본 글은 공부를 위해 망나니개발자에서 참조한 글 입니다.
Stream API의 활용 및 사용법
🎈Stream
자바 8에서 추가된 스트림은 람다를 활용할 수 있는 기술 중 하나로 배열과 컬렉션을 함수형으로 처리할 수 있습니다.
1. Stream 생성하기
앞서 설명한대로 Stream API를 사용하기 위해서는 먼저 Stream을 생성해주어야 한다. 타입에 따라 Stream을 생성하는 방법이 다른데, 여기서는 Collection과 Array에 대해서 Stream을 생성하는 방법에 대해 알아보도록 하자.
[ Collection의 Stream 생성 ]
Collection 인터페이스에는 stream()이 정의되어 있기 때문에, Collection 인터페이스를 구현한 객체들(List, Set 등)은 모두 이 메소드를 이용해 Stream을 생성할 수 있다. stream()을 사용하면 해당 Collection의 객체를 소스로 하는 Stream을 반환한다.
// List로부터 스트림을 생성
List<String> list = Arrays.asList("a", "b", "c");
Stream<String> listStream = list.stream(); [ 배열의 Stream 생성 ]
배열의 원소들을 소스로하는 Stream을 생성하기 위해서는 Stream의 of 메소드 또는 Arrays의 stream 메소드를 사용하면 된다.
// 배열로부터 스트림을 생성
Stream<String> stream = Stream.of("a", "b", "c"); //가변인자
Stream<String> stream = Stream.of(new String[] {"a", "b", "c"});
Stream<String> stream = Arrays.stream(new String[] {"a", "b", "c"});
Stream<String> stream = Arrays.stream(new String[] {"a", "b", "c"}, 0, 3); //end범위 포함 x[ stream.of]
stream.of() 메소드를 사용하면 스트림 객체를 바로 생성할 수 있습니다.
Stream<String> stream = Stream.of("1", "2", "3");
// [1, 2, 3][ 원시 Stream 생성 ]
위와 같이 객체를 위한 Stream 외에도 int와 long 그리고 double과 같은 원시 자료형들을 사용하기 위한 특수한 종류의 Stream(IntStream, LongStream, DoubleStream) 들도 사용할 수 있으며,💫 Intstream같은 경우 range()함수를 사용하여 기존의 for문을 대체할 수 있다.
// 4이상 10 이하의 숫자를 갖는 IntStream
IntStream stream = IntStream.range(4, 10);[ 빈 리스트]
Stream<String> stream = Stream.empty();[ builder ]
builder를 사용하면 사용자가 원하는 값을 입력할 수 있습니다. builder 사용 후, 마지막에 build() 메소드로 스트림을 리턴합니다.
Stream<String> builderStream = Stream.<String>builder()
.add("1")
.add("2")
.add("3")
.build();
// [1, 2, 3][ generate ]
generate를 사용하면 파라미터에 람다를 입력해 람다에서 리턴하는 값으로 스트림을 구성합니다. 생성되는 스트림의 크기는 무한이기 때문에 사이즈를 제한하는 것이 필요합니다.
Stream<String> generatedStream = Stream.generate(() -> "1").limit(3);
// [1, 1, 1][ iterate ]
iterate 메소드를 이용하면 초기값과 해당 값을 다루는 람다를 이용해서 스트림에 들어갈 요소를 만듭니다. 다음 예제에서는 30이 초기값이고 값이 2씩 증가하는 값들이 들어가게 됩니다. 즉 요소가 다음 요소의 인풋으로 들어갑니다. 이 방법도 스트림의 사이즈가 무한하기 때문에 특정 사이즈로 제한해야 합니다.
iterate를 사용하면 초기값, 해당 값을 다루는 람다를 사용해 스트림에 들어갈 요소를 만들어 냅니다. 1, 3, 5, 7, 9, ... 와 같은 형식을 만들 수 있습니다.
Stream<Integer> iteratedStream = Stream.iterate(1, n -> n + 2).limit(10);
// [1, 3, 5, 7, 9, 11, 13, 15, 17, 19]2. Stream 가공하기(중간연산)
생성한 Stream 객체에서 요소들을 가공하기 위해서는 중간연산이 필요하다. 가공하기 단계의 파라미터로는 앞서 설명하였던 함수형 인터페이스들이 사용되며, 여러 개의 중간연산이 연결되도록 반환값으로 Stream을 반환한다.
