🎈 1. Offset-based Pagination
📍1-1. 개념
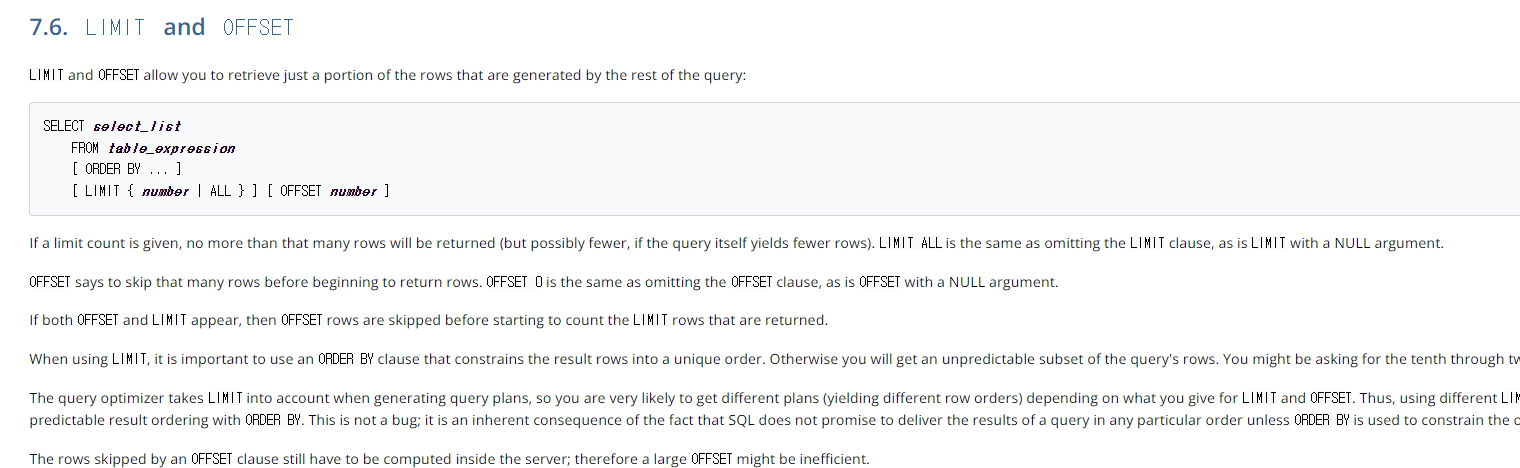
LIMIT and OFFSET allow you to retrieve just a portion of the rows that are generated by the rest of the query:
즉 Limit와 Offset 을 이용하여 쿼리에 의해 검색되어진 일부분을 보여줌으로 페이징 처리가 가능하다.
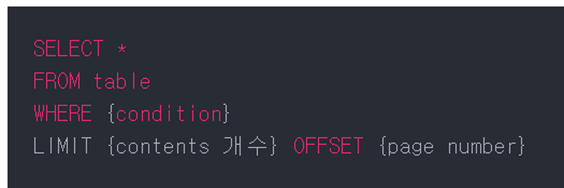
Limit
-
LIMIT는 원하는 레코드 수를 쿼리에 알려준다.
-
LIMIT를 사용할 때 결과 행을 고유한 순서로 제한하는 ORDER BY 절을 사용하는 것이 중요하다. 그렇지 않으면 쿼리 행의 예측할 수 없는 하위 집합이 생성된다.
OFFSET
-
OFFSET은 쿼리를 시작할 위치를 알려준다.
-
OFFSET으로 처음 5개 레코드를 가져오는 쿼리 이다. 처음부터 쿼리를 시작하도록 명시적으로 지시하고 있다.
select * from public.customer
order by customer_id
limit 5
offset 5;즉 5번째부터 5개를 가져와야 함으로 6,7,8,9,10 데이터를 가져오는 것이다.
결과적으로 아래와 같은 쿼리가 작성된다.
select *
from [테이블명]
order by [정렬 기준이 되는 컬럼]
limit #{take}
offset (#{page} -1)* #{take} // 실제 페이지는 1이 아닌 0부터 시작하기 때문에 '-1'을 해준다.📍1-2. 장점
페이지번호와 페이지크기만 알면 어떤 페이지든 쉽게 접근 할 수 있어, 사용자가 대량의데이터 중 특정 부분으로 바로 접근하고 할때 유용하다.
