이터를 저장 할 수 없습니다.
3-2. 활용 예
- 순차열적인 데이터를 저장할 때 ex)주식 차트 (날짜별로 주식 가격이 저장)
3-3. Array Index Out Of Bound Exception이라는 Runtime Error
배열의 크기를 정하게 되는데, 크기 이상으로 값을 삽입하게 되면 Array Index Out Of Bound Exception이라는 Runtime Error가 발생하게 됩니다.
4. ⚡️ Linked List
4-1. 정의
동적 자료구조로서 각 노드는 데이터와 다음노드를 가리키는 주소 값(포인터)을 가지는 구조로 next라는 포인터로 연결된 형태입니다. (첫번째 노드는 헤드(Head),마지막 노드를 테일(Tail))
배열과 달리 메모리를 연속적으로 사용하지 않아 데이터 추가 및 삭제가 자유롭다는 장점인 즉 새로운 노드를 끼워넣기 쉽습니다.
- 반면 index로 임의 접근이 불가하며 처음부터 탐색을 해야하는 단점이 있습니다.
4-2. 활용 예
링크드 리스트는 음악플레이어의 이전곡 다음곡 연결 할때 사용한다고 합니다.
3,4 -1. 배열과 링크드 리스트 차이점 요약
따라서 배열은 크기가 정해져 있고, 빠른 접근이 요구되고, 데이터의 삽입과 삭제가 적을때 사용하고 링크드 리스트는 데이터의 크기가 정해져 있지 않고, 삽입과 삭제 연산이 잦고, 검색빈도가 적을 때 사용하는게 좋습니다.
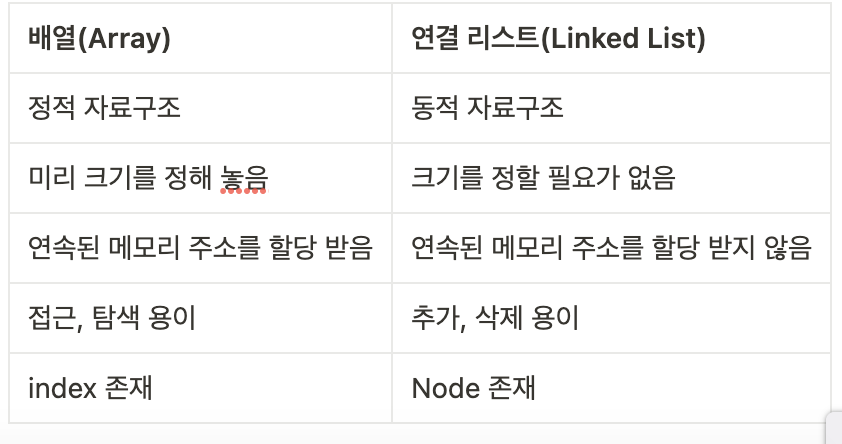
배열과 링크드리스트의 시간 복잡도
시간복잡도
배열은 접근과 탐색이 용이하다고 했는데요. index를 가지고 있기 때문에 탐색은 O(1)의 시간복잡도를 가집니다.
삽입의 경우는 맨 뒤라고 한다면 O(1)의 시간복잡도를 가지지만 맨 뒤가 아닌 나머지는 O(n)입니다.
연결 리스트는 추가, 삭제가 용이하다고 했죠. 삽입은 맨 앞일 경우 O(1)의 시간복잡도, 맨 앞이 아닌 나머지는 O(n)입니다.
그리고 배열과 반대로 탐색은 O(n)의 시간복잡도를 가집니다.