[ 필터링 - Filter ]
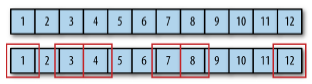
Filter는 Stream에서 조건에 맞는 데이터만을 정제하여 더 작은 컬렉션을 만들어내는 연산이다. Java에서는 filter 함수의 인자로 함수형 인터페이스 Predicate를 받고 있기 때문에, 📢boolean을 반환하는 람다식을 작성하여 filter 함수를 구현할 수 있다. 예를 들어 어떤 String의 stream에서 a가 들어간 문자열만을 포함하도록 필터링하는 예제는 다음과 같이 작성할 수 있다.
Stream<String> stream =
list.stream()
.filter(name -> name.contains("a"));
[ 데이터 변환 - Map ]
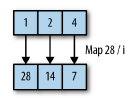
Map은 기존의 Stream 요소들을 변환하여 새로운 Stream을 형성하는 연산이다. 저장된 값을 특정한 형태로 변환하는데 주로 사용되며, Java에서는 map 함수의 인자로 함수형 인터페이스 function을 받고 있다. 예를 들어 String을 요소들로 갖는 Stream을 모두 대문자 String의 요소들로 변환하고자 할 때 map을 이용할 수 있다.
Stream<String> stream =
names.stream()
.map(s -> s.toUpperCase());
위의 map 함수의 람다식은 메소드 참조를 이용해 변경이 가능하다. 이번에는 메소드 참조를 이용하여 파일의 Stream을 파일 이름의 Stream으로 변경해보자.
Stream<File> fileStream = Stream.of(new File("Test1.java"), new File("Test2.java"), new File("Test3.java"));
//Stream<File> --> Stream<String> 변환
Stream<String> fileNameStream = fileStream.map(File::getName);[ 정렬 - Sorted ]
Stream의 요소들을 정렬하기 위해서는 sorted를 사용해야 하며, 파라미터로 Comparator를 넘길 수도 있다. Comparator 인자 없이 호출할 경우에는 오름차순으로 정렬이 되며,
내림차순으로 정렬하기 위해서는 Comparator의 reverseOrder를 이용하면 된다. 예를 들어 어떤 Stream의 String 요소들을 정렬하기 위해서는 다음과 같이 sorted를 활용할 수 있다.
List<String> list = Arrays.asList("Java", "Scala", "Groovy", "Python", "Go", "Swift");
Stream<String> stream = list.stream()
.sorted()
// [Go, Groovy, Java, Python, Scala, Swift]
Stream<String> stream = list.stream()
.sorted(Comparator.reverseOrder())
// [Swift, Scala, Python, Java, Groovy, Go][ 중복 제거 - Distinct ]
Stream의 요소들에 중복된 데이터가 존재하는 경우, 중복을 제거하기 위해 distinct를 사용할 수 있다. distinct는 중복된 데이터를 검사하기 위해 Object의 equals() 메소드를 사용한다. 예를 들어 중복된 Stream의 요소들을 제거하기 위해서는 아래와 같이 distinct()를 사용할 수 있다.
List<String> list = Arrays.asList("Java", "Scala", "Groovy", "Python", "Go", "Swift", "Java");
Stream<String> stream = list.stream()
.distinct()
// [Java, Scala, Groovy, Python, Go, Swift]만약 우리가 생성한 클래스를 Stream으로 사용한다고 하면 equals와 hashCode를 오버라이드 해야만 distinct()를 제대로 적용할 수 있다. equals와 hashCode에 대해서는 여기에서 자세히 다루었다.
만약 다음과 같은 Employee 클래스가 있다고 하자.
public class Employee {
private String name;
public Employee(String name) {
this.name = name;
}
public String getName() {
return name;
}
}위의 Employee 클래스는 equals와 hashCode를 오버라이드하지 않았기 때문에, 아래의 코드를 실행해도 중복된 데이터가 제거되지 않고, size 값으로 2를 출력하게 된다.
import java.util.*;
public class Main {
public static void main(String[] args) {
Employee e1 = new Employee("MangKyu");
Employee e2 = new Employee("MangKyu");
List<Employee> employees = new ArrayList<>();
employees.add(e1);
employees.add(e2);
int size = employees.stream().distinct().collect(Collectors.toList()).size();
System.out.println(size);
}
}그렇기 때문에 우리는 아래와 같이 equals와 hashCode를 오버라이드하여 이러한 문제를 해결해야 한다.
import java.util.Objects;
public class Employee {
private String name;
public Employee(String name) {
this.name = name;
}
public String getName() {
return name;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Employee employee = (Employee) o;
return Objects.equals(name, employee.name);
}
@Override
public int hashCode() {
return Objects.hash(name);
}
}위와 같은 코드를 추가하고 main 함수를 다시 실행시키면 size는 1이 된다.