📍1-3. 단점 및 주의할 점
1-3-1. 단점
단점 1
- offset은 데이터베이스에서 쿼리의 처음 N개 결과를 건너뛰도록 설정되어 있다. 하지만 데이터베이스 N개 결과 이후의 row만 받아오는 것이
- 모든 row 를 디스크로 부터 읽어오고, N개의 결과까지 순서대로 넘기는 식
- 즉, offset을 사용하는것은 많은 행을 읽어들여오고, 이후에 삭제하는 과정을 거쳐 큰offset값은 데이터베이스에 많은 부하를 주게 된다.
단점 2
- 문제사항: order by 절에 사용되는 column에 중복 값이 있는 경우
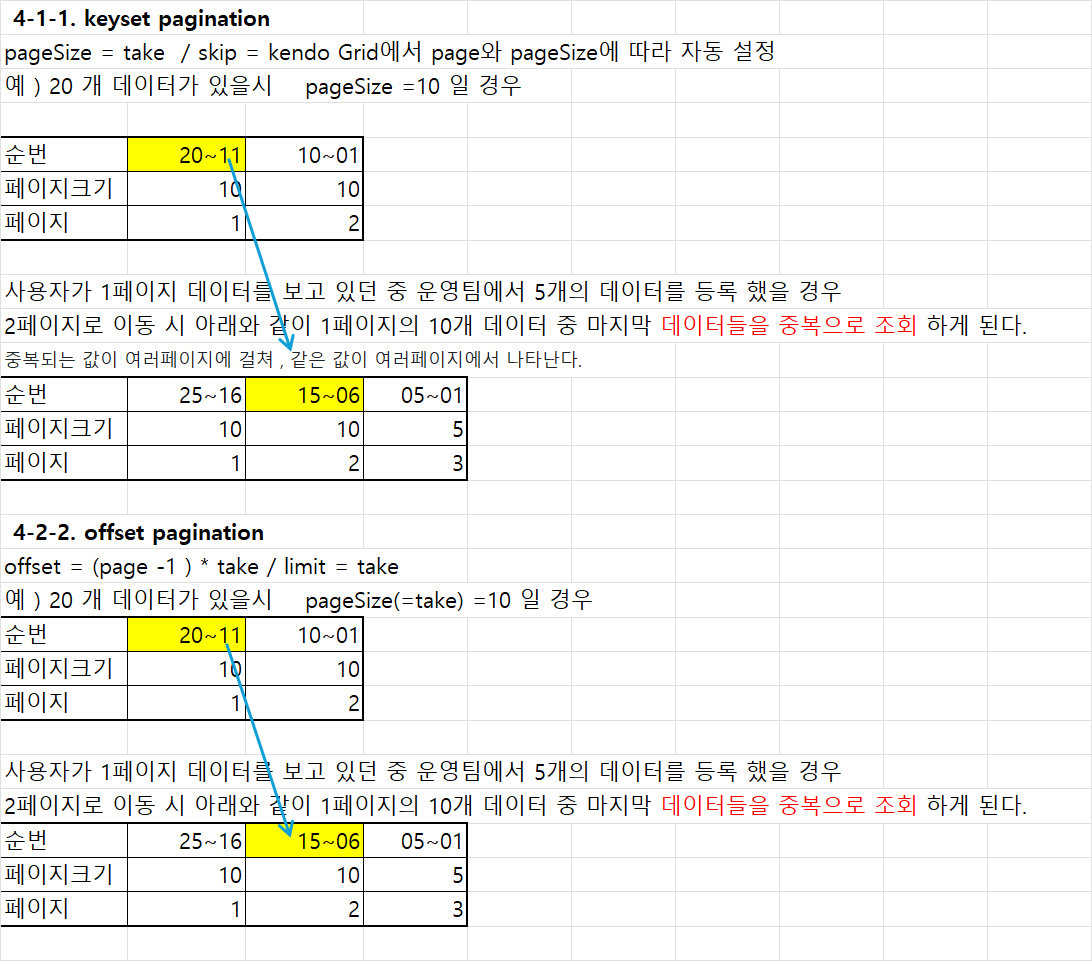
(⭐ 예를 들어 , 1페이지에서 20개의 row 를 불러와서 유저에게 1페이지를 띄워 주었다. 고객이 1페이지 상품들을 보고 있는 사이 , 상품 운영팀에서 5개의 상품을 새로 등록했다면?