[ 특정 연산 수행 - Peek ]
Stream의 요소들을 대상으로 Stream에 영향을 주지 않고 특정 연산을 수행하기 위한 peek 함수가 존재한다. '확인해본다'라는 뜻을 지닌 peek 단어처럼, peek 함수는 Stream의 각각의 요소들에 대해 특정 작업을 수행할 뿐 결과에 영향을 주지 않는다. 또한 peek 함수는 파라미터로 함수형 인터페이스 Consumer를 인자로 받는다. 예를 들어 어떤 stream의 요소들을 중간에 출력하기를 원할 때 다음과 같이 활용할 수 있다.
int sum = IntStream.of(1, 3, 5, 7, 9)
.peek(System.out::println)
.sum();[ 원시 Stream <-> Stream ]
작업을 하다 보면 일반적인 Stream 객체를 원시 Stream으로 바꾸거나 그 반대로 하는 작업이 필요한 경우가 있다. 이러한 경우를 위해서, 일반적인 Stream 객체는 mapToInt(), mapToLong(), mapToDouble()이라는 특수한 Mapping 연산을 지원하고 있으며, 그 반대로 원시객체는 mapToObject를 통해 일반적인 Stream 객체로 바꿀 수 있다.
// IntStream -> Stream<Integer>
IntStream.range(1, 4)
.mapToObj(i -> "a" + i)
// Stream<Double> -> IntStream -> Stream<String>
Stream.of(1.0, 2.0, 3.0)
.mapToInt(Double::intValue)
.mapToObj(i -> "a" + i)3. Stream 결과 만들기(최종 연산)
중간 연산을 통해 생성된 Stream을 바탕으로 이제 결과를 만들 차례이다. 결과를 만들기 위한 최종 연산에는 다음과 같은 것들이 존재한다.
[ 최댓값/최솟값/총합/평균/갯수 - Max/Min/Sum/Average/Count ]
Stream의 요소들을 대상으로 최솟값이나 최댓값 또는 총합을 구하기 위한 최종 연산들이 존재한다. 최솟값이나 최댓값을 구하기 위해서는 max와 min을 이용해야 하며, 총합 또는 평균 또는 개수를 구하기 위해서는 sum과 average, count를 이용해야 한다.📢 min이나 max 또는 average는 Stream이 비어있는 경우에 값을 특정할 수 없다. 그렇기 때문에 다음과 같이 Optional로 값이 반환된다.
OptionalInt min = IntStream.of(1, 3, 5, 7, 9).min();
int max = IntStream.of().max().orElse(0);
IntStream.of(1, 3, 5, 7, 9).average().ifPresent(System.out::println);ifPresent() 메소드
- Void 타입
- ifPresent()는 Optional 객체가 값을 가지고 있으면 실행 값이 없으면
isPresent() 메소드 = true, false 체크
ifPresent() 메소드 = 값을 가지고 있는지 확인 후 예외처리
반면에 총합이나 갯수의 경우에는 값이 비어있는 경우 0으로 값을 특정할 수 있다. 그렇기 때문에 Stream API는 sum 메소드와 count 메소드에대해 Optional이 아닌 원시 값을 반환하도록 구현해두었다. 당연히 Stream이 비어있을 경우에는 0을 반환하게 된다.
long count = IntStream.of(1, 3, 5, 7, 9).count();
long sum = LongStream.of(1, 3, 5, 7, 9).sum();
[ 데이터 수집 - collect ]
Stream의 요소들을 List나 Set, Map, 등 다른 종류의 결과로 수집하고 싶은 경우에는 collect 함수를 이용할 수 있다. collect 함수는 어떻게 Stream의 요소들을 수집할 것인가를 정의한 Collector 타입을 인자로 받아서 처리한다. 일반적으로 List로 Stream의 요소들을 수집하는 경우가 많은데, 이렇듯 자주 사용하는 작업은 Collectors 객체에서 static 메소드로 제공하고 있다. 원하는 것이 없는 경우에는 Collector 인터페이스를 직접 구현하여 사용할 수도 있다.
collect() : 스트림의 최종연산, 매개변수로 Collector를 필요로 한다.
Collector : 인터페이스, collect의 파라미터는 이 인터페이스를 구현해야한다.
Collectors : 클래스, static메소드로 미리 작성된 컬렉터를 제공한다.
// collect의 파라미터로 Collector의 구현체가 와야 한다.
Object collect(Collector collector)collect()를 응용한 다양한 예제들을 살펴보기 위해 다음과 같은 데이터가 사전에 정의되어 있다고 하자. Product 객체는 수량(amount)와 이름(name)을 변수로 가지며, 주어진 데이터를 다양한 방식으로 수집해볼 것이다.
List<Product> productList = Arrays.asList(
new Product(23, "potatoes"),
new Product(14, "orange"),
new Product(13, "lemon"),
new Product(23, "bread"),
new Product(13, "sugar"));1. Collectors.toList()
Stream에서 작업한 결과를 List로 반환받을 수 있다. 아래의 예제에서는 Stream의 요소들을 Product의 이름으로 변환하여, 그 결과를 List로 반환받고 있다.
List<String> nameList = productList.stream()
.map(Product::getName)
.collect(Collectors.toList());만약 해당 결과를 set으로 반환받기를 원한다면 Collectors.toSet()을 사용하면 된다.
2. Collectors.joining()
Stream에서 작업한 결과를 1개의 String으로 이어붙이기를 원하는 경우에 Collectors.joining()을 이용할 수 있다. Collectors.joining()은 총 3개의 인자를 받을 수 있는데, 이를 이용하면 간단하게 String을 조합할 수 있다.
delimiter : 각 요소 중간에 들어가 요소를 구분시켜주는 구분자
prefix : 결과 맨 앞에 붙는 문자
suffix : 결과 맨 뒤에 붙는 문자
String listToString = productList.stream()
.map(Product::getName)
.collect(Collectors.joining());
// potatoesorangelemonbreadsugar
String listToString = productList.stream()
.map(Product::getName)
.collect(Collectors.joining(" "));
// potatoes orange lemon bread sugar
String listToString = productList.stream()
.map(Product::getName)
.collect(Collectors.joining(", ", "<", ">"));
// <potatoes, orange, lemon, bread, sugar>
3. Collectors.averagingInt(), Collectors.summingInt(), Collectors.summarizingInt()
Stream에서 작업한 결과의 평균값이나 총합 등을 구하기 위해서는 Collectors.averagingInt()와 Collectors.summingInt()를 이용할 수 있다. 물론 총합의 경우 이를 구현할 수 있는 방법이 그 외에도 많이 있다.
Double averageAmount = productList.stream()
.collect(Collectors.averagingInt(Product::getAmount));
// 86
Integer summingAmount = productList.stream()
.collect(Collectors.summingInt(Product::getAmount));
// 86
Integer summingAmount = productList.stream()
.mapToInt(Product::getAmount)
.sum();하지만 만약 1개의 Stream으로부터 갯수, 합계, 평균, 최댓값, 최솟값을 한번에 얻고 싶은 경우에는 어떻게 할 수 있을까? 동일한 Stream 작업을 여러 번 실행하는 것은 그렇게 좋지 못한 방법이기 때문에, 이러한 경우에는 Collectors.summarizingInt()를 이용하는 것이 좋다. 이를 이용하면 IntSummaryStatistics 객체가 반환되며, 필요한 값에 대해 get 메소드를 이용하여 원하는 값을 꺼내면 된다.
개수: getCount()
합계: getSum()
평균: getAverage()
최소: getMin()
최대: getMax()
IntSummaryStatistics statistics = productList.stream()
.collect(Collectors.summarizingInt(Product::getAmount));
//IntSummaryStatistics {count=5, sum=86, min=13, average=17.200000, max=23}4. Collectors.groupingBy()
Stream에서 작업한 결과를 특정 그룹으로 묶기를 원할 수 있다. 이러한 경우에는 Collectors.groupingBy()를 이용할 수 있으며, 결과는 Map으로 반환받게 된다. groupingBy는 매개변수로 함수형 인터페이스 Function을 필요로 한다.