-> 유저가 1페이지 상품을 다 둘러보고 2페이지를 눌렀을때 1페이지에서 보았던 상품20개중 마지막 5개를 다시 2페이지에서 만나게 된다. (등록일 기준 내림차순 이므로
반대로 5개 상품을 삭제 했다면 2페이지 넘어갔을때 고객은 5개의 상품을 못하게 된다.
)
중복되는 값이 여러페이지에 걸쳐 , 같은 값이 여러페이지에서 나타난다.
1-3-2. 해결방안 : 중복되는 값이 나타나지 않도록 order by절에 primary key가 되는 column의 값을 추가한다.
변경 전 sql
1개의 페이지에 10개의 게시물이 출력된다고 가정하면, 첫 번째 페이지의 sql 은 다음과 같다.
select
graha_mail_id,
subject,
sent_date
from webmua.graha_mail
order by sent_date desc
limit 10 offset 02 번째 페이지는 offset 부분만 변경된다.
limit 10 offset 10
변경 후 sql
order by 절에 Primary 컬럼인 graha_mail_id 를 추가한다.
📍1-4.
그럼에도 사람들은 왜 keyset pagination보다 offset을 더 선호하는 걸까? 더 사용하고 있는 걸까?
https://vladmihalcea.com/sql-seek-keyset-pagination/ 이 글에서
원작자는 그 이유가 lack of tool support. 즉, 지원되는 도구가 부족하기 때문이라고 말하고 있다. 대부분의 데이터베이스 도구/프레임워크들은 offset을 활용한 pagination을 제공하고, keyset pagination방식을 위한 방법은 제공하지 않고 있다. 그렇기에 이러한 keyset pagination의 사용이 퍼지기 위해서는 더 다양한 도구/프레임워크에서 지원해줘야 한다.
하나의 예를 들어보자면 Spring Data JPA가 있다. Spring Data JPA에서는 Pageable, Page 객체를 통해 쉽게 pagination 구현을 할 수 있도록 지원하고 있다. Database마다 다를 수 있지만 H2 DB를 사용해 테스트해보면, offset을 사용해 pagination 처리를 하고 있는 것을 확인할 수 있다.
select
graha_mail_id,
subject,
sent_date
from webmua.graha_mail
order by sent_date desc, graha_mail_id desc
limit 10 offset 0🎈 2. keyset-based Pagination
📍2-1. 개념
- 특정한 순서를 가진 열(column)을 사용하여 데이터를 페이지별로 나눈다.
order by [고유값 id ]
📍2-2. 장점
2-2-1. 장점
장점 1 예측 가능한 성능
OFFSET Pagination과 달리 데이터베이스가 전체 데이터를 스캔하는 일이 없어지므로 큰 데이터셋에서 성능이 향상될 수 있습니다.
장점 2 안정적인 페이징
OFFSET Pagination은 데이터가 추가되거나 삭제될 때 페이지 경계가 이동할 수 있지만, Keyset Pagination은 이러한 문제를 해결할 수 있습니다.
장점 3 일관된 결과
OFFSET Pagination은 데이터가 변경될 때마다 페이지 내용이 변경될 수 있지만, Keyset Pagination은 페이지 내용이 일관된 상태를 유지합니다.
(추후 수정 가능 , 이부분 내생각엔 일관되지 않는다 . 정렬에 따라 )
📍2-3. 단점
근데 keyset pagination 방식도 단점이 존재한다.
OFFSET Pagination과 달리 데이터베이스가 전체 데이터를 스캔하는 일이 없어지므로 큰 데이터셋에서 성능이 향상될 수 있습니다.
바로 임의의 특정 페이지로 바로 이동이 불가능하다는 것이다. 위 쿼리를 봐서 알겠지만 최근에 조회한 row 이후의 데이터들만 가져오도록 하고 있지, 특정 페이지 번호를 통해 조회하고 있지 않다. 그러므로 비즈니스 로직 상 특정 페이지의 데이터를 조회하는 것이 필요하다 했을 때, keyset pagination는 적합하지 않다. 무한 스크롤 방식이라면 문제가 되지 않는다.
🎈3. 활용
) A
<choose>
<when test="take != '' and take != null">
<choose>
<when test="skip != '' and skip != null">
WHERE T.SN <![CDATA[>]]> #{skip}
</when>
<when test="page != '' and page != null">
OFFSET ((#{page} - 1) * #{take})
</when>
<otherwise>
WHERE T.SN <![CDATA[>]]> 0
</otherwise>
</choose>
LIMIT #{take}
</when>
<otherwise>
LIMIT 10000
</otherwise>
</choose>질문 1.keyset Pagination과 offset Pagination 함께 사용하는 이유?