예를 들어 수량을 기준으로 grouping을 원하는 경우에 다음과 같이 작성할 수 있으며, 같은 수량일 경우에는 List로 묶어서 값을 반환받게 된다.
Map<Integer, List<Product>> collectorMapOfLists = productList.stream()
.collect(Collectors.groupingBy(Product::getAmount));
/*
{23=[Product{amount=23, name='potatoes'}, Product{amount=23, name='bread'}],
13=[Product{amount=13, name='lemon'}, Product{amount=13, name='sugar'}],
14=[Product{amount=14, name='orange'}]}
*/5. Collectors.partitioningBy()
Collectors.groupingBy()가 함수형 인터페이스 Function을 사용해서 특정 값을 기준으로 Stream 내의 요소들을 그룹핑하였다면, Collectors.partitioningBy()는 함수형 인터페이스 Predicate를 받아 Boolean을 Key값으로 partitioning한다.
예를 들어 제품의 갯수가 15보드 큰 경우와 그렇지 않은 경우를 나누고자 한다면 다음과 같이 코드를 작성할 수 있다.
Map<Boolean, List<Product>> mapPartitioned = productList.stream()
.collect(Collectors.partitioningBy(p -> p.getAmount() > 15));
/*
{false=[Product{amount=14, name='orange'}, Product{amount=13, name='lemon'}, Product{amount=13, name='sugar'}],
true=[Product{amount=23, name='potatoes'}, Product{amount=23, name='bread'}]}
*/[ 조건 검사 - Match ]
Stream의 요소들이 특정한 조건을 충족하는지 검사하고 싶은 경우에는 match 함수를 이용할 수 있다. match 함수는 함수형 인터페이스 Predicate를 받아서 해당 조건을 만족하는지 검사를 하게 되고, 검사 결과를 boolean으로 반환한다. match 함수에는 크게 다음의 3가지가 있다.
anyMatch: 1개의 요소라도 해당 조건을 만족하는가
allMatch: 모든 요소가 해당 조건을 만족하는가
nonMatch: 모든 요소가 해당 조건을 만족하지 않는가
예를 들어 다음과 같은 예시 코드가 있다고 할 때, 아래의 경우 모두 true를 반환하게 된다.
List<String> names = Arrays.asList("Eric", "Elena", "Java");
boolean anyMatch = names.stream()
.anyMatch(name -> name.contains("a"));
boolean allMatch = names.stream()
.allMatch(name -> name.length() > 3);
boolean noneMatch = names.stream()
.noneMatch(name -> name.endsWith("s"));[ 특정 연산 수행 - forEach ]
Stream의 요소들을 대상으로 어떤 특정한 연산을 수행하고 싶은 경우에는 forEach 함수를 이용할 수 있다. 앞에서 살펴본 비슷한 함수로 peek()가 있다. peek()는 중간 연산으로써 실제 요소들에 영향을 주지 않은 채로 작업을 진행하고, Stream을 반환하는 함수였다. 하지만 forEach()는 최종 연산으로써 실제 요소들에 영향을 줄 수 있으며, 반환값이 존재하지 않는다. 예를 들어 요소들을 출력하기를 원할 때 다음과 같이 forEach를 사용할 수 있다.
names.stream()
.forEach(System.out::println);[ Stream.reduce() ]
Stream.reduce(accumulator) 함수는 Stream의 요소들을 하나의 데이터로 만드는 작업을 수행합니다.
예를 들어, Stream에서 1부터 10까지 숫자가 전달될 때, 이 값을 모두 합하여 55의 결과가 리턴되도록 만들 수 있습니다. 여기서 연산을 수행하는 부분은 accumulator 함수이며, 직접 구현해서 인자로 전달해야 합니다.
아래는 reduce()를 사용하여 Stream에서 전달되는 요소들의 숫자를 모두 합하는 예제입니다.
Stream<Integer> numbers = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Optional<Integer> sum = numbers.reduce((x, y) -> x + y);
sum.ifPresent(s -> System.out.println("sum: " + s));
Output:
sum: 55위의 예제를 설명하면서 reduce()의 동작 방식에 대해서 소개하겠습니다.
reduce()는 인자로 BinaryOperator 객체를 받는데, BinaryOperator는 T 타입의 인자 두개를 받고 T 타입의 객체를 리턴하는 함수형 인터페이스입니다.
BinaryOperator는 (total, n) -> total + n와 같은 형식으로 인자가 전달되는데요. Stream의 1이 전달될 때, total(0) + n(1) = 1와 같이 계산되고, 여기서 리턴되는 1이 다음에 Stream에서 2가 전달될 때 total로 전달됩니다. 따라서, total(1) + n(2) = 3이 됩니다.
다시 정리하면 아래와 같이 연산되면서, 마지막에는 1에서 10까지의 숫자를 더한 55가 리턴됩니다.
total(0) + n(1) = 1
total(1) + n(2) = 3
total(3) + n(3) = 6
total(6) + n(4) = 10
total(10) + n(5) = 15
total(15) + n(6) = 21
total(21) + n(7) = 28
total(28) + n(8) = 36
total(36) + n(9) = 45
total(45) + n(10) = 55
1 메소드 레퍼런스로 구현
(x, y) -> x + y와 같이 합을 계산하는 함수는, JDK에서 Integer.sum(a, b) 라는 기본 함수를 제공합니다.
여기서 메소드 레퍼런스를 이용하면, Integer::sum 처럼 더 짧은 코드로 동일한 결과를 리턴하는 코드를 구현할 수 있습니다.
Stream<Integer> numbers = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Optional<Integer> sum = numbers.reduce(Integer::sum);
sum.ifPresent(s -> System.out.println("sum: " + s));2. 초기값이 있는 Stream.reduce()
위의 예제에서는 total의 초기 값이 0이였습니다.
하지만 Stream.reduce(init, accumulator) 처럼 초기 값을 인자로 전달할 수 있습니다.
위의 예제에서 초기 값이 10으로 설정하면, '10 + 1 + 2 + 3... 10'과 같이 연산을 합니다.
Stream<Integer> numbers = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Integer sum = numbers.reduce(10, (total, n) -> total + n);
System.out.println("sum: " + sum);
Output:
sum: 653. reduce()의 병렬 처리
Stream.parallel()은 Stream 연산을 병렬 처리로 수행하도록 합니다. 즉, parallel()과 함께 reduce()를 사용하면 순차적으로 연산을 수행하지 않고 여러개의 연산을 동시에 진행하고, 그 작업들을 다시 병합하여 최종적으로 1개의 결과를 생성합니다.
예를 들어, (1 + 2) + (3 + 4) + ... + (9 + 10) 처럼 두개씩 묶어서 먼저 계산하고, 그 결과들을 다시 계산할 수 있습니다.
Stream<Integer> numbers = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Integer sum = numbers.parallel().reduce(0, (total, n) -> total + n);
System.out.println("sum: " + sum);
Output:
sum: 55하지만 빼기 연산의 경우 병렬처리는 순차적인 처리(병렬이 아닌)와 결과가 다릅니다. 아래 코드를 실행해보면 -55가 아니라 -5가 리턴됩니다. 결과가 다른 이유는 (1 - 2) - (3 - 4) - ... - (9 - 10) 처럼 연산이 수행되면서 순차적으로 연산하는 것과 결과가 달라지기 때문입니다.
Stream<Integer> numbers = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Integer sum = numbers.parallel().reduce(0, (total, n) -> total - n);
System.out.println("sum: " + sum);
Output:
sum: -5병렬 처리 과정에서 reduce()를 사용할 때는 위와 같은 문제가 없는지 확인을 해야 합니다.
4. 병렬 처리에서 reduce()는 순차적으로 처리
병렬처리에서 연산 순서에 따라 발생하는 문제를 해결하기 위해, 아래 예제와 같이 다른 규칙을 추가할 수 있습니다.
위의 예제와 비교해보면 (total1, total2) -> total1 + total2가 추가되었는데, 병렬로 처리된 결과들의 관계를 나타냅니다. 다시 설명하면, 첫번째 연산과 두번째 연산은 합해야 한다는 규칙을 추가한 것인데요. 이렇게 규칙을 추가하면, 첫번째 연산의 결과가 다음 연산에 영향을 주기 때문에 reduce()는 작업을 나눠서 처리할 수 없게 됩니다.
Stream<Integer> numbers = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Integer sum = numbers.reduce(0,
(total, n) -> total - n,
(total1, total2) -> total1 + total2);
System.out.println("sum: " + sum);
Output:
sum: -55
🎈참고
스트림의 주요 메소드
스트림