- 현재 kendo Grid 라는 ui 를 사용하고 있는 경우나 또는 parameter를 재지정하여 구현하는 개발자분들도 있어 take,skip,page 가 파라미터로 넘어가지 않는 경우가 있다. 이를 위해 offset pagination 방식을 혼용하여 사용한다.
- keyset paging 이 유리하다 판단되어 해당 파라미터가 있을 경우 최우선으로 keyset paging 처리를 하고 ,
- 파라미터값이 들어오지 않을 경우 대비하여 offset paging 으로 처리,
- 세션이 나가면서 파라미터값이 날아 가는 등의 예외상황시에도 대량 데이터 조회를 막기 위해 limit 10000 건을 지정함으로 끝나지 않는 쿼리로 25시간 동안 쿼리가 돌아가는 현상의 가능성을 막음 , 이 조건이 없을시 where 1=1 로 되어 위험 가능성 있음 (where 1=1 을 쿼리에 사용한 경우)
문제점 : 만약 keyset Pagination 에서 특정한 순서를 가진 열(column)을 순번(SN) 등으로 할때 주의 점
- 테이블 자체의 순번(SN) 특정할 컬럼이 있다면 위의 코드가 문제가 되지 않지만
- 쿼리를 통해 임의로 만든 순번(SN)는 순번을 만드는 과정에서 데이터를 풀스캔하므로 성능저하가 발생한다. 이때는 Offset Pagination이 성능적으로 효과적일 수 있다.
) A
<choose>
<when test="take != '' and take != null">
<choose>
<when test="page != '' and page != null">
OFFSET ((#{page} - 1) * #{take})
</when>
<when test="skip != '' and skip != null">
WHERE T.SN <![CDATA[>]]> #{skip}
</when>
<otherwise>
WHERE T.SN <![CDATA[>]]> 0
</otherwise>
</choose>
LIMIT #{take}
</when>
<otherwise>
LIMIT 10000
</otherwise>
</choose>🎈 4. 페이징 처리 테스트 및 결과
(문제가 되는 경우로 등록일 기준 내림차순 시)
📍 4-1. 고유값이 아닌 순번으로 페이징 처리할때

📍 4-2. 고유값이 아닌 순번으로 페이징 처리할때
(문제가 되지 않는 경우로 등록일 기준 내림차순 이면서 , 페이지마다 순번을 오름차순일 경우- 추후 알게 된 점이지만 보통 이렇게 처리한다고 한다. )


다만 offset pagination의 경우
offset은 데이터베이스에서 쿼리의 처음 N개 결과를 건너뛰도록 설정되어 있다. 하지만 데이터베이스 N개 결과 이후의 row만 받아오는 것이
모든 row 를 디스크로 부터 읽어오고, N개의 결과까지 순서대로 넘기는 식
즉, offset을 사용하는것은 많은 행을 읽어들여오고, 이후에 삭제하는 과정을 거쳐 큰 offset값은 데이터베이스에 많은 부하를 주게 된다.
그러므로 게시판, 무한 스크롤등 paging이 필요한 곳에서는 정렬된 데이터를 필요로 하므로 order by [ 고유값 컬럼 ]을 사용하는 것이 좋다고 생각된다.
🎈5.결론
4-1 번 케이스
등록일 기준 내림차순 정렬하면 보통 위해서 부터 아래로 10 ->1 으로 표시한다.
이런 경우 실사간으로 데이터가 추가되면 중복되는 건 당연하지만
그렇게 되면 순번이 큰 의미가 없어진다.
[출처]네이버 블로그 글 목록
4- 2번케이스
보통 등록일 기준 내림차순 정렬하면 보통 위해서 부터 아래로 1->10 으로 표시한다.

(요구사항에 의해 반대인 경우도 있음)
이 경우엔 중복조회에 대해 갱신된 데이터가 보이가 되므로 문제가 되지 않는다.
- 순번은 관례상 넣어두는 느낌이 강해 쿤 의미가 없다. DB에 들어있는 값이 아닌 조회 쿼리에서 만들어 사용하는 값이기 때문이다.
신규 데이터가 계속 최상위로 올라와야 하는게 보편적인 업무 기준이 된다.
참고자료
Postgresql 의 limit, offset 으로 페이징 처리할 때 주의할 점
https://binux.tistory.com/148
